绘制频谱图需要纯音频数据,WAV就是纯音频,如果要用mp3等其他压缩格式的音频还需先进行解码(解码自行查找资料),这里只讲WAV文件绘制;
频谱是什么?频谱的全称是频率谱密度。一般信号都是用时间和幅度的关系。通过傅立叶变换,可以得到频率和幅度的关系,这个就是信号的频谱。通过傅立叶变换,就可以把时域信号变成频域信号。
那么具体如何绘制呢?下面就会详细讲解到。
在讲解绘制频谱之前,我们要先了解WAV文件格式,进行分析;
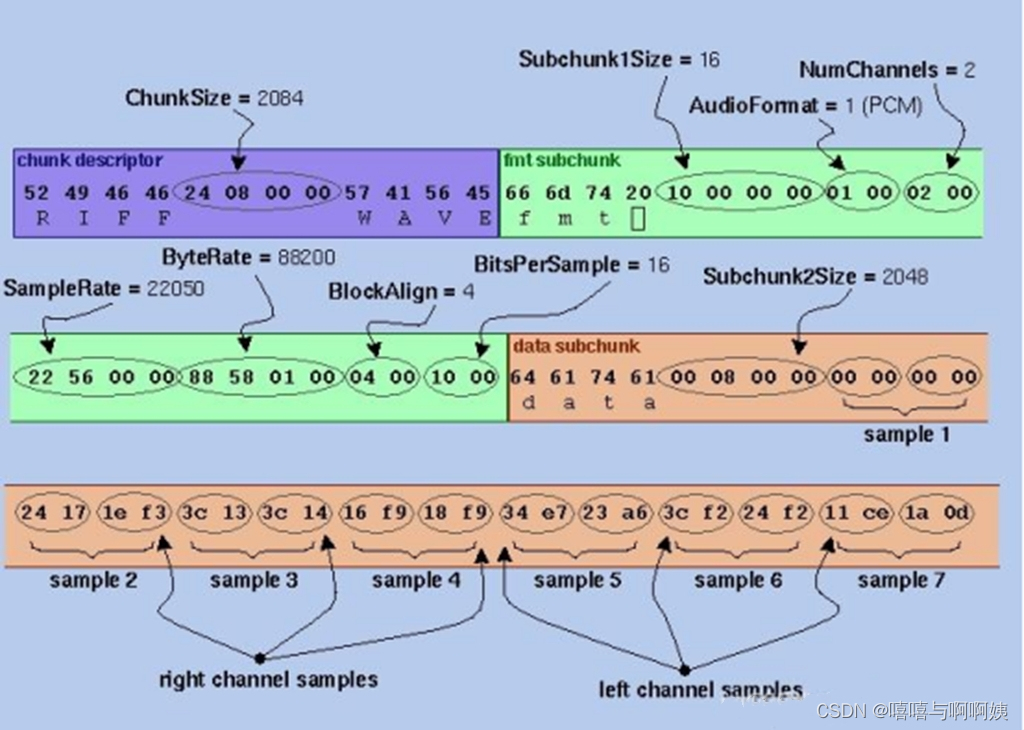
WAV是一种以RIFF为基础的无压缩音频编码格式,该格式以Header、Format Chunk及Data Chunk三部分构成。下图展示了WAV文件格式。

Header
ChunkID: 4字节大端序。文件从此处开始,对于WAV或AVI文件,其值总为“RIFF”。
ChunkSize: 4字节小端序。表示文件总字节数减8,减去的8字节表示ChunkID与ChunkSize本身所占字节数。
Format: 4字节大端序。对于WAV文件,其值总为“WAVE”
Subchunk1ID: 4字节大端序。其值总为“fmt ”,表示Format Chunk从此处开始。
Subchunk1Size: 4字节小端序。表示Format Chunk的总字节数减8。
AudioFormat: 2字节小端序。对于WAV文件,其值总为1。
NumChannels: 2字节小端序。表示总声道个数。
SampleRate: 4字节小端序。表示在每个通道上每秒包含多少帧。
ByteRate: 4字节小端序。大小等于SampleRate * BlockAlign,表示每秒共包含多少字节。
BlockAlign: 2字节小端序。大小等于NumChannels * BitsPerSample / 8, 表示每帧的多通道总字节数。
BitsPerSample: 2字节小端序。表示每帧包含多少比特。
Subchunk2ID: 4字节大端序。其值总为“data”,表示Data Chunk从此处开始。
Subchunk2Size: 4字节小端序。表示data的总字节数。
data: 小端序。表示音频波形的帧数据,各声道按帧交叉排列。
最后数据的data就是音频内容数据(数据的存储是橘色区域)
三、Data块详解
常见的声音文件主要有两种,分别对应于单声道(11.025KHz 采样率、8bit 的采样值)和双声道(44.1KHz 采样率、16bit 的采样值)。采样率是指:声音信号在“模→数”转换过程中单位时间内采样的次数。采样值是指每一次采样周期 内声音模拟信号的积分值。
对于单声道声音文件,采样数据为八位的短整数(short int 00H-FFH);而对于双声道立体声声音文件,每次采样数据为一个16位的整数(int),高八位和低八位分别代表左右两个声道。
例如图中的Sample1可以看出,是位深度为16位的音频文件;
位深度:8位、16位、24位、32位
8位音频:
16位音频:通用标准 ,CD上的音频是16位的,不能编辑;02 1e 10 23
24位音频:是16位的升级版,更适合工作室音频编辑;02 1e 2f 10 23 11
32位音频:增强编辑功能;
8bit单声道:01
| 采样1 | 采样2 |
| 数据1 | 数据2 |
8bit双声道:01 25
| 采样1 | 采样2 | ||
| 左声道数据1 | 右声道数据1 | 左声道数据2 | 右声道数据2 |
16bit单声道:01 1e
| 采样1 | 采样2 | ||
| 数据1低字节 | 数据1高字节 | 数据2低字节 | 数据2高字节 |
16bit双声道:01 1e 24 10
| 采样1 | |||
| 声道1数据1低字节 | 声道1数据1高字节 | 声道2数据1高字节 | 声道2数据1高字节 |
| 采样2 | |||
| 声道1数据2低字节 | 声道1数据2高字节 | 声道2数据2低字节 | 声道2数据2高字节 |
同理 24位: 单声道:01 12 1e 双声道:01 12 1e 13 22 01
注意:WAV文件以小端形式来进行数据存储,低位保存在低地址,高位保存在高地址;
这里我要分析的wav文件:采样率48000hz, 24位,双声道。上代码(解析出来的数据处理)
private void dataimprot(ref Complex[] buf,int len,int count)
{
int data = 0;
int cnt = count * len * 6;
//当前只先计算左声道
for (int i = 0; i < len; i++)
{
data = wavFFT.wavdata[i * 6 + 0 + cnt];
data += (wavFFT.wavdata[i * 6 + 1 + cnt]<<8);
data += (wavFFT.wavdata[i * 6 + 2 + cnt]<<16);
if (data >= Math.Pow(2, 23))//去符号
{
data = data << 8;
data = data >> 8;
}
buf[i].real = (float)(data / Math.Pow(2, 23));
buf[i].imag = 0;
}
}/*
