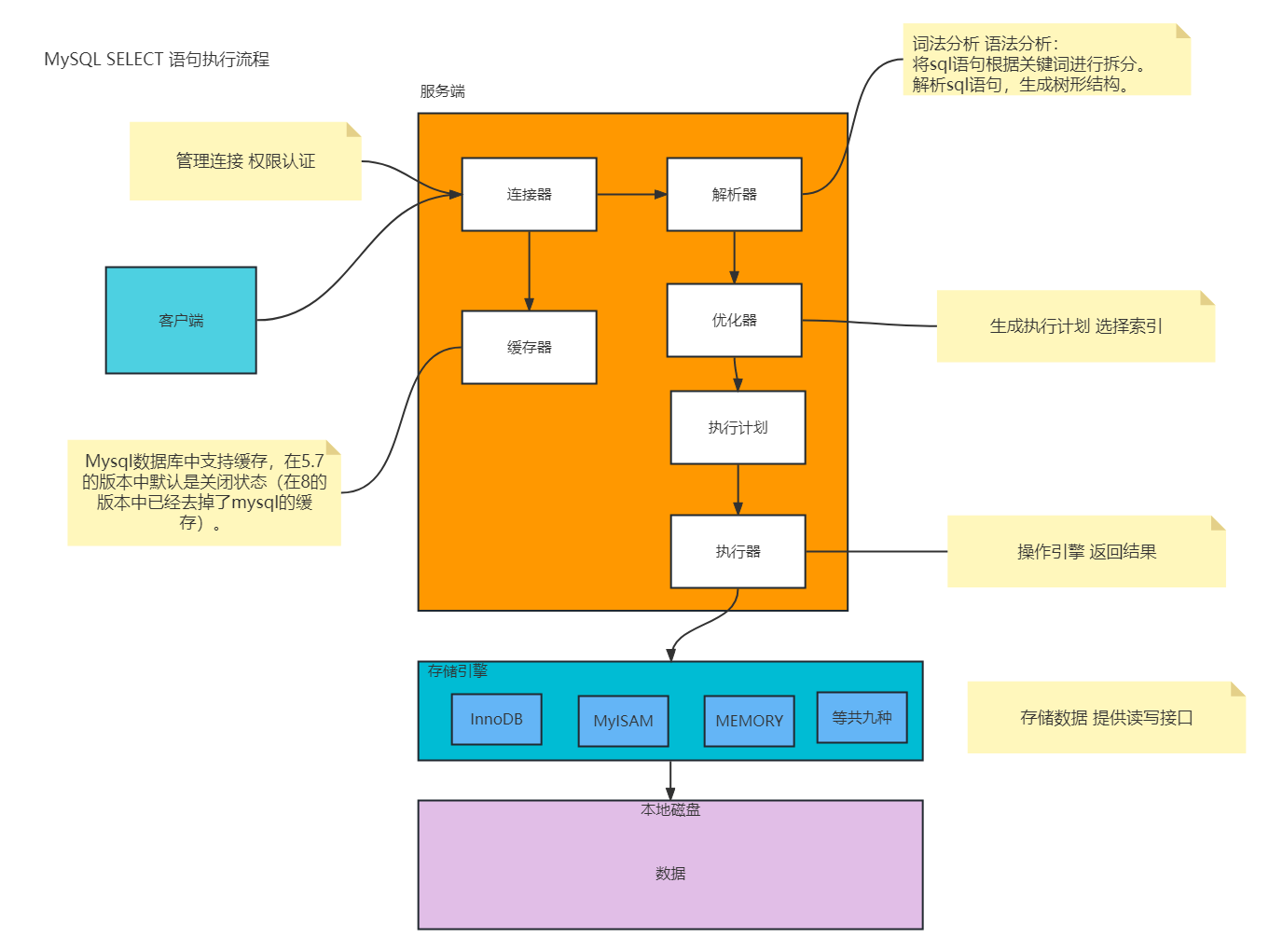
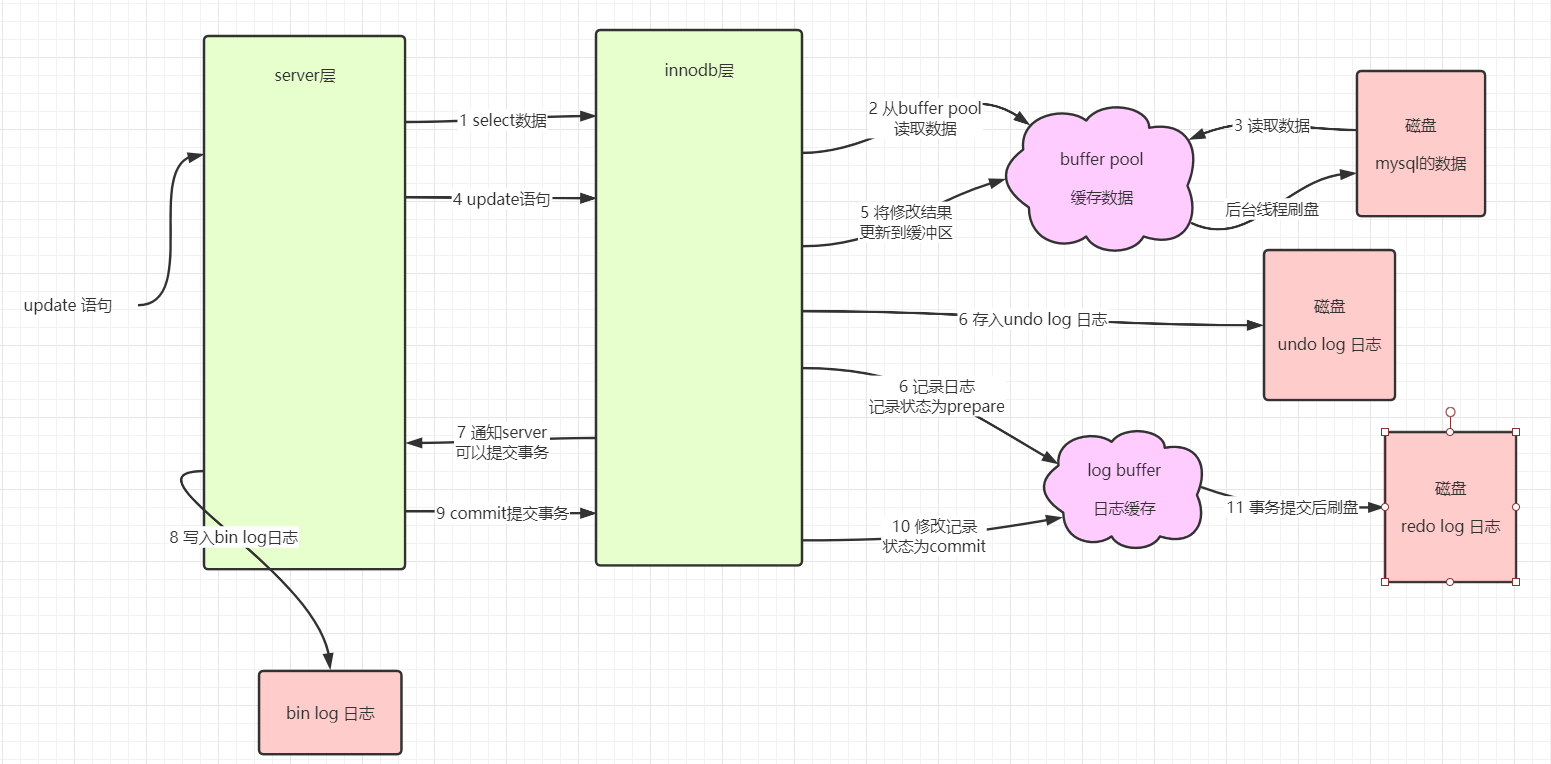
update语句的整体执行流程和select语句是一样的。只是少了缓存的那一步骤。
mysql想完成数据的修改,会先从存储引擎层读取数据,把数据读取到服务层进行数据的修改,再通过存储引擎层把数据更新到数据库中。
mysql每次读取数据都会读取16384B的数据,默认是16KB的数据。一页的数据。
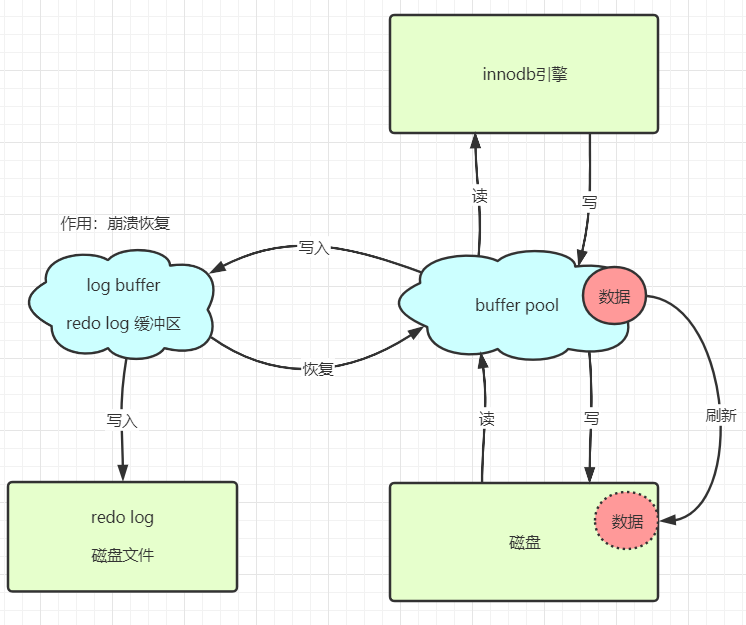
在innodb引擎中设计了 buffer pool 缓冲区。Mysql从磁盘中通过IO读取数据到buffer pool中,引擎从bffer pool中获取数据,然后修改,再把数据写入到buffer pool中。从而完成读写的操作,因为是基于内存的操作,所以速度是非常快的。
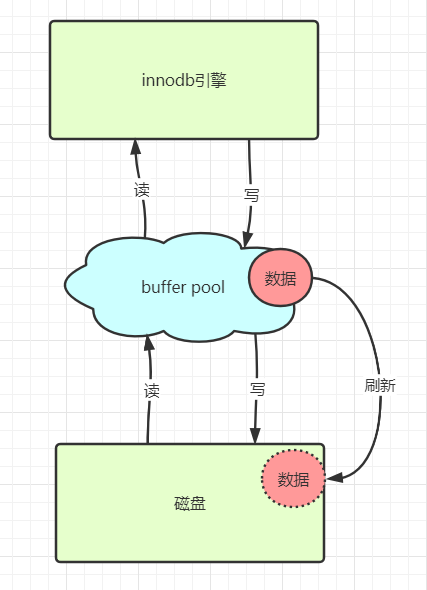
脏数据:buffer pool中的数据,还没有同步到磁盘中的数据称为脏数据。
innodb的脏页刷新机制说明:
1、当innodb中的脏页比例超过innodb_max_dirty_pages_pct_lwm的值时,这个时候innodb就会开始刷新脏页到磁盘。
