目录
spark.sql.repl.eagerEval.enabled
PySpark DataFrame转换为Pandas DataFrame
要想了解PySpark能够干什么可以去看看我之前写的文章,里面很详细介绍了Spark的生态:
PySpark只是通过JVM转换使得Python代码能够在Spark集群上识别运行。故Spark的绝大多数功能都可以被Python程序使用。
上篇文章:一文速学-PySpark数据分析基础:PySpark原理详解
已经把PySpark运行原理讲的很清楚了,现在我们需要了解PySpark语法基础来逐渐编写PySpark程序实现分布式数据计算。
已搭建环境:
Spark:3.3.0
Hadoop:3.3.3
Scala:2.11.12
JDK:1.8.0_201
PySpark:3.1.2
PySpark是Python中Apache Spark的接口。它不仅可以使用Python API编写Spark应用程序,还提供了PySpark shell,用于在分布式环境中交互分析数据。PySpark支持Spark的大多数功能,如Spark SQL、DataFrame、Streaming、MLlib(机器学习)和Spark Core。
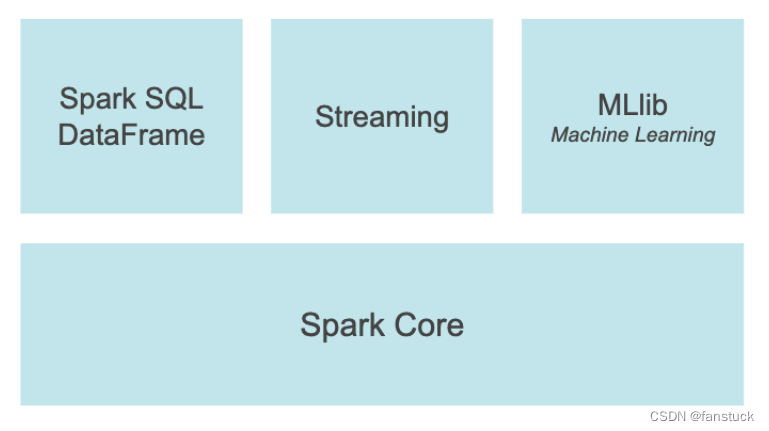
Spark SQL是用于结构化数据处理的Spark模块。它提供了一种称为DataFrame的编程抽象,是由SchemaRDD发展而来。不同于SchemaRDD直接继承RDD,DataFrame自己实现了RDD的绝大多数功能。可以把Spark SQL DataFrame理解为一个分布式的Row对象的数据集合。
Spark SQL已经集成在spark-shell中,因此只要启动spark-shell就可以使用Spark SQL的Shell交互接口。如果在spark-shell中执行SQL语句,需要使用SQLContext对象来调用sql()方法。Spark SQL对数据的查询分成了两个分支:SQLContext和HiveContext,其中HiveContext继承了SQLContext,因此HiveContext除了拥有SQLContext的特性之外还拥有自身的特性。
Spark SQL允许开发人员直接处理RDD,同时也可查询例如在 Apache Hive上存在的外部数据。Spark SQL的一个重要特点是其能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。
Spark上的pandas API可以扩展使用 python pandas库。
Apache Spark中的Streaming功能运行在Spark之上,支持跨Streaming和历史数据的强大交互和分析应用程序,同时继承了Spark的易用性和容错特性。Spark Streaming是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是Spark Core,也就是把Spark Streaming的输入数据按照batch size(如1秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成Spark中的RDD(Resilient Distributed Dataset),然后将Spark Streaming中对DStream的Transformation操作变为针对Spark中对RDD的Transformation操作,将RDD经过操作变成中间结果保存在内存中。
MLlib构建在Spark之上,是一个可扩展的机器学习库,它提供了一组统一的高级API,帮助用户创建和调整实用的机器学习管道。MLBase分为四部分:MLlib、MLI、ML Optimizer和MLRuntime。
Spark Core是Spark平台的底层通用执行引擎,所有其他功能都构建在其之上。它提供了RDD(弹性分布式数据集)和内存计算能力。
| Package | 最低版本限制 | Note |
| pandas | 1.0.5 | 支撑Spark SQL |
| Numpy | 1.7 | 满足支撑MLlib基础API |
| pyarrow | 1.0.0 | 支撑Spark SQL |
| Py4j | 0.10.9.5 | 要求 |
| pandas | 1.0.5 | pandas API on Spark需要 |
| pyarrow | 1.0.0 | pandas API on Spark需要 |
| Numpy | 1.14 | pandas API on Spark需要 |
请注意,PySpark需要Java 8或更高版本,并正确设置Java_HOME。如果使用JDK 11,请设置Dio.netty.tryReflectionSetAccessible=true 以获取与箭头相关的功能。
AArch64(ARM64)用户注意:PyArrow是PySpark SQL所必需的,但PyArrow 4.0.0中引入了对AArch64的PyArrow支持。如果由于PyArrow安装错误导致PyArrow安装在AArch64上失败,可以按如下方式安装PyArrow>=4.0.0:
pip install "pyarrow>=4.0.0" --prefer-binaryPySpark应用程序从初始化SparkSession开始,SparkSession是PySpark的入口点,如下所示。如果通过PySpark可执行文件在PySpark shell中运行它,shell会自动在变量spark中为用户创建会话。
