
hello, 大家好, 今天和大家分享一位朋友自荐的项目——一款无网络限制的ChatGPT替代软件:Claude. 接下来就是使用Claude 的具体介绍, 欢迎大家学习参考, 如果你有好的产品或者开源项目, 也欢迎推荐或者自荐, 让 3w+ 优质程序员看到你的项目.
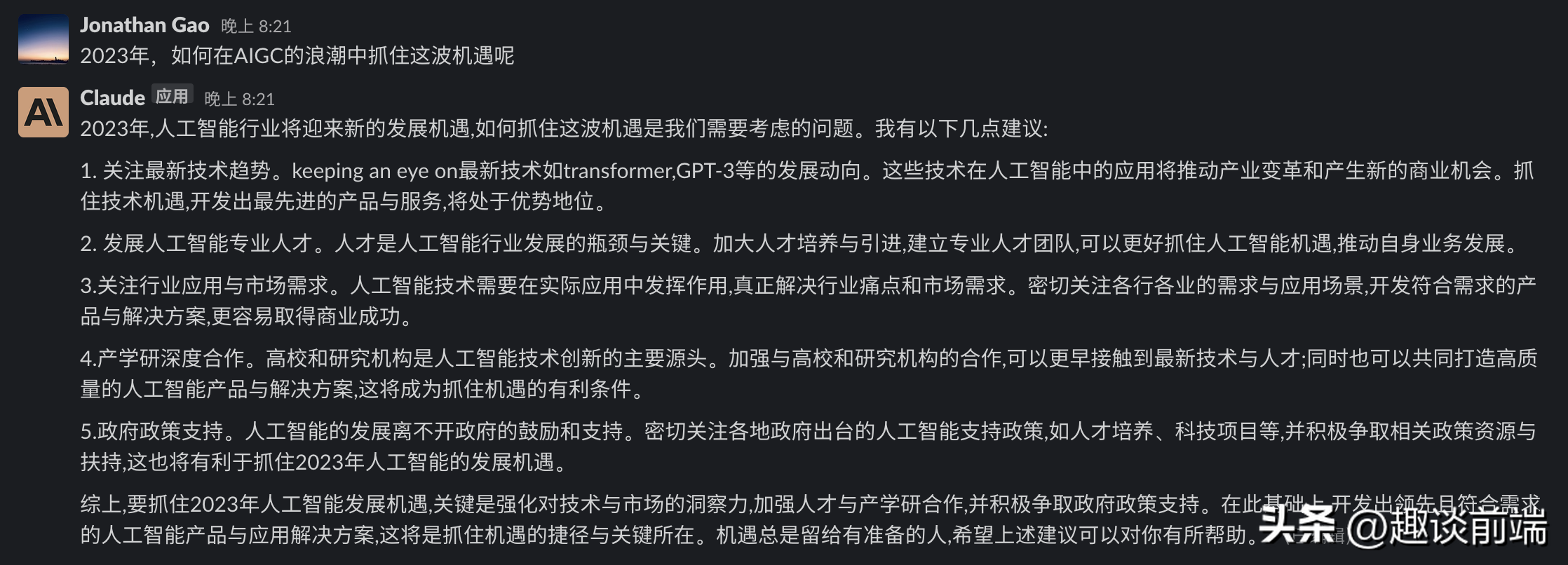
在2023年,人工智能技术和产品正在蓬勃发展。特别是语言模型和对话系统方面,ChatGPT成为了海外用户高效便捷的人工智能助手。然而,ChatGPT目前无法在中国大陆使用。本文将为大家介绍一款在中国大陆可以使用的类似产品——Claude
一款由Anthropic研发的人工智能语言助手。具有以下主要功能:
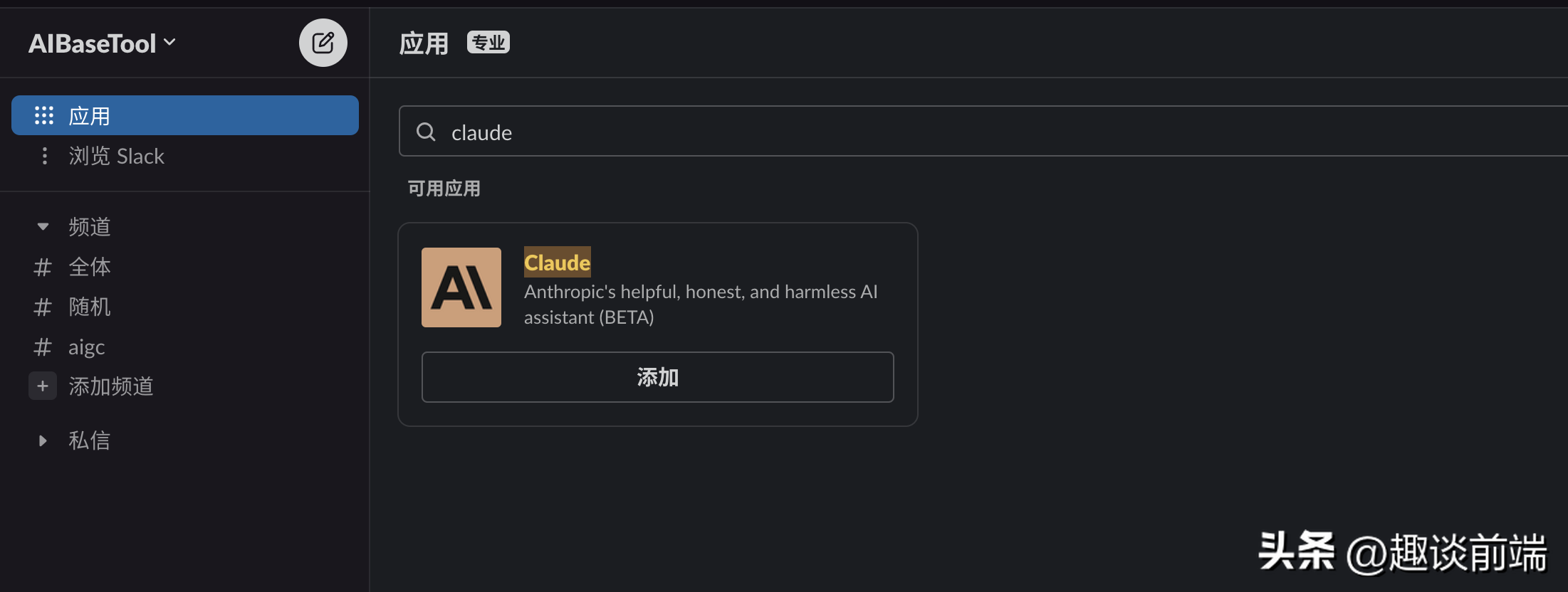