2、当innodb中的脏页比例超过innodb_max_dirty_pages_pct_lwm的值,而且还超过innodb_max_dirty_pages_pct时innodb就会进入勤快刷新模式(agressively flush)这个模式下innodb会把脏页更快的刷新到磁盘。
3、还有一种情况叫做sharp checkpoint ,当innodb要重用它之前的redo文件时,就会把innodb_buffer_pool中所有与这个文件有关的页面都要刷新到磁盘;这样做就有可能引起磁盘的IO风暴了,轻者影响性能,重者影响可用性。
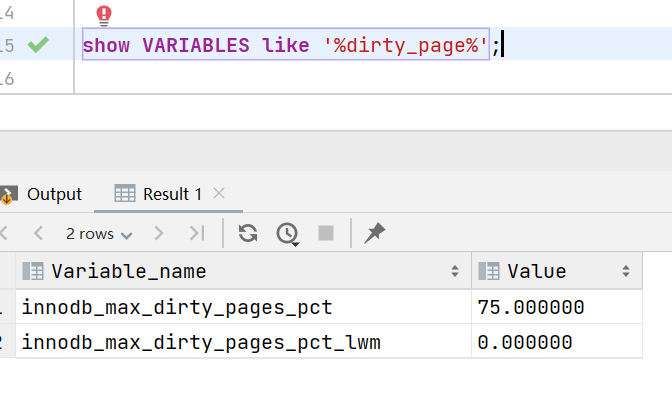
对于控制刷新机制的各个参数的说明:
1、innodb_max_dirty_pages_pct默认值为75,也就是说当脏页比例超过75%时才会进入勤快刷新模式。
2、innodb_max_dirty_pages_pct_lwm默认值是0,0对于innodb_max_dirty_pages_pct_lwm来说是一个特殊值,它表示不启用这个功能;由于没有启用这个功能,也就是说innodb_buffer_pool中的脏页比例会操持在75%左右。
Mysql会在后台使用若干线程,负责把buffer pool中的数据刷新到磁盘中去。
后台常用的线程:
master thread 主线程
IO thread IO操作的线程
Purge thread 清理数据和日志的线程
Page C1eaner thred 刷脏的线程
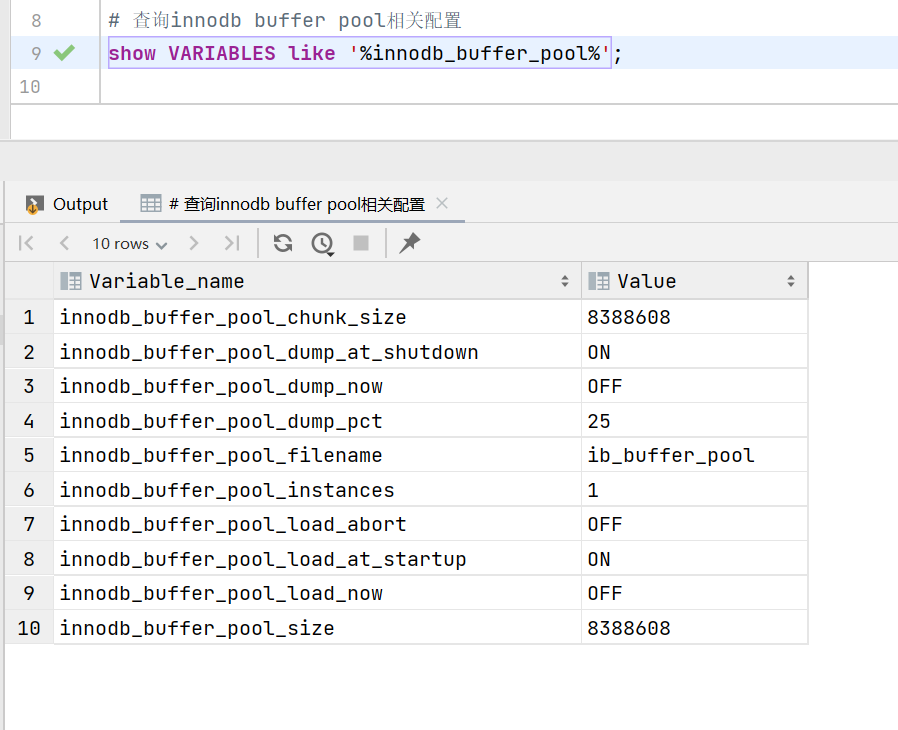
查看buffer pool的大小,默认是128M
# 查询innodb buffer pool相关配置
show VARIABLES like '%innodb_buffer_pool%';
数据存储到buffer pool中,默认是128M,如果buffer pool存满了,那么innodb引擎会使用改良的LRU算法清理数据。
注意:LRU算法是最近最久未使用法,mysql会对LRU的算法进行改良。
官网文档地址:https://dev.mysql.com/doc/refman/5.7/en/innodb-buffer-pool.html
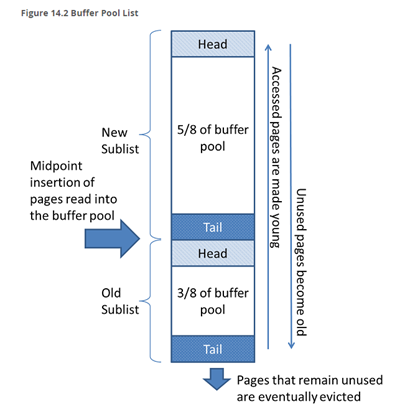
冷热分离的方式:
新的数据刚进来的时候进入冷区域,如果下一秒被调用就进去热区域顶部,热区域的数据都会向下移动。
redo log日志是innodb存储引擎自带的。
避免服务器宕机或者其他突发事件,导致需要保存到数据库的数据还没来得及存储,所以才有了redo log。在mysql事务的层面上来说,redo log保证了数据的持久性。
问题:数据没有直接存入到磁盘上,而是先存入到buffer pool中,然后再刷入磁盘,目的是为了性能考虑,但是现在有需要存入到redo log 日志的磁盘文件中,这样性能不就下降了?
答案:性能肯定是会有一些影响,但是需要保证数据可恢复的能力。写入redo log磁盘文件中的速度会更快一些。
随机磁盘IO和顺序磁盘IO的区别。
随机磁盘IO的情况是数据是会分散到不同的扇区去存储,因为底层是通过索引的顺序来存储,索引会存储到不同的扇区。那么更新数据的时候会增加寻道的时间,写入数据会变慢。
顺序磁盘IO是按着顺序追加写入的。 速度会快一些。
# 通过命令查看innodb_log相关的信息。
show VARIABLES like '%innodb_log%';
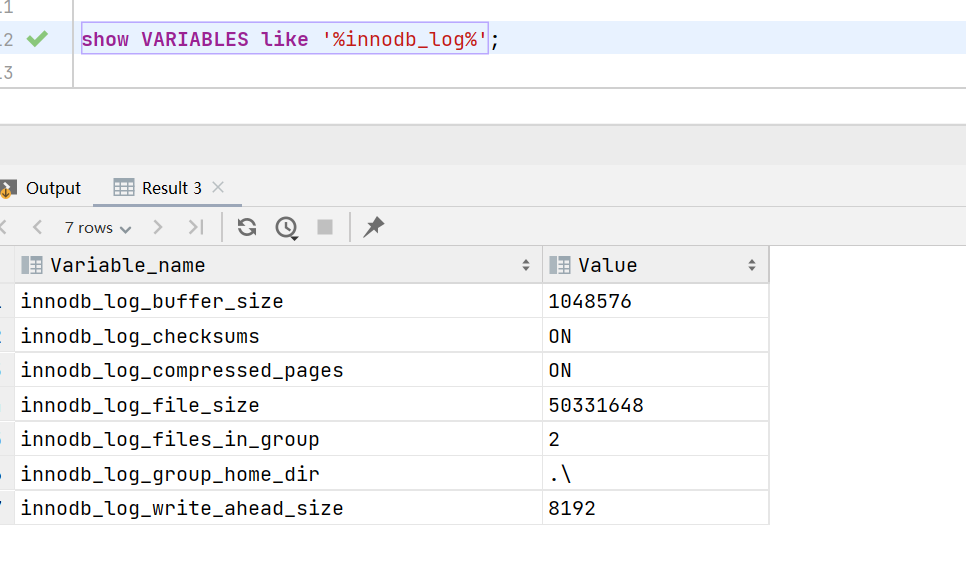
默认是分成2组innodb_log_files_in_group,所以产生2个日志文件。
每个文件的大小默认是48Minnodb_log_file_size 固定的(可以修改),数据满了会产生覆盖的效果。
站在mysql事务的角度,redo log日志是事务持久性的保证。

log buffer 刷盘机制(什么时候将记录的数据存储到磁盘中),官网说明
log buffer刷盘时间间隔

每隔一秒刷盘一次,但是具体的刷盘策略由innodb_flush_log_at_trx_commit参数来决定。
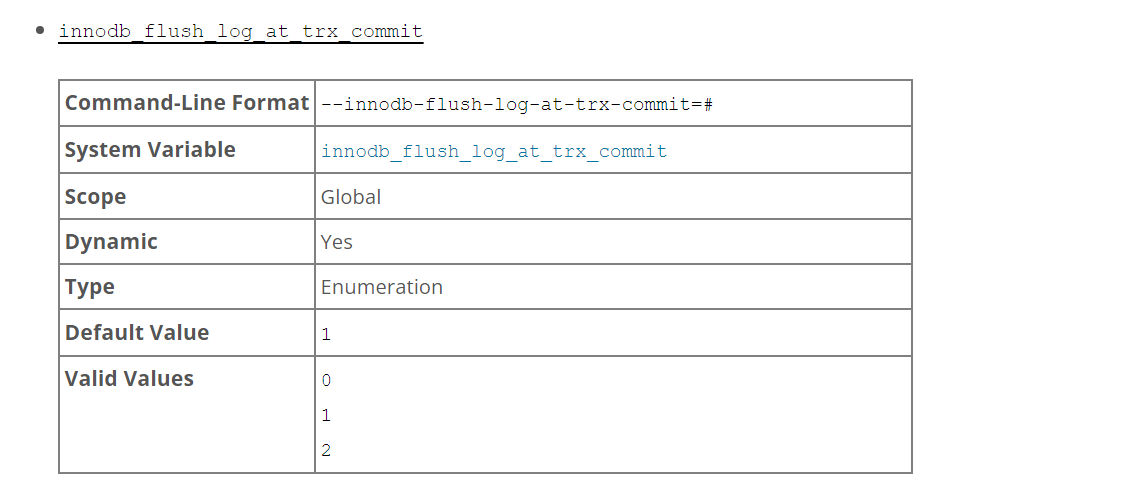
log buffer 刷盘机制:
innodb_flush_log_at_trx_commit:用来控制redo log刷新到磁盘的策略。
当设置为1的时候,事务每次提交都会将log buffer中的日志写入os buffer并调用fsync()刷到log file on disk中。这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO的性能较差。
当设置为0的时候,事务提交时不会将log buffer中日志写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。也就是说设置为0时是(大约)每秒刷新写入到磁盘中的,当系统崩溃,会丢失1秒钟的数据。
当设置为2的时候,每次提交都仅写入到os buffer,然后是每秒调用fsync()将os buffer中的日志写入到log file on disk。
undo log日志是innodb存储引擎自带的。
undo log可以称为撤销日志或者回滚日志,站在事务的角度,undo log可以保证事务的原子性。
日志中记录的反向操作,例如:把username=”张三” 修改成了username=”赵四”,那么undo log中记录的是原来的值,即 username=”张三” 这样数据库再发生回滚操作的时候,可以把数据恢复回来。
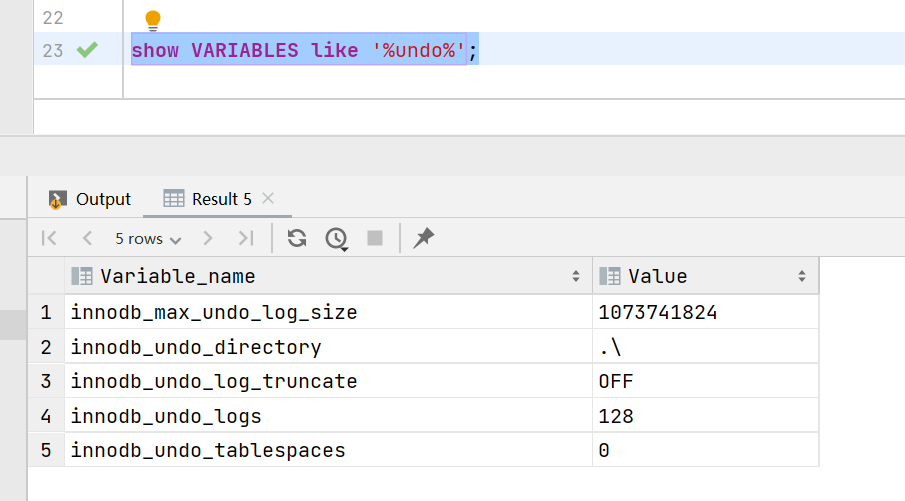
本地存储位置:

show VARIABLES like '%undo%';
bin log是mysql服务端的日志。
binary log 二进制日志,属于mysql服务层的日志。bin log是默认关闭的。
binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
binlog不会记录SELECT和SHOW这类操作,因为这类操作对数据本身并没有修改,但你可以通过查询通用日志来查看MySQL执行过的所有语句。
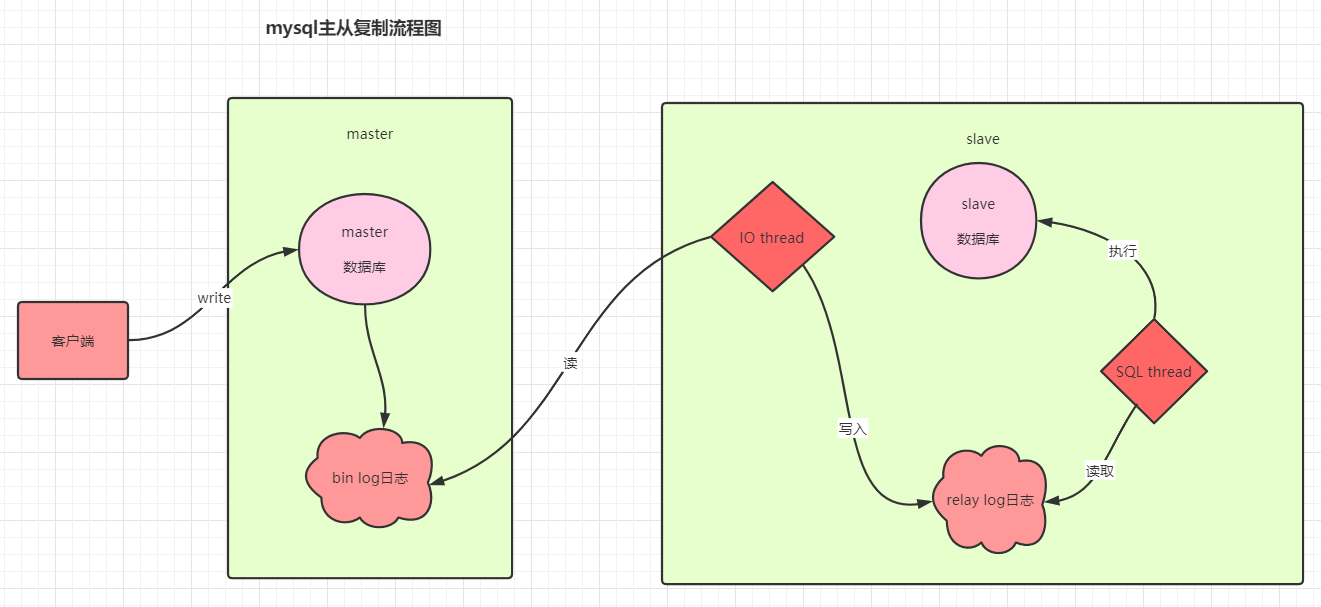
主要作用是主从复制和数据恢复的作用。
特点:
记录DDL和DML的语句,属于逻辑日志
没有固定大小限制,内容可以追加
Server层实现,可以被所有存储引擎使用
用于数据恢复和主从复制。
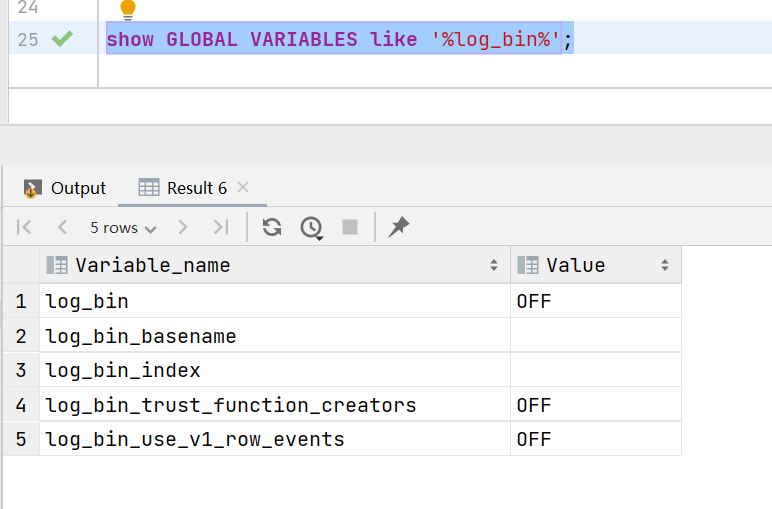
show GLOBAL VARIABLES like '%log_bin%';
bin log主从复制的原理流程图:
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我在用Ruby执行简单任务时遇到了一件奇怪的事情。我只想用每个方法迭代字母表,但迭代在执行中先进行:alfawit=("a".."z")puts"That'sanalphabet:\n\n#{alfawit.each{|litera|putslitera}}"这段代码的结果是:(缩写)abc⋮xyzThat'sanalphabet:a..z知道为什么它会这样工作或者我做错了什么吗?提前致谢。 最佳答案 因为您的each调用被插入到在固定字符串之前执行的字符串文字中。此外,each返回一个Enumerable,实际上您甚至打印它。试试
如何检查Ruby文件是否是通过“require”或“load”导入的,而不是简单地从命令行执行的?例如:foo.rb的内容:puts"Hello"bar.rb的内容require'foo'输出:$./foo.rbHello$./bar.rbHello基本上,我想调用bar.rb以不执行puts调用。 最佳答案 将foo.rb改为:if__FILE__==$0puts"Hello"end检查__FILE__-当前ruby文件的名称-与$0-正在运行的脚本的名称。 关于ruby-检查是否
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我从Ubuntu服务器上的RVM转移到rbenv。当我使用RVM时,使用bundle没有问题。转移到rbenv后,我在Jenkins的执行shell中收到“找不到命令”错误。我内爆并删除了RVM,并从~/.bashrc'中删除了所有与RVM相关的行。使用后我仍然收到此错误:rvmimploderm~/.rvm-rfrm~/.rvmrcgeminstallbundlerecho'exportPATH="$HOME/.rbenv/bin:$PATH"'>>~/.bashrcecho'eval"$(rbenvinit-)"'>>~/.bashrc.~/.bashrcrbenvversions
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我写了一个非常简单的rake任务来尝试找到这个问题的根源。namespace:foodotaskbar::environmentdoputs'RUNNING'endend当在控制台中执行rakefoo:bar时,输出为:RUNNINGRUNNING当我执行任何rake任务时会发生这种情况。有没有人遇到过这样的事情?编辑上面的rake任务就是写在那个.rake文件中的所有内容。这是当前正在使用的Rakefile。requireFile.expand_path('../config/application',__FILE__)OurApp::Application.load_tasks这里
我看到其他人也遇到过类似的问题,但没有一个解决方案对我有用。0.3.14gem与其他gem文件一起存在。我已经完全按照此处指示完成了所有操作:https://github.com/brianmario/mysql2.我仍然得到以下信息。我不知道为什么安装程序指示它找不到include目录,因为我已经检查过它存在。thread.h文件存在,但不在ruby目录中。相反,它在这里:C:\RailsInstaller\DevKit\lib\perl5\5.8\msys\CORE\我正在运行Windows7并尝试在Aptana3中构建我的Rails项目。我的Ruby是1.9.3。$gemin