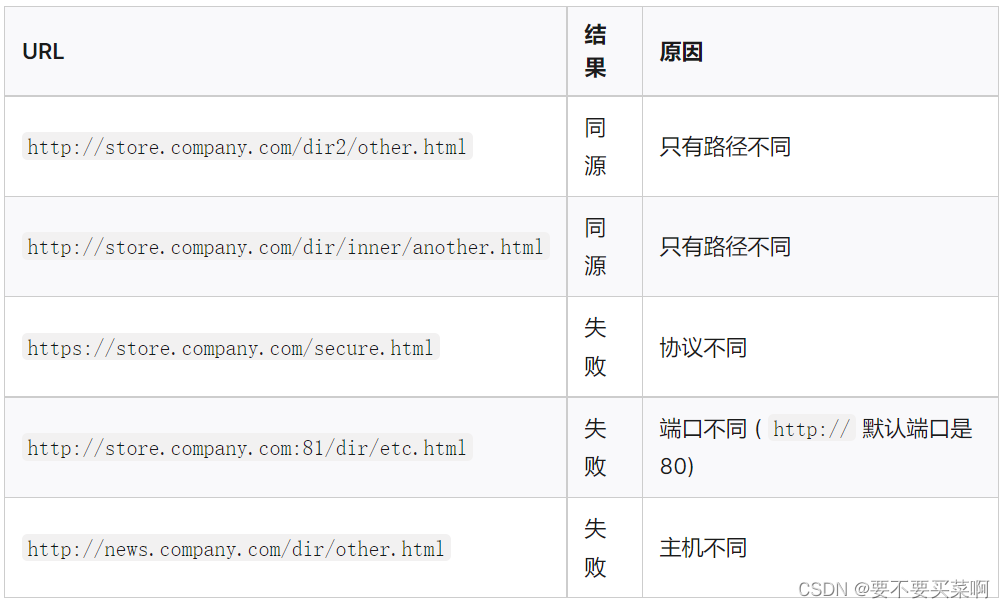
同源策略是一个重要的安全策略,它用于限制一个origin的文档或它加载的脚本如何能与另一个源的资源进行交互。能够减少恶意文档,减少可能被攻击媒介。 如果两个URL的协议、域名、端口号都相同,就称这两个URL同源。
浏览器默认两个不同的源之间是可以互相访问资源和操作DOM的。两个不同的源之间若是想要访问资源或者操作DOM,那么会有一套基础的安全策略的制约,我们把这称为同源策略。它的存在可以保护用户隐私信息,防止身份伪造。
Web内容的源用于访问它的URL的协议(方案)、主机(域名)、和端口号。只有当协议、主机、域名都匹配时,两个对象才具有相同的起源,即Origin相同。
(如果把html看做是一个文档,那么端口号是其存放位置的根目录,主机是其上级目录,协议是其上上级目录,同源策略就可以理解为同一根目录下的文件才可以访问、操作)
在浏览器中, <script> 、<img>、<iframe>、<link>等标签都可以跨域加载,而不受浏览器的同源策略的限制, 这些带src属性的标签每次加载的时候,实际上都是浏览器发起一次GET请求, 不同于普通请求(XMLHTTPRequest)的是,通过src属性加载的资源,浏览器限制了JavaScript的权限,使其不能读写src加载返回的内容。
浏览器同源策略中,除了上述的几个标签可以跨域加载外,其他出现跨域请求时,请求会发到跨域的服务器,并且会服务器会返回数据,只不过浏览器"拒收"返回的数据
浏览器的同源策略目的是为了保护用户的信息安全,为了防止恶意网站窃取用户在浏览器上的数据,如果不是同源的站点,将不能进行如下操作 :
jsonp(JSON with Padding),是JSON的一种 “使用模式”,可以让网页跨域读取数据,其本质是利用script标签的开放策略,浏览器传递callback参数到后端,后端返回数据时会将callback参数作为函数名来包裹数据,从而浏览器就可以跨域请求数据并制定函数来自动处理返回数据。
jsonp跨域实现流程:

var script = document.createElement('script');
script.type = 'text/javascript';
// 传参callback给后端,后端返回时执行这个在前端定义的回调函数
script.src = 'http://a.qq.com/index.php?callback=handleCallback';
document.head.appendChild(script);
// 回调执行函数
function handleCallback(res) {
alert(JSON.stringify(res));
}
JSON 与 JS 对象 与 JSONP 的区别_要不要买菜啊的博客-CSDN博客
跨域资源共享(Cross-origin resource sharing,CORS)是一个 W3C标准,允许浏览器向跨域服务器发送请求,从而克服了ajax只能同源使用的限制。CORS需要浏览器和服务器同时支持。目前,所有主流浏览器(IE10及以上)使用XMLHttpRequest对象都可支持该功能,IE8和IE9需要使用XDomainRequest对象进行兼容。
CORS整个通信过程都是浏览器自动完成,浏览器一旦发现ajax请求跨源,就会自动在头信息中增加Origin字段,用来说明本次请求来自哪个源(协议+域名+端口)。因此,实现CORS通信的关键是服务器,需要服务器配置Access-Control-Allow-Origin头信息。当CORS请求需要携带cookie时,需要服务端配置Access-Control-Allow-Credentials头信息,前端也需要设置withCredentials。
浏览器将CORS请求分成两类:简单请求和非简单请求。简单请求需要满足以下两大条件:
请求方法是以下三种方法之一:HEAD、GET、POST。
HTTP的头信息不超出以下几种字段:Accept、Accept-Language、Content-Language、Last-Event-ID、Content-Type:只限于三个值application/x-www-form-urlencoded、multipart/form-data、text/plain。

