
这个问题一般会出现在面试题里面,然后回答一些诸如轮询、WebSocket之类的答案。当然,实际开发中,也会遇到类似别人给你赞了,要通知给你的情况。这时服务端推送给Web前端(先局限在Web前端,毕竟其他端还有一些特殊方法)到底有多少种方法?它们到底是怎么实现的?
写个Demo看看吧,这样正好把主要(不清楚是否还有漏的)的方案都实现一遍。先看效果:

其中的代码也上传到GitHub了,在server-push( github.com/waiter/serv… )这里。
从上面的截图也已经可以看出,本文主要写了5种方案,那么接下来也就一个一个简单介绍一下吧。
另外,本文涉及的Demo,后端直接使用原生的Node.js开发,没有使用Koa、Express之类的,也没有使用额外的库,类似socket.io,主要是想保持最精简的状态来呈现。前端也只是在最基础的HTML上,引入了jQuery来方便做DOM操作,也引入了Bootstrap来快速实现统一的样式,而未再引入类似Vue、React之类的框架。
还有,为了触发服务端推送,这边在前端页面上加了个输入框和按钮,来将消息发送给后端,后端会缓存消息,并触发推送,后端大体代码类似:
// 缓存需要推送的信息
const datas = [];
// 各种方案触发推送时的回调
const callbacks = {};
// 注册接口回调
server.on('request', (req, res) => {
const { pathname, query } = parse(req.url, true);
// 如果发现是前端触发推送接口
if (pathname === '/api/push') {
if (query.info) {
// 缓存推送信息
datas.push(query.info);
const d = JSON.stringify([query.info]);
// 触发所有推送回调
Object.keys(callbacks).forEach(k => callbacks[k](d));
}
res.end('ok');
}
});
这是最简单直观的方法,就是每隔一段时间发起一个请求到后端询问是否有新信息。至于为什么又叫短轮询,其是相对于后续要说的长轮询来对比的。
这样前端只要设置一个setTimeout来定时请求就行:
// 缓存前端已经获取的最新id
let id = 0;
function poll() {
$.ajax({
url: '/api/polling',
data: { id },
}).done(res => {
id += res.length;
}).always(() => {
// 10s后再次请求
setTimeout(poll, 10000);
});
}
poll();
后端也是否简单,根据前端给到的id,看看有没有新消息,有就返回,没有就返回空
const id = parseInt(query.id || '0', 10) || 0;
res.writeHead(200, { 'Content-Type': 'application/json;' });
res.end(JSON.stringify(datas.slice(id)));
这个看起来其实时性与请求频率成正相关,但是当请求频率上来了,性能浪费也就越高,毕竟可能大部分请求都是无意义的。
在翻找资料的时候,发现有些资料会直接把这个当作短轮询,有点匪夷所思。这里的长轮询相对前面的轮询来说,算是一种优化。具体就是前端发起请求到后端,后端不直接返回,而是等待有新信息时再返回。所以这样发起的一个请求,可能需要很长的时间才能等到返回,故而叫做长轮询。
其前端代码基本和短轮询一致,只不过把请求的超时时间设置较长(比如1分钟),然后无论请求成功或失败,马上再次发起请求即可。
相对来说,后端的写法就要稍微改动一下
const id = parseInt(query.id || '0', 10) || 0;
const cbk = 'long-polling';
delete callbacks[cbk];
const data = datas.slice(id);
res.writeHead(200, { 'Content-Type': 'application/json' });
// 发起请求时,正好有新消息就返回
if (data.length) {
return res.end(JSON.stringify(data));
}
req.on('close', () => {
delete callbacks[cbk];
});
// 注册新消息回调
callbacks[cbk] = (d) => {
res.end(d);
};
这样,**相对于短轮询,少了很多无意义的请求,而且消息的实时性也非常好。**不过,当服务端有异常时,会导致长轮询短时间内不断发起请求,可能让服务端承受更大的压力,所以两次长轮询之间最好有一定间隔,或者异常检测机制。
Traditionally, a web page has to send a request to the server to receive new data; that is, the page requests data from the server. With server-sent events, it's possible for a server to send new data to a web page at any time, by pushing messages to the web page. These incoming messages can be treated as Events + data inside the web page.
前面提到的轮询、长轮询都是一问一答式的,一次请求,无法推送多次消息到前端。而SSE就厉害了,一次请求,N次推送。
其原理,或者说类比,个人认为可以理解为下载一个巨大的文件,文件的内容分块传给前端,每块就是一次消息推送。
听起来很厉害,先看看后端代码要怎么写
const cbk = 'sse';
delete callbacks[cbk];
res.writeHead(200, {
// 这个是核心
'Content-Type': 'text/event-stream',
'Connection': 'keep-alive',
});
// 把缓存的信息推送给前端
res.write(`data: ${JSON.stringify(datas)}\n\n`);
// 注册新消息回调
callbacks[cbk] = (d) => {
res.write(`data: ${d}\n\n`);
};
req.on('close', () => {
delete callbacks[cbk];
});
后端代码很简单,核心在于Content-Type: text/event-stream,这要让前端知道这是SSE,还有就是传输信息的格式比较特别一点,详细的可以看 MDN( developer.mozilla.org/en-US/docs/… )
而前端有专门的EventSource来接收,使用起来很方便
const es = new EventSource('/api/sse');
es.onmessage = (e) => {
try {
const c = JSON.parse(e.data);
} catch (err) {
console.log(err);
}
}
这样就好了,如果你打开Chrome的开发者工具中的网络标签,你就会发现Chrome对于SSE请求,有专门的展示标签
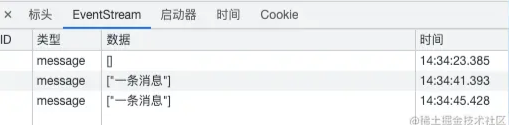
另外,**SSE还支持自动重连!**服务器短时间异常,恢复之后,无需额外代码,SSE就自动重连上了。不过,本人在实际工作中却没有碰到过SSE,也就在面试题中见过。
既然有了SSE,那还要WebSocket干啥啊?因为WebSocket可以一次连接,双向推送,而SSE只能从服务端推送到前端。从这个角度来看,用WebSocket来单做服务端推送,有点大材小用了。
另外,初见WebSocket,可能会对其与Socket的联系有点疑惑。Socket协议是与HTTP协议平级的,而WebSocket协议是基于HTTP协议的,不过两者在使用层面上是十分相近的。
其前端使用写法与SSE类似,十分简单,只不过请求链接为ws://或者wss://开头(相当于http://和https://)
const ws = new WebSocket('ws://localhost:3000/ws');
ws.onmessage = e => {
try {
const c = JSON.parse(e.data);
} catch (err) {
console.log(err);
}
};
而如果要用原生Node.js来写WebSocket服务,就会麻烦一些了,一般情况都会使用类似socket.io之类的三方库来降低实现成本。这边也就在网上摘抄了一段代码来简单实现一下,详细的可以看Github上的Demo代码
server.on('upgrade', (req, socket) => {
const cbk = 'ws';
delete callbacks[cbk];
const acceptKey = req.headers['sec-websocket-key'];
const hash = generateAcceptValue(acceptKey);
const responseHeaders = [ 'HTTP/1.1 101 Web Socket Protocol Handshake', 'Upgrade: WebSocket', 'Connection: Upgrade', `Sec-WebSocket-Accept: ${hash}` ];
// 告知前端这是WebSocket协议
socket.write(responseHeaders.join('\r\n') + '\r\n\r\n');
// 发送数据
socket.write(constructReply(datas));
callbacks[cbk] = (d) => {
socket.write(constructReply(d));
}
socket.on('close', () => {
delete callbacks[cbk];
});
});
这个在Chrome浏览器中,也有专门的标签页展示
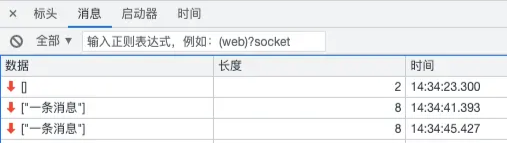
不过,它没有像SSE一样有自动重连,这块需要自行实现。
一般网页实时聊天之类需要双向推送的,都会使用WebSocket来实现。
这算是找资料的时候意外发现的,之前并不知道还有这样的玩法。原理类似使用iFrame加载一个巨大的网页,利用浏览器会一边加载一边解析执行返回的HTML,通过分次返回Script标签来实现消息推送。其实现类似SSE,不过看起来就比较==hack==。
前端代码很简单,只不过要注册一个回调给iframe使用
// 注册给iframe使用的方法
window.change = function(data) {
};
$('body').append('<iframe src="/api/iframe"></iframe>');
而后端也很简单,有消息的时候返回script标签即可
const cbk = 'iframe';
delete callbacks[cbk];
// 返回缓存信息
res.write(`<script>window.parent.change(${JSON.stringify(datas)});</script>`);
callbacks[cbk] = (d) => {
res.write(`<script>window.parent.change(${d});</script>`);
};
req.on('close', () => {
delete callbacks[cbk];
});
相当奇淫巧技了。不过,似乎没找到怎么判断加载异常的情况,可能需要自行加心跳来实现了。
另外,很多文章在说使用iFrame方法时,会导致浏览器显示未加载完,图标一直转的样子。但是个人认为,图标一直转是因为页面一直没有onload,那么在页面onload之后,再创建iFrame就应该没有这个问题了。
上面实现了5种推送的方案,弄了一个表格简单对比一下
| 方案 | (准)实时 | 单次连接 | 自动重连 | 断线检测 | 双向推送 | 无跨域 |
|---|---|---|---|---|---|---|
| 短轮询 | ❌ | ❌ | ➖ | ✅ | ❌ | ❌ |
| 长轮询 | ✅ | ❌ | ➖ | ✅ | ❌ | ❌ |
| SSE | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| WebSocket | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ |
| iFrame | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |

我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
Sinatra新手;我正在运行一些rspec测试,但在日志中收到了一堆不需要的噪音。如何消除日志中过多的噪音?我仔细检查了环境是否设置为:test,这意味着记录器级别应设置为WARN而不是DEBUG。spec_helper:require"./app"require"sinatra"require"rspec"require"rack/test"require"database_cleaner"require"factory_girl"set:environment,:testFactoryGirl.definition_file_paths=%w{./factories./test/
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我有两个Rails模型,即Invoice和Invoice_details。一个Invoice_details属于Invoice,一个Invoice有多个Invoice_details。我无法使用accepts_nested_attributes_forinInvoice通过Invoice模型保存Invoice_details。我收到以下错误:(0.2ms)BEGIN(0.2ms)ROLLBACKCompleted422UnprocessableEntityin25ms(ActiveRecord:4.0ms)ActiveRecord::RecordInvalid(Validationfa
question的一些答案关于redirect_to让我想到了其他一些问题。基本上,我正在使用Rails2.1编写博客应用程序。我一直在尝试自己完成大部分工作(因为我对Rails有所了解),但在需要时会引用Internet上的教程和引用资料。我设法让一个简单的博客正常运行,然后我尝试添加评论。靠我自己,我设法让它进入了可以从script/console添加评论的阶段,但我无法让表单正常工作。我遵循的其中一个教程建议在帖子Controller中创建一个“评论”操作,以添加评论。我的问题是:这是“标准”方式吗?我的另一个问题的答案之一似乎暗示应该有一个CommentsController参