文章目录
任务目标:生成高质量的音频驱动的面部视频序列合成,实现音频到视觉人脸的跨模态映射。
应用方向:数字人、聊天机器人、虚拟会议等
针对这个任务,目前已经有了一些解决方案。早期的方案基于专业的建模师以及动作捕捉系统,近些年深度学习的发展演化出了一系列基于GAN的方案来实现audio2face的领域迁移。但是这类任务目标的核心难点在于如何把音频信号和脸部变形(表情+嘴唇)联系起来。因此,绝大多数方法使用了人脸的一些中间表示,这些中间表示通常例如一些显式建模的3D人脸(🏷这里注意一定是显示的,区别于NeRF的implicit modeling),人脸的表情回归系数或者2D的人脸landmarks点集。而往往这类方法一点中间表示的信息有miss或者偏差,那么最后的audio-face之间也会存在明确的语义不匹配。这些方法的另外一个局限性在于大多数模型都是静态的头部以及动态的嘴部视频渲染,这类方法对姿态的操作以及背景替换而言都比较糟糕。
为了解决这些问题,我们尝试转向利用NeRF来对人脸的外观的变化进行建模。我们提出了AD-NeRF,利用辐射场来避免在处理跨模态的映射问题中引入中间表示。得益于神经辐射场,我们可以对脸部细节组件如牙齿和头发进行细致化地建模,对比基于GAN的方法能取得更好的图像质量。此外,体积表示提供了一种自然的方式来自由调整动画扬声器的整体变形,这是传统的二维图像生成方法无法实现的。此外,我们的方法考虑了头部姿态和上身运动,能够产生极为真实的Talking Head视频。
具体来看,我们的方法以视频序列,包括目标说话人的视频和音轨作为输入。基于DeepSpeech提取的音频特征,结合人脸解析的maps,旨在构建一个audio-conditional的隐式函数(🏷简单理解以下,实际上就是以音频信息作为条件,以此条件给到NeRF完成视频序列的生成。便于理解的话可以假象cGAN做Domain Translation)。由于头部部分的运动与头部以下的上半身的运动差异,我们进一步将NeRF分为两个部分来进行渲染,一个是前景的脸,另一个是前景的躯干。通过这种方式,我们可以从收集到的训练数据中生成自然的说话头序列。
言而总之,工作贡献主要有以下几个方面:
我们提出了一种音频驱动的Talking Head的方法,该方法直接将音频特征映射到动态NeRF,没有任何可能导致信息丢失的中间模式。消融研究表明,这种直接映射方法能够较好地通过现有视频的训练,产生精确的唇动结果。
我们将人体人像场景的神经辐射场分解为两个分支,分别对头部和躯干变形进行建模,这有助于生成更自然的头部说话结果。
利用AD-NeRF,可以实现Talking Head视频的编辑,如姿态操作和背景替换,这在虚拟现实的应用中有明确的潜在价值。
音频驱动面部动画的目标是用任意输入的语音序列同步再现一个特定的人的人脸表情。这了技术基本分为两类,基于模型的方法和数据驱动的方法。前者需要一些专门的工作去完成音频语义和嘴唇运动的关系建模,例如音素-viseme映射。这种方法除了在电影、游戏以及高精度的数字人中,在其他的常规场景中应用并不太容易。随着DNN的兴起,基于数据驱动的方法开始浮现。早期的方法是尝试利用训练数据来拟合静态头像的嘴部运动。随后的改进点在于
根据应用的目标和技术,可将其分为两类:基于模型的方法和数据驱动的方法。基于模型的方法[39,12,60]需要专门的工作来建立音频语义和嘴唇运动之间的关系,如音素-人脸映射[14]。因此,除了电影、游戏等先进的数字形象之外,它们在一般应用中都不方便。随着深度学习技术的兴起,许多数据驱动的方法被提出来生成逼真的说话头结果。早期的方法试图合成嘴唇的运动来满足静止面部图像的训练数据。随后的改进便是尝试对完整的图像进行渲染(🏷不在局限于脸部)。另一套前面提到的方案是利用中间表示的方法,基于3D人脸重构以及GAN,很多工作尝试去通过利用音频信息去估计3DMM或者人脸的landmark点来实现驱动目标。但是这类方法往往需要很多数据(🏷这一点我个人不是很认可,one-shot,few-shot的方案也有呀)。
这个方向是指将人脸的姿态和表情从源视频迁移到目标(🏷这里的目标应该值得是图像)的过程。
这里插一句,其实总的来看就是两种方案:
- 音频驱动图像,图像的人脸的表情、嘴唇根据音频特征进行运动。
- 视频驱动图像,图像中的人脸参照视频中的人脸进行运动(src视频人脸怎么动,tgt图像人脸怎么动)。
这项任务的大多数方法依赖于基于模型的面部表现捕捉。一个方案是用RGB-D摄像机跟踪动态3D人脸,然后将面部表情从源actor转移到目标。后续的方案也尝试着使用RGB图像来实现相同的功能。也有利用GAN来进行渲染,可以实现逼真的皮肤纹理。Kim等人分析了人脸表情风格这么个概念,并展示了其对基于视频的配音的重要性(🏷这个work讲的我有点迷幻…)。
Neural scene representation是利用神经网络来表示场景的形状和外观。神经场景表示网络(SRNs)是由Sitzmann等人首先提出的,其中对象的几何形状和外观被表示为一个可以在空间点上采样的神经网络(🏷这句话看起来比较难理解,其实就是在讲NeRF的概念,物体的形态和颜色等信息可以通过MLP进行建模,输入是空间中任意一个观察点位置,输出的对象的一些表征信息例如Signed Distance Field之类的)。从去年开始,神经辐射场(NeRF)在神经渲染和神经重建任务中受到了广泛关注。三维物体的形状和外观的潜在隐式表示可以转化为体积射线采样结果。后续工作扩展了这一思想,使用in-the-wild训练数据,包括appearance embedding(🏷源自论文: Nerf in the wild),引入可变形的NeRF来表示non-rigidly的物体运动,并在不预先计算相机参数的情况下优化NeRF。
这里我就不列具体论文名字的引用了,感兴趣的可以参考以下原文。
