文章目录
大家好,我是阿光。
本专栏整理了《图神经网络代码实战》,内包含了不同图神经网络的相关代码实现(PyG以及自实现),理论与实践相结合,如GCN、GAT、GraphSAGE等经典图网络,每一个代码实例都附带有完整的代码。
正在更新中~ ✨

🚨 我的项目环境:
💥 项目专栏:【图神经网络代码实战目录】
本文我们将使用PyTorch来简易实现一个EdgeCNN,不使用PyG库,让新手可以理解如何PyTorch来搭建一个简易的图网络实例demo。
本项目是采用自己实现的EdgeCNN,并没有使用 PyG 库,原因是为了帮助新手朋友们能够对EdgeConv的原理有个更深刻的理解,如果熟悉之后可以尝试使用PyG库直接调用 EdgeConv 这个图层即可。
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.utils import scatter
from torch_geometric.datasets import Planetoid
本文使用的数据集是比较经典的Cora数据集,它是一个根据科学论文之间相互引用关系而构建的Graph数据集合,论文分为7类,共2708篇。
这个数据集是一个用于图节点分类的任务,数据集中只有一张图,这张图中含有2708个节点,10556条边,每个节点的特征维度为1433。
# 1.加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')
这里我们就不重点介绍EdgeCNN网络了,相信大家能够掌握基本原理,本文我们使用的是PyTorch定义网络层。
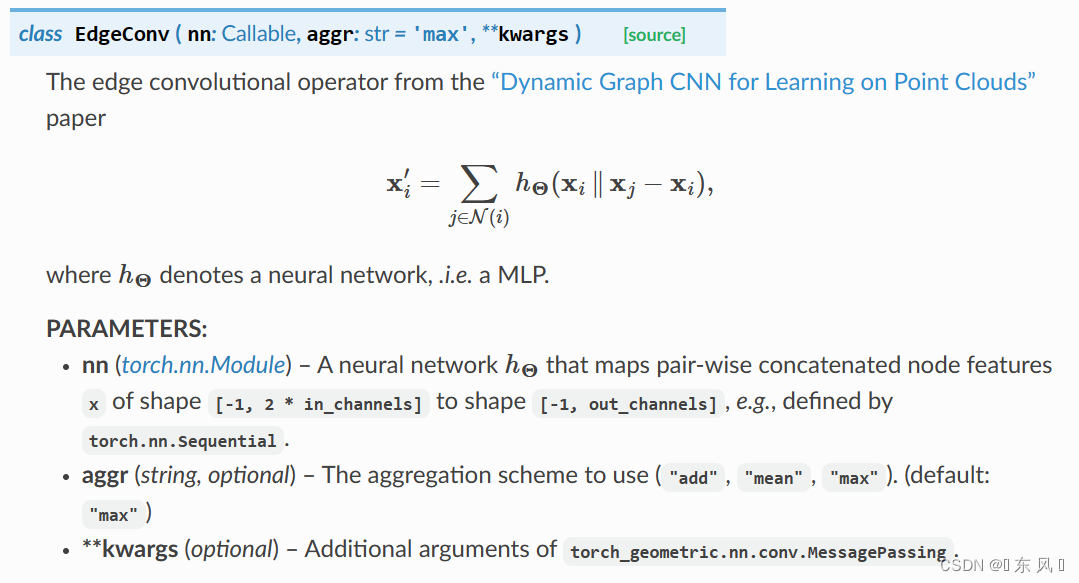
对于EdgeConv的常用参数:
MLP网络,需要自己定义传入max我们在实现时也是考虑这几个常见参数
对于EdgeConv的传播公式为:
x
i
′
=
∑
j
∈
N
(
i
)
h
θ
(
x
i
∣
∣
x
j
−
x
i
)
x_i'=\sum_{j\in N(i)}h_{\theta}(x_i||x_j-x_i)
xi′=j∈N(i)∑hθ(xi∣∣xj−xi)
上式子中的
x
i
x_i
xi 代表中心节点特征信息,
x
j
x_j
xj 代表邻居节点的特征信息,对于
h
θ
h_{\theta}
hθ 代表每个 EdgeConv 层的可学习参数,也就是对应传入的MLP层中的可学习参数。
所以我们的任务无非就是获取这几个变量,然后进行传播计算即可
该环节实现的公式为: x i ∣ ∣ x j − x i x_i||x_j-x_i xi∣∣xj−xi,对于这个公式来说,我们要获得两个变量,一个是中心节点 x i x_i xi(target)的特征信息,一个是邻居节点 x j x_j xj(source)的特征信息。
对于这两个变量的获取很容易,利用 edge_index 就可以提取出来,edge_index 中保存的是每一条边的一对起始节点与终止节点,对于起始节点可以认为就是 i,对于终止节点就可以认为是 j,然后我们就会获得两个向量,分别为 row 和 col ,这两个向量就是起始顶点和终止顶点的集合。
然后我们在根据索引进行提取特征,利用 x_i = x[row] 和 x_j = x[col] 就可以将中心节点和终止节点对应的特征获取,维度为【E,feature_size】。
然后就可以按照公式实现做差然后与中心节点的特征进行拼接,获得拼接后的特征维度为原来的2倍。
row, col = edge_index # 获取target、source节点索引 [E]
x_i = x[row] # 获取target节点信息,中心节点 [E, feature_size]
x_j = x[col] # 获取source节点信息,邻居节点 [E, feature_size]
x_cat = torch.cat([x_i, x_j - x_i], dim=1) # 拼接特征 [E, 2 * feature_size]
对于这里 x_i 和 x_j 以及起始节点的索引初学可能混淆,所以多多打印中间结果一步一步调试进行理解。
对于 EdgeConv 的默认聚合方式为 max,其实还可以使用 mean 、sum 等排列不变函数进行聚合。
对于聚合操作就是公式中求和符号那里,只不过框架给的公式是 sum ,对于聚合我们希望做的是将中心节点的邻居特征按照指定的聚合方式进行聚合。
我们可以利用 PyG 工具库中提供的 scatter 函数进行操作,该函数可以指定聚合方式以及聚合维度等参数,使用方法就是需要传入需要聚合的 Tensor ,此外还需要传入一个 index ,指明哪些向量为同一个邻居的节点,举个例子,我们传入的 index=[0,0,0,1,1] ,这就代表第一个、第二个、第三个为同一节点的邻居,所以就会将待聚合的 Tensor 的第一个向量、第二个向量、第三个向量按照指定聚合方式进行聚合。
这里说的有点抽象,自己尝试一个简单示例就明白了。
out = scatter(src=x_cat, index=row, dim=0, reduce='max') # max聚合操作 [num_nodes, feature_size]
在公式中有个
h
θ
h_{\theta}
hθ,这个就代表 MLP 做特征映射做的,对于官方给的 EdgeConv 需要我们手动传入 MLP 模型,所以本项目自实现也是按照这种方式,MLP 的操作在 EdgeConv 中并没有实现,而是利用传入的模型进行操作。
这里注意一点就是定义的 MLP 模型的输入维度应该为原始维度的2倍,因为我们在这之前进行了特征拼接操作,所以特征维度进行了加倍。
out = self.mlp(out) # 特征映射 [num_nodes, out_channels]
接下来就可以定义EdgeConv层了,该层实现了1个函数,为 forward()
forward():这个函数定义模型的传播过程,也就是上面公式的
x
i
′
=
∑
j
∈
N
(
i
)
h
θ
(
x
i
∣
∣
x
j
−
x
i
)
x_i'=\sum_{j\in N(i)}h_{\theta}(x_i||x_j-x_i)
xi′=∑j∈N(i)hθ(xi∣∣xj−xi)# 2.定义EdgeConv层
class EdgeConv(nn.Module):
def __init__(self, nn, aggr='max'):
super(EdgeConv, self).__init__()
self.mlp = nn # MLP网络
def forward(self, x, edge_index):
row, col = edge_index # 获取target、source节点索引 [E]
x_i = x[row] # 获取target节点信息,中心节点 [E, feature_size]
x_j = x[col] # 获取source节点信息,邻居节点 [E, feature_size]
x_cat = torch.cat([x_i, x_j - x_i], dim=1) # 拼接特征 [E, 2 * feature_size]
out = scatter(src=x_cat, index=row, dim=0, reduce='max') # max聚合操作 [num_nodes, feature_size]
out = self.mlp(out) # 特征映射 [num_nodes, out_channels]
return out
对于我们实现这个网络的实现效率上来讲比PyG框架内置的 EdgeConv 层稍差一点,因为我们是按照公式来一步一步利用矩阵计算得到,没有对矩阵计算以及算法进行优化,不然初学者可能看不太懂,不利于理解EdgeConv公式的传播过程,有能力的小伙伴可以看下官方源码学习一下,框架内是按照消息传递方式实现的。
上面我们已经实现好了 EdgeConv 的网络层,之后就可以调用这个层来搭建 EdgeCNN 网络。
# 3.定义EdgeConv网络
class EdgeCNN(nn.Module):
def __init__(self, num_node_features, num_classes):
super(EdgeCNN, self).__init__()
self.conv1 = EdgeConv(nn=nn.Linear(2 * num_node_features, 16), aggr='max')
self.conv2 = EdgeConv(nn=nn.Linear(2 * 16, num_classes), aggr='max')
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
上面网络我们定义了两个EdgeConv层,第一层的参数的输入维度就是初始每个节点的特征维度 * 2,输出维度是16。
第二个层的输入维度为16 * 2,输出维度为分类个数,因为我们需要对每个节点进行分类,最终加上softmax操作。
这里说明一下为什么要将输入乘以2,原因是在使用MLP进行特征转换之前,会将中心节点的特征与中心节点和邻居节点的差向量做拼接,所以得到的输出维度为节点的特征维度 * 2。
下面就是定义了一些模型需要的参数,像学习率、迭代次数这些超参数,然后是模型的定义以及优化器及损失函数的定义,和pytorch定义网络是一样的。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
epochs = 10 # 学习轮数
lr = 0.003 # 学习率
num_node_features = dataset.num_node_features # 每个节点的特征数
num_classes = dataset.num_classes # 每个节点的类别数
data = dataset[0].to(device) # Cora的一张图
# 3.定义模型
model = EdgeCNN(num_node_features, num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 优化器
loss_function = nn.NLLLoss() # 损失函数
模型训练部分也是和pytorch定义网络一样,因为都是需要经过前向传播、反向传播这些过程,对于损失、精度这些指标可以自己添加。
# 训练模式
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
pred = model(data)
loss = loss_function(pred[data.train_mask], data.y[data.train_mask]) # 损失
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item() # epoch正确分类数目
acc_train = correct_count_train / data.train_mask.sum().item() # epoch训练精度
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print("【EPOCH: 】%s" % str(epoch + 1))
print('训练损失为:{:.4f}'.format(loss.item()), '训练精度为:{:.4f}'.format(acc_train))
print('【Finished Training!】')
下面就是模型验证阶段,在训练时我们是只使用了训练集,测试的时候我们使用的是测试集,注意这和传统网络测试不太一样,在图像分类一些经典任务中,我们是把数据集分成了两份,分别是训练集、测试集,但是在Cora这个数据集中并没有这样,它区分训练集还是测试集使用的是掩码机制,就是定义了一个和节点长度相同纬度的数组,该数组的每个位置为True或者False,标记着是否使用该节点的数据进行训练。
# 模型验证
model.eval()
pred = model(data)
# 训练集(使用了掩码)
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item()
acc_train = correct_count_train / data.train_mask.sum().item()
loss_train = loss_function(pred[data.train_mask], data.y[data.train_mask]).item()
# 测试集
correct_count_test = pred.argmax(axis=1)[data.test_mask].eq(data.y[data.test_mask]).sum().item()
acc_test = correct_count_test / data.test_mask.sum().item()
loss_test = loss_function(pred[data.test_mask], data.y[data.test_mask]).item()
print('Train Accuracy: {:.4f}'.format(acc_train), 'Train Loss: {:.4f}'.format(loss_train))
print('Test Accuracy: {:.4f}'.format(acc_test), 'Test Loss: {:.4f}'.format(loss_test))
【EPOCH: 】1
训练损失为:1.9629 训练精度为:0.1214
【EPOCH: 】21
训练损失为:1.6709 训练精度为:0.5714
【EPOCH: 】41
训练损失为:1.3965 训练精度为:0.7571
【EPOCH: 】61
训练损失为:1.1095 训练精度为:0.8643
【EPOCH: 】81
训练损失为:0.9088 训练精度为:0.9286
【EPOCH: 】101
训练损失为:0.7454 训练精度为:0.9643
【EPOCH: 】121
训练损失为:0.5841 训练精度为:0.9643
【EPOCH: 】141
训练损失为:0.4985 训练精度为:0.9714
【EPOCH: 】161
训练损失为:0.3954 训练精度为:0.9714
【EPOCH: 】181
训练损失为:0.3339 训练精度为:0.9857
【Finished Training!】
>>>Train Accuracy: 1.0000 Train Loss: 0.3133
>>>Test Accuracy: 0.4230 Test Loss: 1.6562
| 训练集 | 测试集 | |
|---|---|---|
| Accuracy | 1.0000 | 0.4230 |
| Loss | 0.3133 | 1.6562 |
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch_geometric.utils import scatter
from torch_geometric.datasets import Planetoid
# 1.加载Cora数据集
dataset = Planetoid(root='./data/Cora', name='Cora')
# 2.定义EdgeConv层
class EdgeConv(nn.Module):
def __init__(self, nn, aggr='max'):
super(EdgeConv, self).__init__()
self.mlp = nn # MLP网络
def forward(self, x, edge_index):
row, col = edge_index # 获取target、source节点索引 [E]
x_i = x[row] # 获取target节点信息,中心节点 [E, feature_size]
x_j = x[col] # 获取source节点信息,邻居节点 [E, feature_size]
x_cat = torch.cat([x_i, x_j - x_i], dim=1) # 拼接特征 [E, 2 * feature_size]
out = scatter(src=x_cat, index=row, dim=0, reduce='max') # max聚合操作 [num_nodes, feature_size]
out = self.mlp(out) # 特征映射 [num_nodes, out_channels]
return out
# 3.定义EdgeConv网络
class EdgeCNN(nn.Module):
def __init__(self, num_node_features, num_classes):
super(EdgeCNN, self).__init__()
self.conv1 = EdgeConv(nn=nn.Linear(2 * num_node_features, 16), aggr='max')
self.conv2 = EdgeConv(nn=nn.Linear(2 * 16, num_classes), aggr='max')
