#QQ:502440275@qq.com
#本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系
#1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg
#2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果
文件夹目录样式
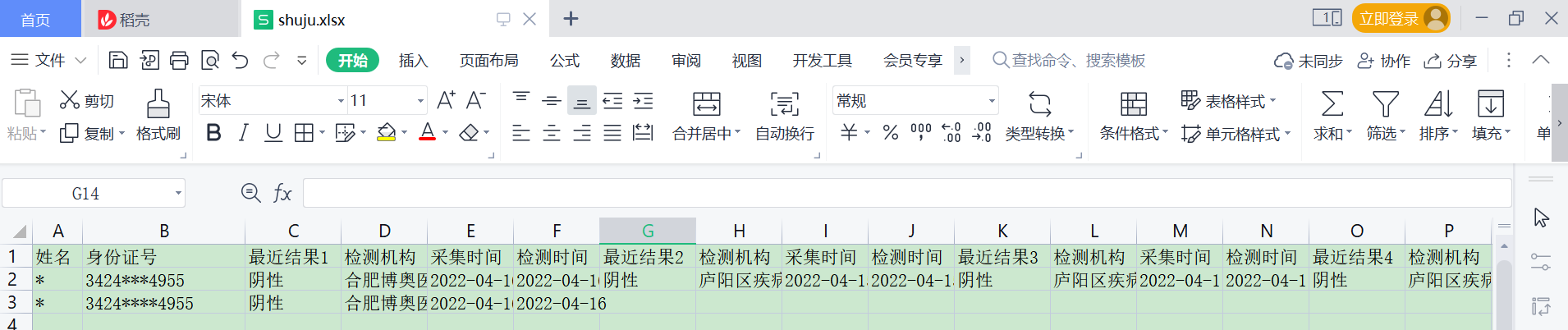
统计结果Excel样式
具体代码如下:
# @Time : 2022/4/19 22:00
# @Author : CFang
# @File : hesuan_results.py
# @Software: PyCharm
#QQ:502440275@qq.com
#本截图适合安康码截图,如需其他地区截图统计,可与我QQ或QQ邮箱联系
#1、在当前文件夹下创建imgs文件夹用于存放图片,图片格式.jpg
#2、在当前文件夹下创建“shuju.xlsx”的Excel用于存放统计结果
#获得截图结果
def get_hesuan_res(path):
#获得API的access_token
import requests
AK = '*******'#输入自己的百度智能云的AK和SK
SK = '*******'
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id='+AK+'&client_secret='+SK
response = requests.get(host)
if response:
print(response.json())
print(response.json()['access_token'])
# encoding:utf-8
#文字识别接口,可自己调整不同接口获得不同精度要求
import requests
import base64
'''
通用文字识别
'''
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
# 二进制方式打开图片文件
f = open(path, 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = response.json()['access_token']
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
# print (response.json())
# print(response.json()['words_result'])
all_res = response.json()['words_result']
return all_res
# for i in range(len(all_res)):
# print(i,all_res[i])
# 对图片识别结果的数据清洗
all_lists_deals = []
def deal_datas(all_lists):
all_lists_deal = []
if all_lists[5]['words'].split(":")[0] == "姓名":
for i in range(5, len(all_lists)):
print(i, all_lists[i]['words']) # ,all_lists_display[i]['words']
if all_lists[i]['words'] != '>' and all_lists[i]['words'] != '身份证件号码:':
all_lists_deal.append(all_lists[i]['words'])
all_lists_deal[0] = all_lists_deal[0].split(":")[1][:-1]
# print(all_lists_deal)
else:
for i in range(6, len(all_lists)):
print(i, all_lists[i]['words']) # ,all_lists_display[i]['words']
if all_lists[i]['words'] != '>':
all_lists_deal.append(all_lists[i]['words'])
all_lists_deal[0] = all_lists_deal[0].split(":")[1]
all_lists_deal[1] = all_lists_deal[1].split(":")[1]
# print(all_lists_deal)
print(all_lists_deal)
all_lists_deals.append(all_lists_deal)
#获取文件夹imgs内的所有图片
import os
def get_imlist(path):
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
img_path = get_imlist("imgs")
print(img_path)
for path in img_path:
all_lists = get_hesuan_res(path)
deal_datas(all_lists)
#保存识别清洗后的数据结果到“shuju.xlsx”表中
# -*- coding: UTF-8 -*-
from openpyxl import load_workbook
wb = load_workbook('shuju.xlsx')
ws = wb['Sheet1']
row = ws.max_row+1
for j in range(len(all_lists_deals)):
for i in range(len(all_lists_deals[j])):
if len(all_lists_deals[j][i].split(":")) == 1:
ws.cell(row+j,i+1).value = all_lists_deals[j][i]
elif all_lists_deals[j][i].split(":")[0] == "检测机构" or all_lists_deals[j][i].split(":")[0] == "身份证件号码":
ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1]
else:
ws.cell(row+j, i + 1).value = all_lists_deals[j][i].split(":")[1][:10]
wb.save('shuju.xlsx')
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht