对于线性方程组求解,我们一般写成矩阵形式 Ax = y。
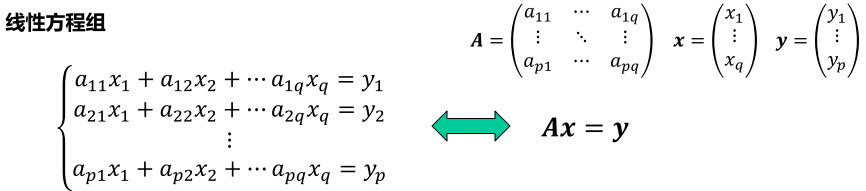
当矩阵A满秩(即这q个变量是线性无关的)时:
p<q 时,为欠定方程组,方程个数少于未知数个数,有多解;
p=q 时,为方阵,方程个数等于未知数个数,有唯一解;
p>q 时,为超定方程组,方程个数多于未知数个数,无解(除非y可以由A的列向量线性表示);
我们实际中,需要使用多个方程组,以降低噪声对求解过程的影响,得到近似最优解。p>q时,定义误差函数E(x):
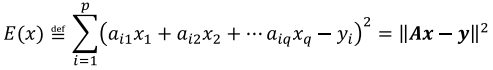
线性方程组的最小二乘解为:
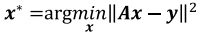
有以下三种求解方法:

方法1,需要求解A的逆,计算量大。方法2,不用求逆。方法三需要迭代。所以一般,选择方法2。
齐次线性方程组的特点是右边表达式全为0,写成矩阵形式为 Ax = 0。
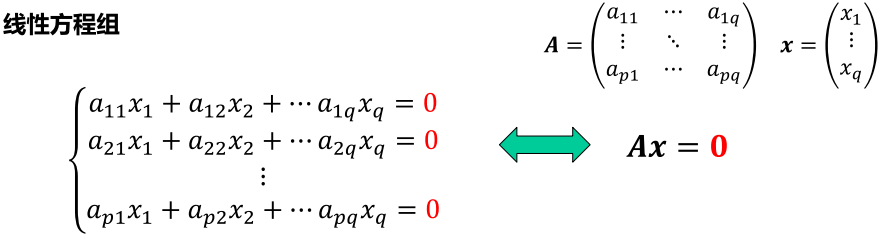
当矩阵A满秩时:
p<q 时,为欠定方程组,方程个数少于未知数个数,有多解;
p=q 时,方程个数等于未知数个数,只有零解;
p>q 时,为超定方程组,方程个数多于未知数个数,除零解外无解;
PS:如果 x 是方程组的解,对于任意 k != 0,kx也是方程组的解。
当 p>q是时,定义误差函数 E(x):
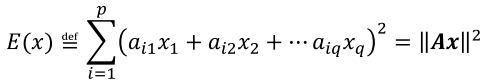
齐次方程的最小二乘解,为了求解唯一值,增加约束 ||x||=1 ,所以齐次方程解与真实解永远相差一个放大系数:
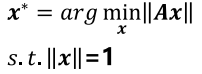
求解方法(奇异值分解):

PS:或者拉格朗日求解。
一般系统,有 p 个方程,q 个变量。f 为非线性函数。
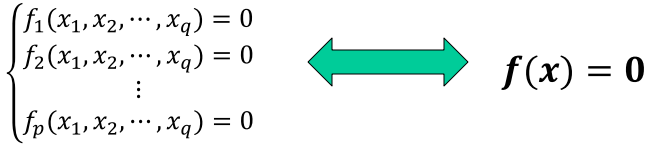
当 p > q 时的最小二乘解:
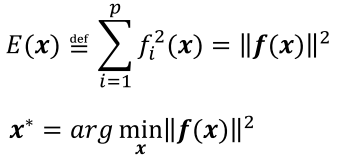
解法:牛顿法与列文伯格-马夸尔特法(L-M方法)
1)从初始解开始迭代,若初始解与实际相距较远,可能会很慢;
2)估计解可能是初始解的函数(由于局部最小值);
3)牛顿法需计算一阶段到矩阵J(雅克比矩阵),二阶导矩阵H(海塞矩阵);
4)L-M算法不用计算H。
实际中使用时,有现成的包可以调用,不用担心计算过程。
为什么以下不同?Time.now.end_of_day==Time.now.end_of_day-0.days#falseTime.now.end_of_day.to_s==Time.now.end_of_day-0.days.to_s#true 最佳答案 因为纳秒数不同:ruby-1.9.2-p180:014>(Time.now.end_of_day-0.days).nsec=>999999000ruby-1.9.2-p180:015>Time.now.end_of_day.nsec=>999999998
假设我有以下类(class):classPersondefinitialize(name,age)@name=name@age=ageenddefget_agereturn@ageendend我有一组Person对象。是否有一种简洁的、类似于Ruby的方法来获取最小(或最大)年龄的人?如何根据它对它们进行排序? 最佳答案 这样做会:people_array.min_by(&:get_age)people_array.max_by(&:get_age)people_array.sort_by(&:get_age)
看来我正在回顾SO帖子中采取的步骤:Capybara,PoltergeistandPhantomjsandgivinganemptyresponseinbody.(如果你愿意,可以将其标记为重复,但我包含了一个最小的独立测试用例和版本号。)问题我做错了什么吗?我可以运行另一个可能有助于隔离问题的最小测试吗?文件:pgtest.rbrequire'rubygems'require'capybara'require'capybara/dsl'require'capybara/poltergeist'modulePGTestincludeCapybara::DSLextendselfdeft