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
epochs = 200 # 学习轮数
lr = 0.0003 # 学习率
num_node_features = dataset.num_node_features # 每个节点的特征数
num_classes = dataset.num_classes # 每个节点的类别数
data = dataset[0].to(device) # Cora的一张图
# 4.定义模型
model = EdgeCNN(num_node_features, num_classes).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 优化器
loss_function = nn.NLLLoss() # 损失函数
# 训练模式
model.train()
for epoch in range(epochs):
optimizer.zero_grad()
pred = model(data)
loss = loss_function(pred[data.train_mask], data.y[data.train_mask]) # 损失
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item() # epoch正确分类数目
acc_train = correct_count_train / data.train_mask.sum().item() # epoch训练精度
loss.backward()
optimizer.step()
if epoch % 20 == 0:
print("【EPOCH: 】%s" % str(epoch + 1))
print('训练损失为:{:.4f}'.format(loss.item()), '训练精度为:{:.4f}'.format(acc_train))
print('【Finished Training!】')
# 模型验证
model.eval()
pred = model(data)
# 训练集(使用了掩码)
correct_count_train = pred.argmax(axis=1)[data.train_mask].eq(data.y[data.train_mask]).sum().item()
acc_train = correct_count_train / data.train_mask.sum().item()
loss_train = loss_function(pred[data.train_mask], data.y[data.train_mask]).item()
# 测试集
correct_count_test = pred.argmax(axis=1)[data.test_mask].eq(data.y[data.test_mask]).sum().item()
acc_test = correct_count_test / data.test_mask.sum().item()
loss_test = loss_function(pred[data.test_mask], data.y[data.test_mask]).item()
print('Train Accuracy: {:.4f}'.format(acc_train), 'Train Loss: {:.4f}'.format(loss_train))
print('Test Accuracy: {:.4f}'.format(acc_test), 'Test Loss: {:.4f}'.format(loss_test))
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
通常,数组被实现为内存块,集合被实现为HashMap,有序集合被实现为跳跃列表。在Ruby中也是如此吗?我正在尝试从性能和内存占用方面评估Ruby中不同容器的使用情况 最佳答案 数组是Ruby核心库的一部分。每个Ruby实现都有自己的数组实现。Ruby语言规范只规定了Ruby数组的行为,并没有规定任何特定的实现策略。它甚至没有指定任何会强制或至少建议特定实现策略的性能约束。然而,大多数Rubyist对数组的性能特征有一些期望,这会迫使不符合它们的实现变得默默无闻,因为实际上没有人会使用它:插入、前置或追加以及删除元素的最坏情况步骤复
在ruby中,你可以这样做:classThingpublicdeff1puts"f1"endprivatedeff2puts"f2"endpublicdeff3puts"f3"endprivatedeff4puts"f4"endend现在f1和f3是公共(public)的,f2和f4是私有(private)的。内部发生了什么,允许您调用一个类方法,然后更改方法定义?我怎样才能实现相同的功能(表面上是创建我自己的java之类的注释)例如...classThingfundeff1puts"hey"endnotfundeff2puts"hey"endendfun和notfun将更改以下函数定
我正在寻找用于Rails的优质管理插件。似乎大多数现有的插件/gem(例如“restful_authentication”、“acts_as_authenticated”)都围绕着self注册等展开。但是,我正在寻找一种功能齐全的基于管理/管理角色的解决方案——但不是简单地附加到另一个非基于角色的解决方案。如果我找不到,我想我会自己动手......只是不想重新发明轮子。 最佳答案 RyanBates最近做了两个关于授权的railscast(注意身份验证和授权之间的区别;身份验证检查用户是否如她所说的那样,授权检查用户是否有权访问资源