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()PySpark DataFrame能够通过pyspark.sql.SparkSession.createDataFrame创建,通常通过传递列表(list)、元组(tuples)和字典(dictionaries)的列表和pyspark.sql.Rows,Pandas DataFrame,由此类列表组成的RDD转换。pyspark.sql.SparkSession.createDataFrame接收schema参数指定DataFrame的架构(优化可加速)。省略时,PySpark通过从数据中提取样本来推断相应的模式。
from datetime import datetime, date
import pandas as pd
from pyspark.sql import Row
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
dfDataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]
df = spark.createDataFrame([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
], schema='a long, b double, c string, d date, e timestamp')
dfDataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [2., 3., 4.],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
df = spark.createDataFrame(pandas_df)
dfDataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]
rdd = spark.sparkContext.parallelize([
(1, 2., 'string1', date(2000, 1, 1), datetime(2000, 1, 1, 12, 0)),
(2, 3., 'string2', date(2000, 2, 1), datetime(2000, 1, 2, 12, 0)),
(3, 4., 'string3', date(2000, 3, 1), datetime(2000, 1, 3, 12, 0))
])
df = spark.createDataFrame(rdd, schema=['a', 'b', 'c', 'd', 'e'])
dfDataFrame[a: bigint, b: double, c: string, d: date, e: timestamp]
以上的DataFrame格式创建的都是一样的。
df.printSchema()root |-- a: long (nullable = true) |-- b: double (nullable = true) |-- c: string (nullable = true) |-- d: date (nullable = true) |-- e: timestamp (nullable = true)
使用格式:
df.show(<int>)df.show(1)
+---+---+-------+----------+-------------------+ | a| b| c| d| e| +---+---+-------+----------+-------------------+ | 1|2.0|string1|2000-01-01|2000-01-01 12:00:00| +---+---+-------+----------+-------------------+ only showing top 1 row
spark.sql.repl.eagerEval.enabled用于在notebooks(如Jupyter)中快速生成PySpark DataFrame的配置。控制行数可以使用spark.sql.repl.eagerEval.maxNumRows。
spark.conf.set('spark.sql.repl.eagerEval.enabled', True)
df 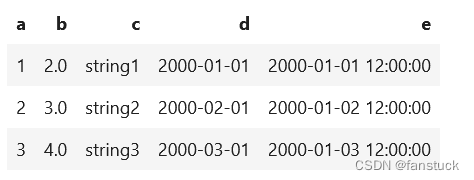
spark.conf.set('spark.sql.repl.eagerEval.maxNumRows',1)
df 
行也可以垂直显示。当行太长而无法水平显示时,纵向显示就很明显。
df.show(1, vertical=True)-RECORD 0------------------ a | 1 b | 2.0 c | string1 d | 2000-01-01 e | 2000-01-01 12:00:00 only showing top 1 row
df.columns['a', 'b', 'c', 'd', 'e']
df.printSchema()root |-- a: long (nullable = true) |-- b: double (nullable = true) |-- c: string (nullable = true) |-- d: date (nullable = true) |-- e: timestamp (nullable = true)
