文章目录
YOLOv7论文在上个月6号挂在了Arxiv上之后,引起了巨大轰动,短短一个月的时间,Github上就有了4.3k个Star。

从论文题目可以看出来,YOLOv7又是一个集大成者的杰作;从Github源码可以看出, 整体结构与YOLOv5极其相似,因此有YOLOov5基础的小伙伴可以无脑上手v7。
另外来看下v7的两位大牛作者,一作是 Chien-Yao Wang,近几年一直耕耘在目标检测领域,尤其是YOLO系列,代表作:YOLOv7、YOLOR、ScaledYOLOv4、CSPNet等。二作是 Alexey Bochkovskiy,就是在20年Joseph Redmon宣布退出CV领域后扛起YOLO系列大旗并发布YOLOv4的那位大神。
YOLOv7完整网络架构以及各组件的详细解析可以移步至:【YOLOv7_0.1】网络结构与源码解析,这里从另一个角度来了解YOLOov7的网络架构:
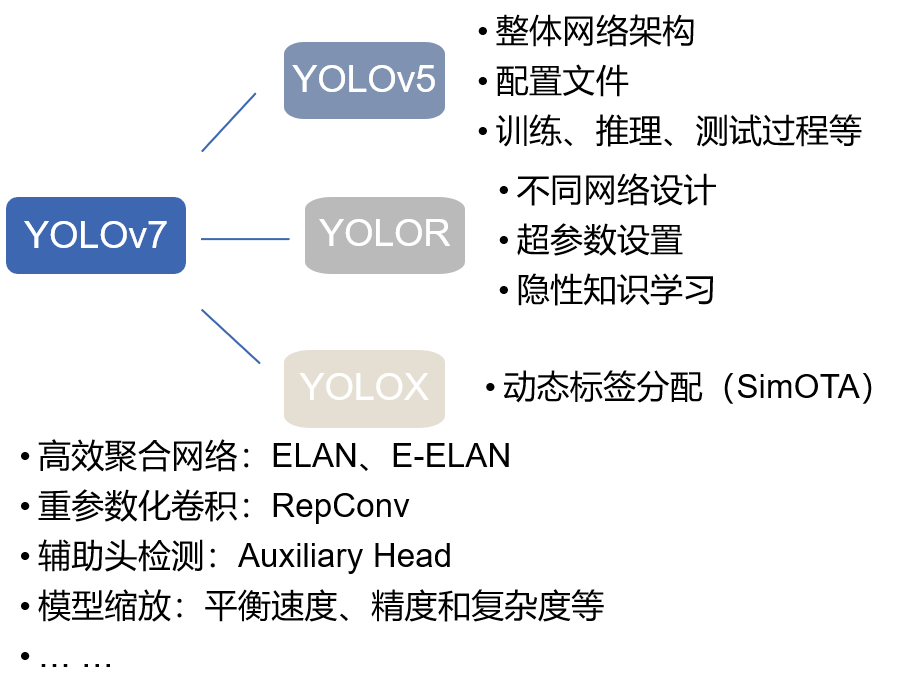
上面这张图是根据我目前的理解,对YOLOv7的整体结构进行的拆分,可能会有不正确的地方,欢迎各位小伙伴前来交流~
可以很清楚的看到,YOLOv7大部分继承自YOLOv5,包括整体网络架构、配置文件的设置和训练、推理、验证过程等等,基本上熟悉v5就可以无脑上手v7了;此外,v7也有不少继承自YOLOR,毕竟是同一个作者前后年的工作,包括不同网络的设计、超参数设置以及隐性知识学习的加入;还有就是在正样本匹配时仿照了YOLOX的SimOTA策略。
除了这些在已有YOLO版本中的算法之外,YOLOv7还包括了近几年最新的trick:高效聚合网络(目前论文还未接收)、重参数化卷积、辅助头检测、模型缩放等等,因此学习YOLOv7还是非常有价值的。
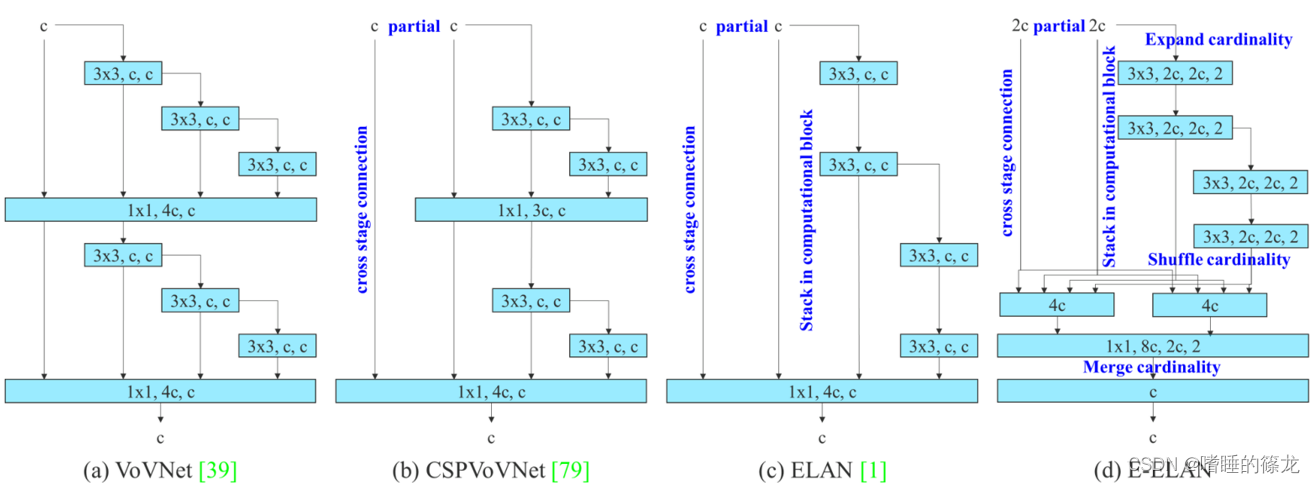
图a和图b是之前常用的特征提取网络,图c则是YOLOv7主要用到的ELAN网络,虽然有引文,但是并没有任何详细资料来学习,对此,作者是这么说的:
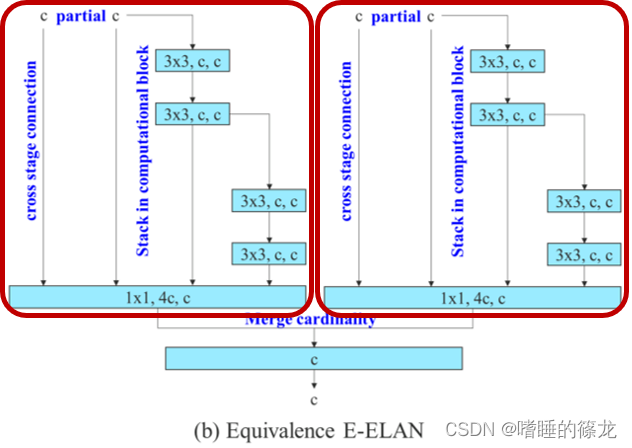
好叭,那就再等等。图d是对ELAN的改进,其等效网络就是下面这个,也就是两个ELAN(红框里)的Concat,作者的解释是:
For E-ELAN architecture, since our edge device do not support group convolution and shuffle operation, we are forced to implement it as an equivalence architecture.
重参数化的作用:在保证模型性能的条件下加速网络,主要是对卷积+BN层以及不同卷积进行融合,合并为一个卷积模块。
下面给出了卷积+BN融合的公式化过程,红色表示卷积参数(权重和偏置),蓝色是BN参数( m m m是输入均值, v v v是输入标准差, γ \gamma γ和 β \beta β是两个可学习的参数),最终经过一系列化简,融合成了一个卷积:
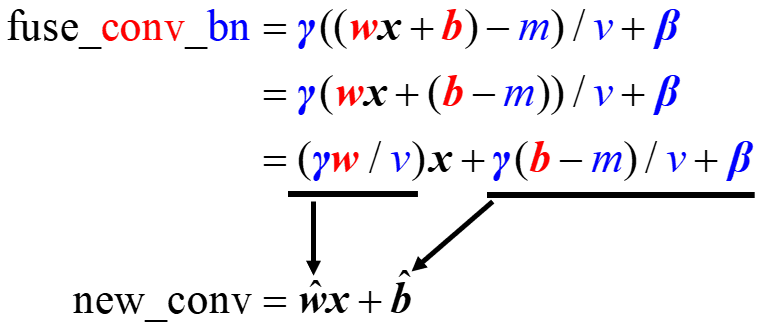
在YOLOv7中,除了网络最后使用RepConv重参数化卷积之外,作者也提到了其他三处使用重参数化技巧的地方:
we perform reparameterization on conv-bn, repconv, orepa, and yolor.
对应model/yolo.py中model类的fuse函数(这里):

YOLOv7中,将head部分的浅层特征提取出来作为Aux head(辅助头),深层特征也就是网络的最终输出作为Lead head(引导头),如图b所示。
在计算损失时:

以training/yolov7-w6.yaml为例,最后detect模块的前四层为lead head,后四层为aux head,在推理时,只取前四层作为detect层的输出:

YOLOv7的标签分配策略(正样本筛选),集成了YOLOv5和YOLOX两者的精华:

概括:
不足:
我已经从我的命令行中获得了一切,所以我可以运行rubymyfile并且它可以正常工作。但是当我尝试从sublime中运行它时,我得到了undefinedmethod`require_relative'formain:Object有人知道我的sublime设置中缺少什么吗?我正在使用OSX并安装了rvm。 最佳答案 或者,您可以只使用“require”,它应该可以正常工作。我认为“require_relative”仅适用于ruby1.9+ 关于ruby-主要:Objectwhenrun
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
一、什么是MQTT协议MessageQueuingTelemetryTransport:消息队列遥测传输协议。是一种基于客户端-服务端的发布/订阅模式。与HTTP一样,基于TCP/IP协议之上的通讯协议,提供有序、无损、双向连接,由IBM(蓝色巨人)发布。原理:(1)MQTT协议身份和消息格式有三种身份:发布者(Publish)、代理(Broker)(服务器)、订阅者(Subscribe)。其中,消息的发布者和订阅者都是客户端,消息代理是服务器,消息发布者可以同时是订阅者。MQTT传输的消息分为:主题(Topic)和负载(payload)两部分Topic,可以理解为消息的类型,订阅者订阅(Su
TCL脚本语言简介•TCL(ToolCommandLanguage)是一种解释执行的脚本语言(ScriptingLanguage),它提供了通用的编程能力:支持变量、过程和控制结构;同时TCL还拥有一个功能强大的固有的核心命令集。TCL经常被用于快速原型开发,脚本编程,GUI和测试等方面。•实际上包含了两个部分:一个语言和一个库。首先,Tcl是一种简单的脚本语言,主要使用于发布命令给一些互交程序如文本编辑器、调试器和shell。由于TCL的解释器是用C\C++语言的过程库实现的,因此在某种意义上我们又可以把TCL看作C库,这个库中有丰富的用于扩展TCL命令的C\C++过程和函数,所以,Tcl是
关闭。这个问题需要更多focused.它目前不接受答案。想改进这个问题吗?更新问题,使其只关注一个问题editingthispost.关闭9年前。Improvethisquestion我现在是java专业人士,我喜欢使用ruby。这两种语言有什么相似之处吗?主要区别是什么?因为两者都是面向对象的。
我正在使用Rails并且非常随机地遇到连接池错误,它不专门针对任何单个端点。我可以在大约70%的时间内命中端点而不会出现此错误。数据库是在谷歌云上运行的PostgreSQL。这是我遇到的错误的主要内容:#/usr/local/bundle/gems/activerecord-5.1.5/lib/active_record/connection_handling.rb:112:in`connection_pool'ActiveRecord::ConnectionNotEstablished(Noconnectionpoolwith'primary'found.):gem文件:source
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
文章目录概念索引相关操作创建索引更新副本查看索引删除索引索引的打开与关闭收缩索引索引别名查询索引别名文档相关操作新建文档查询文档更新文档删除文档映射相关操作查询文档映射创建静态映射创建索引并添加映射概念es中有三个概念要清楚,分别为索引、映射和文档(不用死记硬背,大概有个印象就可以)索引可理解为MySQL数据库;映射可理解为MySQL的表结构;文档可理解为MySQL表中的每行数据静态映射和动态映射上面已经介绍了,映射可理解为MySQL的表结构,在MySQL中,向表中插入数据是需要先创建表结构的;但在es中不必这样,可以直接插入文档,es可以根据插入的文档(数据),动态的创建映射(表结构),这就
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使