在我们进行计算的过程中,经常会遇到几十位,甚至几百位的数字的计算问题,也有可能会遇到小数点后几十位,几百位的情况,而我们面对这样的情况下,
和
的数据范围显然是不够使用的了。因此这时,我们就需要引入一个新的算法,叫做高精度算法 .
我们可以利用程序设计的方法去实现这样的高精度计算 . 介绍常用的几种高精度计算的方法 .
高精度算法本质上是用字符串模拟数字进行计算,再利用类似于数学里的竖式的形式,一位一位进行相关计算 .
高精度计算中需要处理好以下几个问题:
1)数据的接收方法和存储方法
数据的接收和存储:当输入的数很长时,可采用字符串方式输入,这样可输入位数很长的数,利用字符串函数和操作运算,将每一位取出,存入数组中 .
void init(int a[]) { // 传入数组
string s;
cin >> s;
len = s.length(); // s.length --> 计算字符串位数
for(int i=1; i<=len; i++)
a[i] = s[len -i] - '0'; //将字符串s转换为数组a, 倒序存储
}2)进位、借位的处理.
// 加法进位: c[i] = a[i] + b[i]
code: if(c[i] >= 10) {
c[i] %= 10;
++c[i++];
}
//减法借位: c[i] = a[i] - b[i]
code: if(a[i] < b[i]) {
--a[i+1];
a[i] += 10;
}
//乘法进位: c[i + j - 1] = a[i] * b[j] + x + c[i + j - 1];
x = c[i + j - 1] / 10;
c[i + j - 1] % 10;输入两个数到变量中,然后用赋值语句求它们的和后输出 . But,我们知道,在 C++ 语言中任何数据类型都有一定表示范围. 当两个加数很大时,以前的算法显然不能求出精确解,因此我们需要寻求另一种方法 .在读小学时,我们做加法都采用竖式方法 . 这样我们方便写出两个整数相加的算法 .
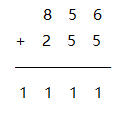
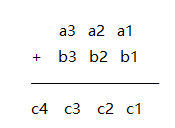
如果我们用数组分别储存两个加数,用数组
储存结果。则上例有 :
#include <cstdio>
#include <cstring>
using namespace std;
int main() {
char a1[5005], b1[5005]; //用字符存储数字
int a[5005], b[5005], c[5005]; //c[i] 用来储存每位相加的结果
int len_a, len_b, len_c = 1, x, i;
memset(a, 0, sizeof(a));
memset(b, 0, sizeof(b));
memset(c, 0, sizeof(c));
scanf("%s%s", a1, b1); //输入两个加数
len_a = strlen(a1);
len_b = strlen(b1);
for(i=0; i<len_a; i++) a[len_a - i] = a1[i] - '0'; // 将加数放进a数组
for(i=0; i<len_b; i++) b[len_b - i] = b1[i] - '0'; // 将另一个加数放进b数组
x = 0; // x为进位
while(len_c <= len_a || len_c <= len_b) {
c[len_c] = a[len_c] + b[len_c] + x; // 两数相加,再加上前两个数进位的
x = c[len_c] / 10; // 刷新进位
c[len_c] %= 10; // 进位后剩下的
len_c++; //位数加1
}
c[len_c] = x;
if(c[len_c] == 0) { //判断首位是否为0
len_c--; // 不输出此位
}
for(int i=len_c; i>=1; i--) {
printf("%d", c[i]); //输出每一位的数
}
return 0;
}
类似加法,同样使用竖式。在做减法运算时,需要注意的是:需要有借位处理。
#include <iostream>
#include <cstring>
int main() {
int a[5005], b[5005], c[5005];
int lena, lenb, lenc, i;
char n[5005], n1[5005], n2[5005];
std::memset(a, 0, sizeof(a));
std::memset(b, 0, sizeof(b));
std::memset(c, 0, sizeof(c));
std::cin >> n1 >> n2; //输入被减数和减数
lena = std::strlen(n1);
lenb = std::strlen(n2);
for(i=0; i<lena; i++) a[lena - i] = (int)n1[i] - '0';
for(i=0; i<lenb; i++) b[lenb - i] = (int)n2[i] - '0'; //逆序存放排列
i = 1;
while(i <= lena || i <= lenb) {
if(a[i] < b[i]) {
c[i] = a[i] + 10 - b[i];
a[i+1]--; //借位处理
}
else {
c[i] = a[i] - b[i];
}
i++;
}
lenc = i;
while(c[lenc] == 0 && lenc > 1) { //如果最后一位是0,是需要输出的
lenc--; // 不输出首位0
}
for(i=lenc; i>=1; i--) std::cout << c[i];
return 0;
}
类似加法,使用竖式。在做乘法时,同样也有进位。
分析 数组的下标变化规律,可以写出以下关系式:
由此可见, 跟
乘积有关,跟上次的进位有关,跟还原
的值有关,分析下标规律,有 :
#include <iostream>
#include <cstring>
int main() {
int a[105], b[105], c[10005];
char n1[105], n2[105], lena, lenb, lenc, j, i, x;
std::memset(a, 0, sizeof(a));
std::memset(b, 0, sizeof(b));
std::memset(c, 0, sizeof(c));
std::cin >> n1 >> n2;
lena = std::strlen(n1);
lenb = std::strlen(n2);
for(i=0; i<=lena-1; i++) a[lena - i] = n1[i] - 48;
for(i=0; i<=lenb-1; i++) b[lenb - i] = n2[i] - 48; // 倒序储存
for(i=1; i<=lena; i++) {
x = 0;
for(j=1; j<=lenb; j++) {
c[i + j - 1] = c[i + j - 1] + x + a[i] * b[j];
x = c[i + j - 1] / 10; // 进位
c[i + j - 1] %= 10; // 剩余
}
c[i + lenb] = x; // 进位的数
}
lenc = lena + lenb;
while(c[lenc] == 0 && lenc > 1) {
lenc--; // 删除前导0
}
for(i=lenc; i>=1; i--) {
std::cout << c[i];
} // 输出每一位
std::cout << std::endl;
return 0;
} 做除法时,每一次的商值都在 0~9 之间,每次求得的余数连接以后的若干位得到新的被除数,继续做除法。因此,在做高精度除法时,要涉及到乘法运算和减法运算,还有移位处理。当然,为了程序简洁,可以避免高精度乘法,用 0~9 次循环减法取代得到商的值。采用按位相除法。
#include <iostream>
int main(){
char n1[100];
int a[100], c[100], lena, i, x = 0, lenc, b;
std::memset(a, 0, sizeof(a));
std::memset(c, 0, sizeof(c));
std::cin >> n1 >> b;
lena = strlen(n1);
for(i=1; i<=lena; i++) {
a[i] = n1[i - 1] - '0'; //除法不需要逆序存放
}
//-------------------------初始化------------------------------
for(i=1; i<=lena; i++) {
c[i] = (a[i] + x * 10) / b; // 算上上一位剩下的继续除
x = (a[i] + 10 * x) % b; // 求余
}
lenc = 1;
while(c[lenc] == 0 && lenc < lena) {
lenc++;
}
for(i=lenc; i<lena; i++) std::cout << c[i];
return 0;
}高精除以低精是对被除数的每一位(这里的"一位"包含前面的余数,以下都是如此)都除以除数,而高精除以高精则使用减法模拟除法,对被除数的每一位都减去除数,一直减到当前位置的数字(包含前面的余数)小于除数(由于每一位的数字小于10,所以对每一位最多进行10次运算),代码如下:
#include <cstdio>
#include <iostream>
#include <cstring>
using namespace std;
int a[50005], b[50005], c[50005], d;
void init(int a[]) {
char s[50005];
cin >> s;
a[0] = strlen(s); // 字符串存储,表示位数
for (int i=1; i<=a[0]; i++) {
a[i] = s[a[0]-i] - 48; // 正序储存
}
}
void print(int a[]) {
if (a[0] == 0) {
cout << 0 << endl;
return; // 位数为0,输出0
}
for (int i=a[0]; i>=1; i--) {
cout << a[i]; // 输出函数
}
cout << endl;
return;
}
int compare(int a[], int b[]) {
if (a[0] > b[0]) {
return 1; // 被减数大于减数
}
if (a[0] < b[0]) {
return -1; // 被减数小于减数
}
for (int i=a[0]; i>=1; i--) {
if (a[i] > b[i]) {
return 1;
}
if (a[i] < b[i]) {
return -1;
} // 位数相同,找到第一位不同的进行比较
}
return 0;
}
void numcpy(int p[], int q[], int det) {
for (int i=1; i<=p[0]; i++) {
q[i+det-1] = p[i]; //复制p数组到q数组从det开始的地方
}
q[0] = p[0] + det - 1;
}
void jian(int a[], int b[]) {
int flag = compare(a, b);
if (flag == 0) {
a[0] = 0;
return;
}
if (flag == 1) {
for (int i=1; i<=a[0]; i++) {
if (a[i] < b[i]) {
a[i+1]--;
a[i] += 10;
}
a[i] -= b[i];
}
while (a[0]>0 && a[a[0]]==0) {
a[0]--;
}
return;
}
} // 高精减法
void chugao(int a[], int b[], int c[]) {
int tmp[50005];
c[0] = a[0] - b[0] + 1;
for (int i=c[0]; i>0; i--) {
memset(tmp, 0, sizeof(tmp));
numcpy(b, tmp, i);// 清零
while (compare(a, tmp) >= 0) {
c[i]++;
jian(a, tmp); // 用减法模拟
}
}
while (c[0] > 0 && c[c[0]] == 0) {
c[0]--;
}
return;
}
int main() {
memset(a, 0, sizeof(a));
memset(b, 0, sizeof(b));
memset(c, 0, sizeof(c));
init(a);
init(b);
chugao(a,b,c);
print(c);
return 0;
}如果这篇文章对你有帮助的话,请来个三连~~你们的支持是对我max(鼓 励)🤑
目录一.加解密算法数字签名对称加密DES(DataEncryptionStandard)3DES(TripleDES)AES(AdvancedEncryptionStandard)RSA加密法DSA(DigitalSignatureAlgorithm)ECC(EllipticCurvesCryptography)非对称加密签名与加密过程非对称加密的应用对称加密与非对称加密的结合二.数字证书图解一.加解密算法加密简单而言就是通过一种算法将明文信息转换成密文信息,信息的的接收方能够通过密钥对密文信息进行解密获得明文信息的过程。根据加解密的密钥是否相同,算法可以分为对称加密、非对称加密、对称加密和非
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
我正在尝试使用正则表达式验证美元金额:^[0-9]+\.[0-9]{2}$这工作正常,但每当用户提交表单并且美元金额以0(零)结尾时,ruby(或rails?)将0砍掉。所以500.00变成500.0,因此正则表达式验证失败。有没有办法让ruby/rails保持用户输入的格式,而不管尾随零? 最佳答案 我假设您的美元金额是小数类型。因此,用户在字段中输入的任何值在保存到数据库之前都会从字符串转换为适当的类型。验证适用于已转换为数字类型的值,因此在您的情况下,正则表达式并不是真正合适的验证过滤器。不过,您有几种可能性可以解决这个问
1.问题描述使用Python的turtle(海龟绘图)模块提供的函数绘制直线。2.问题分析一幅复杂的图形通常都可以由点、直线、三角形、矩形、平行四边形、圆、椭圆和圆弧等基本图形组成。其中的三角形、矩形、平行四边形又可以由直线组成,而直线又是由两个点确定的。我们使用Python的turtle模块所提供的函数来绘制直线。在使用之前我们先介绍一下turtle模块的相关知识点。turtle模块提供面向对象和面向过程两种形式的海龟绘图基本组件。面向对象的接口类如下:1)TurtleScreen类:定义图形窗口作为绘图海龟的运动场。它的构造器需要一个tkinter.Canvas或ScrolledCanva
目录H2数据库入门以及实际开发时的使用1.H2数据库的初识1.1H2数据库介绍1.2为什么要使用嵌入式数据库?1.3嵌入式数据库对比1.3.1性能对比1.4技术选型思考2.H2数据库实战2.1H2数据库下载搭建以及部署2.1.1H2数据库的下载2.1.2数据库启动2.1.2.1windows系统可以在bin目录下执行h2.bat2.1.2.2同理可以通过cmd直接使用命令进行启动:2.1.2.3启动后控制台页面:2.1.3spring整合H2数据库2.1.3.1引入依赖文件2.1.4数据库通过file模式实际保存数据的位置2.2H2数据库操作2.2.1Mysql兼容模式2.2.2Mysql模式
Ruby到底是怎么做到的?Jörg或其他人是否知道幕后发生的事情?不幸的是,我不太了解C,所以bignum.c对我帮助不大。我只是有点好奇有人可以解释(用简单的英语)它使用的任何神奇算法背后的理论。irb(main):001:0>999**99936806348825922326789470084006052186583833823203735320465595962143702560930047223153010387361450517521869134525758989639113039318944796977164583238219236607653663113200177617
我一直在尝试用Ruby实现Luhn算法。我一直在执行以下步骤:该公式根据其包含的校验位验证数字,该校验位通常附加到部分帐号以生成完整帐号。此帐号必须通过以下测试:从最右边的校验位开始向左移动,每第二个数字的值加倍。将乘积的数字(例如,10=1+0=1、14=1+4=5)与原始数字的未加倍数字相加。如果总模10等于0(如果总和以零结尾),则根据Luhn公式该数字有效;否则无效。http://en.wikipedia.org/wiki/Luhn_algorithm这是我想出的:defvalidCreditCard(cardNumber)sum=0nums=cardNumber.to_s.s
下面是我写的一个计算斐波那契数列中的值的方法:deffib(n)ifn==0return0endifn==1return1endifn>=2returnfib(n-1)+(fib(n-2))endend它工作到n=14,但在那之后我收到一条消息说程序响应时间太长(我正在使用repl.it)。有人知道为什么会这样吗? 最佳答案 Naivefibonacci进行了大量的重复计算-在fib(14)fib(4)中计算了很多次。您可以将内存添加到您的算法中以使其更快:deffib(n,memo={})ifn==0||n==1returnnen
我目前有一个运行Ruby1.8.7和Rails2.3.2的RubyonRails项目我有一些从数据库中读取数据的单元测试,特别是两个连续项目的日期时间列,这两个项目应该相隔24小时。在一项测试中,我将项目2的日期时间设置为与项目1的日期时间相同。当我执行断言以确保两个值相等时,测试在rails2.3.2下工作正常。当我升级到rails2.3.11时,测试失败显示两次之间的差异将关闭并出现以下错误:expectedbutwas.这两个版本的rails中似乎存在浮点转换问题。如何解决float问题? 最佳答案 这也发生在我身上,我最终这