上面介绍了一大堆之后,现在给大家进行对比展示:




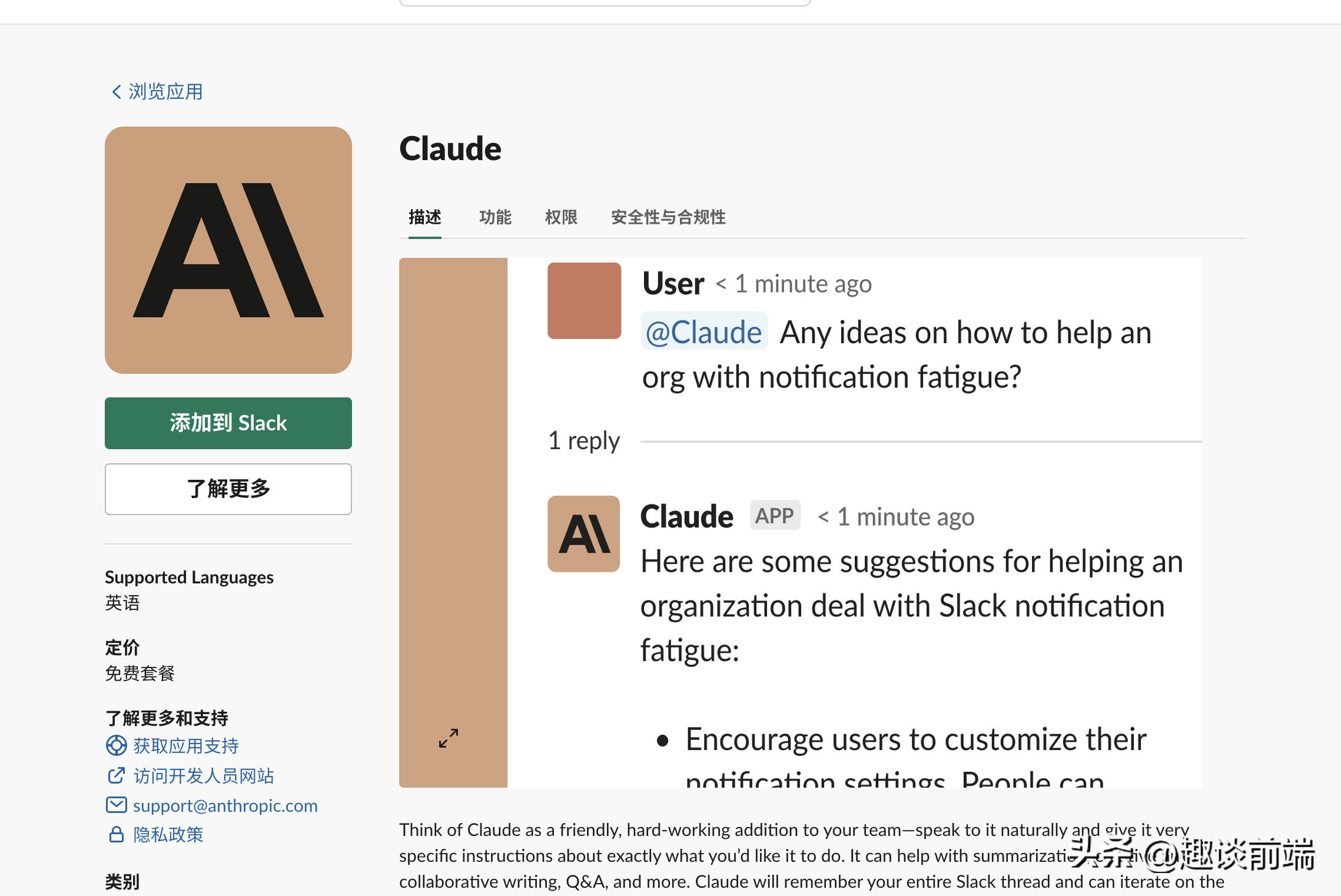
关于如何使用Claude,就不得不提到Slack这款优秀的团队协作和沟通平台。Slack和Claude的关系如下:
整个工作流程如下:
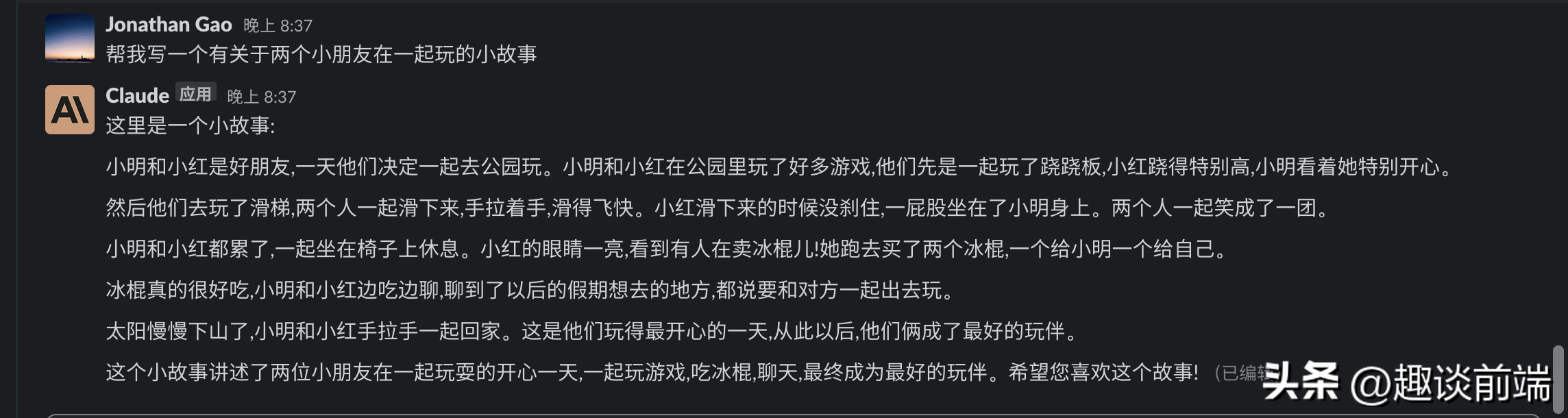
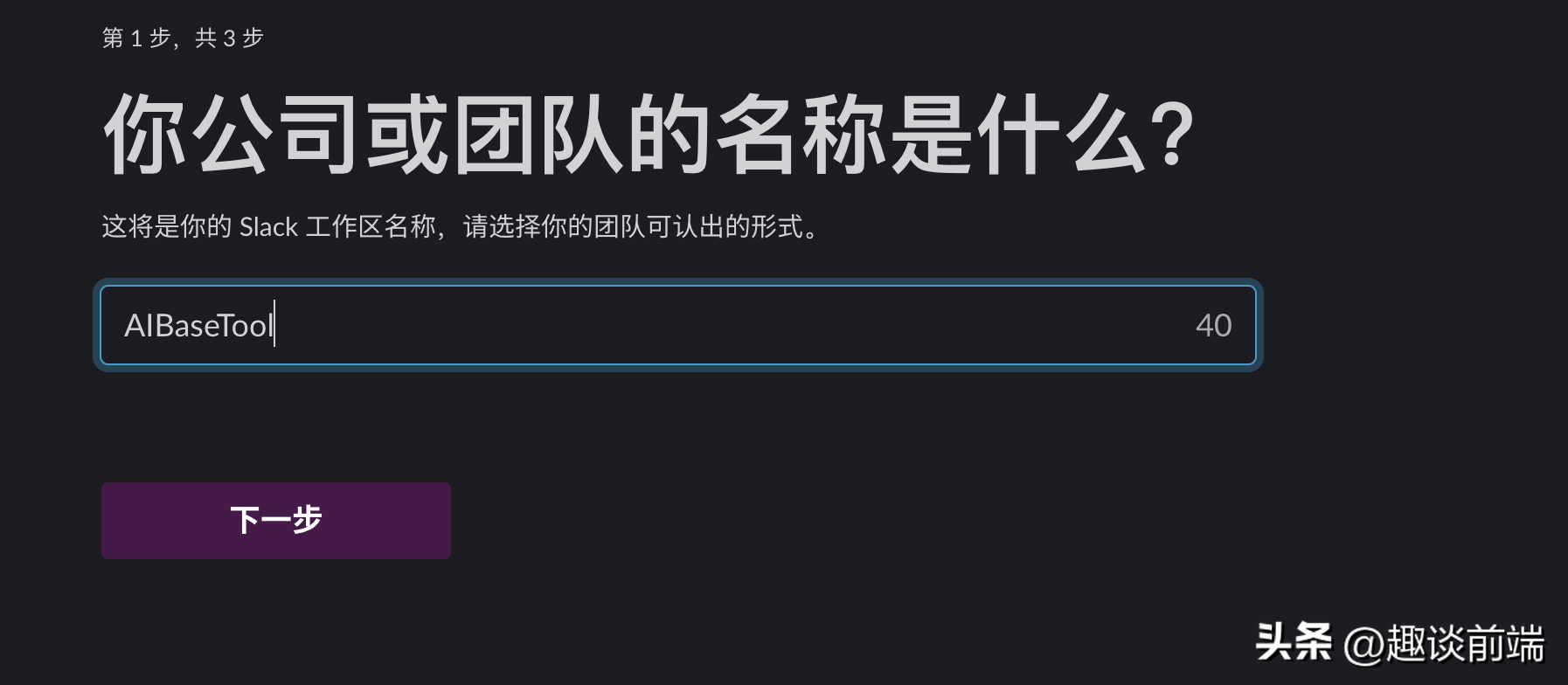
接下来,小编将教你一步步创建一个拥有Claude人工智能助手的工作频道。今天这个教程完全是站在国内用户受限的情况角度来创建:
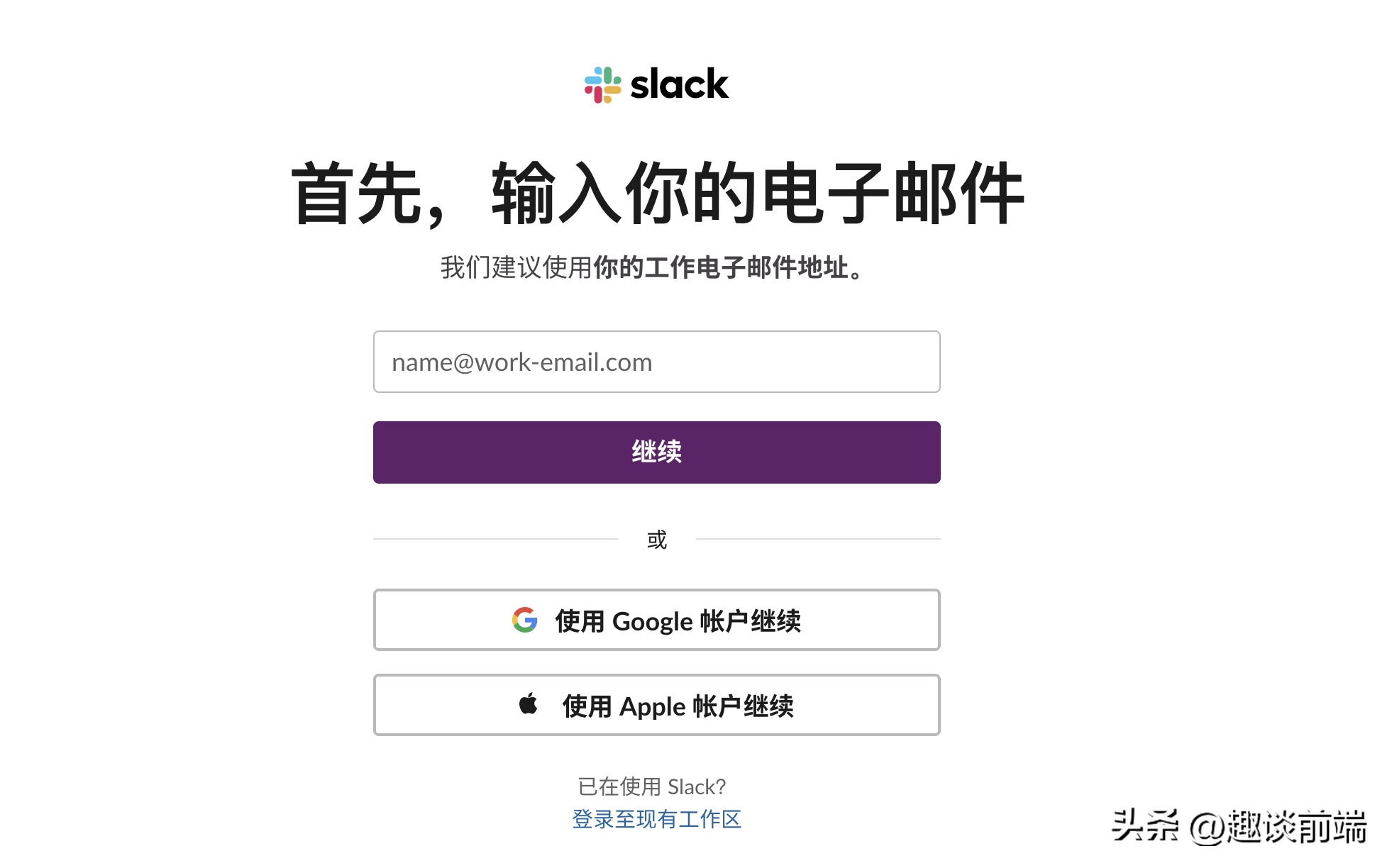
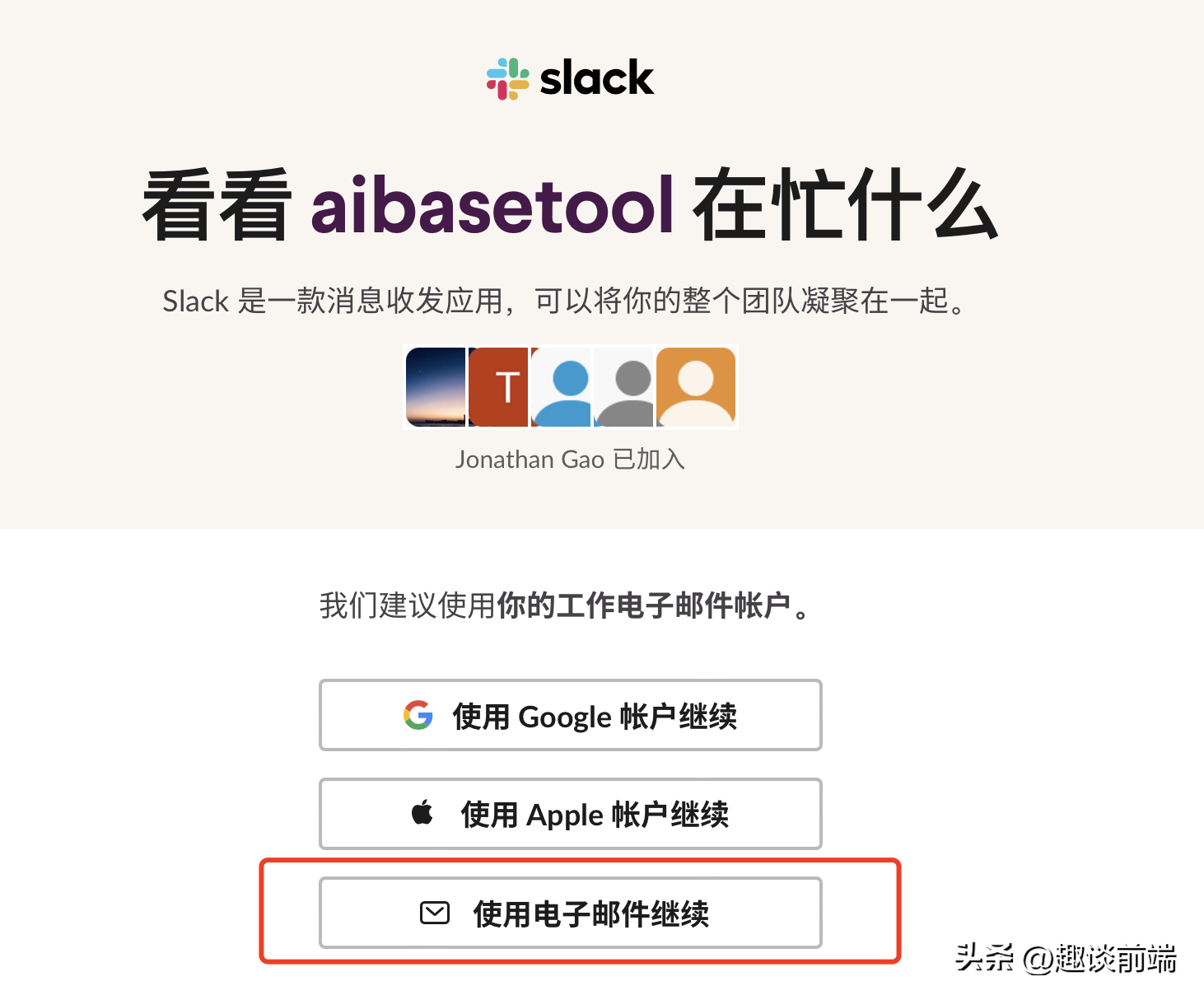
准备一个非国内公司邮箱账号,推荐微软邮箱(不受网络限制),就可以打开Slack网站创建工作区的工作区。


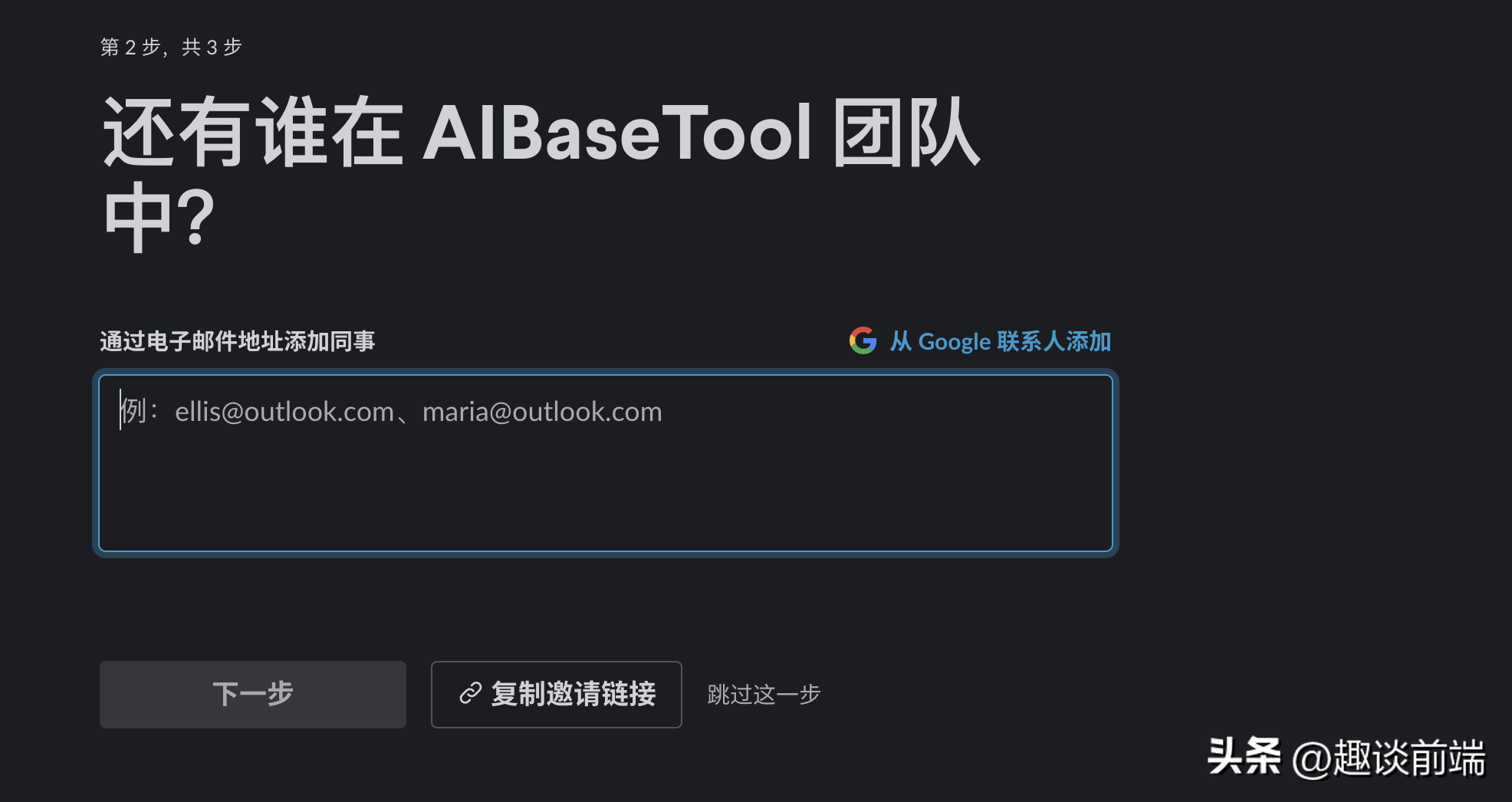


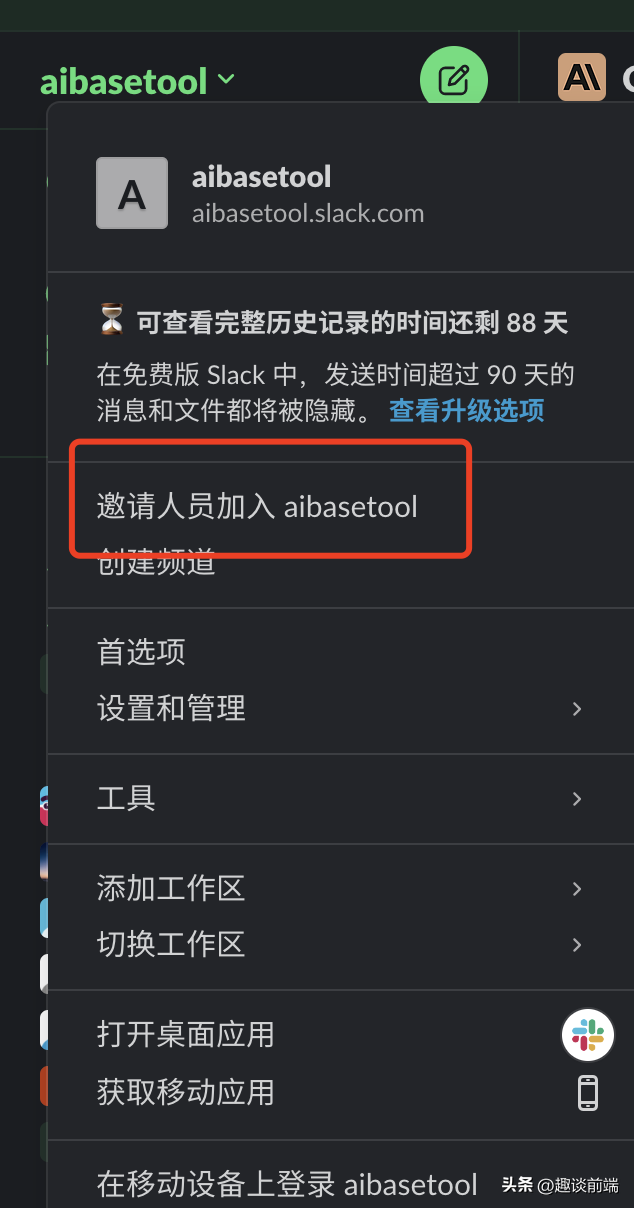
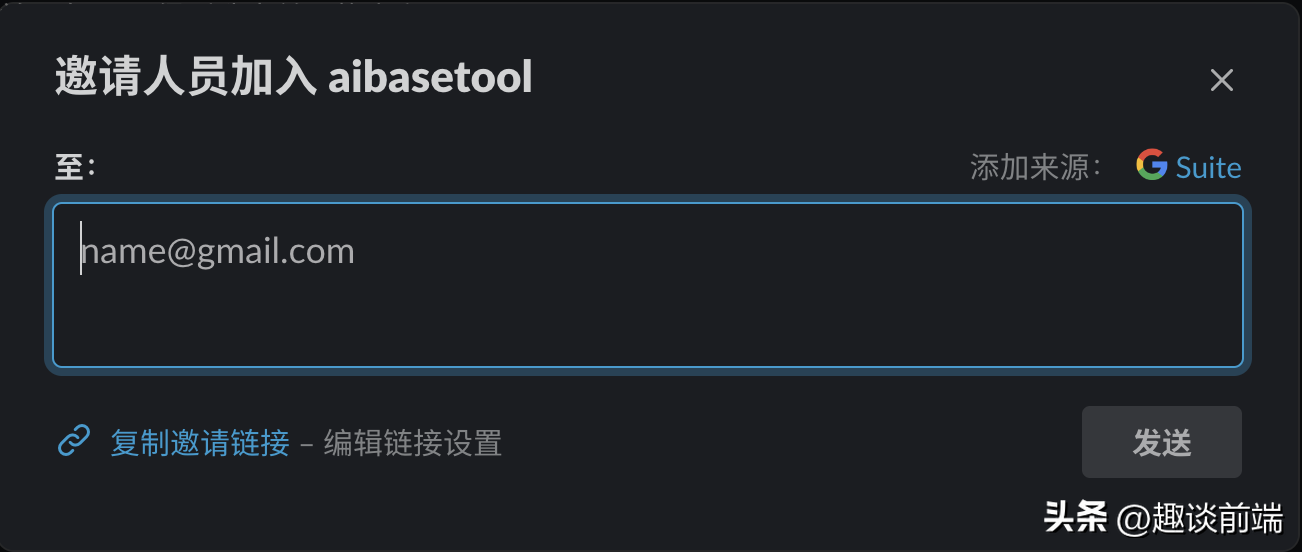
这里可以邀请指定邮件,也可以复制邀请链接发送给朋友。
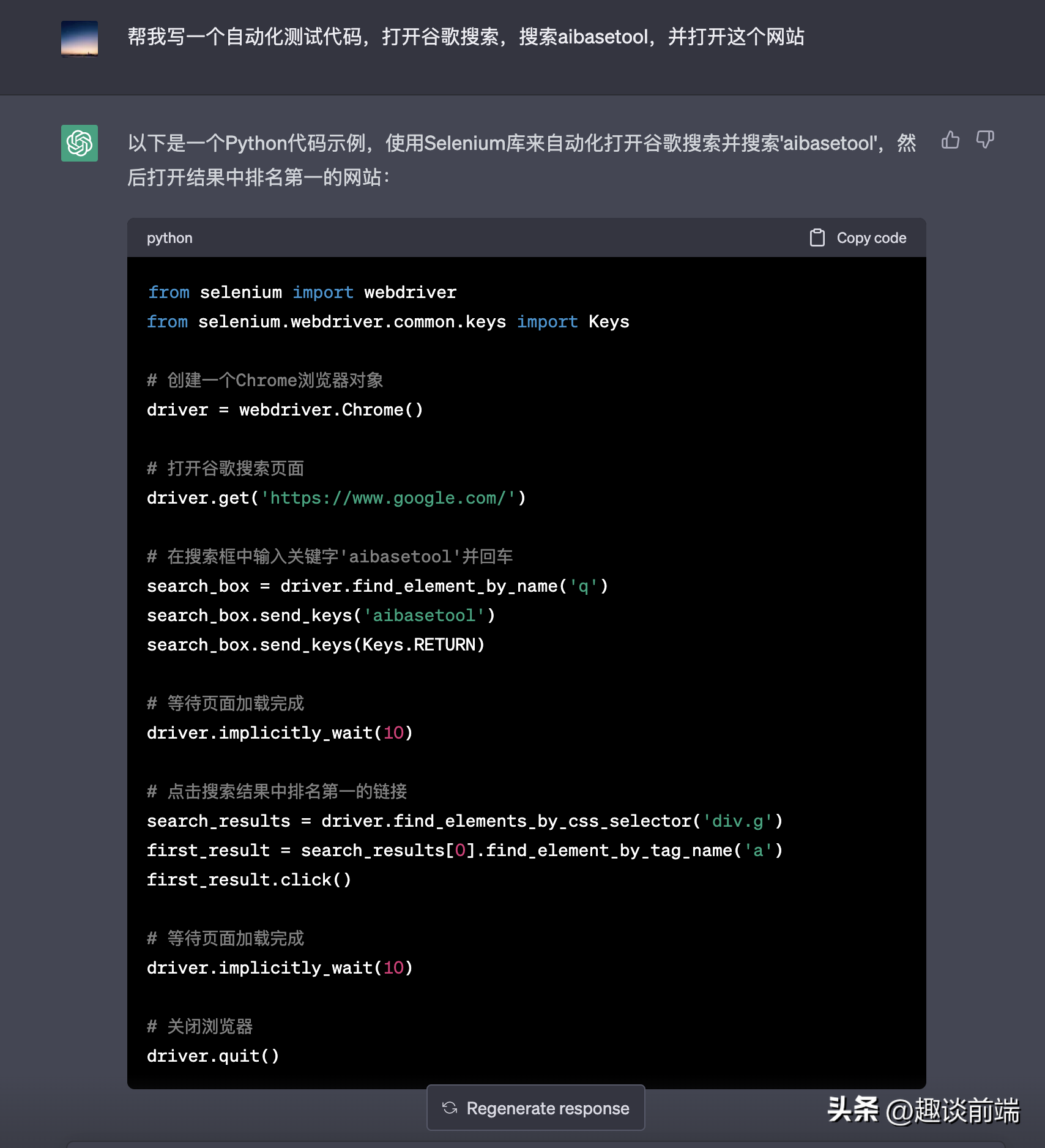
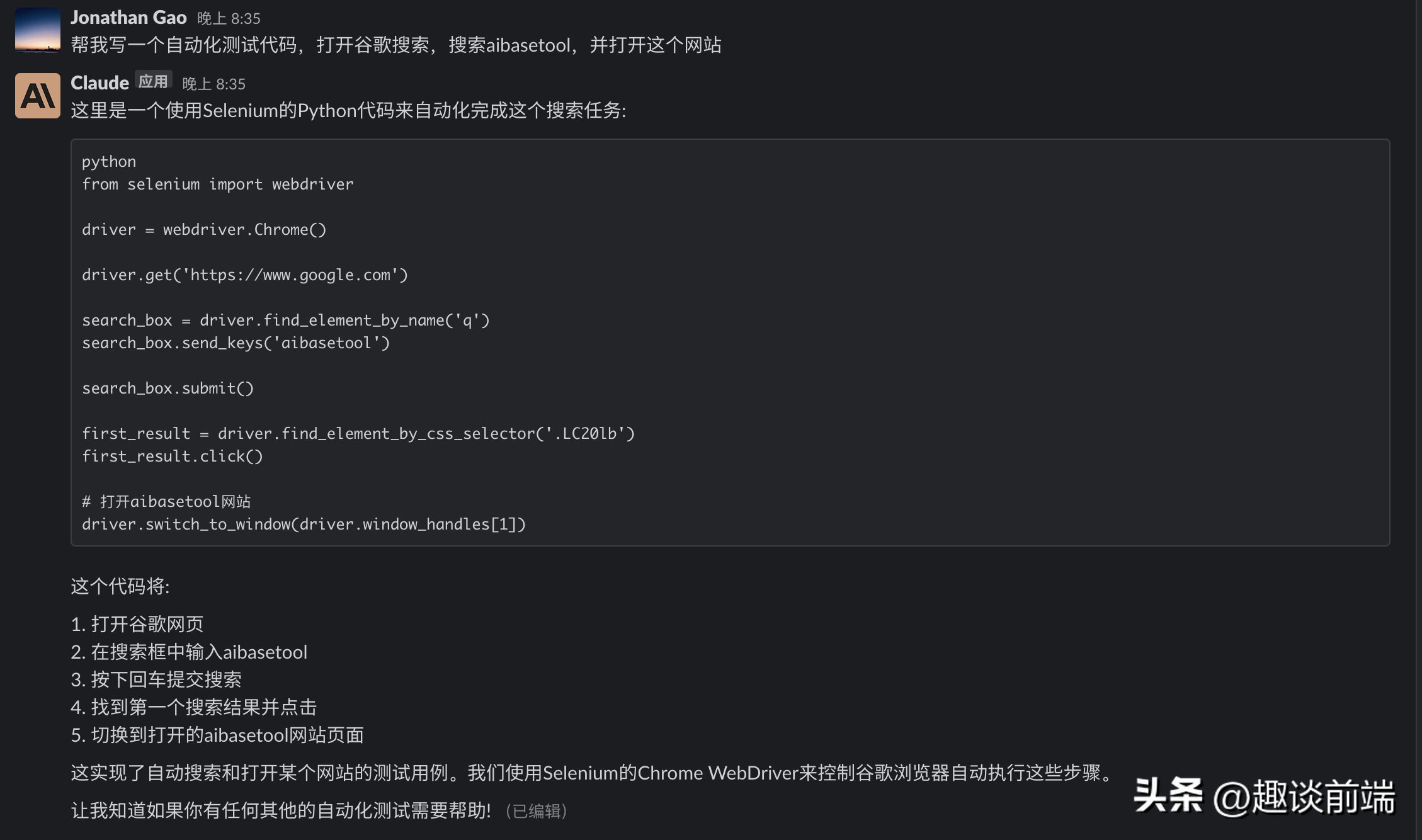
安卓手机如果找不到下载的安装包可进入我们aibasetool.com下载。
在人工智能高速发展的时代,一定要去掌握使用他们的方法,今天这款Claude软件可以大大方便了用户来体验、来应用人工智能的技术。