CORS简单请求跨域代码示例:
// IE8/9需用XDomainRequest兼容
var xhr = new XMLHttpRequest();
// 前端设置是否带cookie
xhr.withCredentials = true;
xhr.open('post', 'http://a.qq.com/index.php', true);
xhr.setRequestHeader('Content-Type', 'application/x-www-form-urlencoded');
xhr.send('user=saramliu');
xhr.onreadystatechange = function() {
if (xhr.readyState == 4 && xhr.status == 200) {
alert(xhr.responseText);
}
};
目前主流浏览器(IE10及以上)都支持CORS,但IE8和IE9需要使用XDomainRequest对象进行兼容,IE7及以下浏览器不支持。
服务器代理,顾名思义即在发送跨域请求时,后端进行代理中转请求至服务器端,然后将获取的数据返回给前端。一般适用于以下场景:
针对IE7及以下浏览器摒弃Flash插件的情况,配置代理接口与前端页面同源,并中转目标服务器接口,则ajax请求不存在跨域问题。
外网前端页面无法访问内网接口,配置代理接口允许前端页面访问,并中转内网接口,则外网前端页面可以跨域访问内网接口。
服务器代理实现流程: 服务器代理优点:
服务器代理优点:
在不使用Flash的情况下,兼容不支持CORS的浏览器跨域请求。
服务器代理缺点:
后端需要一定的改造工作量。
2、前端跨域通信解决方案
前端跨域通信是指浏览器中两个不符合同源策略的前端页面进行通信。那么,这种跨域问题,如何进行解决呢。本文总结以下四种常见解决方案:
此方案仅适用于主域相同,子域不同的前端通信跨域场景。如下图所示,两个不符合同源策略的页面http://a.qq.com/a.html和http://b.qq.com/b.html,其主域相同为qq.com。a.html嵌套b.html,再都通过js设置document.domain为主域qq.com,则两个页面满足了同源策略,从而实现了跨域通信。
<!-- A页面 http://a.qq.com/a.html -->
<iframe id="iframe" src="http://b.qq.com/b.html"></iframe>
<script>
document.domain = "qq.com";
var windowB = document.getElementById("iframe").contentWindow;
alert("B页面的user变量:" + windowB.user);
</script>
<!-- B页面 http://b.qq.com/b.html -->
<script>
document.domain = "qq.com";
var user = "saramliu";
</script>
document.domain+iframe方案优点:
document.domain+iframe方案缺点:
当两个不符合同源策略且主域不同的页面需要进行跨域通信时,可以利用url的hash值改变但不刷新页面的特性,实现简单的前端跨域通信。
通常情况下http://a.qq.com/a.html内嵌不同域的http://b.qq1.com/b.html时,受浏览器安全机制限制,a.html 可以修改b.html的hash值,但b.html不被允许修改不同域的父窗体a.html的hash值。因此,此方案需要一个与a.html同源的http://a.qq.com/c.html来进行中转,此方案实现流程如下图所示: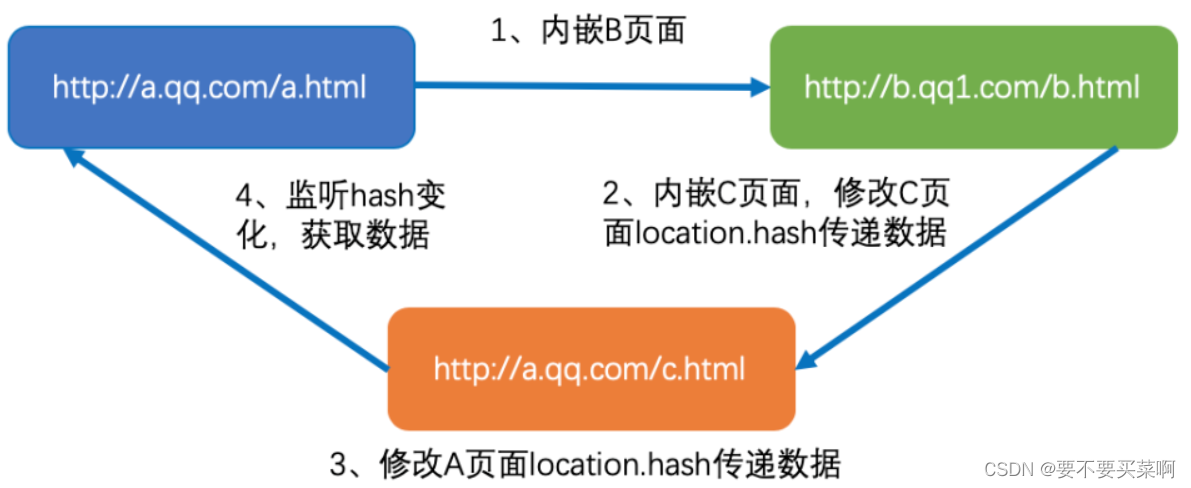
<!-- A页面 http://a.qq.com/a.html -->
<iframe id="iframe" src="http://b.qq1.com/b.html"></iframe>
<script>
// 监听c.html传来的hash值
window.onhashchange = function () {