头部以及身体的神经渲染已经引起了非常多的关注。基于最近的隐式神经场景表示,Wang等人提出了一种合成的3D场景表示,用于学习高质量的upper body动态NeRF。Raj等人在NeRF中利用pixel-aligned特征,将模型泛化到非训练集数据。Gao等人提出了一个元学习框架,可以实现通过单张人像输入完成NeRF的估计。Gafni等人提出了动态神经辐射场用于动态人脸建模。Peng等人整合了视频帧的视角观察信息,从而能够利用稀疏的多视角视频,实现人体的进行新视角图像生成。
整体框架如下图所示。
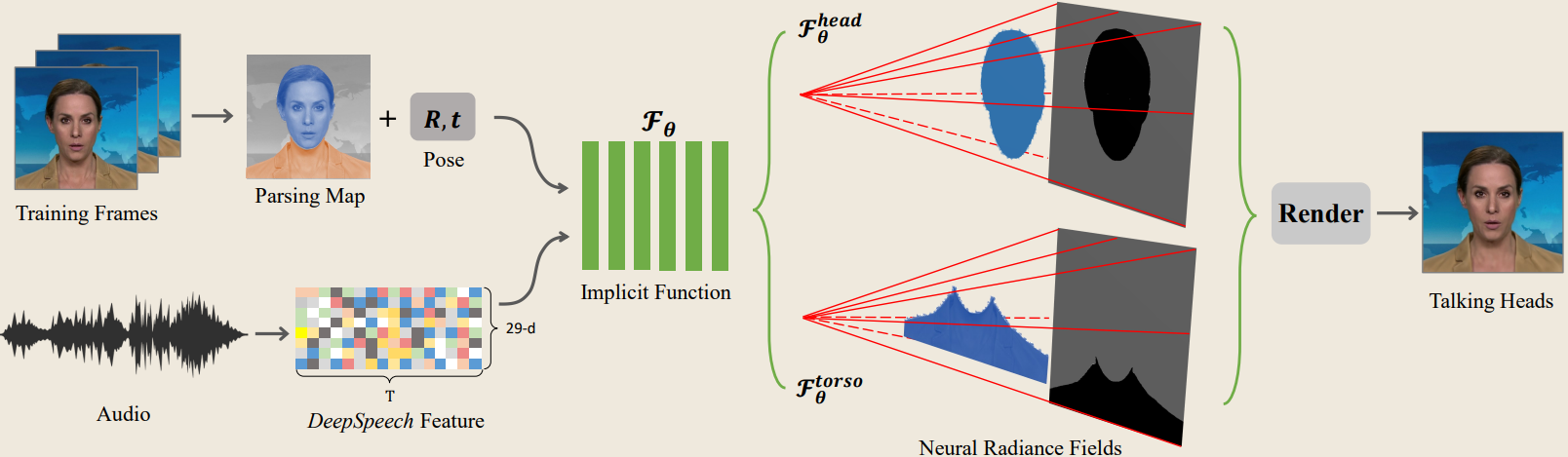
在标准神经辐射场场景表示的基础上,受Gafni等人在facial animation上采用动态神经辐射场的启发,我们利用额外的音频编码作为输入,构建一个条件隐式函数,提出了一个说话头的条件辐射场。除了观察方向
d
\mathbf{d}
d和3D位置
x
\mathbf{x}
x外,音频
a
\mathbf{a}
a的语义特征将作为隐式函数
F
θ
\mathcal{F}_{\theta}
Fθ的另一个输入。在实际应用中,
F
θ
\mathcal{F}_{\theta}
Fθ是由多层感知器(MLP)实现的。将所有的输入向量
(
a
,
d
,
x
)
(\mathbf{a}, \mathbf{d}, \mathbf{x})
(a,d,x)拼接起来,网络将沿散射光线估计颜色值
c
\mathbf{c}
c以及密度
σ
\mathbf{\sigma}
σ。完整的函数定义可以看作为:
F
θ
:
(
a
,
d
,
x
)
→
(
c
,
σ
)
.
\mathcal{F}_\theta : (\mathbf{a}, \mathbf{d}, \mathbf{x}) \rightarrow (\mathbf{c},\sigma).
Fθ:(a,d,x)→(c,σ).
为了从声音信号中提取有语义意义的信息,我们使用流行的DeepSpeech模型,对每个20ms的音频片段生成一个29维的特征编码。在我们的实现中,为了消除原始输入的噪声信号,几个连续的音频特征会被拼接起来送入一个时间卷积网络。具体来看,我们使用16个相邻的音频特征编码 a ∈ R 16 × 29 \mathbf{a} \in \mathbb{R}^{16\times29} a∈R16×29来表示音频形态的当前状态(❓ current state of audio modality 没看明白)。使用音频特征来代替表情回归系数或是face landmarks这种中间编码状态,有利于减轻中间网络的训练成本(🏷这里个人理解实际就是减少了从landmark或者表情回归系数到实际人脸表情运动的转换),同时减少audio-visual信号之间潜在的语义不匹配问题。
根据上述隐式模型
F
θ
\mathcal{F}_\theta
Fθ预测的颜色
c
\mathbf{c}
c和密度
σ
\sigma
σ,我们可以采用volume rendering将采样的密度和RGB值沿每个像素投射的射线进行累积,计算出图像渲染结果。与NeRF类似,摄像机射线
r
(
t
)
=
o
+
t
d
