
在本文章,我们将了解如何通过几个步骤在 Elastic 中实施相似图像搜索。 开始设置应用程序环境,然后导入 NLP 模型,最后完成为你的图像集生成嵌入。
第一步是为你的应用程序设置环境。 一般要求包括:
使用数百张图像以确保获得最佳效果非常重要。
转到工作文件夹并检查创建的存储库代码。 然后导航到存储库文件夹。
git clone https://github.com/radoondas/flask-elastic-image-search.git
cd flask-elastic-image-search$ git clone https://github.com/radoondas/flask-elastic-image-search.git
Cloning into 'flask-elastic-image-search'...
remote: Enumerating objects: 105, done.
remote: Counting objects: 100% (105/105), done.
remote: Compressing objects: 100% (72/72), done.
remote: Total 105 (delta 37), reused 94 (delta 27), pack-reused 0
Receiving objects: 100% (105/105), 20.72 MiB | 9.75 MiB/s, done.
Resolving deltas: 100% (37/37), done.
$ cd flask-elastic-image-search/
$ pwd
/Users/liuxg/python/flask-elastic-image-search因为你将使用 Python 来运行代码,所以你需要确保满足所有要求并且环境已准备就绪。 现在创建虚拟环境并安装所有依赖项。
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
如果你还没有安装好自己的 Elasticsearch 及 Kibana,请参考如下的文章来进行安装:
特别注意的是:我们将以最新的 Elastic Stack 8.6.1 来进行展示。请参考 Elastic Stack 8.x 的文章进行安装。