alert("B页面传递数据:" + location.hash.substring(1));
};
</script><!-- B页面 http://b.qq1.com/b.html -->
<iframe id="iframe" src="http://a.qq.com/c.html"></iframe>
<script>
// 向c.html传递hash值
var iframe = document.getElementById('iframe');
setTimeout(function() {
iframe.src = iframe.src + '#user=saramliu';
}, 1000);
</script><!-- C页面 http://a.qq.com/c.html -->
<script>
// 监听b.html传来的hash值
window.onhashchange = function () {
// 操作同域a.html的hash值,传递数据
window.parent.parent.location.hash = window.location.hash.substring(1);
};
</script>
补充:window.parent - Web API 接口参考 | MDN (mozilla.org)
window.name属性的独特之处在于,name值在不同页面(甚至不同域名)加载后依旧存在,并且可以支持非常长的name值(2MB)。
如下图所示,http://a.qq.com/a.html内嵌不同域的http://b.qq1.com/b.html。b.html有数据要传递时,把数据附加到window.name上,然后跳转到一个和a.html同域的http://a.qq.com/c.html。由于a.html和c.html满足同源策略,a.html可以获取c.html的window.name,从而实现了跨域通信。
<!-- A页面 http://a.qq.com/a.html -->
<iframe id="iframe" src="http://b.qq1.com/b.html"></iframe>
<script>
var state = 0;
var iframe = document.getElementById('iframe');
iframe.onload = function() {
if (state === 1) {
// 第2次onload成功后,读取同域window.name中数据
alert(iframe.contentWindow.name);
} else if (state === 0) {
// 第1次onload成功后
state = 1;
}
};
</script>
<!-- B页面 http://b.qq1.com/b.html -->
<script>
window.name = "这里是B页面!";
window.location = "http://a.qq.com/c.html";
</script>
postMessage是HTML5 XMLHttpRequest Level2中的API,且是为数不多可以跨域操作的window属性之一,它通常用于解决以下方面的问题:
postMessage是一种安全的跨域通信方法。当a.html获得对b.html的window对象后,a.html调用postMessage方法分发一个MessageEvent消息。b.html通过监听message事件即可获取a.html传递的数据,从而实现跨域通信。postMessage实现流程如下图所示:
postMessage方法的语法如下:
otherWindow.postMessage(message、targetOrigin、[transfer])
目标窗口的window对象,比如iframe的contentWindow属性、执行window.open返回的window对象等。
将要发送给其他window的数据。
指定哪些窗口能接收到消息事件,其值可以是字符串*(表示无限制)或者是“协议+主机+端口号”。
是一串和message同时传递的Transferable对象,这些对象的所有权将被转移给消息的接收方,而发送一方将不再保有所有权。