\mathbf{r}(t) = \mathbf{o} + t\mathbf{d}
r(t)=o+td,摄像机中心为
o
\mathbf{o}
o,观看方向
d
\mathbf{d}
d,从
t
n
t_n
tn和远端
t
f
t_f
tf的期望颜色
C
\mathcal{C}
C被计算为:
C
(
r
;
θ
,
Π
,
a
)
=
∫
t
n
t
f
σ
θ
(
r
(
t
)
)
⋅
c
θ
(
r
(
t
)
,
d
)
⋅
T
(
t
)
d
t
,
\mathcal{C}(\mathbf{r} ; \theta, \Pi, \mathbf{a})=\int_{t_{n}}^{t_{f}} \sigma_{\theta}(\mathbf{r}(t)) \cdot \mathbf{c}_{\theta}(\mathbf{r}(t), \mathbf{d}) \cdot T(t) d t,
C(r;θ,Π,a)=∫tntfσθ(r(t))⋅cθ(r(t),d)⋅T(t)dt,
其中
c
θ
(
⋅
)
\mathbf{c}_\theta(\centerdot)
cθ(⋅)以及
σ
θ
(
⋅
)
\sigma_\theta(\centerdot)
σθ(⋅)是
F
θ
\mathcal{F}_\theta
Fθ的输出,
T
(
t
)
T(t)
T(t)是沿着光线传播方向从
t
n
t_n
tn到
t
t
t的累计透光率:
T
(
t
)
=
exp
(
−
∫
t
n
t
σ
(
r
(
s
)
)
d
s
)
T(t)=\exp \left(-\int_{t_{n}}^{t} \sigma(\mathbf{r}(s)) d s\right)
T(t)=exp(−∫tntσ(r(s))ds)
其中
Π
=
{
R
,
t
}
\Pi = \{R, t\}
Π={R,t}是人脸的刚体姿态参数,通过旋转矩阵
R
∈
R
3
×
3
R \in \mathbb{R}^{3\times3}
R∈R3×3以及一个转换矩阵
t
∈
R
3
×
1
t \in \mathbb{R}^{3\times 1}
t∈R3×1进行表示。其中
Π
\Pi
Π这个参数可以被用于将一个采样点转换到canonical空间中。注意在网络训练阶段我们只使用了head pose信息而不是任何的3D人脸形态。我们采用了两阶段拼接的方式,具体来看就是首先用一个coarse网络来沿着一条光线预测物体的密度,然后在利用一个fine网络来采样更多的点(🏷应该就是原始NeRF提到的那个用来减轻计算负担的模块)
与静态背景相比,人体部位(包括头部和躯干)是动态地从一帧移动到另一帧,这也是为什么需要在渲染过程中考虑头部姿势。因此,将相机空间中的deformed点转换到canonical空间来进行辐射场训练是十分必要的。Gafni等人尝试通过预测出来的密度对前景和背景进行解耦来处理头部的运动状态。简单来看,即是通过前景物体散射(🏷原文是dispatched)出来的密度来判断前景背景,高密度光线来预测人体的部位,忽略低密度的背景图像。然而,将躯干区域转化到canonical空间存在一些模糊性。由于头部部分的运动与躯干部分的运动通常不一致,且姿态参数 Π \Pi Π仅用于面部形态的估计,因此对头部和躯干区域同时应用相同的刚性变换,对upper body的渲染结果并不那么让人满意。为了解决这个问题,我们用两个单独的神经辐射场来模拟这两个部分:一个用于头部部分,另一个用于躯干部分。
如下图所示,我们最初利用一种自动人脸解析方法将训练图像分为静态背景、头部和躯干三部分。我们首先训练头部部分的隐函数 F θ h e a d \mathcal{F}_\theta^{head} Fθhead。在此步骤中,我们将解析出来的头部区域作为前景,其余区域作为背景。头部姿态 Π \Pi Π应用于沿通过每个像素投射的射线的采样点。然后将 F θ h e a d \mathcal{F}_\theta^{head} Fθhead的绘制头像和静态背景加起来作为新的背景区域,将躯干部分作为前景,训练第二个隐式模型 F θ t o r s o \mathcal{F}_\theta^{torso} Fθtorso。在这个阶段,对于躯干区域实际并没有可用的姿态参数。换句话说,我们隐式地将头部姿态参数 Π \Pi Π作为额外的输入,而不是在 F θ t o r s o \mathcal{F}_\theta^{torso} Fθtorso中使用 Π \Pi Π进行显式转换。
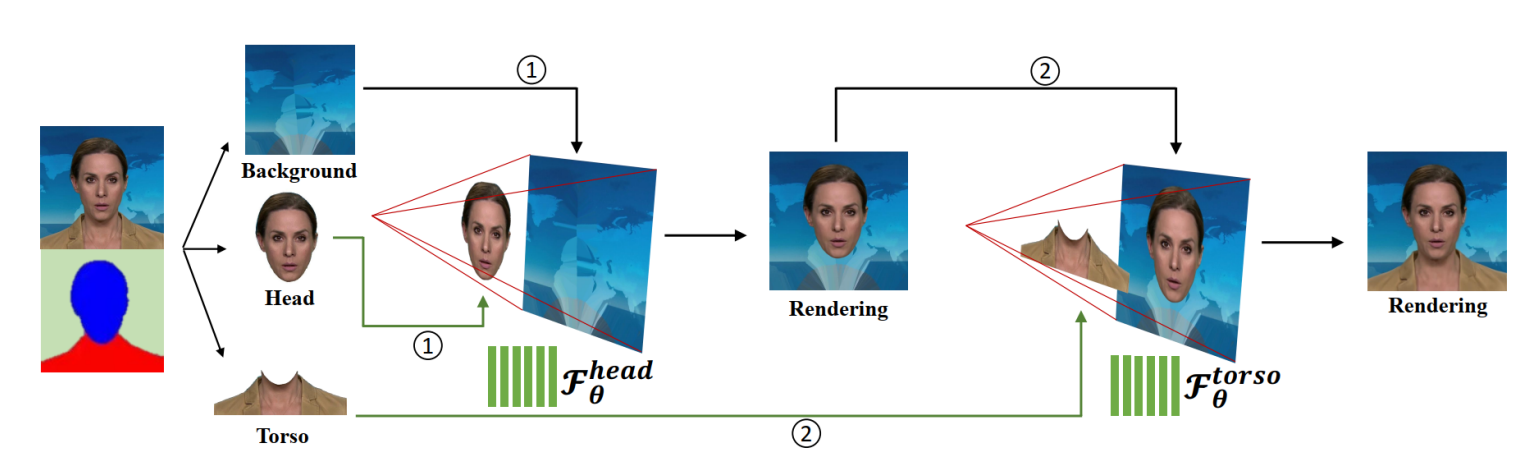
在推理阶段,头部部位模型 F θ h e a d \mathcal{F}_\theta^{head} Fθhead和躯干部位模型 F θ t o r s o \mathcal{F}_\theta^{torso} Fθtorso接受相同的输入参数,包括音频特征码 a \mathbf{a} a和姿态系数 Π \Pi Π。Volume Rendering过程,首先采用头部模型积累像素的采样密度和RGB值。然后把渲染好头部图像贴到静态背景上。然后躯干模型通过预测躯干区域的前景像素来填充缺失的躯干部分。一般来说,这种单独的神经辐射场表示设计有助于模拟不一致的头部和上身运动,并产生自然的结果。
由于两个神经辐射场都以语义音频特征和姿态系数作为输入来控制说话内容和说话头的运动,我们的方法可以通过替换音频输入和调整姿态系数来实现声音驱动和姿态操纵说话头视频的生成。此外,与Gafni等人的方法类似,我们用类似的方式实现了对前景和背景进行了解耦。通过这样的方式,我们就可以简单的替换背景来实现背景编辑。
对于目标任务需要3-5分钟25fps的视频,且假定视频背景是固定的。测试阶段允许任意的音频输入,可以是不同的人,不同的性别,甚至不同的语言。