如果在使用的过程中有什么疑问请在评论区留言,也欢迎你加入我们的社区。我会定期分享更多关于Claude和人工智能的技巧和教程。与人工智能技术的交互将成为一种越来越重要的技能,Claude使这种体验更加容易和无障碍。
我衷心希望这款软件能够帮助更多人入门人工智能,并体会到人工智能带来的便利与乐趣。让我们一起探索这个令人兴奋的领域!我将竭诚为您解答,并定期更新教程内容。人工智能时代已经来临,希望Claude可以成为您在这个时代学习和成长的伙伴。让我们一起见证这一技术如何改变世界,并通过反复实践与交流,共同成长。
最后,我希望Claude不仅能成为一个有用的工具,更能成为大家学习和交流人工智能的平台。
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
“输出”是一个序列化的OpenStruct。定义标题try(:output).try(:data).try(:title)结束什么会更好?:) 最佳答案 或者只是这样:deftitleoutput.data.titlerescuenilend 关于ruby-on-rails-更好的替代方法try(:output).try(:data).try(:name)?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
Ⅰ软件测试基础一、软件测试基础理论1、软件测试的必要性所有的产品或者服务上线都需要测试2、测试的发展过程3、什么是软件测试找bug,发现缺陷4、测试的定义使用人工或自动的手段来运行或者测试某个系统的过程。目的在于检测它是否满足规定的需求。