在计算机视觉领域,识别大规模图像集合是一个重要的任务。然而,由于数据量大,多样性复杂,传统的机器学习方法在此任务上面临着许多挑战。深度学习方法的出现解决了这一问题,其中卷积神经网络(CNNs)被证明在大规模视觉识别任务中非常有效。
本文介绍了一个基于卷积神经网络的深度学习模型,名为AlexNet。该模型通过在大规模视觉识别挑战(ILSVRC)上获得了最好的成绩,使得深度学习在视觉识别领域受到了广泛的关注。
AlexNet是一个由8个神经网络层组成的深度卷积神经网络模型,用于大规模视觉识别任务。
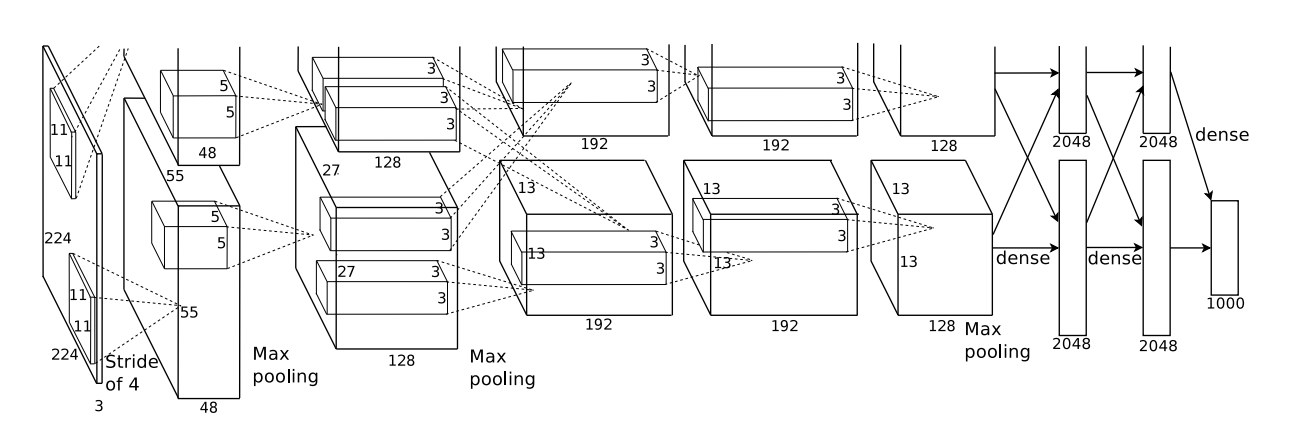
AlexNet使用了5个卷积层和3个池化层,每个卷积层后面紧跟一个ReLU激活函数和一个局部响应归一化(LRN)层。这些卷积层和池化层的作用是通过提取图像的特征,逐渐降低图像的分辨率和复杂性,从而使得后续的全连接层可以更好地处理图像的特征。
AlexNet使用了3个全连接层,其中第三个全连接层的输出是1000个类别的概率分布,对应着ImageNet数据集中的1000个类别。全连接层的作用是将卷积层和池化层提取的特征转化为分类器可以处理的形式。
AlexNet使用了ReLU激活函数,相比于传统的sigmoid函数,ReLU可以在训练过程中加速收敛,并且减少梯度消失问题。此外,为了防止过拟合,AlexNet还采用了Dropout技术和LRN层。Dropout可以随机地丢弃一些神经元,从而减少模型的复杂度,避免过拟合。LRN层可以对神经元的输出进行标准化,使得神经元对输入数据的变化更加鲁棒。
AlexNet还使用了数据增强技术来扩充训练数据集。数据增强的方法包括:随机裁剪、水平翻转、色彩变换等。这些方法可以使得模型更好地适应各种图像变换,提高模型的泛化能力。
在ImageNet LSVRC-2010数据集上,AlexNet模型取得了16.4%的top-5错误率,比排名第二的模型低10.8%。该模型的表现证明了深度卷积神经网络在大规模视觉识别任务中的效果,并且使得深度学习在视觉识别领域受到广泛关注。
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
在该代码中定义了一个名为AlexNet的类,该类继承自nn.Module。在该类的构造函数中,定义了该模型的各个层和参数,其中features是卷积和池化和LRN层,avgpool是自适应平均池化层,classifier是全连接层。在forward函数中,将输入x传入features和avgpool层,并将输出结果压缩成一个向量,最后通过全连接层得到预测结果。
答:AlexNet使用了以下技术手段来提高模型性能:
答:有
答:
答:由于GPU算力飞快发展,在大部分任务中好像已经不需要在进行这样的操作了,但是在自然语言处理领域也可能会出现参数过多模型过大导致单个GPU无法训练的情况,这时候还是要采取多GPU联合训练的方法的。
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我的Rails应用程序中安装了carrierwave。但是,当用户上传多页pdf时,我只希望应用程序获取文档中的第一页并将其转换为jpeg。这可能吗?用什么命令?这是我的uploader。#encoding:utf-8classImageUploader[200,300]##defscale(width,height)##dosomething#end#Createdifferentversionsofyouruploadedfiles:version:thumbdoprocess:resize_to_fill=>[150,210]process:convert=>:jpgdefful
有没有办法跳过CSV文件的第一行,让第二行作为标题?我有一个CSV文件,第一行是日期,第二行是标题,所以我需要能够在遍历它时跳过第一行。我尝试使用slice但它会将CSV转换为数组,我真的很想将其读取为CSV,以便我可以利用header。 最佳答案 根据您的数据,您可以使用另一种方法和skip_lines-option此示例跳过所有以#开头的行require'csv'CSV.parse(DATA.read,:col_sep=>';',:headers=>true,:skip_lines=>/^#/#Markcomments!)do|
我的任务是从数组中选择最高和最低的数字。我想我很清楚我想做什么,但只是努力以正确的格式访问信息以满足通过标准。defhigh_and_low(numbers)array=numbers.split("").map!{|x|x.to_i}array.sort!{|a,b|ba}putsarray[0,-1]end数字可能看起来像"80917234100",要通过,我需要输出"9234"。我正在尝试putsarray.first.last,但一直无法弄明白。 最佳答案 有Array#minmax完全满足您需要的方法:array=[80,
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
或者好像我必须自己写方法?(保持DHA不变):ruby-1.9.2-p180:001>s='omega-3(DHA)'=>"omega-3(DHA)"ruby-1.9.2-p180:002>s.capitalize=>"Omega-3(dha)"ruby-1.9.2-p180:003>s.titleize=>"Omega3(Dha)"ruby-1.9.2-p180:005>s[0].upcase+s[1..-1]=>"Omega-3(DHA)" 最佳答案 如果我的回答只是垃圾,我深表歉意(我不做ruby)。但我相信我已经为您找到了答
我有这个字符串:auteur="comtedeFlandreetHainaut,Baudouin,Jacques,Thierry"我想删除第一个逗号之前的所有内容,即在这种情况下保留“Baudouin,Jacques,Thierry”试过这个:nom=auteur.gsub(/.*,/,'')但这会删除最后一个逗号之前的每个逗号,只保留“Thierry”。 最佳答案 auteur.partition(",").last#=>"Baudouin,Jacques,Thierry" 关于rub
我有一个以时间戳为键的哈希。hash={"2016-05-31T22:30:58+02:00"=>{"path"=>"/","method"=>"GET"},"2016-05-31T22:31:23+02:00"=>{"path"=>"/tour","method"=>"GET"},"2016-05-31T22:31:05+02:00"=>{"path"=>"/contact_us","method"=>"GET"}}我订购了这个系列并得到了第一双这样的:hash.sort_by{|k,_|k}.first.first但是我该如何删除它呢?删除方法requiresyou知道key的准确
我有一个字符串数组,我需要从中提取第一个单词,将它们转换为整数并获得它们的总和。示例:["5Apple","5Orange","15Grapes"]预期输出=>25我的尝试:["5","5","15"].map(&:to_i).sum 最佳答案 我从你的问题中找到了答案。["5Apple","5Orange","15Grapes"].map(&:to_i).sum在数组中,如果存在任何整数可转换值,那么它将自动转换为整数。 关于arrays-字符串数组中字符串第一部分的总和,我们在Sta