由于上传模型是一个白金版的功能,我们需要启动试用功能。更多关于订阅的信息,请参考网址:订阅 | Elastic Stack 产品和支持 | Elastic。
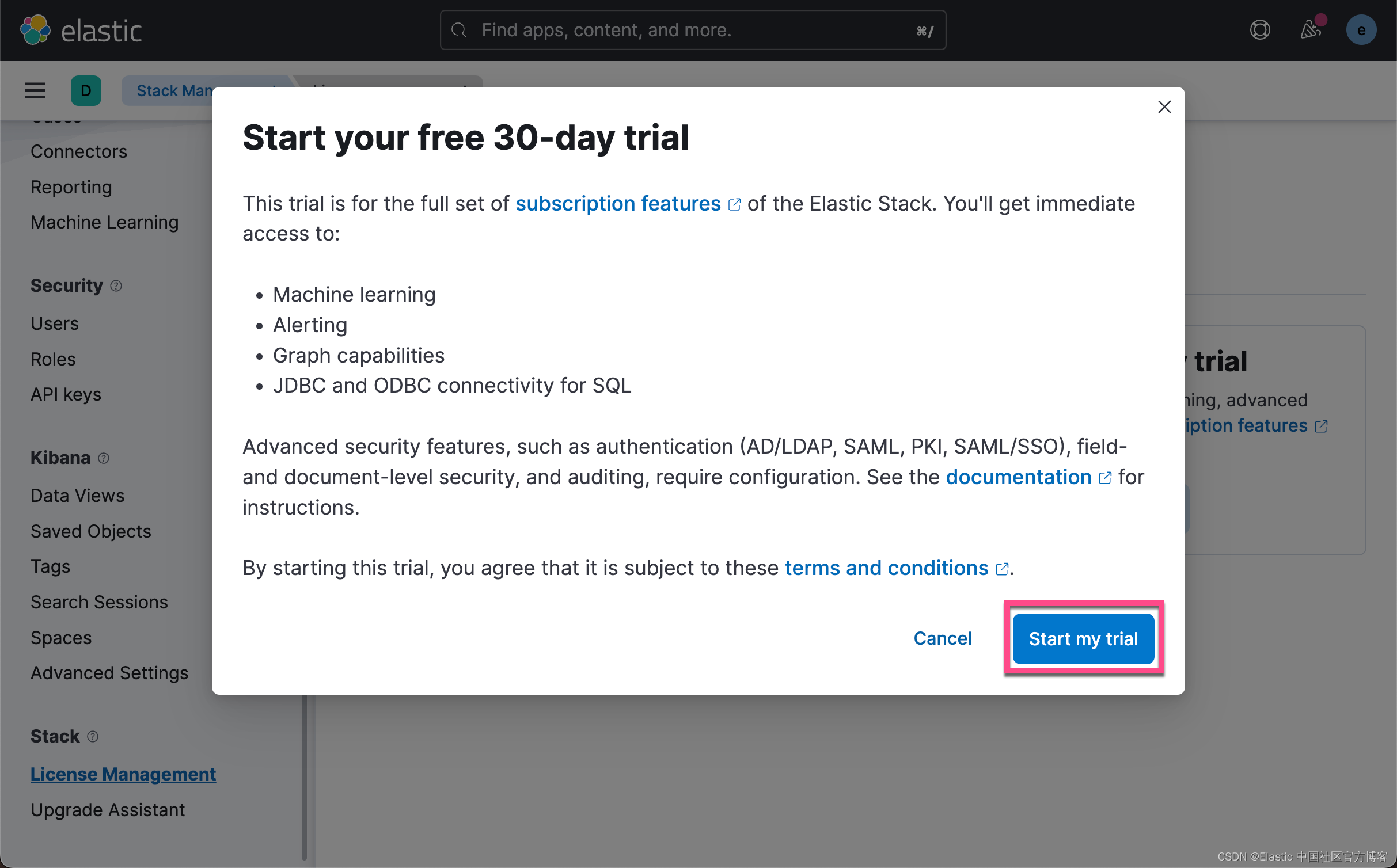
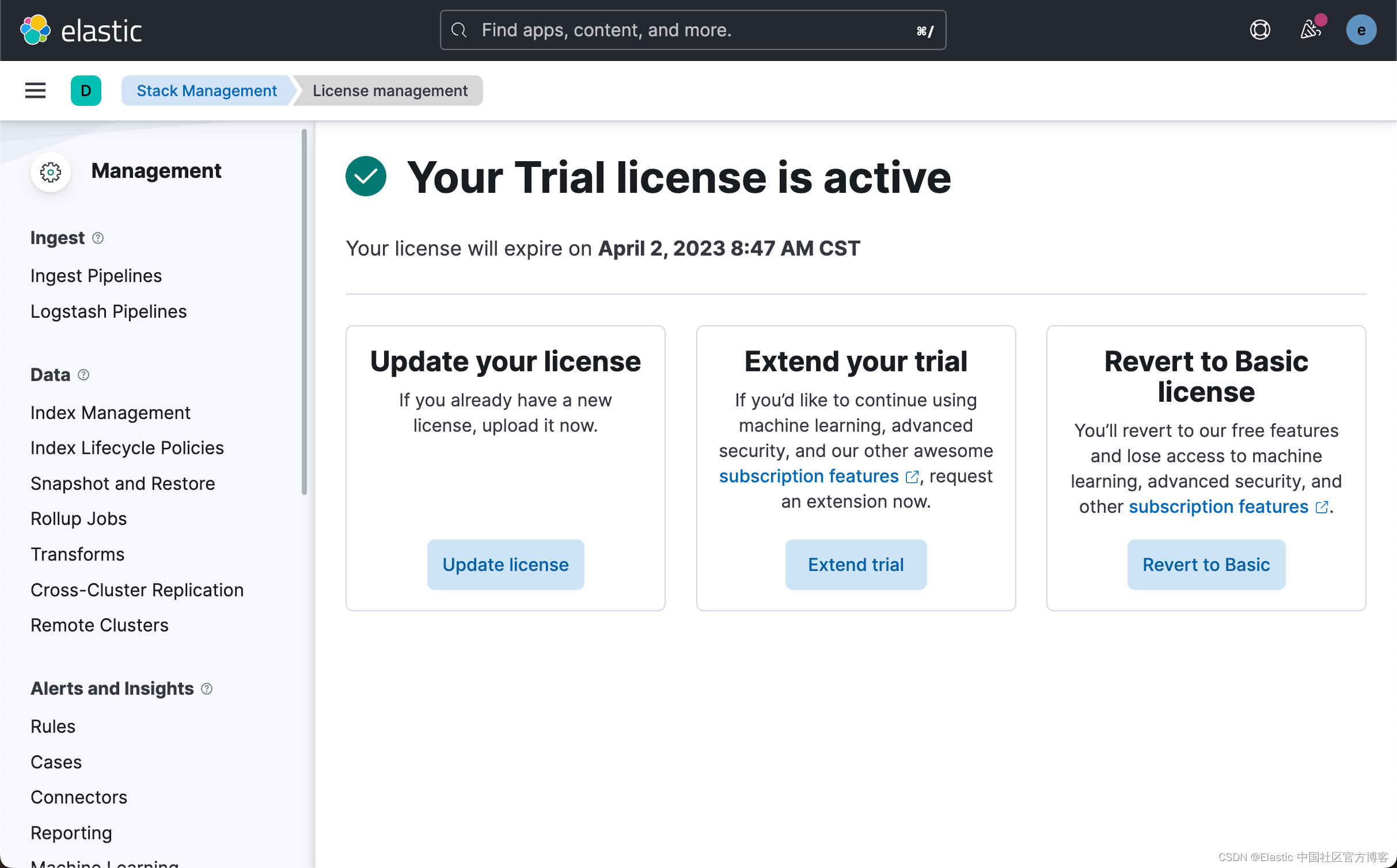
这样我们就成功地启动了白金版试用功能。
登录到你的帐户以启动 Elasticsearch 集群。 设置一个小型集群:
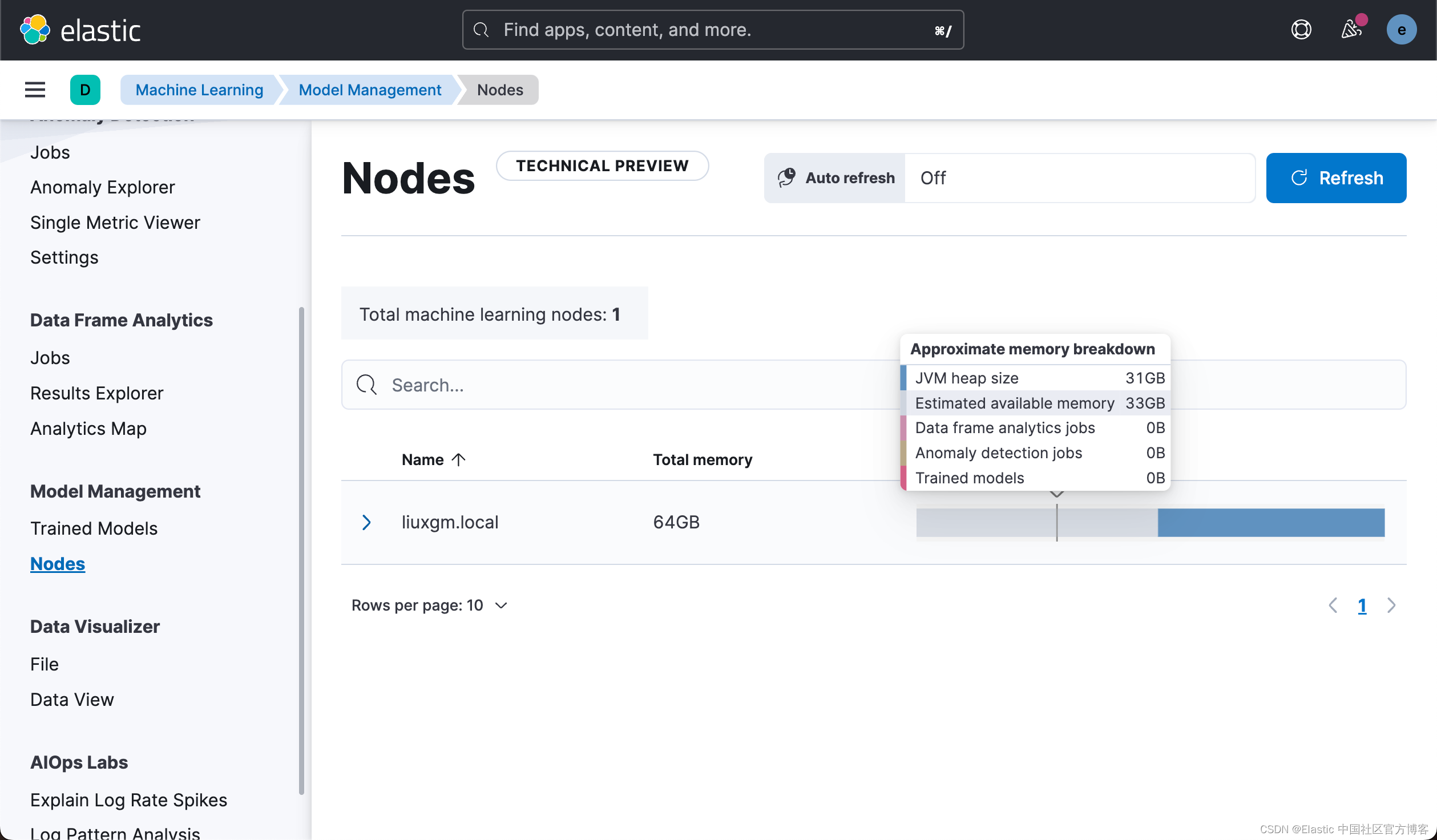
部署准备就绪后,转到 Kibana 并检查机器学习节点的容量。 你将在视图中看到一个机器学习节点。 目前没有加载模型。
使用 Eland 库从 OpenAI 上传 CLIP 嵌入模型。 Eland 是一个 Python Elasticsearch 客户端,用于在 Elasticsearch 中探索和分析数据,能够处理文本和图像。 您将使用此模型从文本输入生成嵌入并查询匹配图像。 在 Eland 库的文档中找到更多详细信息。
对于下一步,你将需要 Elasticsearch 端点。 你可以从部署详细信息部分的 Elasticsearch 云控制台获取它。
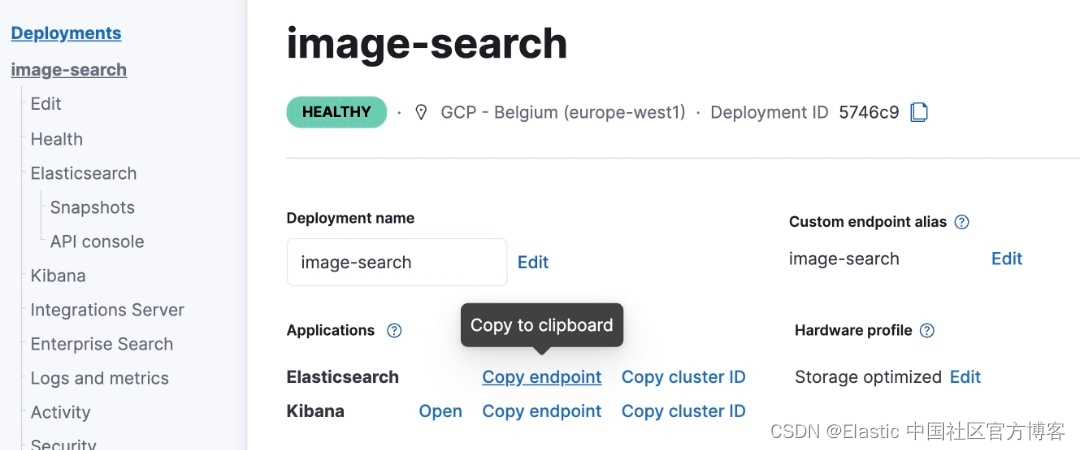
在本示例中,我们将使用本地部署来进行展示,所以,我们并不必要完成上面的步骤。
Eland 可以通过 pip 从 PyPI 安装。在安装之前,我们需要安装好自己的 Python。
$ python --version
Python 3.10.2可以使用 Pip 从 PyPI 安装 Eland:
python -m pip install eland也可以使用 Conda 从 Conda Forge 安装 Eland:
conda install -c conda-forge eland希望在不安装 Eland 的情况下使用它的用户,为了只运行可用的脚本,可以构建 Docker 容器:
git clone https://github.com/elastic/eland
cd eland
docker build -t elastic/eland .