弄清预期结果和实际结果的差别。5、测试的目的以最小的人力、物力和时间找出软件中潜在的错误和缺陷6、测试的原则28原则:20%的主要功能要重点测(eg:支付宝的支付功能,其他功能都是次要的)80%的错误存在于20%的代码中7、测试标准8、测试的基本要求功能测试性能测试安全性测试兼容性测试易用性测试外观界面测试可靠性测试二、质量模型衡量一个优秀软件的维度①功能性功
我正在使用DMOZ的listofurltopics,其中包含一些具有包含下划线的主机名的url。例如:608609TheOuterHeaven610InformationandimagegalleryofMcFarlane'sactionfiguresforTrigun,Akira,TenchiMuyoandotherJapaneseSci-Fianimations.611Top/Arts/Animation/Anime/Collectibles/Models_and_Figures/Action_Figures612虽然此url可以在网络浏览器中使用(或者至少在我的浏览器中可以使用:
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案
我在这方面尝试了很多URL,在我遇到这个特定的之前,它们似乎都很好:require'rubygems'require'nokogiri'require'open-uri'doc=Nokogiri::HTML(open("http://www.moxyst.com/fashion/men-clothing/underwear.html"))putsdoc这是结果:/Users/macbookair/.rvm/rubies/ruby-2.0.0-p481/lib/ruby/2.0.0/open-uri.rb:353:in`open_http':404NotFound(OpenURI::HT
因此,在使用Sphinx时,搜索限制为1000个结果。但是,如果will_paginate生成的结果分页链接超过1000个,请不要考虑这一点,并提供指向超过1000/per_page的页面的链接。设置最大页数或类似内容的明显方法是什么?干杯。 最佳答案 我认为最好将参数:total_entries提交给方法paginate:@posts=Post.paginate(:page=>params[:page],:per_page=>30,:total_entries=>1000)will_paginate将仅为显示1000个结果所需的页