你好,Stackoverflow的人们,我经营一个网站,为用户寻找最便宜的书籍购买地点。这对于单本书来说很容易,但对于多本书来说,有时在一家商店购买一本书而在另一家商店购买另一本书会更便宜。目前我找到了销售用户列表中所有书籍的最便宜的商店,但我想要一个更智能的系统。这里有更多信息:一本书的价格对于一家商店来说是不变的。运费可能会有所不同,具体取决于书籍的数量或书籍的总值(value)。每个商店对象都可以获取一组书籍并返回运费。通常,并非每家书店都出售每一本书。不确定在这里链接到我的站点是否很酷,但它列在我的用户配置文件中。我希望能够找到最便宜的商店和书籍组合。我担心这需要一种蛮力方法-
我编写了一个非常简单的Sassmixin,用于将像素值转换为rem值(请参阅JonathanSnook的articleonthebenefitsofusingrems)。这是代码://MixinCode$base_font_size:10;//10px@mixinrem($key,$px){#{$key}:#{$px}px;#{$key}:#{$px/$base_font_size}rem;}//Includesyntaxp{@includerem(font-size,14);}//RenderedCSSp{font-size:14px;font-size:1.4rem;}这个mixi
是否有Ruby库允许我对一组数据进行线性或非线性最小二乘法逼近。我想做的是:给定一系列[x,y]数据点针对该数据生成线性或非线性最小二乘法近似值库不必弄清楚它是否需要进行线性或非线性近似。库的调用者应该知道他们需要什么类型的回归我不想尝试移植某些C/C++/Java库来获得此功能,因此我希望有一些现有的Ruby库可供我使用。 最佳答案 尝试使用“statsample”gem。您可以使用下面提供的示例执行对数、指数、幂或任何其他转换。我希望这有帮助。require'statsample'#IndependentVariablex_da
嗨,假设我有一个table(ads),其中有一个column(views)观看次数21463如何找到该列中的最小值?有什么简单的方法可以做到这一点?这就是我的@ads=Ad.all@show_this_ad=@ads.min(:views)这给了我一个“参数数量错误(1代表0)错误”@ads=Ad.all@show_this_ad=@ads.minimum(:views)这给了我一个“未定义的方法错误” 最佳答案 Ad.minimum(:views)应该可以您仍然可以添加更多限制,例如:Ad.where(:user_id=>1234
我知道,在Ruby中,您可以使用Integer#lcm求两个数的最小公倍数的方法。例如:10.lcm(15)#=>30是否有一种有效的(或内置于核心或标准库中)方法来获取给定数组中所有整数的最小公倍数?例如:[5,3,10,2,20].lcm#=>60 最佳答案 任何需要两个操作数的操作都可以通过folding迭代地应用于一个集合它:Enumerable#inject/reduce.为了覆盖空情况,将identityelement作为第一个参数传递操作的最小公分母为1。[5,3,10,2,20].reduce(1){|acc,n|a
有什么办法可以更优雅地重写这个吗?我认为,这是一段糟糕的代码,应该重构。>>a=[2,4,10,1,13]=>[2,4,10,1,13]>>index_of_minimal_value_in_array=a.index(a.min)=>3 最佳答案 我相信这只会遍历数组一次并且仍然很容易阅读:numbers=[20,30,40,50,10]#=>[20,30,40,50,10]elem,idx=numbers.each_with_index.min#=>[10,4] 关于Ruby:如何找
我想使用min(5,10)或Math.max(4,7)。Ruby中有实现这种效果的函数吗? 最佳答案 你可以做到[5,10].min或[4,7].max它们来自Enumerablemodule,因此任何包含Enumerable的内容都将具有可用的方法。v2.4引入了自己的Array#min和Array#max,它们比Enumerable的方法快得多,因为它们跳过调用#each.@nicholasklick提到了另一个选项,Enumerable#minmax,但这次返回一个[min,max]数组。[4,5,7,10].minmax=>