总的来看我们有两个主要的约束项。在[3.2节](#3.2. Neural Radiance Fields for Talking Heads)我们提到用了DeepSpeech特征,window size为16,然后这16个连续的audio features将会被送入到1D卷积中去,回归出每一帧的latent code。为了保证音频信号的稳定性,我们采用Self-Attention,在连续音频编码上训练一个时间滤波器。该滤波器由具有softmax激活层的1D卷积层实现。因此,最终的音频条件输入 a \mathbf{a} a由时间滤波的latent code给出。
其次,我们必须约束了我们的方法渲染出来的图像和Ground Truth尽可能相似。让
I
r
∈
R
W
×
H
×
3
I_r \in \mathbb{R}^{W\times H\times3}
Ir∈RW×H×3作为渲染结果,标签为
I
g
∈
R
W
×
H
×
3
I_g \in \mathbb{R}^{W\times H\times3}
Ig∈RW×H×3。优化目标就可以呗定义为:
L
photo
(
θ
)
=
∑
w
=
0
W
∑
h
=
0
H
∥
I
r
(
w
,
h
)
−
I
g
(
w
,
h
)
∥
2
I
r
(
w
,
h
)
=
C
(
r
w
,
h
;
θ
,
Π
,
a
)
\begin{aligned} &\mathcal{L}_{\text {photo }}(\theta)=\sum_{w=0}^{W} \sum_{h=0}^{H}\left\|I_{r}(w, h)-I_{g}(w, h)\right\|^{2} \\ &I_{r}(w, h)=\mathcal{C}\left(r_{w, h} ; \theta, \Pi, \mathbf{a}\right) \end{aligned}
Lphoto (θ)=w=0∑Wh=0∑H∥Ir(w,h)−Ig(w,h)∥2Ir(w,h)=C(rw,h;θ,Π,a)
框架用了PyTorch,优化器用了Adam,初始学习率0.0005。两个 F \mathcal{F} F都训练 400 k 400k 400k次迭代。在每个迭代中,每一个像素着每一个像素随机采样2048条光线。用RTX 3090来训练模型,五分钟的450x450像素的视频大约耗费36个小时,每一帧大约需要12秒来渲染。
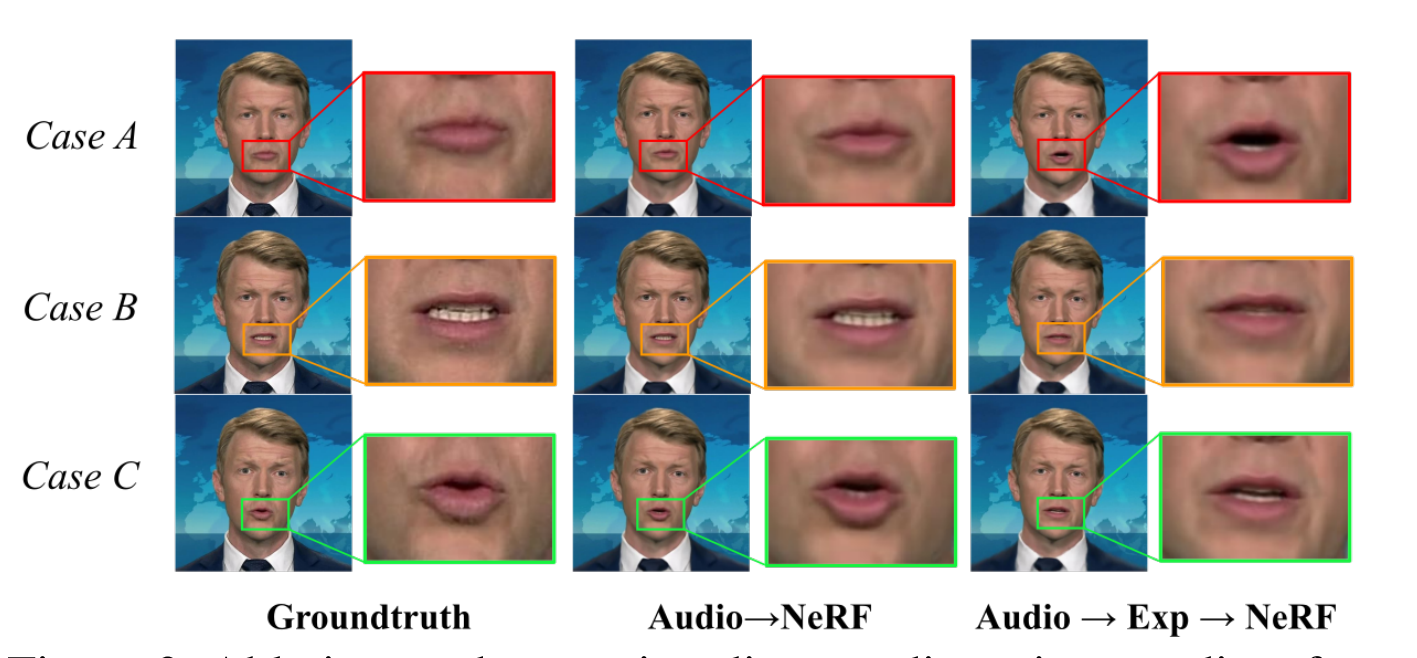
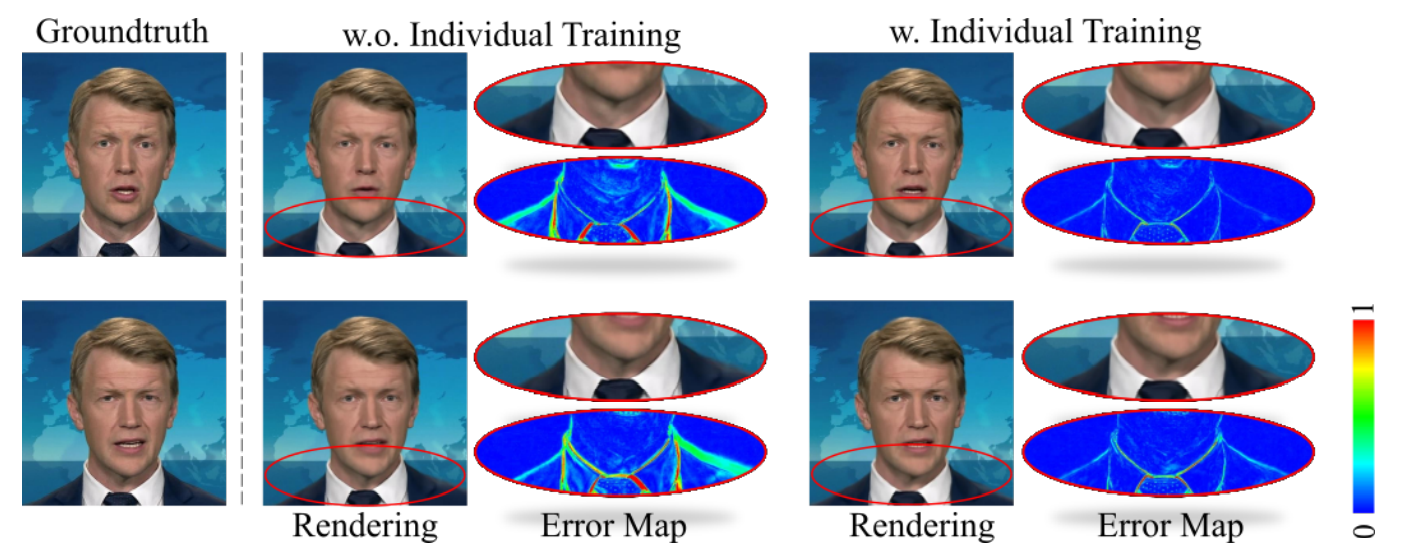
这部分后面就不看了,包含两个部分,看图理解。
Audio condition.
Individual training for head and torso region.
没啥好讲的,量化评估结果,有兴趣去原文看图看表。
最后一部分用自己的头像测试了一下~ 实际效果有限吧,全部用的默认参数,大概占了12-14G显存左右,单卡A100-80G两个模型顺序跑,每一个都跑满400k轮迭代,平均28h一个模型,推理阶段大概30s一帧。
可以说效果有限吧。
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭10年前。问题1)我想知道rubyonrails是否有功能类似于primefaces的gem。我问的原因是如果您使用primefaces(http://www.primefaces.org/showcase-labs/ui/home.jsf),开发人员无需担心javascript或jquery的东西。据我所知,JSF是一个规范,基于规范的各种可用实现,prim
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit
技术选型1,前端小程序原生MINA框架cssJavaScriptWxml2,管理后台云开发Cms内容管理系统web网页3,数据后台小程序云开发云函数云开发数据库(基于MongoDB)云存储4,人脸识别算法基于百度智能云实现人脸识别一,用户端效果图预览老规矩我们先来看效果图,如果效果图符合你的需求,就继续往下看,如果不符合你的需求,可以跳过。1-1,登录注册页可以看到登录页有注册入口,注册页如下我们的注册,需要管理员审核,审核通过后才可以正常登录使用小程序1-2,个人中心页登录成功以后,我们会进入个人中心页我们在个人中心页可以注册人脸,因为我们做人脸识别签到,需要先注册人脸才可以进行人脸比对,进
我使用的是最新版本的Chrome(32.0.1700.107)和Chrome驱动程序(V2.8)。但是当我在Ruby中使用以下代码运行示例测试时:require'selenium-webdriver'WAIT=Selenium::WebDriver::Wait.new(timeout:100)$driver=Selenium::WebDriver.for:chrome$driver.manage.window.maximize$driver.navigate.to'https://www.google.co.in'defapps_hoverele_hover=$driver.find_
按照目前的情况,这个问题不适合我们的问答形式。我们希望答案得到事实、引用或专业知识的支持,但这个问题可能会引发辩论、争论、投票或扩展讨论。如果您觉得这个问题可以改进并可能重新打开,visitthehelpcenter指导。关闭9年前。多年来,我一直在使用多种语言进行编程,并且认为自己总体上相当擅长。但是,我从未编写过任何自动化测试:没有单元测试,没有TDD,没有BDD,什么都没有。我已经尝试开始为我的项目编写适当的测试套件。我可以看到在进行任何更改后能够自动测试项目中所有代码的理论值(value)。我可以看到像RSpec和Mocha这样的测试框架应该如何使设置和运行所述测试变得相当容易
如果我在功能规范中调用url_for,它会返回一个以http://www.example.com/开头的绝对URL.Capybara会很乐意尝试加载该站点上的页面,但这与我的应用程序无关。以下是重现该问题的最少步骤:从这个Gemfile开始:source'https://rubygems.org'gem"sqlite3"gem"jquery-rails"gem"draper"gem"rails",'4.1.0'gem"therubyracer"gem"uglifier"gem"rspec-rails"gem"capybara"gem"poltergeist"gem"launchy"运行