postMessage方案代码示例:
<!-- A页面 http://a.qq.com/a.html -->
<iframe id="iframe" src="http://b.qq1.com/b.html"></iframe>
<script>
var iframe = document.getElementById('iframe');
iframe.onload = function() {
var data = {meesage: "这里是A页面发的消息"};
var url = "http://b.qq1.com/b.html";
// 向B页面发送消息
iframe.contentWindow.postMessage(JSON.stringify(data), url);
};
window.addEventListener("message", function(e) {
alert("B页面发来消息:" + JSON.parse(e.data));
});
</script><!-- B页面 http://b.qq1.com/b.html -->
<script>
window.addEventListener("message", function(e) {
alert("A页面发来消息:" + JSON.parse(e.data));
var data = {meesage: "这里是B页面发的消息"};
var url = "http://a.qq.com/a.html";
window.parent.postMessage(JSON.stringify(data), url);
}, false);
</script>postMessage方案优点:
postMessage方案缺点:
我想使用两种不同的protect_from_forgery策略构建一个Rails应用程序:一种用于Web应用程序,一种用于API。在我的应用程序Controller中,我有这行代码:protect_from_forgerywith::exception为了防止CSRF攻击,它工作得很好。在我的API命名空间中,我创建了一个继承self的应用程序Controller的api_controller,它是API命名空间中所有其他Controller的父类,我将上面的代码更改为:protect_from_forgery:null_session.遗憾的是,我在尝试发出POST请求时遇到错误:“
HTTP缓存是指浏览器或者代理服务器将已经请求过的资源保存到本地,以便下次请求时能够直接从缓存中获取资源,从而减少网络请求次数,提高网页的加载速度和用户体验。缓存分为强缓存和协商缓存两种模式。一.强缓存强缓存是指浏览器直接从本地缓存中获取资源,而不需要向web服务器发出网络请求。这是因为浏览器在第一次请求资源时,服务器会在响应头中添加相关缓存的响应头,以表明该资源的缓存策略。常见的强缓存响应头如下所述:Cache-ControlCache-Control响应头是用于控制强制缓存和协商缓存的缓存策略。该响应头中的指令如下:max-age:指定该资源在本地缓存的最长有效时间,以秒为单位。例如:Ca
我正在开发一个将XML发布到某些网络服务的小型应用程序。这是使用Net::HTTP::Post::Post完成的。但是,服务提供商建议使用重新连接。类似于:第一个请求失败->2秒后重试第二个请求失败->5秒后重试第三次请求失败->10秒后重试...这样做的好方法是什么?简单地在循环中运行以下代码,捕获异常并在一定时间后再次运行?或者还有其他聪明的方法吗?也许Net包甚至有一些我不知道的内置功能?url=URI.parse("http://some.host")request=Net::HTTP::Post.new(url.path)request.body=xmlrequest.con
我有这个原始文本:________________________________________________________________________________________________________________________________PosCarCompetitor/TeamDriverVehicleCapCLLapsRace.TimeFastest...Lap16JasonClementsJasonClementsBMWM33200109:48.571030:57.3228*242DavidSkillenderDavidSkillenderHo
