
Halo,这里是Ppeua。平时主要更新C语言,C++,数据结构算法......感兴趣就关注我吧!你定不会失望。
🌈个人主页:主页链接
🌈算法专栏:专栏链接
我会一直往里填充内容哒!
🌈LeetCode专栏:专栏链接
目前在刷初级算法的LeetBook 。若每日一题当中有力所能及的题目,也会当天做完发出
🌈代码仓库:Gitee链接
🌈点击关注=收获更多优质内容🌈
目录
今天的题目相较于昨天,增加了一点难度,但不用慌,我们一起来看看吧.
还不熟悉的朋友们可以看看我的二叉树专题,相信你定能有所收获

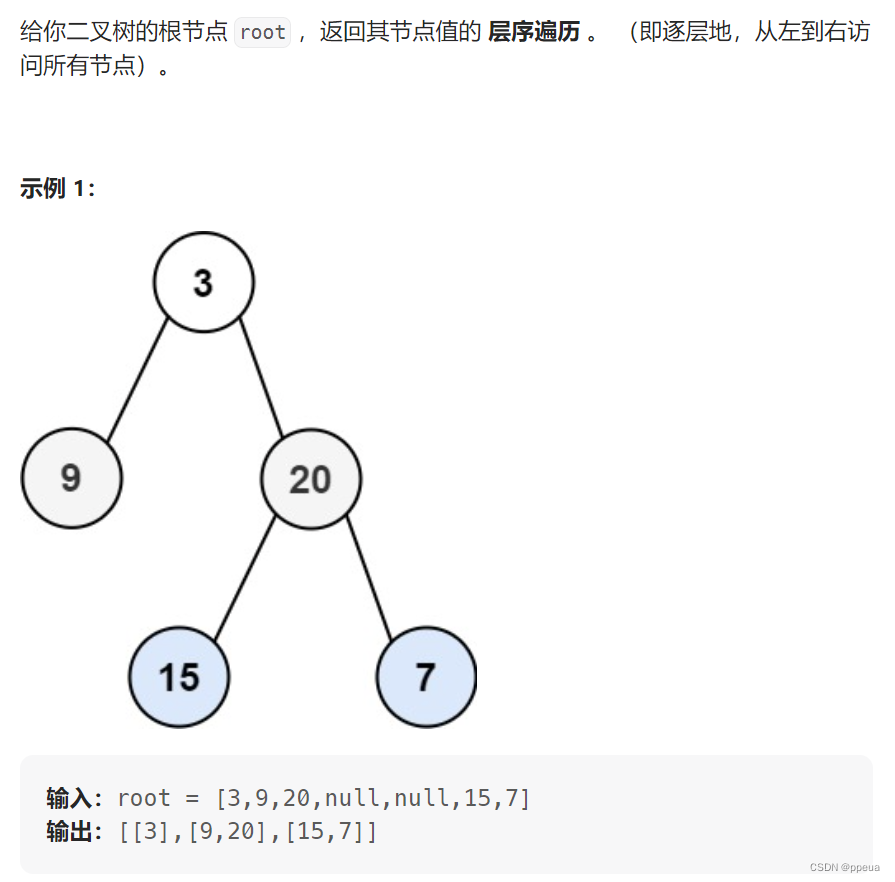
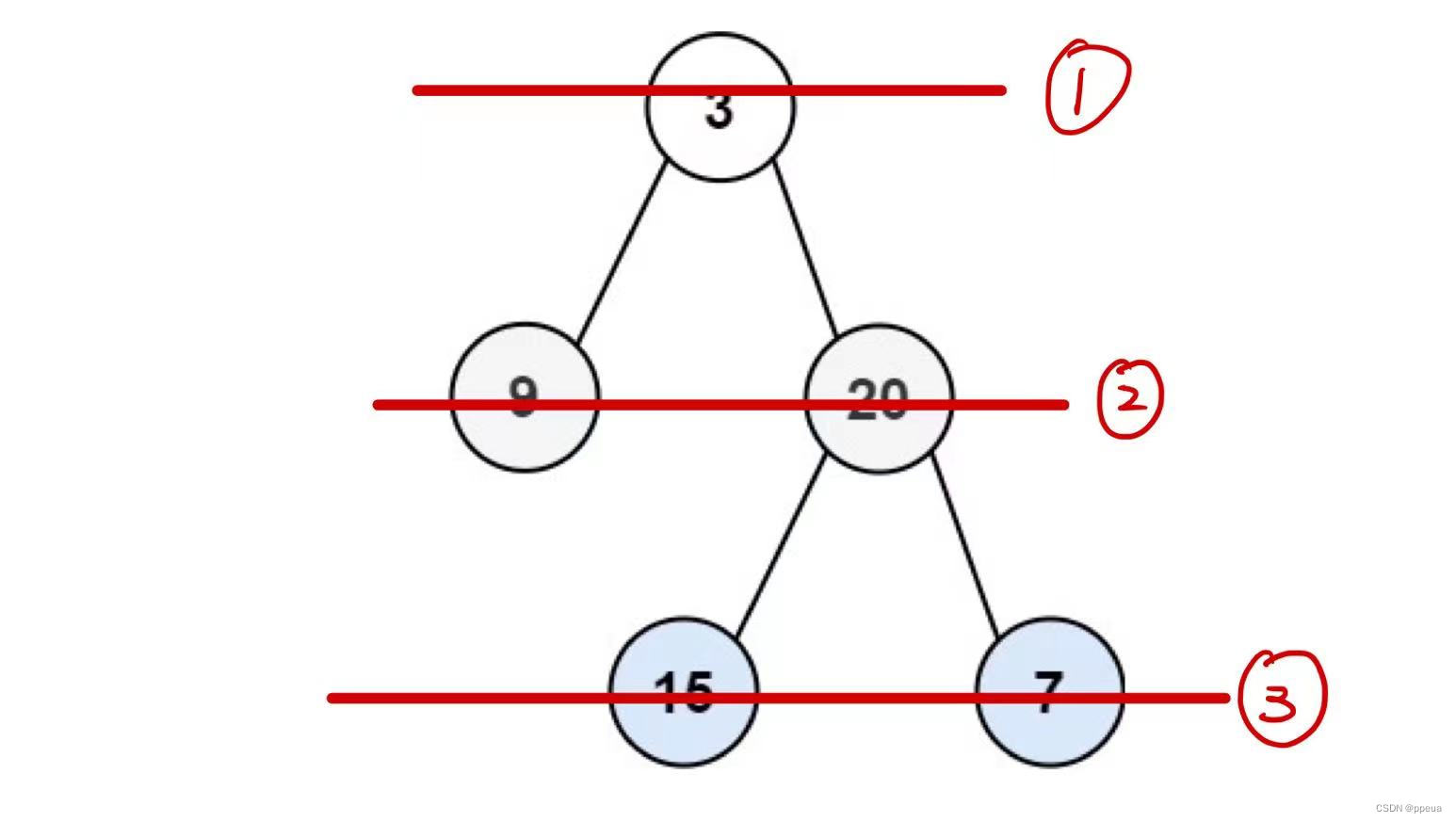
什么是层序遍历呢?相较于前中后序的遍历方式,层序遍历是一层层的去遍历,例如这一题
那如何做到一层层遍历呢?
可以先将一个节点放入队列,每当取出一个节点的时候就将其左右非空节点放入队列中.
如此循环往复,当队列为空的时候,此时就将二叉树层序遍历完了.

所以我们需要一个队列来存储树的节点,那么如何知道这一层遍历完了呢?
