MySQL优化器可以生成Explain执行计划,我们可以通过执行计划查看是否使用了索引,使用了哪种索引?
但是到底为什么会使用这个索引,我们却无从得知。
好在MySQL提供了一个好用的工具 — optimizer trace(优化器追踪),可以帮助我们查看优化器生成执行计划的整个过程,以及做出的各种决策,包括访问表的方法、各种开销计算、各种转换等。
show variables like '%optimizer_trace%';

输出参数详解:
optimizer_trace 主配置,enabled的on表示开启,off表示关闭,one_line表示是否展示成一行
optimizer_trace_features 表示优化器的可选特性,包括贪心搜索、范围优化等
optimizer_trace_limit 表示优化器追踪最大显示数目,默认是1条
optimizer_trace_max_mem_size 表示优化器追踪占用的最大容量
optimizer_trace_offset 表示显示的第一个优化器追踪的偏移量
optimizer trace默认是关闭,我们可以使用命令手动开启:
SET optimizer_trace="enabled=on";

先造点数据备用,创建一张用户表:
CREATE TABLE `user` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL COMMENT '姓名',
`gender` tinyint NOT NULL COMMENT '性别',
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_gender_name` (`gender`,`name`)
) ENGINE=InnoDB COMMENT='用户表';
创建了两个索引,分别是(name)和(gender,name)。
执行一条SQL,看到底用到了哪个索引:
select * from user where gender=0 and name='一灯';

跟期望的一致,优先使用了(gender,name)的联合索引,因为where条件中刚好有gender和name两个字段。
我们把这条SQL传参换一下试试:
select * from user where gender=0 and name='张三';

这次竟然用了(name)上面的索引,同一条SQL因为传参不同,而使用了不同的索引。
到这里,使用现有工具,我们已经无法排查分析,MySQL优化器为什么使用了(name)上的索引,而没有使用(gender,name)上的联合索引。
只能请今天的主角 —optimizer trace(优化器追踪)出场了。
使用optimizer trace查看优化器的选择过程:
SELECT * FROM information_schema.OPTIMIZER_TRACE;

输出结果共有4列:
QUERY 表示我们执行的查询语句
TRACE 优化器生成执行计划的过程(重点关注)
MISSING_BYTES_BEYOND_MAX_MEM_SIZE 优化过程其余的信息会被显示在这一列
INSUFFICIENT_PRIVILEGES 表示是否有权限查看优化过程,0是,1否
接下来我们看一下TRACE列的内容,里面的数据很多,我们重点分析一下range_scan_alternatives结果列,这个结果列展示了索引选择的过程。
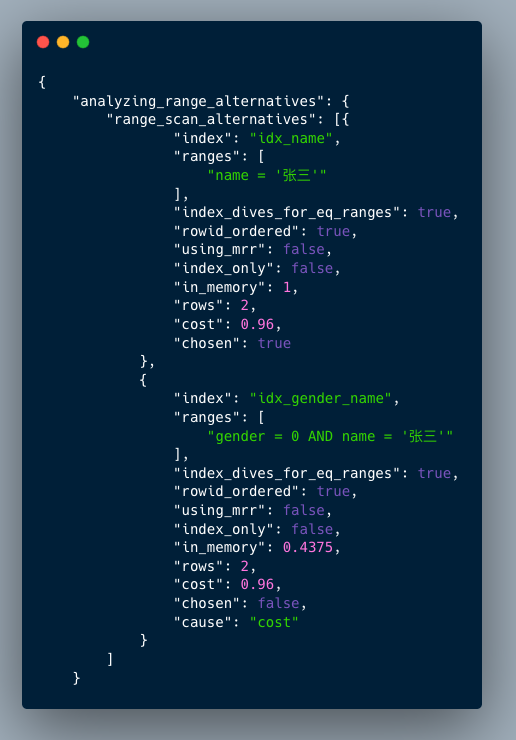
输出结果字段含义:
index 索引名称
ranges 查询范围
index_dives_for_eq_ranges 是否用到索引潜水的优化逻辑
rowid_ordered 是否按主键排序
using_mrr 是否使用mrr
index_only 是否使用了覆盖索引
in_memory 使用内存大小
rows 预估扫描行数
cost 预估成本大小,值越小越好
chosen 是否被选择
cause 没有被选择的原因,cost表示成本过高
从输出结果中,可以看到优化器最终选择了使用(name)索引,而(gender,name)索引因为成本过高没有被使用。
再也不用担心找不到MySQL用错索引的原因,赶紧用起来吧!
文章持续更新,可以微信搜一搜「 一灯架构 」第一时间阅读更多技术干货。
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin
我正在使用Ruby解决一些ProjectEuler问题,特别是这里我要讨论的问题25(Fibonacci数列中包含1000位数字的第一项的索引是多少?)。起初,我使用的是Ruby2.2.3,我将问题编码为:number=3a=1b=2whileb.to_s.length但后来我发现2.4.2版本有一个名为digits的方法,这正是我需要的。我转换为代码:whileb.digits.length当我比较这两种方法时,digits慢得多。时间./025/problem025.rb0.13s用户0.02s系统80%cpu0.190总计./025/problem025.rb2.19s用户0.0
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在寻找一个用ruby演示计时器的在线示例,并发现了下面的代码。它按预期工作,但这个简单的程序使用30Mo内存(如Windows任务管理器中所示)和太多CPU有意义吗?非常感谢deftime_blockstart_time=Time.nowThread.new{yield}Time.now-start_timeenddefrepeat_every(seconds)whiletruedotime_spent=time_block{yield}#Tohandle-vesleepinteravalsleep(seconds-time_spent)iftime_spent
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
