scroll即滚动查询,我们知道,es中在进行普通的查询时,默认只会查询出来10条数据。我们通过设置es中的size可以将最终的查询结果从10增加到10000,那么问题来了,当我们需要查询的数据大于10000条怎么办?这时有两种方式解决:深度分页和滚动查询。优先使用滚动查询,因为深度分页越往后查性能越低,极其耗费内存和CPU。
分页即使用from和size,如下:
{
"query": {
"match_all": {}
},
"from": 9990,
"size": 20
}像这样就能够获取到9990-10010的20条数据了,但是这样每次都需要将前面的9990条数据查询出来,然后再向下继续寻找后面的20条,最终就会导致搜索很深,即深度分页,性能就会受到极大影响,因此这种方式不推荐使用。
滚动查询,和关系型数据库中的游标有点类似,因此也叫游标查询。也相当于一个快照,它是es中提供的一种查询大数据量的方式。
在dsl语句中,完成一个scroll查询分为两步:
第一步:带有查询条件,根据条件查询。
GET search_account/_search?scroll=1m
{
"size":1000,
"query": {
"term": {
"type": {
"value": "生活"
}
}
}
}这是一个简单的term查询哈,这个查询条件比较简单,相当于一个示意,关键点两个:
① scroll表示这是一个scroll滚动查询;
② scroll=1m表示查询的结果数据在es服务器中过期时间为1min。
该查询返回的结果如下:
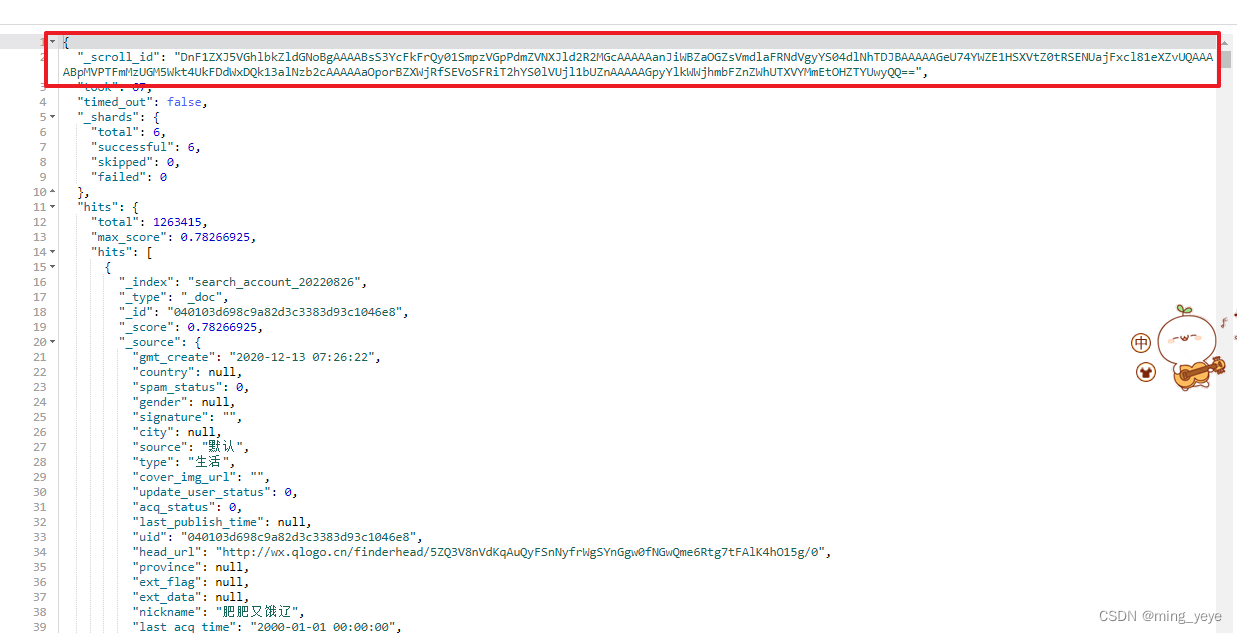
可以看到,返回结果中有一个_scroll_id字段,该字段其实就相当于一个书签,在我们之后的查询中需要带着这个书签,就可以一直往后根据设置的size大小获取数据(前提是在设置的过期时间之内)。
第二步:获取的scroll_id作为查询条件往后查询数据。
GET /_search/scroll/
{
"scroll":"1m",
"scroll_id":"DnF1ZXJ5VGhlbkZldGNoBgAAAABtmn3QFnJNSEk2S2FBVENTQ21JR0dtVXZEbFEAAAAAaePcNhZaOGZsVmdlaFRNdVgyYS04dlNhTDJBAAAAAG2afdEWck1ISTZLYUFUQ1NDbUlHR21VdkRsUQAAAABplHFdFkpvME9pZEd1U0pXdVlSc29CYXFkZHcAAAAAamCmqhZVNXRmNFhlNFN5NjZwMHZraE5ndEV3AAAAAGnj3DcWWjhmbFZnZWhUTXVYMmEtOHZTYUwyQQ=="
}将获取的scroll_id作为条件继续查询即可,不需要再指定索引和类型。因为scroll_id具有唯一性,在过期时间内,之后查询的scroll_id是不变的。
以上说明的是在dsl语句中如何使用scroll,但是既然涉及到大数据量,在dsl中完成就不太可能了,一般都是通过代码的方式进行滚动查询。这里说明一下es中的scroll查询在Springboot中的使用:
环境准备:springboot项目,es依赖,restHighLevelClient客户端配置。(具体配置这里就不赘述了,咱们直接上手)
需求描述:现已经获取了大批账号的uid(20万以上的数据),需要根据这些账号的uid去es中查询账号所属的分类信息。
代码:
public String redoAccountTypeByScroll(List<String> uidList) {
List<List<RedoAccountTypeVO>> resultList=new ArrayList<>();
//构造es查询条件。
SearchRequest searchRequest = new SearchRequest("search_account");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termsQuery("uid",uidList))
//设置最多一次能够取出10000条数据,从第10001条数据开始,将开启滚动查询。
.size(10000)
.fetchSource(new String[]{"uid","type"},null);
searchRequest.source(sourceBuilder);
//设置scroll超时时间(10min)。
Scroll scroll=new Scroll(TimeValue.timeValueMinutes(10L));
//放入滚动查询对象。
searchRequest.scroll(scroll);
SearchResponse response = restHighLevelClient.search(searchRequest);
//TODO:这里可以解析response对象,获取前10000条数据,封装实体类对象(属性为uid和type),并构成集合accountTypeVOList。我这里假设已经解析response对象完成,得到了accountTypeVOList集合。
resultList.add(accountTypeVOList);
//记录滚动id。
String scrollId=response.getScrollId();
//滚动查询部分,将从第10001条数据开始取。
SearchHit[] scrollHits = response.getHits().getHits();
while (ObjectUtil.isNotNull(scrollHits) && scrollHits.length > 0 ) {
//构造滚动查询条件
SearchScrollRequest searchScrollRequest = new SearchScrollRequest(scrollId);
searchScrollRequest.scroll(scroll);
//响应必须是上面的响应对象,需要对上一层进行覆盖。
response = restHighLevelClient.scroll(searchScrollRequest);
scrollId = response.getScrollId();
scrollHits=response.getHits().getHits();
//TODO:同上面一样,在这个位置可以对滚动查询到的从10001条数据开始的数据进行处理(封装实体类),构成集合accountTypeVOList(假设我已经构成了集合)。
resultList.add(accountTypeVOList);
}
//TODO:在循环结束后可以遍历resultList这个大集合,来实现我们自己的需求,我这里是获取账号分类(由于我这里需要调用其它项目完成账号分类的获取,代码就不再贴了,感觉冗余。读者需要明白这里是实现自己的业务需求)。
//数据获取完毕后需要清楚滚动,否则影响下次查询。
ClearScrollRequest clearScrollRequest = new ClearScrollRequest();
clearScrollRequest.addScrollId(scrollId);
ClearScrollResponse clearScrollResponse = restHighLevelClient.clearScroll(clearScrollRequest);
//清除滚动是否成功
boolean isSuccess = clearScrollResponse.isSucceeded();
log.info("=====================>清楚滚动scroll是否成功:{}",isSuccess);
return "==================>账号分类获取完毕~";
}总结:
① 滚动查询是建立在普通查询基础上的。
② 需要注意的是:滚动查询相当于快照,如果在使用scroll进行滚动查询期间有增删改的操作,那么查询结果是获取不到最新的数据的。
③ 深度分页和滚动查询优先使用滚动查询,性能更优,CPU资源耗费更少。
希望对你有所帮助!
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。