本文章承接《基于Python的人脸识别课堂考勤系统(毕设)》,填坑上篇文章遗留的代码部分。因为项目分的模块比较多,再加上本人能力有限,所以代码过于臃肿还存在许多优化的地方。同样本篇文章也仅适用于小白,零基础人群。PS:每个文件之中代码都已经区分开来,可以对照左侧目录部分实现快速预览! 由于代码过于多我这里分成上,下两个部分来发布吧!一、主文件importosimportsysimportrandomimportpymysqlimportcv2importnumpyasnpfrommathimportpifrommatplotlibimportpyplotaspltfromPILimpor
在笔者前面有一篇文章《驱动开发:断链隐藏驱动程序自身》通过摘除驱动的链表实现了断链隐藏自身的目的,但此方法恢复时会触发PG会蓝屏,偶然间在网上找到了一个作者介绍的一种方法,觉得有必要详细分析一下他是如何实现的进程隐藏的,总体来说作者的思路是最终寻找到MiProcessLoaderEntry的入口地址,该函数的作用是将驱动信息加入链表和移除链表,运用这个函数即可动态处理驱动的添加和移除问题。MiProcessLoaderEntry(pDriverObject->DriverSection,1)添加MiProcessLoaderEntry(pDriverObject->DriverSection,
本人是音乐爱好者,从小就特别喜欢那个随着音乐跳动的方框效果,就是这个:arduino上一大把对,我忍你很久了,我就想用mpy做,全网没有,行我自己研究。果然兴趣是最好的老师,我之前有篇博客专门讲音频,有兴趣的可以回顾一下。提到可视化频谱,必然绕不开fft,大学学过这玩意,当时一心玩,老师讲的一个字都么听进去,网上教程简略扫了一下,大该就是把时域转频域的工具,我大mpy居然没有fft函数,奶奶的,先放着。音频信息如何收集?第一种傻瓜式的ADC,模拟转数字,原始粗暴,第二种,I2S库,我之前博客有讲过,数据是PCM编码。然后又去学PCM编码,一学豁然开朗,舒服,以代码为例:audio_in=I2S
我有一个适用于事件/监听器模型的应用程序。发布了几种不同类型的数据(事件),然后许多不同的事情可能需要也可能不需要对该数据(监听器)采取行动。监听器的发生没有特定的顺序,每个监听器将决定是否需要对事件采取行动。Rails应用程序有哪些工具可以完成此任务?我希望自己不必这样做(尽管我可以。这没什么大不了的。)编辑:观察者模式可能是更好的选择 最佳答案 查看EventMachine.它是一个非常流行的Ruby事件处理库。它看起来相当不错,而且很多其他库似乎都在利用它(Cramp)。这是一个很好的介绍:http://rubylearnin