Eland 将 Hugging Face 转换器模型到其 TorchScript 表示的转换和分块过程封装在一个 Python 方法中; 因此,这是推荐的导入方法。
eland_import_hub_model --url <clusterUrl> \
--hub-model-id elastic/distilbert-base-cased-finetuned-conll03-english \
--task-type ner
我们使用如下的命令来进行上传模型:
eland_import_hub_model --url https://<user>:<password>@<hostname>:<port> \
--hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 \
--task-type text_embedding \
--ca-certs <your certificate> \
--start针对我的情况:
eland_import_hub_model --url https://elastic:ZgzSt2vHNwA6yPn-fllr@localhost:9200 \
--hub-model-id sentence-transformers/clip-ViT-B-32-multilingual-v1 \
--task-type text_embedding \
--ca-certs /Users/liuxg/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt \
--start请注意: 你需要根据自己的 Elasticsearch 访问端点,用户名及密码来修改上面的设置,同时你需要根据自己的配置修改上面的证书路径。
运行上面的命令:
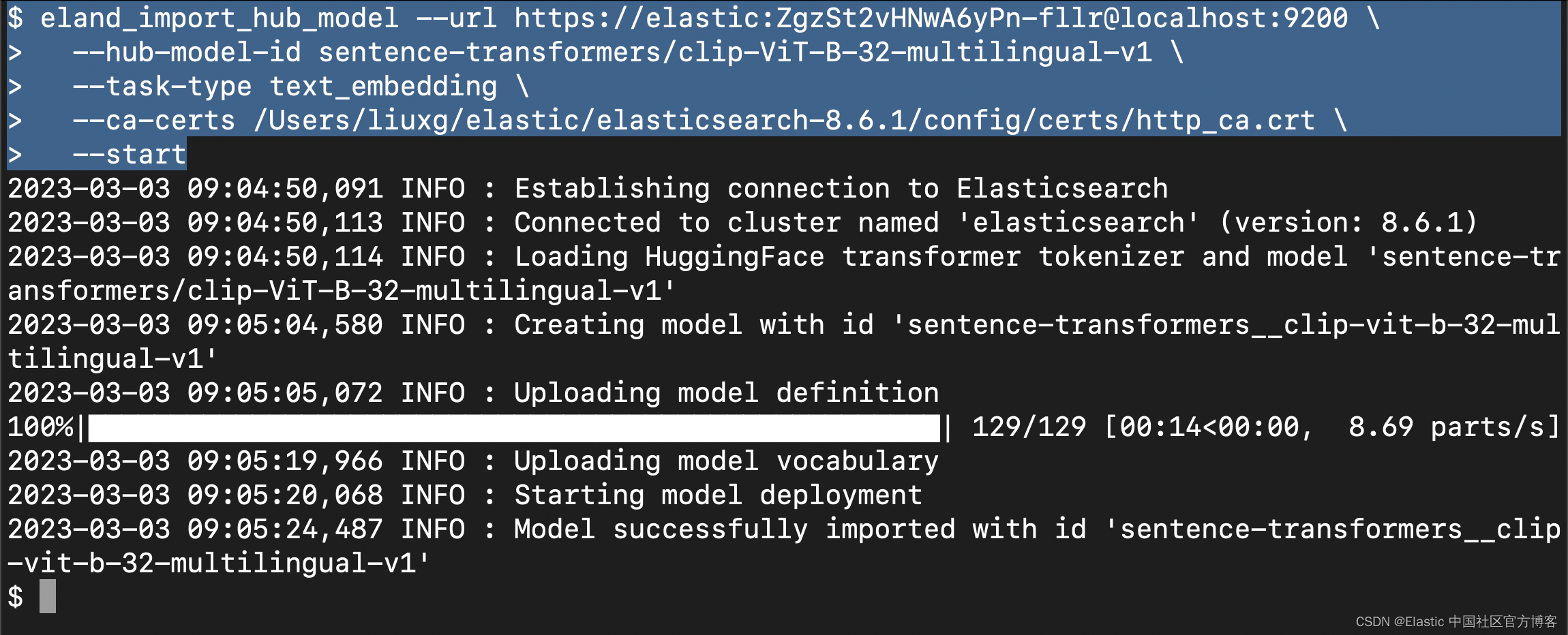
上面显示,我们已经成功地上传了模型。我们可以到 Kibana 中进行查看:
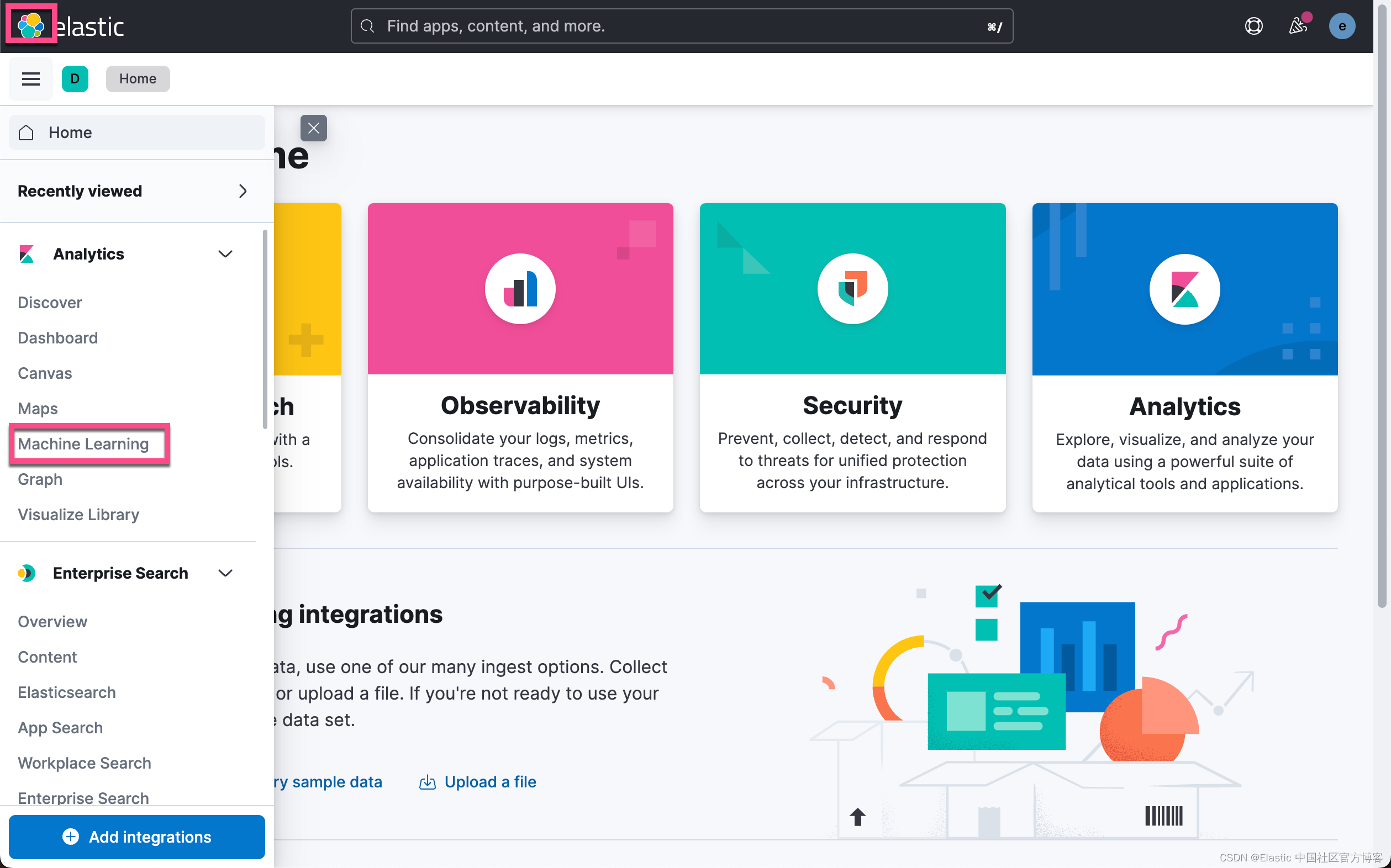
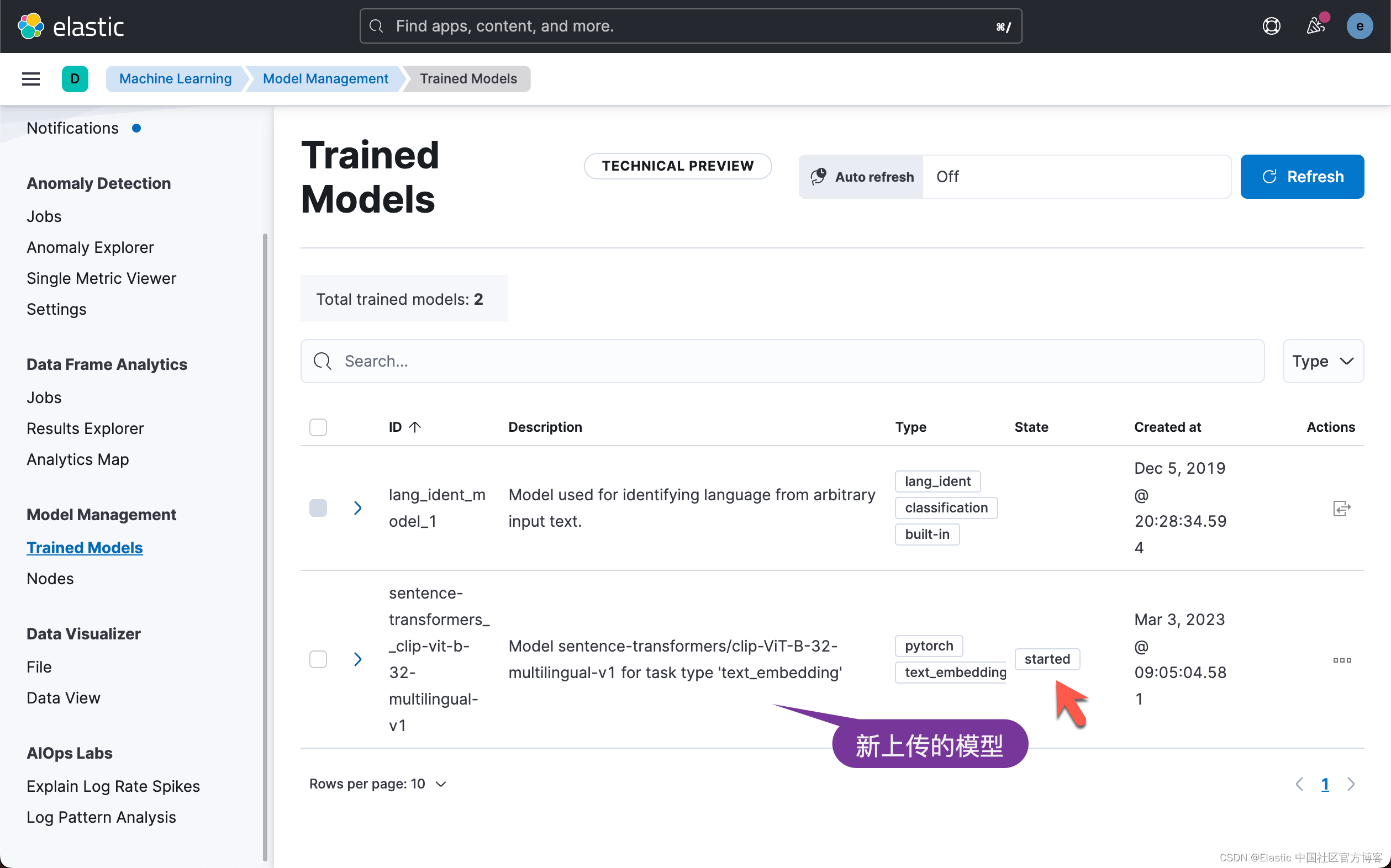
上面显示我们已经上传了所需要的 CLIP 模型,并且它的状态是 started。
在设置 Elasticsearch 集群并导入嵌入模型后,你需要矢量化图像数据并为数据集中的每个图像创建图像嵌入。
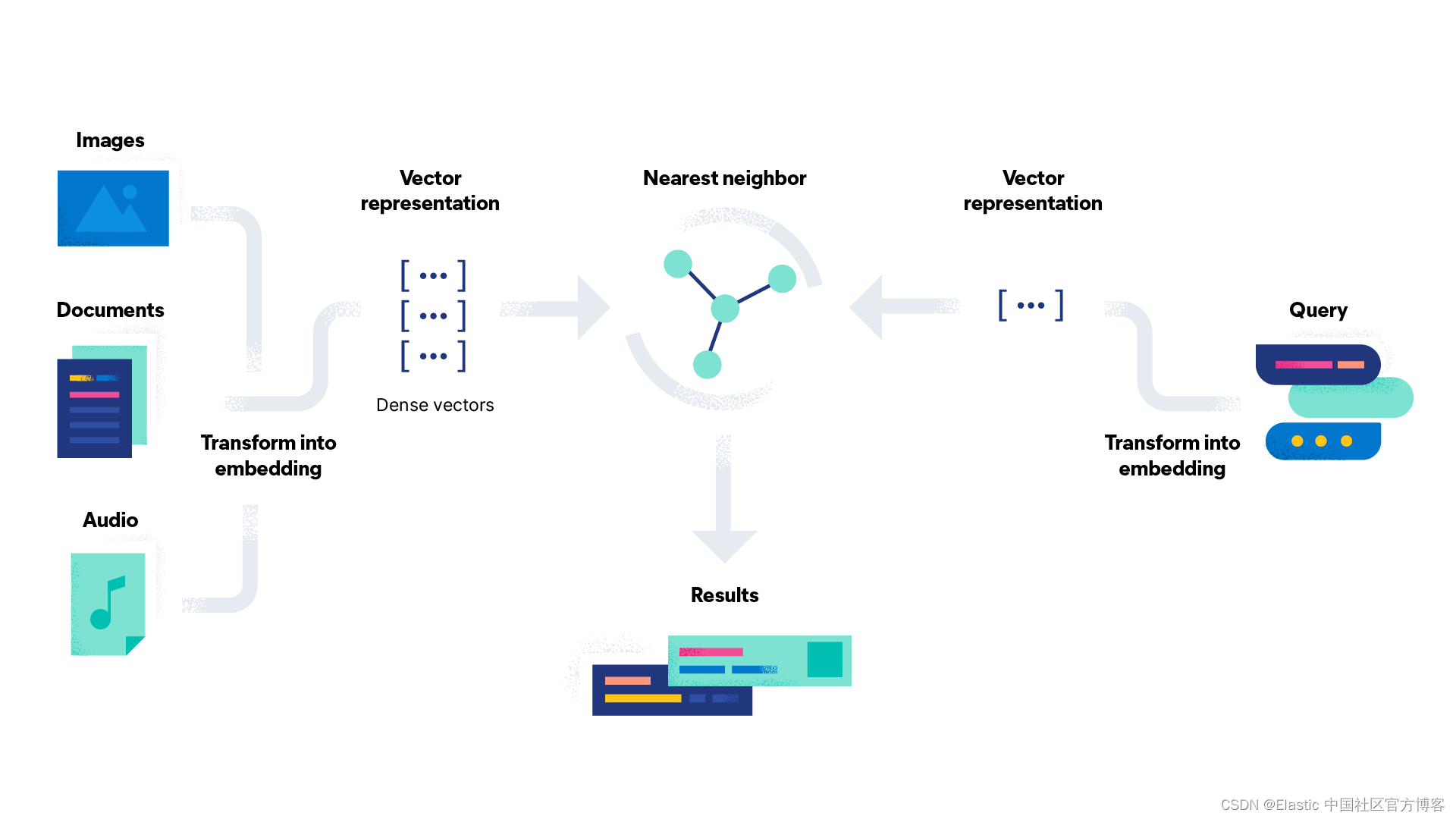
要创建图像嵌入,请使用简单的 Python 脚本。 你可以在此处找到该脚本:create-image-embeddings.py。 该脚本将遍历你的图像目录并生成单独的图像嵌入。 它将使用名称和相对路径创建文档,并使用提供的映射将其保存到 Elasticsearch 索引 my-image-embeddings 中。
将所有图像(照片)放入文件夹 app/static/images。 使用带有子文件夹的目录结构来组织图像。 所有图像准备就绪后,使用几个参数执行脚本。
至少要有几百张图像才能获得合理的结果,这一点至关重要。 图像太少不会产生预期的结果,因为你要搜索的空间非常小,而且到搜索向量的距离也非常相似。我尝试在网上下载很多的照片,但是感觉一张一张地下载非常麻烦。你可以在谷歌浏览器中添加插件 Image downloader - Imageye。它可以方便地把很多照片一次下载下来。
在 image_embeddings 文件夹中,运行脚本并为变量使用你的值。
cd image_embeddings
python3 create-image-embeddings.py \
--es_host='https://localhost:9200' \
--es_user='elastic' --es_password='ZgzSt2vHNwA6yPn-fllr' \
--ca_certs='/Users/liuxg/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt'根据图像的数量、它们的大小、你的 CPU 和你的网络连接,此任务将需要一些时间。 在尝试处理完整数据集之前,先试验少量图像。脚本完成后,吧可以使用 Kibana 开发工具验证索引 my-image-embeddings 是否存在并具有相应的文档。
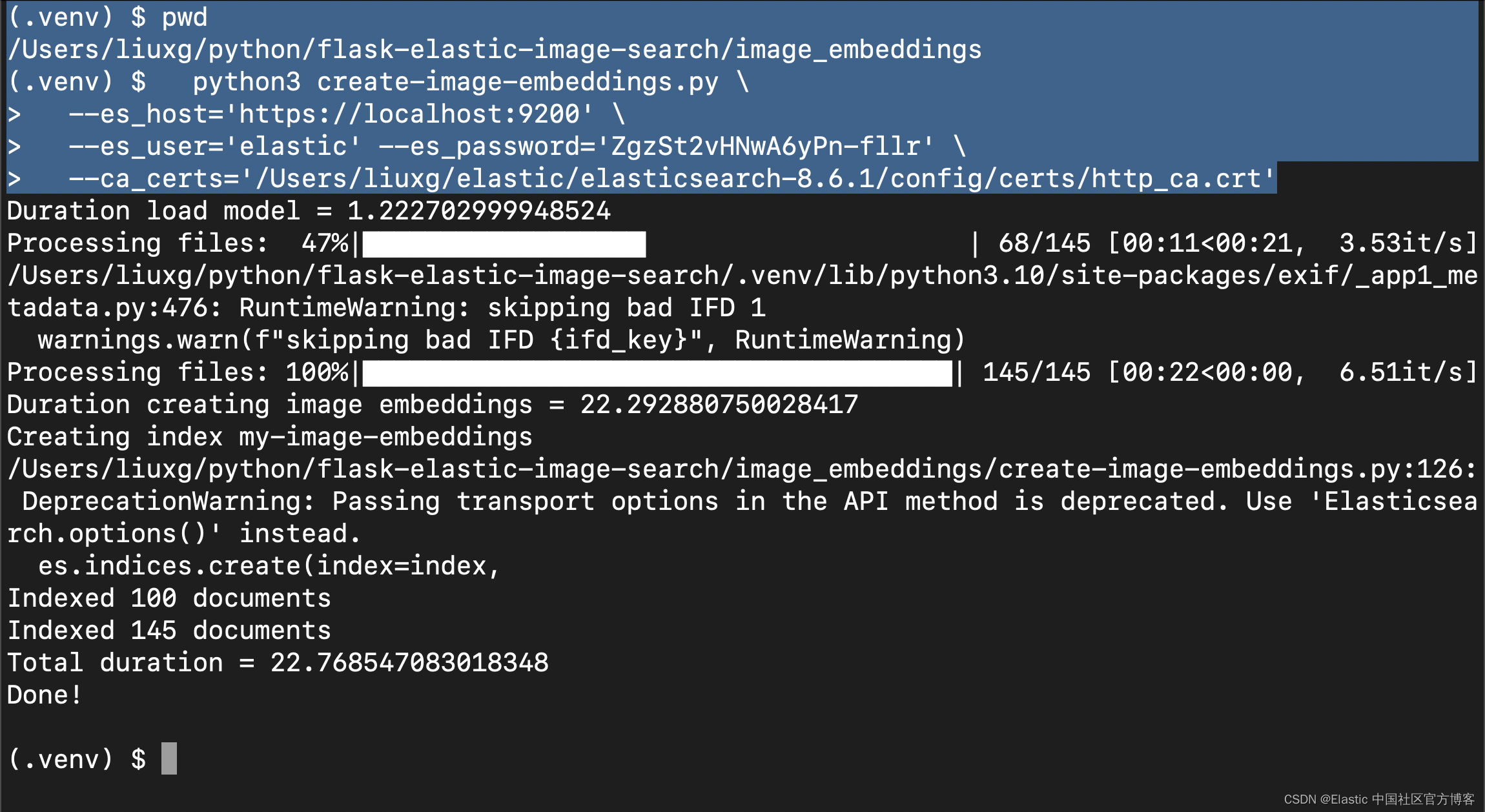
我们在Kibana 中进行查看:
GET _cat/indices/my-image-embeddings?v上面命令的响应为:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
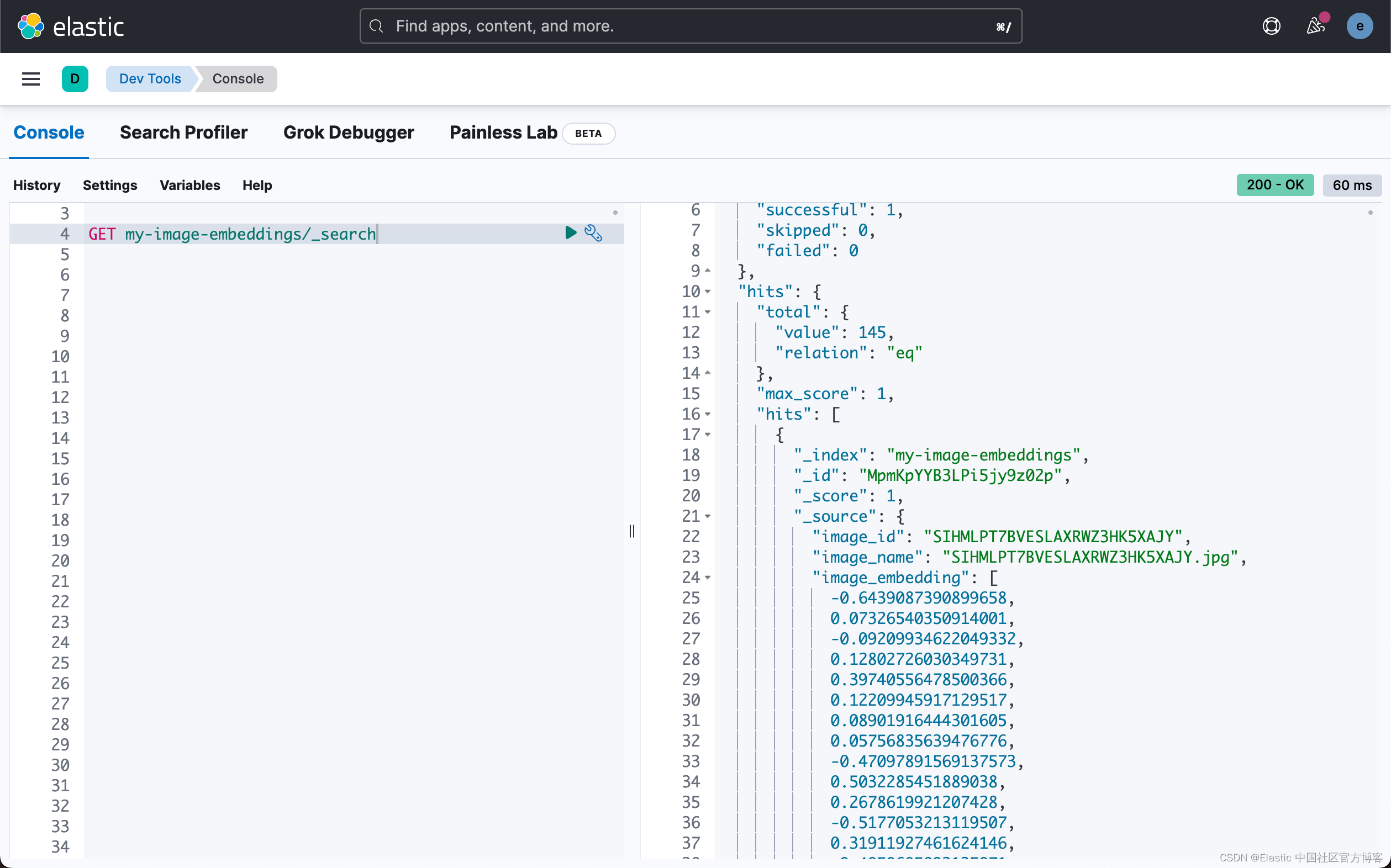
yellow open my-image-embeddings h6oUBdHCScWmXOZaf57oWg 1 1 145 0 1.4mb 1.4mb查看文档,你会看到非常相似的 JSON 对象(如示例)。 你将在图像文件夹中看到图像名称、图像 ID 和相对路径。 此路径用于前端应用程序以在搜索时正确显示图像。JSON 文档中最重要的部分是包含 CLIP 模型生成的密集矢量的 image_embedding。 当应用程序正在搜索图像或类似图像时使用此矢量。
GET my-image-embeddings/_search{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}
现在你的环境已全部设置完毕,你可以进行下一步,使用我们作为概念证明提供的 Flask 应用程序,使用自然语言实际搜索图像并查找相似图像。 该 Web 应用程序具有简单的 UI,使图像搜索变得简单。 你可以在此 GitHub 存储库中访问原型 Flask 应用程序。
后台应用程序执行两个任务。 在搜索框中输入搜索字符串后,文本将使用机器学习 _infer 端点进行矢量化。 然后,针对带有向量的索引 my-image-embeddings 执行带有密集向量的查询。
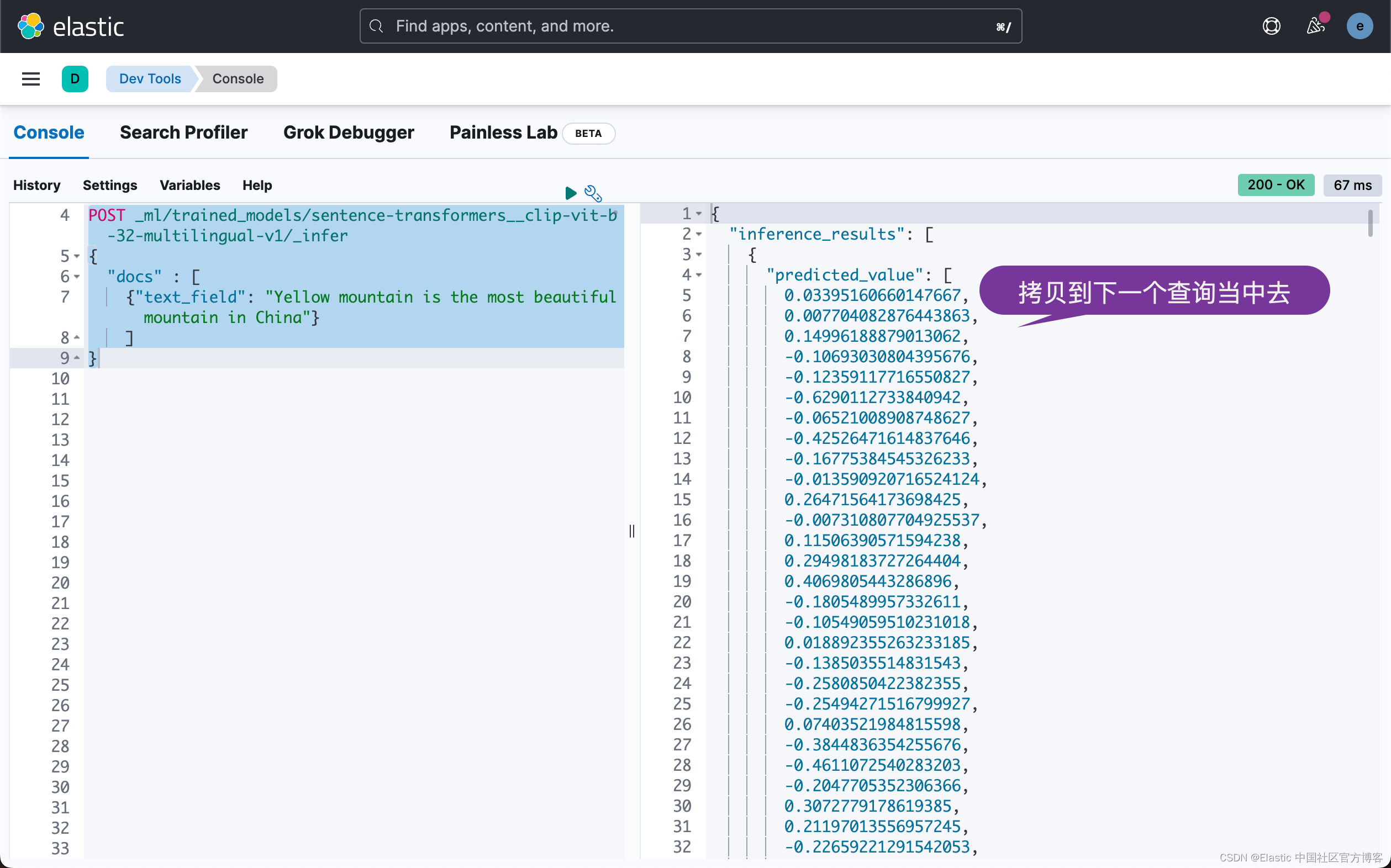
你可以在示例中看到这两个查询。 第一个 API 调用使用 _infer 端点,结果是一个密集矢量。
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/_infer
{
"docs" : [
{"text_field": "Yellow mountain is the most beautiful mountain in China"}
]
}上面的响应如下:
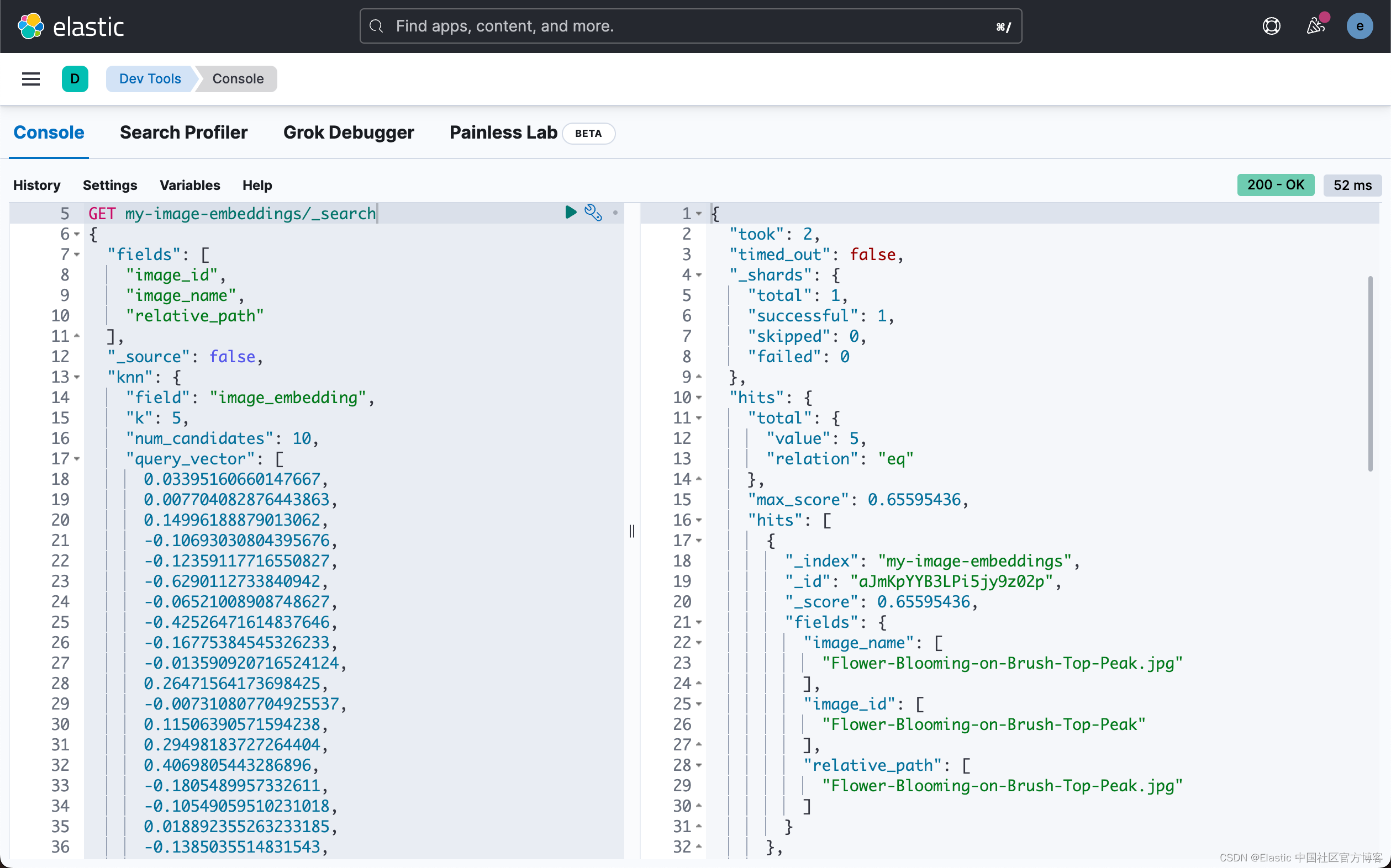
在第二个任务中,搜索查询,我们将使用密集矢量并获得按分数排序的图像。
GET my-image-embeddings/_search
{
"fields": [
"image_id",
"image_name",
"relative_path"
],
"_source": false,
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
0.03395160660147667,
0.007704082876443863,
0.14996188879013062,
-0.10693030804395676,
...
0.05140634626150131,
0.07114913314580917
]
}
}
要启动并运行 Flask 应用程序,请导航到存储库的根文件夹并配置 .env 文件。 配置文件中的值用于连接到 Elasticsearch 集群。 你需要为以下变量插入值。 这些与图像嵌入生成中使用的值相同。
.env
ES_HOST='URL:PORT'
ES_USER='elastic'
ES_PWD='password'为了能够使得我们自构建的 Elasticsearch 集群能够被正确地访问,我们必须把 Elasticsearch 的根证书拷贝到 Flask 应用的相应目录中:
flask-elastic-image-search/app/conf/ca.crt
(.venv) $ pwd
/Users/liuxg/python/flask-elastic-image-search/app/conf
(.venv) $ cp ~/elastic/elasticsearch-8.6.1/config/certs/http_ca.crt ca.crt
overwrite ca.crt? (y/n [n]) y在上面,我们替换了仓库中原有的证书文件 ca.crt。
准备就绪后,运行主文件夹中的 flask 应用程序并等待它启动。
# In the main directory
$ flask run --port=5001如果应用程序启动,你将看到类似于下面的输出,它在末尾指示你需要访问哪个 URL 才能访问该应用程序。
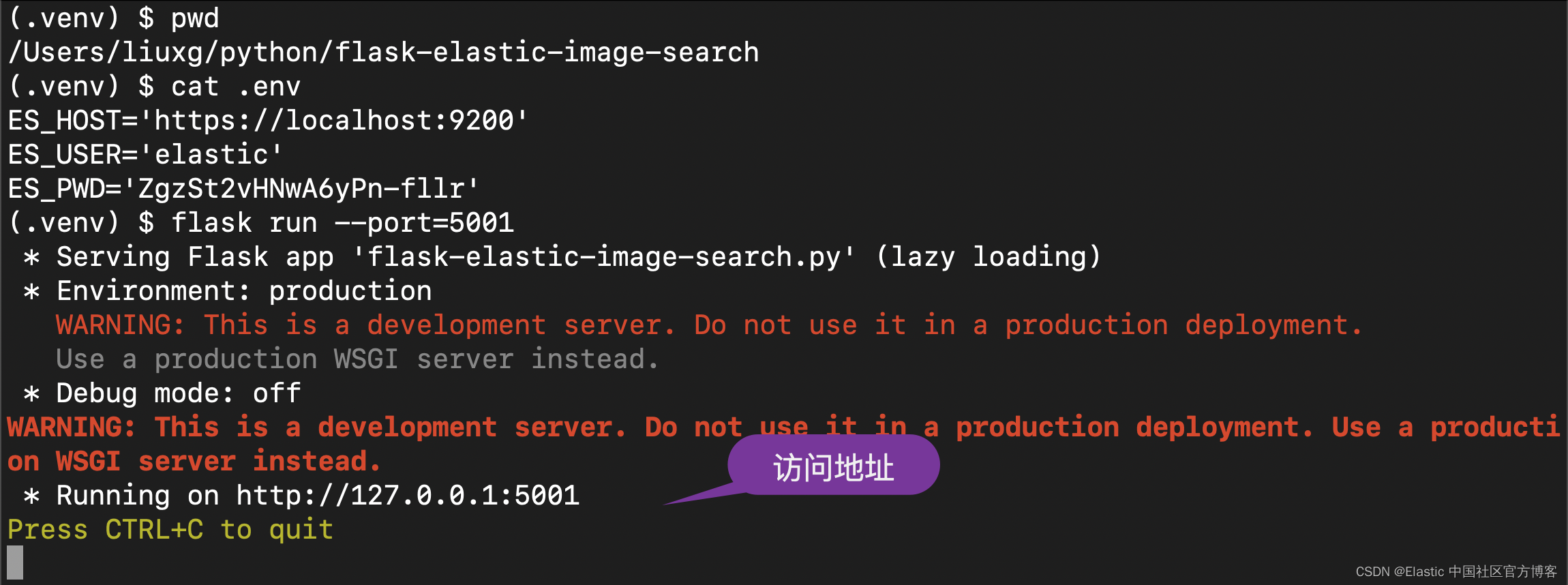
恭喜! 你的应用程序现在应该已启动并正在运行,并且可以通过互联网浏览器在 http://127.0.0.1:5001 上访问。
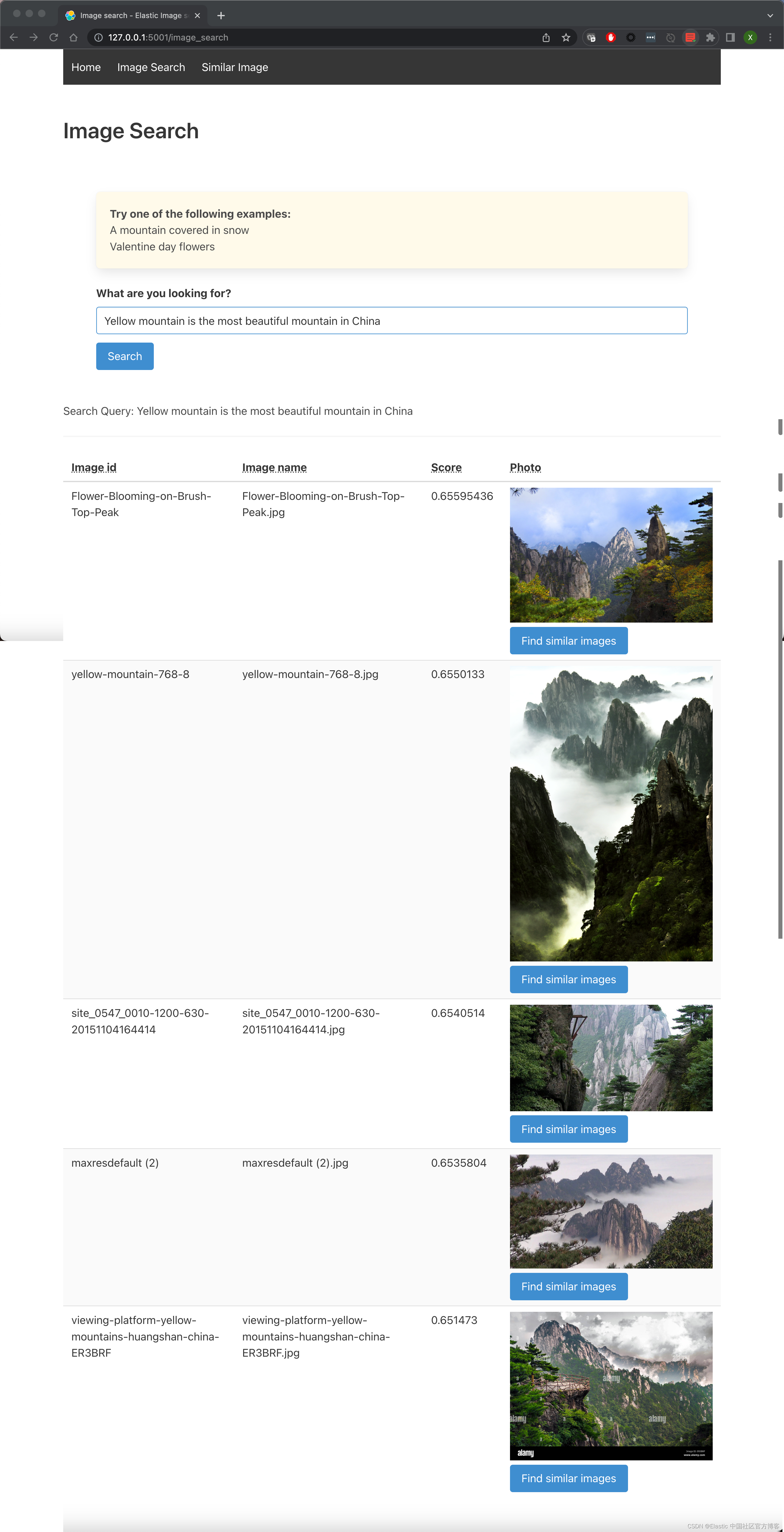
导航到图像搜索选项卡并输入描述你最佳图像的文本。 尝试使用非关键字或描述性文字。
在下面的示例中,输入的文本是 “Yellow mountain is the most beautiful mountain in China”。 结果显示在我们的数据集中。 如果用户喜欢结果集中的一张特定图像,只需单击它旁边的按钮,就会显示类似的图像。 用户可以无限次地这样做,并通过图像数据集构建自己的路径。
我们尝试另外的一个例子。这次我们输入:I love beautiful girls。
搜索也可以通过简单地上传图像来进行。 该应用程序会将图像转换为矢量并在数据集中搜索相似的图像。 为此,导航到第三个选项卡 “Similar Image”,从磁盘上传图像,然后点击 “Search”。
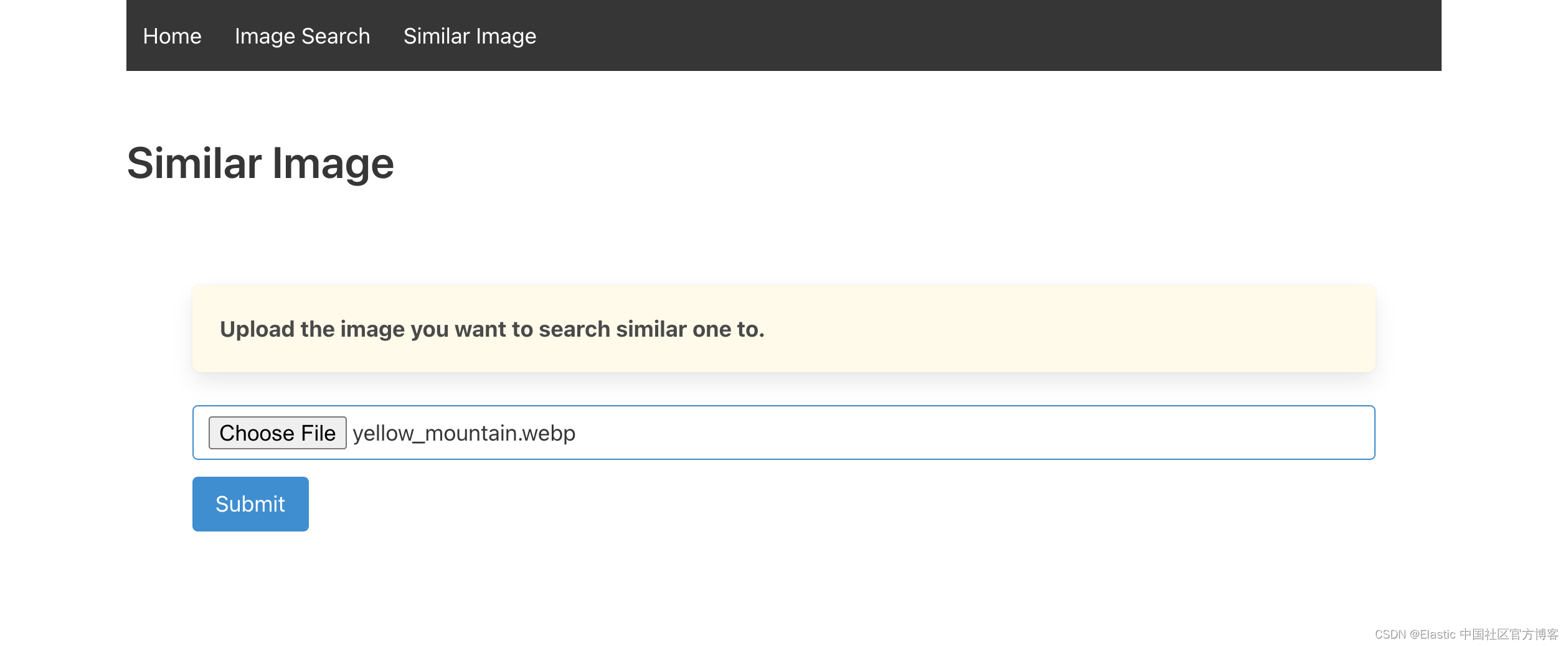
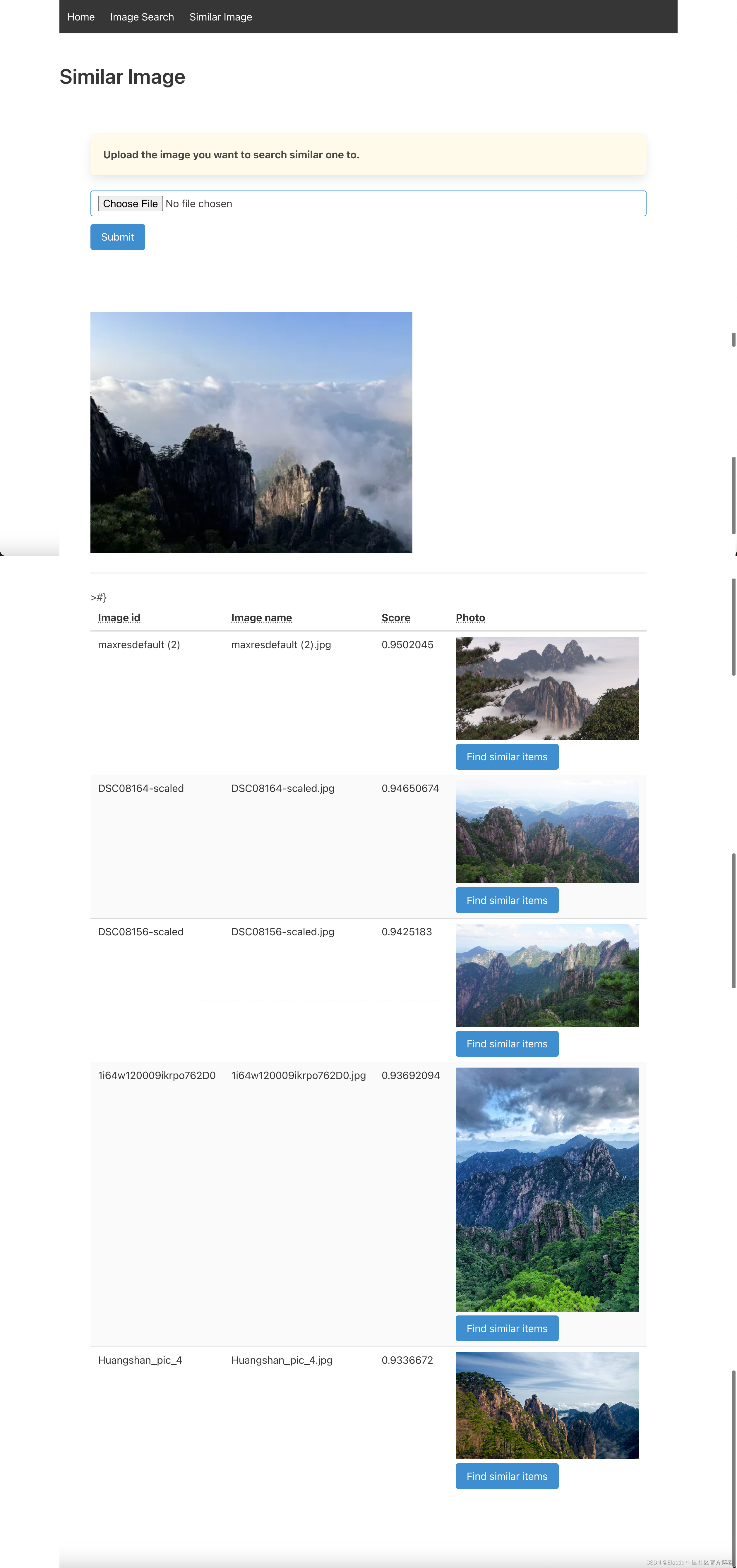
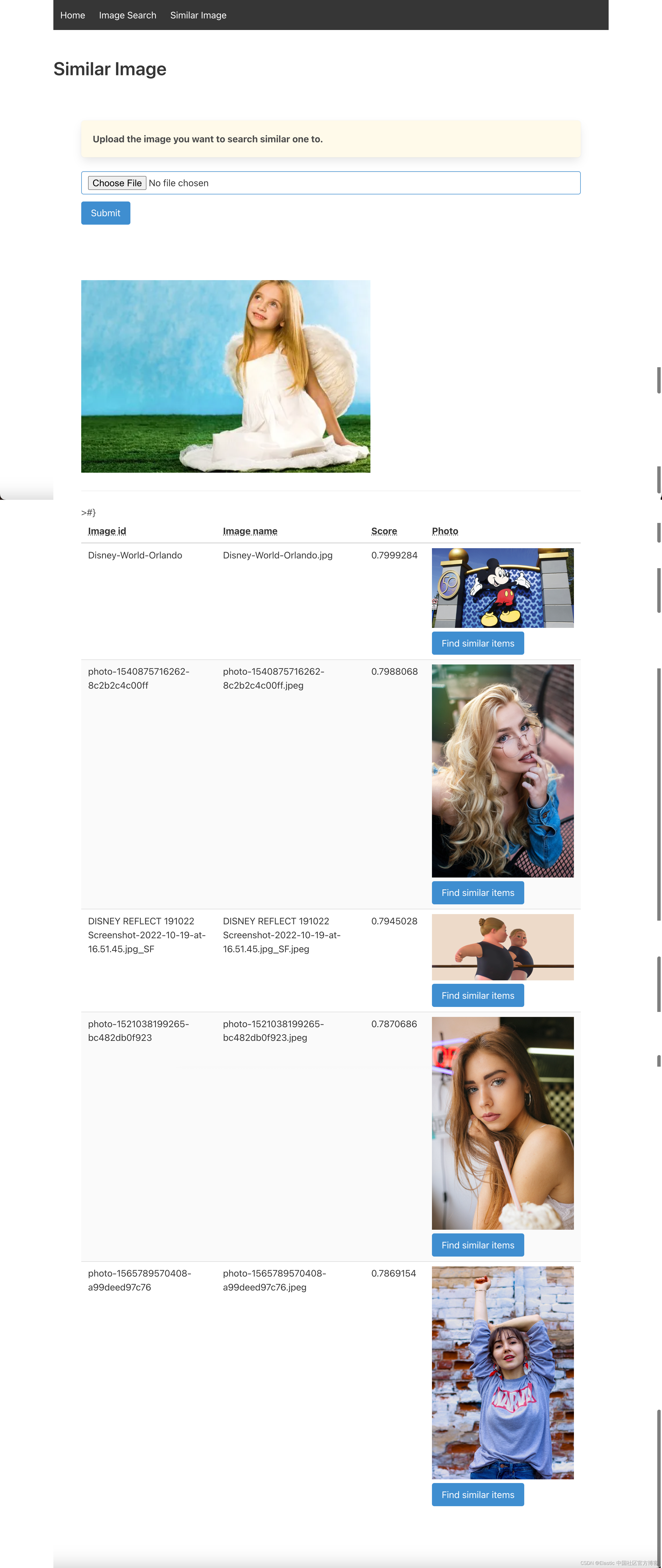
我们可以看到相似的图片。我们尝试使用一个女孩的照片再试试:
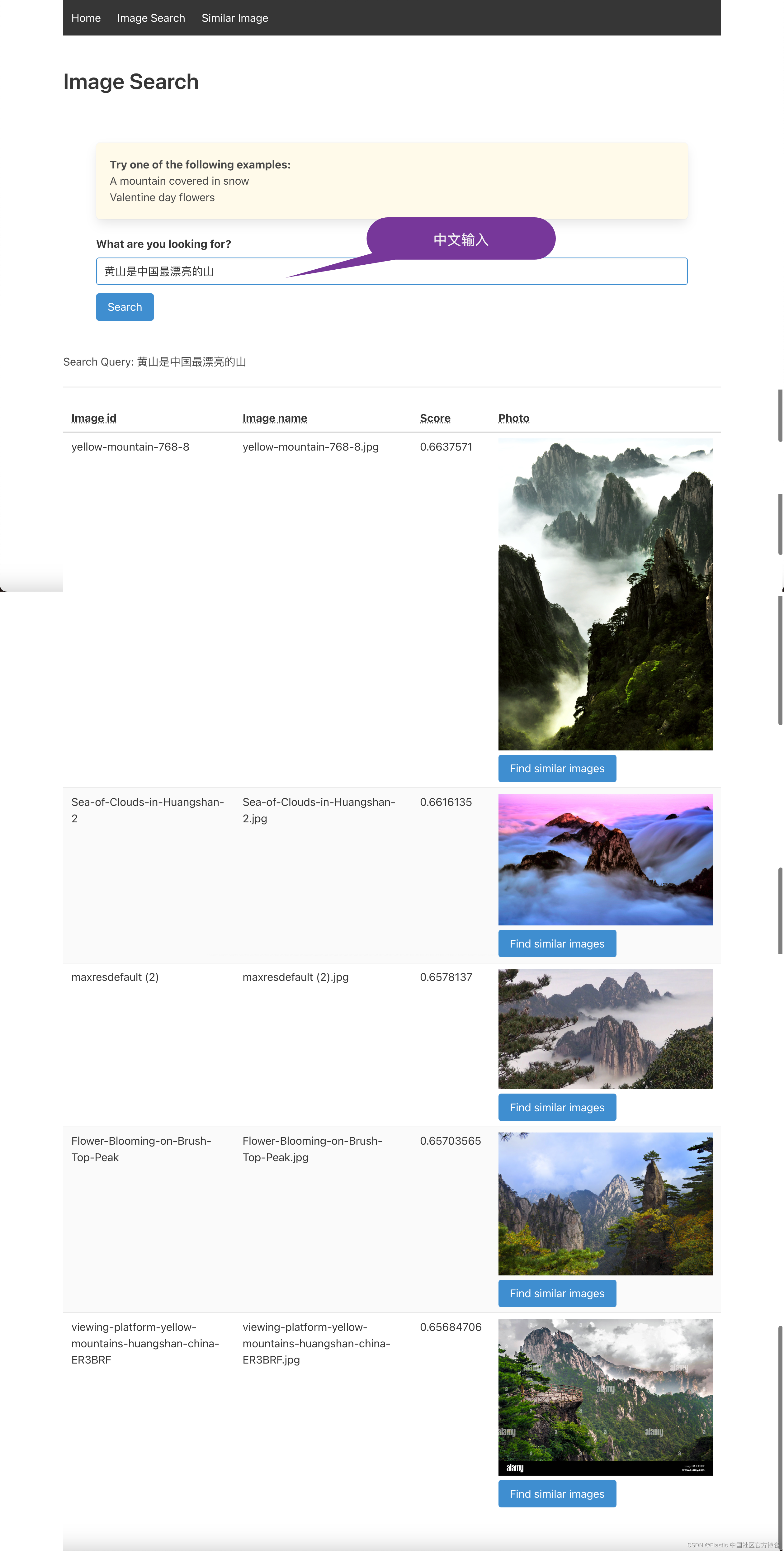
因为我们在 Elasticsearch 中使用的 NLP(sentence-transformers/clip-ViT-B-32-multilingual-v1)模型是多语言的,支持多语言推理,所以尽量搜索自己语言的图片。 然后也使用英文文本验证结果。我们尝试使用 “黄山是中国最漂亮的山”:
请务必注意,使用的模型是通用模型,这些模型非常准确,但你获得的结果会因用例或其他因素而异。 如果你需要更高的精度,则必须采用通用模型或开发自己的模型 —— CLIP 模型只是一个起点。
你可以在 GitHub 存储库中找到完整的代码。 你可能正在检查 routes.py 中的代码,它实现了应用程序的主要逻辑。 除了明显的路线定义之外,你还应该关注定义 _infer 和 _search 端点(infer_trained_model 和 knn_search_images)的方法。 生成图像嵌入的代码位于 create-image-embeddings.py文件中。
现在你已经设置了 Flask 应用程序,你可以轻松地搜索你自己的图像集! Elastic 在平台内提供了矢量搜索的原生集成,避免了与外部进程的通信。 你可以灵活地开发和使用你可能使用 PyTorch 开发的自定义嵌入模型。
语义图像搜索具有其他传统图像搜索方法的以下优点:
如果你的用例更多地依赖于文本数据,你可以在以前的博客中了解更多关于实现语义搜索和将自然语言处理应用于文本的信息。 对于文本数据,向量相似度与传统关键词评分的结合呈现了两全其美的效果。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
我怎样才能完成http://php.net/manual/en/function.call-user-func-array.php在ruby中?所以我可以这样做:classAppdeffoo(a,b)putsa+benddefbarargs=[1,2]App.send(:foo,args)#doesn'tworkApp.send(:foo,args[0],args[1])#doeswork,butdoesnotscaleendend 最佳答案 尝试分解数组App.send(:foo,*args)
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R