df.select("a", "b", "c").describe().show()+-------+---+---+-------+ |summary| a| b| c| +-------+---+---+-------+ | count| 3| 3| 3| | mean|2.0|3.0| null| | stddev|1.0|1.0| null| | min| 1|2.0|string1| | max| 3|4.0|string3| +-------+---+---+-------+
DataFrame.collect()将分布式数据收集到驱动程序端,作为Python中的本地数据。请注意,当数据集太大而无法容纳在驱动端时,这可能会引发内存不足错误,因为它将所有数据从执行器收集到驱动端。
df.collect()[Row(a=1, b=2.0, c='string1', d=datetime.date(2000, 1, 1), e=datetime.datetime(2000, 1, 1, 12, 0)), Row(a=2, b=3.0, c='string2', d=datetime.date(2000, 2, 1), e=datetime.datetime(2000, 1, 2, 12, 0)), Row(a=3, b=4.0, c='string3', d=datetime.date(2000, 3, 1), e=datetime.datetime(2000, 1, 3, 12, 0))]
为了避免引发内存不足异常可以使用DataFrame.take()或者是DataFrame.tail():
df.take(1)[Row(a=1, b=2.0, c='string1', d=datetime.date(2000, 1, 1), e=datetime.datetime(2000, 1, 1, 12, 0))]
df.tail(1)[Row(a=3, b=4.0, c='string3', d=datetime.date(2000, 3, 1), e=datetime.datetime(2000, 1, 3, 12, 0))]
PySpark DataFrame还提供了到pandas DataFrame的转换,以利用pandas API。注意,toPandas还将所有数据收集到driver端,当数据太大而无法放入driver端时,很容易导致内存不足错误。
df.toPandas() 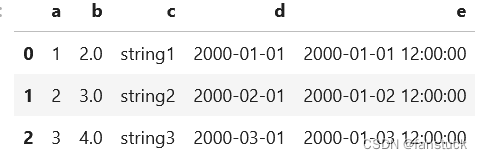
PySpark DataFrame是惰性计算的,仅选择一列不会触发计算,但它会返回一个列实例:
df.aColumn<'a'>
大多数按列操作都返回列:
from pyspark.sql import Column
from pyspark.sql.functions import upper
type(df.c) == type(upper(df.c)) == type(df.c.isNull())True
上述生成的Column可用于从DataFrame中选择列。例如,DataFrame.select()获取返回另一个DataFrame的列实例:
df.select(df.c).show()+-------+ | c| +-------+ |string1| |string2| |string3| +-------+
df.withColumn('upper_c', upper(df.c)).show()+---+---+-------+----------+-------------------+-------+ | a| b| c| d| e|upper_c| +---+---+-------+----------+-------------------+-------+ | 1|2.0|string1|2000-01-01|2000-01-01 12:00:00|STRING1| | 2|3.0|string2|2000-02-01|2000-01-02 12:00:00|STRING2| | 3|4.0|string3|2000-03-01|2000-01-03 12:00:00|STRING3| +---+---+-------+----------+-------------------+-------+
df.filter(df.a == 1).show()+---+---+-------+----------+-------------------+ | a| b| c| d| e| +---+---+-------+----------+-------------------+ | 1|2.0|string1|2000-01-01|2000-01-01 12:00:00| +---+---+-------+----------+-------------------+
PySpark支持各种UDF和API,允许用户执行Python本机函数。另请参阅最新的Pandas UDF( Pandas UDFs)和Pandas Function API( Pandas Function APIs)。例如,下面的示例允许用户在Python本机函数中直接使用pandas Series中的API。
import pandas as pd
from pyspark.sql.functions import pandas_udf
@pandas_udf('long')
def pandas_plus_one(series: pd.Series) -> pd.Series:
# Simply plus one by using pandas Series.
return series + 1
df.select(pandas_plus_one(df.a)).show()+------------------+ |pandas_plus_one(a)| +------------------+ | 2| | 3| | 4| +------------------+
DataFrame.mapInPandas允许用户在pandas DataFrame中直接使用API,而不受结果长度等任何限制。
def pandas_filter_func(iterator):
for pandas_df in iterator:
yield pandas_df[pandas_df.a == 1]
df.mapInPandas(pandas_filter_func, schema=df.schema).show()+---+---+-------+----------+-------------------+ | a| b| c| d| e| +---+---+-------+----------+-------------------+ | 1|2.0|string1|2000-01-01|2000-01-01 12:00:00| +---+---+-------+----------+-------------------+
PySpark DataFrame还提供了一种使用常见方法,即拆分-应用-合并策略来处理分组数据的方法。它根据特定条件对数据进行分组,对每个组应用一个函数,然后将它们组合回DataFrame。
df = spark.createDataFrame([
['red', 'banana', 1, 10], ['blue', 'banana', 2, 20], ['red', 'carrot', 3, 30],
['blue', 'grape', 4, 40], ['red', 'carrot', 5, 50], ['black', 'carrot', 6, 60],
['red', 'banana', 7, 70], ['red', 'grape', 8, 80]], schema=['color', 'fruit', 'v1', 'v2'])
df.show()+-----+------+---+---+ |color| fruit| v1| v2| +-----+------+---+---+ | red|banana| 1| 10| | blue|banana| 2| 20| | red|carrot| 3| 30| | blue| grape| 4| 40| | red|carrot| 5| 50| |black|carrot| 6| 60| | red|banana| 7| 70| | red| grape| 8| 80| +-----+------+---+---+
分组,然后将avg()函数应用于结果组。
df.groupby('color').avg().show()+-----+-------+-------+ |color|avg(v1)|avg(v2)| +-----+-------+-------+ | red| 4.8| 48.0| | blue| 3.0| 30.0| |black| 6.0| 60.0| +-----+-------+-------+
还可以使用pandas API对每个组应用Python自定义函数。
def plus_mean(pandas_df):
return pandas_df.assign(v1=pandas_df.v1 - pandas_df.v1.mean())
df.groupby('color').applyInPandas(plus_mean, schema=df.schema).show()+-----+------+---+---+ |color| fruit| v1| v2| +-----+------+---+---+ |black|carrot| 0| 60| | blue|banana| -1| 20| | blue| grape| 1| 40| | red|banana| -3| 10| | red|carrot| -1| 30| | red|carrot| 0| 50| | red|banana| 2| 70| | red| grape| 3| 80| +-----+------+---+---+
df1 = spark.createDataFrame(
[(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0)],
('time', 'id', 'v1'))
df2 = spark.createDataFrame(
[(20000101, 1, 'x'), (20000101, 2, 'y')],
('time', 'id', 'v2'))
def asof_join(l, r):
return pd.merge_asof(l, r, on='time', by='id')
df1.groupby('id').cogroup(df2.groupby('id')).applyInPandas(
asof_join, schema='time int, id int, v1 double, v2 string').show()+--------+---+---+---+ | time| id| v1| v2| +--------+---+---+---+ |20000101| 1|1.0| x| |20000102| 1|3.0| x| |20000101| 2|2.0| y| |20000102| 2|4.0| y| +--------+---+---+---+
CSV简单易用。Parquet和ORC是高效紧凑的文件格式,读写速度更快。
PySpark中还有许多其他可用的数据源,如JDBC、text、binaryFile、Avro等。另请参阅Apache Spark文档中最新的Spark SQL、DataFrames和Datasets指南。Spark SQL, DataFrames and Datasets Guide
df.write.csv('foo.csv', header=True)
spark.read.csv('foo.csv', header=True).show()这里记录一个报错:
java.lang.UnsatisfiedLinkError:org.apache.hadoop.io.nativeio.NativeIO$Windows.access0将Hadoop安装目录下的 bin 文件夹中的 hadoop.dll 和 winutils.exe 这两个文件拷贝到 C:\Windows\System32 下,问题解决。
+---+---+-------+----------+--------------------+ | a| b| c| d| e| +---+---+-------+----------+--------------------+ | 1|2.0|string1|2000-01-01|2000-01-01T12:00:...| | 2|3.0|string2|2000-02-01|2000-01-02T12:00:...| | 3|4.0|string3|2000-03-01|2000-01-03T12:00:...| +---+---+-------+----------+--------------------+
df.write.parquet('bar.parquet')
spark.read.parquet('bar.parquet').show()+-----+------+---+---+ |color| fruit| v1| v2| +-----+------+---+---+ |black|carrot| 6| 60| | blue|banana| 2| 20| | blue| grape| 4| 40| | red|carrot| 5| 50| | red|banana| 7| 70| | red|banana| 1| 10| | red|carrot| 3| 30| | red| grape| 8| 80| +-----+------+---+---+
df.write.orc('zoo.orc')
spark.read.orc('zoo.orc').show()
+-----+------+---+---+ |color| fruit| v1| v2| +-----+------+---+---+ | red|banana| 7| 70| | red| grape| 8| 80| |black|carrot| 6| 60| | blue|banana| 2| 20| | red|banana| 1| 10| | red|carrot| 5| 50| | red|carrot| 3| 30| | blue| grape| 4| 40| +-----+------+---+---+
DataFrame和Spark SQL共享同一个执行引擎,因此可以无缝地互换使用。例如,可以将数据帧注册为表,并按如下方式轻松运行SQL:
df.createOrReplaceTempView("tableA")
spark.sql("SELECT count(*) from tableA").show()+--------+ |count(1)| +--------+ | 8| +--------+
此外UDF也可在现成的SQL中注册和调用
@pandas_udf("integer")
def add_one(s: pd.Series) -> pd.Series:
return s + 1
spark.udf.register("add_one", add_one)
spark.sql("SELECT add_one(v1) FROM tableA").show() 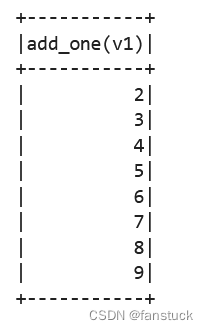
这些SQL表达式可以直接混合并用作PySpark列。
from pyspark.sql.functions import expr
df.selectExpr('add_one(v1)').show()
df.select(expr('count(*)') > 0).show()
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
在Ruby类中,我重写了三个方法,并且在每个方法中,我基本上做同样的事情:classExampleClassdefconfirmation_required?is_allowed&&superenddefpostpone_email_change?is_allowed&&superenddefreconfirmation_required?is_allowed&&superendend有更简洁的语法吗?如何缩短代码? 最佳答案 如何使用别名?classExampleClassdefconfirmation_required?is_a
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
可能已经问过了,但我找不到它。这里有2个常见的情况(对我来说,在编程Rails时......)用ruby编写是令人沮丧的:"astring".match(/abc(.+)abc/)[1]在这种情况下,我得到一个错误,因为字符串不匹配,因此在nil上调用[]运算符。我想找到的是比以下内容更好的替代方法:temp="astring".match(/abc(.+)abc/);temp.nil??nil:temp[1]简而言之,如果不匹配,则简单地返回nil而不会出错第二种情况是这样的:var=something.very.long.and.tedious.to.writevar=some
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
我正在学习Ruby的基础知识(刚刚开始),我遇到了Hash.[]method.它被引入a=["foo",1,"bar",2]=>["foo",1,"bar",2]Hash[*a]=>{"foo"=>1,"bar"=>2}稍加思索,我发现Hash[*a]等同于Hash.[](*a)或Hash.[]*一个。我的问题是为什么会这样。是什么让您将*a放在方括号内,是否有某种规则可以在何时何地使用“it”?编辑:我的措辞似乎造成了一些困惑。我不是在问数组扩展。我明白了。我的问题基本上是:如果[]是方法名称,为什么可以将参数放在括号内?这看起来几乎——但不完全是——就像说如果你有一个方法Foo.d
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD