本文来源:知乎
大家好,我是脚丫先生 (o^^o)
最近小伙伴们,有问到大数据工程师岗位平常的日常工作都是干嘛的?

大数据或者说想入门大数据,技术肯定是第一重要的,不会大数据的技术谈什么大数据。那么大数据的技术怎么学,要知道大数据是依赖Java的,首先要保证Java得会。
一个项目一般包含:前端,后端,后后端,大数据属于后后端,是在项目开发完成之后有了数据之后才到大数据这一步。从上帝视角看张图:
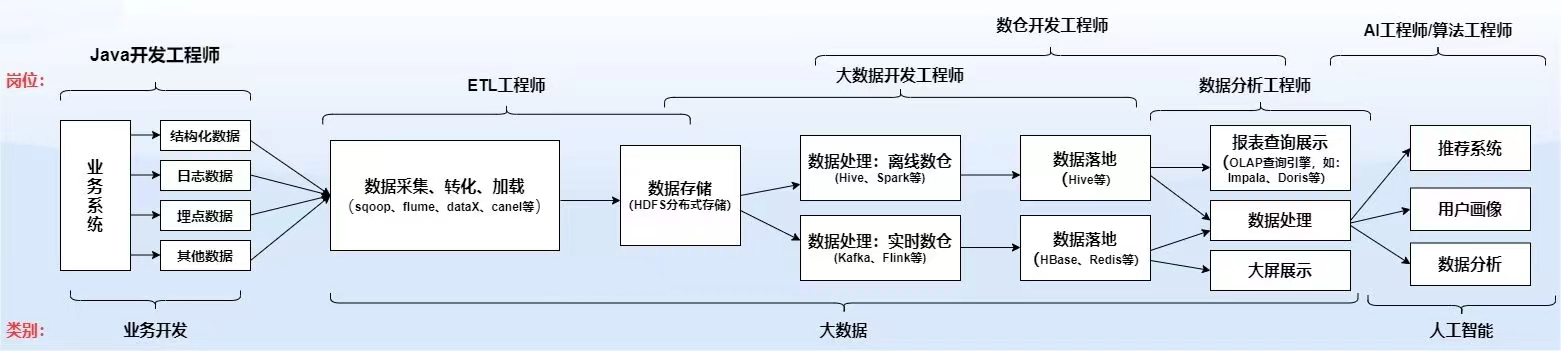
大数据工作分为图上这几种,和后端接触的是ETL工程师,负责将数据拿到大数据平台,然后供数仓开发工程师使用,大数据开发负责大数据平台的建设,后面还有数据分析师,AI工程师等。
数仓工程师日常工作一般是不写代码的,主要以写 SQL 为主!
数仓工程师是大数据领域公司招聘较多的岗位,薪资也较高,需要重点关注!数据仓库分为离线数仓和实时数仓,但是企业在招聘时大多要求两者都会,进入公司之后可能会专注于离线或实时其中之一。
就目前来说,大多数的企业还是以离线数仓为主,不过未来趋势肯定是实时数仓为主,所以学习时,为了现在能找到工作,需要学习离线数仓,为了以后的发展,需要学习实时数仓。
所以,离线和实时都是我们重点掌握的!需要掌握的技能:
不管离线还是实时,重中之重就是:SQL
SQL 语法及调优一定要掌握,这里说的SQL包括mysql中的 sql,hive中的 hive sql,spark中的spark sql,flink中的 flink sql。
在企业招聘的笔记及面试中,一般问的关于 sql 的问题主要是以 hive sql 为主,所以请重点关注!
除sql外,还需要重点掌握以下技能,分为离线和实时
离线数仓需要重点掌握的技能:
实时数仓需要重点掌握的技能:
数据开发工程师一般是以写代码为主,以 Java 和 Scala 为主。
大数据开发分两类,第一类是编写Hadoop、Spark、Flink 的应用程序,第二类是对大数据处理系统本身进行开发,如对开源框架的扩展开发,数据中台的开发等!
需要重点掌握的技能:
通过以上技能,我们也能看出,数据开发和数仓开发的技能重复率较高,所以很多公司招聘时 大数据开发和数仓建设分的没有这么细,数据开发包含了数仓的工作!
ETL是三个单词的首字母,中文意思是抽取、转换、加载从开始的图中也能看出,ETL工程师是对接业务和数据的交接点,所以需要处理上下游的关系对于上游,需要经常跟业务系统的人打交道,所以要对业务系统比较熟悉。
比如它们存在各种接口,不管是API级别还是数据库接口,这都需要ETL工程师非常了解。
其次是其下游,这意味着你要跟许多数据开发工程师师、数据科学家打交道。比如将准备好的数据(数据的清洗、整理、融合),交给下游的数据开发和数据科学家。
需要重点掌握的技能。
在数据工程师准备好数据维护好数仓后,数据分析师就上场了。
分析师们会根据数据和业务情况,分析得出结论、制定业务策略或者建立模型,创造新的业务价值并支持业务高效运转。
同时数据分析师在后期还有数据爬虫、数据挖掘和算法工程师三个分支。
需要重点掌握的技能:
1 写 SQL (很多入职一两年的大数据工程师主要的工作就是写 SQL )。
2 为集群搭大数据环境(一般公司招大数据工程师环境都已经搭好了,公司内部会有现成的大数据平台,但我这边会私下搞一套测试环境,毕竟公司内部的大数据系统权限限制很多,严重影响开发效率)
3 维护大数据平台(这个应该是每个大数据工程师都做过的工作,或多或少会承担“运维”的工作)
4 数据迁移(有部分公司需要把数据从传统的数据库 Oracle、MySQL 等数据迁移到大数据集群中,这个是比较繁琐的工作,吃力不讨好)
5 应用迁移(有部分公司需要把应用从传统的数据库 Oracle、MySQL 等数据库的存储过程程序或者SQL脚本迁移到大数据平台上,这个过程也是非常繁琐的工作,无聊,高度重复且麻烦,吃力不讨好)
6 数据采集(采集日志数据、文件数据、接口数据,这个涉及到各种格式的转换,一般用得比较多的是 Flume 和 Logstash)
7 数据处理
7.1 离线数据处理(这个一般就是写写 SQL 然后扔到 Hive 中跑,其实和第一点有点重复了)
7.2 实时数据处理(这个涉及到消息队列,Kafka,Spark,Flink 这些,组件,一般就是 Flume 采集到数据发给 Kafka 然后 Spark 消费 Kafka 的数据进行处理)
8 数据可视化(这个我司是用 Spring Boot 连接后台数据与前端,前端用自己魔改的 echarts)
9 大数据平台开发(偏Java方向的,大概就是把开源的组件整合起来整成一个可用的大数据平台这样,常见的是各种难用的 PaaS 平台)
10 数据中台开发(中台需要支持接入各种数据源,把各种数据源清洗转换为可用的数据,然后再基于原始数据搭建起宽表层,一般为了节省开发成本和服务器资源,都是基于宽表层查询出业务数据)
11 搭建数据仓(离线数仓和实时数仓)
总之就是离不开写 SQL …
好了,今天就聊到这里,祝各位终有所成,收获满满!
更多精彩内容请关注 微信公众号 👇「大数据指北」🔥:
一枚热衷于分享大数据基础原理,技术实战,架构设计与原型实现之外,还喜欢输出一些个人私活案例。
更多精彩福利干货,期待您的关注 ~
我在从html页面生成PDF时遇到问题。我正在使用PDFkit。在安装它的过程中,我注意到我需要wkhtmltopdf。所以我也安装了它。我做了PDFkit的文档所说的一切......现在我在尝试加载PDF时遇到了这个错误。这里是错误:commandfailed:"/usr/local/bin/wkhtmltopdf""--margin-right""0.75in""--page-size""Letter""--margin-top""0.75in""--margin-bottom""0.75in""--encoding""UTF-8""--margin-left""0.75in""-
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我花了三天的时间用头撞墙,试图弄清楚为什么简单的“rake”不能通过我的规范文件。如果您遇到这种情况:任何文件夹路径中都不要有空格!。严重地。事实上,从现在开始,您命名的任何内容都没有空格。这是我的控制台输出:(在/Users/*****/Desktop/LearningRuby/learn_ruby)$rake/Users/*******/Desktop/LearningRuby/learn_ruby/00_hello/hello_spec.rb:116:in`require':cannotloadsuchfile--hello(LoadError) 最佳
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion在首页我有:汽车:VolvoSaabMercedesAudistatic_pages_spec.rb中的测试代码:it"shouldhavetherightselect"dovisithome_pathit{shouldhave_select('cars',:options=>['volvo','saab','mercedes','audi'])}end响应是rspec./spec/request
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我正在尝试解析一个CSV文件并使用SQL命令自动为其创建一个表。CSV中的第一行给出了列标题。但我需要推断每个列的类型。Ruby中是否有任何函数可以找到每个字段中内容的类型。例如,CSV行:"12012","Test","1233.22","12:21:22","10/10/2009"应该产生像这样的类型['integer','string','float','time','date']谢谢! 最佳答案 require'time'defto_something(str)if(num=Integer(str)rescueFloat(s