我们可以在取出每次开始取出节点的时候,记录下此时队列内的数据个数,此时就是该层的节点个数.(可以看看上图)
(注意队列是头先出,从尾插入)每次插入的是非空节点
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
queue<TreeNode*>tree;
vector<vector<int>>ans;
if(root==NULL)return {};
tree.push(root);
int height=0;
while(!tree.empty())
{
height=tree.size();
ans.push_back(vector<int>());
for(int i=1;i<=height;i++)
{
TreeNode*tmp=tree.front();
tree.pop();
ans.back().push_back(tmp->val);
if(tmp->left)tree.push(tmp->left);
if(tmp->right)tree.push(tmp->right);
}
}
return ans;
}
};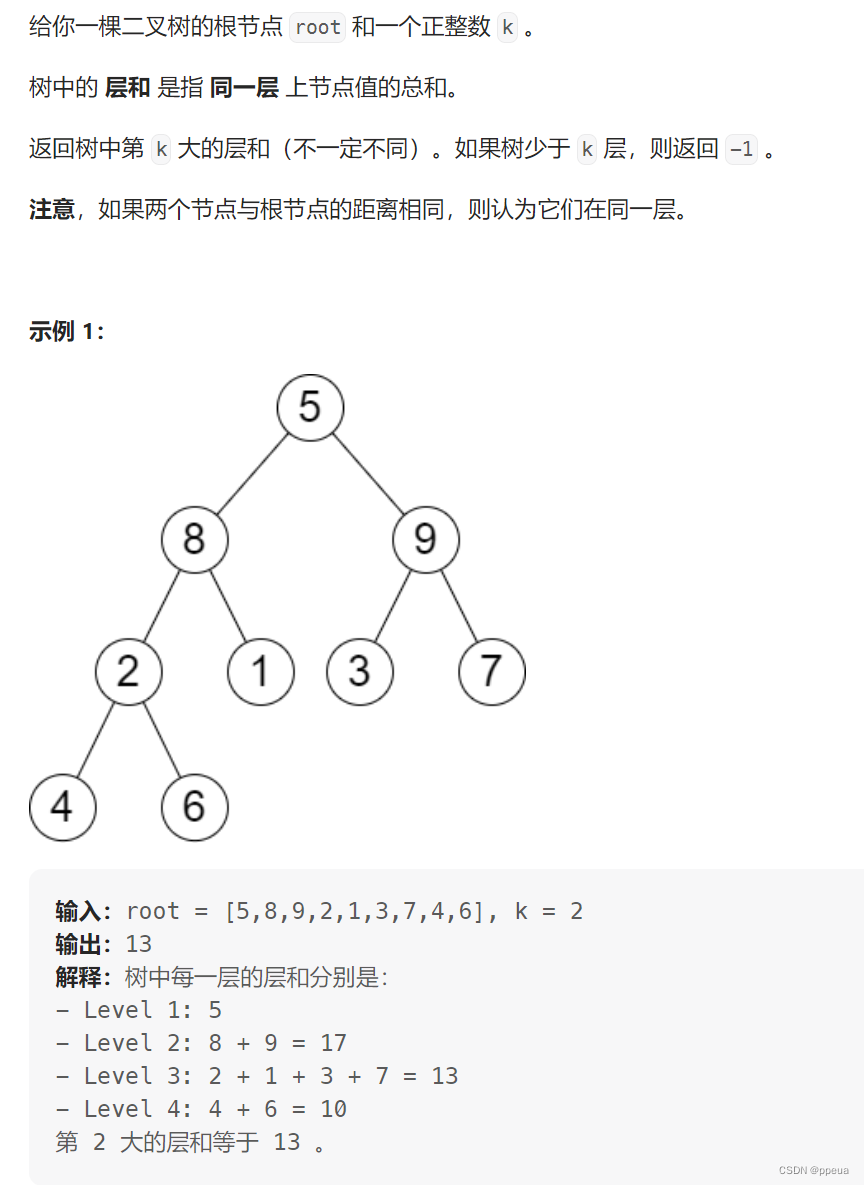
在有了上一题的基础下,这题就十分的简单啦,整体思想如下:先将每一层的值相加,然后放入容器当中,最后排个序,取出k-1层的即可.
具体的来看:层序遍历每一层的值,当遍历完这一层的时候,也就是size==0时,将这层的结果放入容器当中,最后通过lambda表达式实现从大到小排序,返回k-1层的结果(下标从0开始)
class Solution {
public:
long long kthLargestLevelSum(TreeNode* root, int k) {
queue<TreeNode*>tag;
vector<long long>res;
tag.push(root);
while(!tag.empty())
{
int size=tag.size();
int ans=0;
for(int i=1;i<=size;i++)
{
TreeNode*tmp=tag.front();
tag.pop();
ans+=tmp->val;
if(tmp->left)tag.push(tmp->left);
if(tmp->right)tag.push(tmp->right);
}
res.push_back(ans);
}
sort(res.begin(),res.end(),[](auto const &c1,auto const &c2){
return c1>=c2;
});
if(res.size()<k)return -1;
else return res[k-1];
}
};
这里有两种方法(深度优先搜索与广度优先搜索)其实也就是前序遍历与层序遍历,层序遍历这里简单提一下.与上面的大同小异就不过多赘述了:依旧是遍历出每一层最大的值,将其放入数组即可.
深度优先搜索:先看看基础情况 若当前遍历到的值等于size,则说明这一层还没有元素被放入到容器当中,此时直接放入遍历到的元素即可,若反之,则取容器中对应层的元素与现在要放入的元素比较取最大值即可.
class Solution0 {//dfs
public:
void preorder(TreeNode*root,vector<int>&res,int pi)
{
if(pi==res.size())
{
res.push_back(root->val);
}else
{
res[pi]=max(res[pi],root->val);
}
if(root->left)
{
preorder(root,res,pi+1);
}
if(root->right)
{
preorder(root, res,pi+1);
}
}
vector<int> largestValues(TreeNode* root) {
int i=0;
if(!root)return {};
vector<int>res;
preorder(root,res,0);
return res;
}
};
class Solution {
public:
vector<int> largestValues(TreeNode* root) {
queue<TreeNode*>tree;
vector<int>ans;
if(root==NULL)return {};
tree.push(root);
int height=0;
while(!tree.empty())
{
int Max=INT_MIN;
height=tree.size();
for(int i=1;i<=height;i++)
{
TreeNode*tmp=tree.front();
tree.pop();
Max=max(Max,tmp->val);
if(tmp->left)tree.push(tmp->left);
if(tmp->right)tree.push(tmp->right);
}
ans.push_back(Max);
}
return ans;
}
};🌈本篇博客的内容【你真的会二叉树了嘛? --二叉树LeetCode专题Ⅱ】已经结束。
🌈若对你有些许帮助,可以点赞、关注、评论支持下博主,你的支持将是我前进路上最大的动力。
🌈若以上内容有任何问题,欢迎在评论区指出。若对以上内容有任何不解,都可私信评论询问。
🌈诸君,山顶见!
ValidPalindromeGivenastring,determineifitisapalindrome,consideringonlyalphanumericcharactersandignoringcases. [#125]Example:"Aman,aplan,acanal:Panama"isapalindrome."raceacar"isnotapalindrome.Haveyouconsiderthatthestringmightbeempty?Thisisagoodquestiontoaskduringaninterview.Forthepurposeofthisproblem
我的问题很简单:我是否必须在使用RubyonRails的类上require'csv'?如果我打开一个railsconsole并尝试使用CSVgem它可以工作,但我必须在文件中这样做吗? 最佳答案 CSVlibrary是ruby标准库的一部分;它不是gem(即第三方库)。与所有标准库(与核心库不同)一样,csv不会由ruby解释器自动加载。所以是的,在您的应用程序中某处您确实需要要求它:irb(main):001:0>CSVNameError:uninitializedconstantCSVfrom(irb):1from/Us