这里的参数len 为1024(可以选择样本划分大小512/1024等,根据需求自己划分)
去符号:第24位为符号位,只有23位表示实际的数据。数据有正有负,要将其全部取正,需要将负数去符号(可用自己的方式去符号)。
*/
fft之前要进行窗函数处理数据!!!
什么是窗函数?为什么要加窗?
每次FFT变换只能对有限长度的时域数据进行变换,因此,需要对时域信号进行信号截断。即使是周期信号,如果截断的时间长度不是周期的整数倍(周期截断),那么,截取后的信号将会存在泄漏。为了将这个泄漏误差减少到最小程度(注意我说是的减少,而不是消除),我们需要使用加权函数,也叫窗函数。加窗主要是为了使时域信号似乎更好地满足FFT处理的周期性要求,减少泄漏。
void fft4(ref Complex[] im, int log4_N)
{
int N = 1 << (log4_N * 2);
int i;
Complex[] win = new Complex[N];
reverse_idx(ref im, log4_N);
for (i = 0; i < (3 * N / 4 - 2); i++)
{
win[i].real = (float)Math.Cos(2 * pi * i / (float)N);
win[i].imag = -(float)Math.Sin(2 * pi * i / (float)N);
}
fft_ifft_4_common(ref im,ref win, log4_N, 0);
}
void reverse_idx(ref Complex[] im, int log4_N)
{
int i;
int N = 1 << (log4_N * 2);
Complex[] temp = new Complex[N];
for (i = 0; i < N; i++)
{
int idx;
idx = BitReverse(i, log4_N);
temp[idx].real = im[i].real;
temp[idx].imag = im[i].imag;
}
for (i = 0; i < N; i++)
{
im[i].real = temp[i].real;
im[i].imag = temp[i].imag;
}
}
void fft_ifft_4_common(ref Complex[] im,ref Complex[] win, int log4_N, int reverse)
{
int N = (1 << log4_N * 2);
int i, j, k;
int span = 1;
int n = N >> 2;
int widx;
Complex temp1 = new Complex();
Complex temp2 = new Complex();
Complex temp3 = new Complex();
Complex temp4 = new Complex();
int idx1, idx2, idx3, idx4;
for (i = 0; i < log4_N; i++)
{
for (j = 0; j < n; j++)
{
widx = 0;
idx1 = j * span * 4;
idx2 = idx1 + span;
idx3 = idx2 + span;
idx4 = idx3 + span;
for (k = 0; k < span; k++)
{
temp1.real = im[idx1 +k].real;
temp1.imag = im[idx1 +k].imag;
temp2.real = win[widx].real * im[idx2 +k].real - win[widx].imag * im[idx2 +k].imag;
temp2.imag = win[widx].imag * im[idx2 +k].real + win[widx].real * im[idx2 +k].imag;
temp3.real = win[widx * 2].real * im[idx3 +k].real - win[widx * 2].imag * im[idx3 +k].imag;
temp3.imag = win[widx * 2].imag * im[idx3 +k].real + win[widx * 2].real * im[idx3 +k].imag;
temp4.real = win[widx * 3].real * im[idx4 +k].real - win[widx * 3].imag * im[idx4 +k].imag;
temp4.imag = win[widx * 3].imag * im[idx4 +k].real + win[widx * 3].real * im[idx4 +k].imag;
im[idx1 +k].real = temp1.real + temp3.real;
im[idx1 +k].imag = temp1.imag + temp3.imag;
im[idx2 +k].real = temp1.real - temp3.real;
im[idx2 +k].imag = temp1.imag - temp3.imag;