现在已经为此奋斗了一段时间,不确定为什么它不起作用。要点是希望将Devise与LDAP结合使用。除了身份验证外,我不需要做任何事情,所以除了自定义策略外,我不需要使用任何东西。我根据https://github.com/plataformatec/devise/wiki/How-To:-Authenticate-via-LDAP创建了一个据我所知,一切都应该正常工作,除了每当我尝试运行服务器(或rake路由)时,我得到一个NameErrorlib/devise/models.rb:88:in`const_get':uninitializedconstantDevise::Models:
我正在使用Grape和Rails创建RESTAPI。我有基本的架构,我正在寻找“清理”东西的地方。其中一个地方是错误处理/处理。我目前正在为整个API修复root.rb(GRAPE::API基类)文件中的错误。我格式化它们,然后通过rack_response发回错误。一切正常,但root.rb文件变得有点臃肿,所有错误都被修复,其中一些有需要完成的特殊解析。我想知道是否有人制定了一个好的错误处理策略,以便可以将其移出到它自己的模块中,并使root.rb(GRAPE::API基类)相当精简。我很想创建一个错误处理模块并为每种类型的错误定义方法,例如...moduleAPImoduleEr
我正在开发一个利用twitteroauth的应用程序,但在试图弄清楚如何测试twitteroauth时遇到了障碍。特别是尝试使用Cucumber和Webrat/Selenium来测试功能——注册/登录过程中的某些步骤在用户是否授予对应用程序的oauth访问权限等方面表现不同。有没有人在他们的RubyonRailsCucumber功能(或与此相关的任何其他测试框架)中成功模拟或stub部分或全部TwitterOAuth系统?任何帮助将不胜感激。 最佳答案 OP已经一年多了,但我最近发现这篇关于使用TwitterAuth和Cucumbe
目前我正在处理Rails4项目,现在我必须链接/连接另一个应用程序(不是sso,而是用于访问API),比如example.com。(注意example.com使用三足式oauth安全架构)搜索后发现必须要实现omniouth策略。为此我引用了this关联。根据Strategy-Contribution-Guide我能够完成设置和请求阶段,您可以在此处找到我的示例代码。require'multi_json'require'omniauth/strategies/oauth2'require'uri'moduleOmniAuthmoduleStrategiesclassMyAppStrat
我更新到第3章,似乎不再支持set:deploy_via,:copy。在releaseannoucement有一个视频链接用于复制当前返回404的复制策略。我使用了:copy策略,因为服务器无法访问git或访问存储库,因为它在防火墙后面。用v3复制此功能的最佳方法是什么? 最佳答案 我遇到了同样的问题,并在capistranogooglegroup上发布了类似的问题。参见此处:https://groups.google.com/forum/#!topic/capistrano/BRa4Vj1_mEo简短回答:编写您自己的rake任务
问题有没有可以保持的最佳值(value),这样我才能赢得尽可能多的比赛?如果是这样,那是什么?编辑:是否可以为给定的限制计算出确切的获胜概率,而与对手的所作所为无关?(自大学以来,我还没有做过概率和统计)。我有兴趣将其作为与模拟结果进行对比的答案。编辑:修复了我算法中的错误,更新了结果表。背景我一直在玩改进的二十一点游戏,其中对标准规则进行了一些相当烦人的规则调整。我已将与标准二十一点规则不同的规则斜体化,并为不熟悉的人添加了二十一点规则。修改二十一点规则正是两个人类玩家(经销商无关)每个玩家面朝下发两张牌双方玩家_ever_都不知道对手纸牌的_any_的值在_both_完成手牌之前,