我一直在尝试在Ruby中实现BinaryTree类,但我得到了stackleveltoodeep错误,尽管我似乎没有在该特定代码段中使用任何递归:1.classBinaryTree2.includeEnumerable3.4.attr_accessor:value5.6.definitialize(value=nil)7.@value=value8.@left=BinaryTree.new#stackleveltoodeephere9.@right=BinaryTree.new#andhere10.end11.12.defempty?13.(self.value==nil)?true:
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
前言我们习惯用idea编写、调试代码,在LeetCode上刷题时,如果能够在IDEA编写代码,并且做好代码管理,是一件事半功倍的事情。对于后续复习题目,做笔记也会非常便利。本文目的在于介绍LeetCodeEditor的使用,以及配置工具类,最终目录结构如下:note:放置笔记src:放置代码leetcode.editor.cn:插件LeetCodeEditor自动生成utils:自定义的工具包,可用于自动化输入测试用例,定义题目需要的类(结构体)out:运行测试时自动生成LeetCodeEditorGitHub:https://github.com/shuzijun/leetcode-edit
有人知道为什么我的rails3.0.7cli这么慢吗?当我运行railss或railsg时,他大约需要5秒才能真正执行命令...有什么建议吗?谢谢 最佳答案 更新:我正在将我的建议从rrails切换到rails-sh,因为前者支持REPL,而rrails不是用例。此外,当与ruby环境结合使用时,修补似乎确实可以提高性能变量,现在反射(reflect)在答案中。一个可能的原因可能是这个performancebuginruby每当在ruby代码中使用“require”时,它就会调用一些代码(更多详细信息here)。在使用Rai
最近火热的“数字藏品”,你真正了解吗?其实有很多人会把数字藏品跟NFT混为一谈,但其实这两者还是有差别的。数字藏品并不等同于NFT数字藏品是什么?直观来看,它可能就是一张数字化照片或视频,甚至就只是一串数字。但它却是一件对应特定作品、艺术品生成的包含着大量数字信息且拥有唯一加密信息的可以买卖交易的收藏品。NFT则是指一种基于以太坊区块链的“非同质化代币”。它在百度百科里的释义是“用于表示数字资产(包括jpg和视频剪辑形式)的唯一加密货币令牌,可以买卖”。比如已被很多人认识的比特币就是NFT的一种。NFT在元宇宙中发挥的作用是巨大的,目前正是它在支撑着元宇宙中的经济体系。数字藏品其实也是NFT的
我正在开发Rails5应用程序并使用Assets管道。它在开发模式下运行良好,但如果我尝试在生产模式下运行它,它无法正确加载图像和样式。我查了一下,发现是因为config.assets.compile=false在config/environments/production.rb中除非我将其设置为真,否则它根本不起作用。我知道实时编译不适合生产,有什么解决方案? 最佳答案 有两个与在Rails服务器中提供Assets相关的选项:Assets编译config.assets.compile=true指Assets编译。也就是说,当Rai
我从Rails收到了很多回击,因为我将User子类化为许多不同的子类。在我的应用程序中,并非所有用户都是平等的。实际上有很多模型对象,并不是每个用户类型都可以访问它们。我还需要一种方法来执行多态行为。例如,许多方法的行为会因类型而异。多态性不就是为了这个吗?但问题是,我总是被Rails拒之门外。默认值——尤其是表单提交到参数哈希的方式——似乎像非子类模型一样工作。链接和参数哈希值只是默认值真正让您厌烦的两种方式。在Rails中处理不同类型用户的复杂逻辑的“正确”方法是什么?在Java中,子类化模型是有效的——您不必为了让它按照您想要的方式工作而费尽心思。但是在Rails中,很难让子类与
Ruby真的可以用作函数式语言吗?有哪些好的教程可以教授该语言的这一方面?注意:我真的想使用并坚持使用Ruby作为我的主要语言,所以我现在对转换为YAFL(另一种函数式语言)不感兴趣。我对Ruby的功能方面相对于标准功能语言基线的表现非常感兴趣。谢谢。 最佳答案 是的......有点。Ruby缺乏合理的结构来强制实现不变性。(Object#freeze不算)不变性确实是函数式语言的基石。此外,Ruby的核心库高度面向命令式设计。它的Array和Hash类本质上都是可变的,甚至String也有使非不可变的方法(例如gsub!)。具有讽