im[idx3 +k].real = temp2.real + temp4.real;
im[idx3 +k].imag = temp2.imag + temp4.imag;
im[idx4 +k].real = temp2.real - temp4.real;
im[idx4 +k].imag = temp2.imag - temp4.imag;
temp1.real = im[idx1 +k].real + im[idx3 +k].real;
temp1.imag = im[idx1 +k].imag + im[idx3 +k].imag;
if (reverse == 0)
{
temp2.real = im[idx2 +k].real + im[idx4 +k].imag;
temp2.imag = im[idx2 +k].imag - im[idx4 +k].real;
}
else
{
temp2.real = im[idx2 +k].real - im[idx4 +k].imag;
temp2.imag = im[idx2 +k].imag + im[idx4 +k].real;
}
temp3.real = im[idx1 +k].real - im[idx3 +k].real;
temp3.imag = im[idx1 +k].imag - im[idx3 +k].imag;
if (reverse == 0)
{
temp4.real = im[idx2 +k].real - im[idx4 +k].imag;
temp4.imag = im[idx2 +k].imag + im[idx4 +k].real;
}
else
{
temp4.real = im[idx2 +k].real + im[idx4 +k].imag;
temp4.imag = im[idx2 +k].imag - im[idx4 +k].real;
}
im[idx1 +k].real = temp1.real;
im[idx1 +k].imag = temp1.imag;
im[idx2 +k].real = temp2.real;
im[idx2 +k].imag = temp2.imag;
im[idx3 +k].real = temp3.real;
im[idx3 +k].imag = temp3.imag;
im[idx4 +k].real = temp4.real;
im[idx4 +k].imag = temp4.imag;
widx += n;
}
}
n >>= 2;
span <<= 2;
}
}
Pref为基准参考声压,空气中一般取2x10^-5 (Pa)。
N为时域采样点数,我这里为1024;

for (int i = 0; i < buf.Length; i++)//
{
double data = Math.Pow((buf[i].real * buf[i].real + buf[i].imag * buf[i].imag)/ (1024 * buf.Length), 0.5);//求复数模
//Console.WriteLine(data);
if(data==0)
{
continue;
}
data = 20 * Math.Log10(data / (2 * Math.Pow(10, -5)) );//计算声压级
sw.Write(Math.Round(data, 2).ToString()+" ");//将数据写入文件
hz = (i+1) * wavFFT.SamplesPerSec / Len;
if (i < pictureBox1.Width && i != 0)
{
//Console.WriteLine("data:{0}", data);
g.DrawLine(pen, new PointF(i , this.Height-(float)pr-200), new PointF((i + 1) , this.Height-(float)data-200));//简略的画一下数据
}
pr = data;//保存上一次数据
//Console.WriteLine(hz);
//Console.WriteLine(data);// + " = " + buf[i].real + " + " + buf[i].imag + "i;");
}
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我得到了一个包含嵌套链接的表单。编辑时链接字段为空的问题。这是我的表格:Editingkategori{:action=>'update',:id=>@konkurrancer.id})do|f|%>'Trackingurl',:style=>'width:500;'%>'Editkonkurrence'%>|我的konkurrencer模型:has_one:link我的链接模型:classLink我的konkurrancer编辑操作:defedit@konkurrancer=Konkurrancer.find(params[:id])@konkurrancer.link_attrib
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信