目录
我们知道冒泡算法的时间复杂度是O(N^2),在数据量很多的时候,N^2是个很可怕的数字,二分算法的时间复杂度是O(logn),但是二分算法有限制条件,实用性并不高,那怎样才能高效实用的排序呢?
堆排序就能很好解决上述问题,堆排序的时间复杂度是O(logn),也没啥限制条件,可以实现高效排序。
这里要注意,排升序要建大堆,排降序要建小堆;
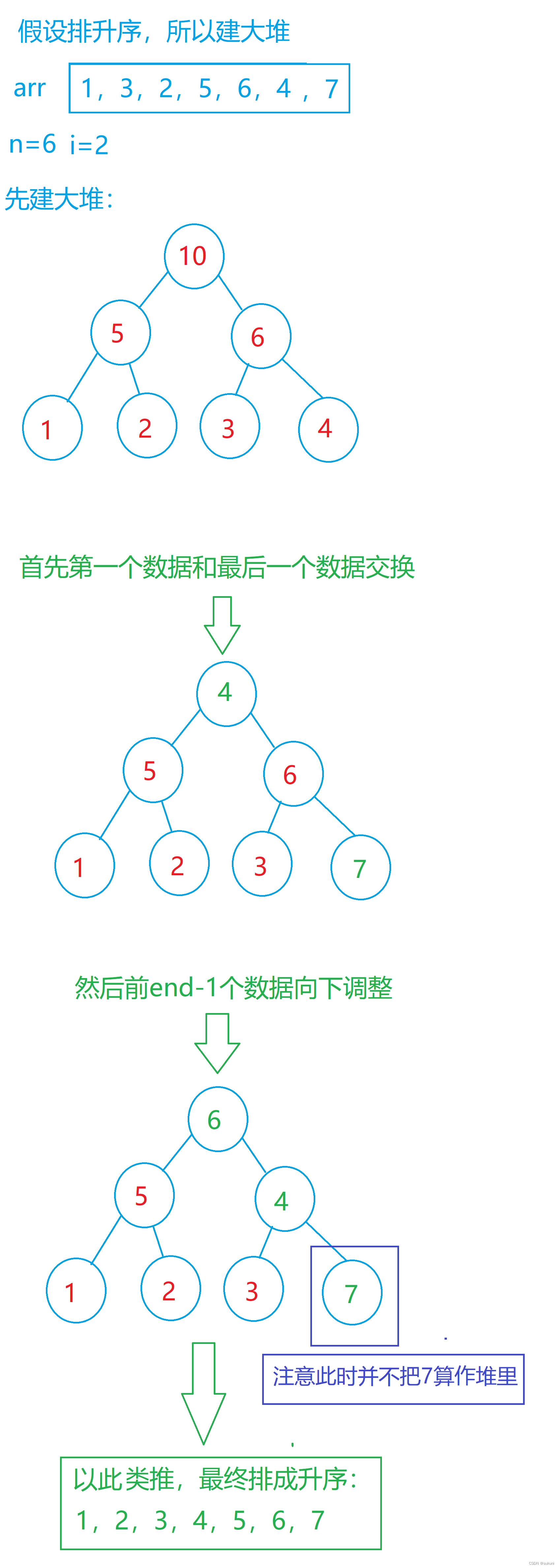
1.假设排升序,所以建大堆;
2.堆建好后,定义一个 end 变量,令其 =n-1(数组最后一个元素的下标是n-1) ;
3.堆建好后,数组第一个元素就是最大的,将其与最后一个数据交换,然后这个数据就不需要动了,为了保持它是个大堆,让它的前 end-1 个元素向下调整,然后end--,当 end<=0 时就结束循环。
堆排序不需要手搓个堆,只需要用到向下调整这个函数,所以使用堆排序时,只需写个向下调整就行了。
void Swap(int* p1, int* p2)
{
int tmp = *p1;
*p1 = *p2;
*p2 = tmp;
}
void AdjustDown(int* arr, int parent, int n)
{
assert(arr);
int child = 2 * parent + 1;
while (child < n)
{
if ((child + 1) < n&& arr[child + 1] > arr[child])
{
child++;
}
if (arr[child] > arr[parent])
{
Swap(&arr[child], &arr[parent]);
parent = child;
child = 2 * parent + 1;
}
else
break;
}
}
void Heapsort(int* arr, int n)
{
assert(arr);
int i = 0;
for (i = (n - 2) / 2; i >= 0; i--) //建堆
{
AdjustDown(arr, i, n);
}
int end = n - 1;
while (end)
{
Swap(&arr[0], &arr[end]);
AdjustDown(arr, 0, end);
end--;
}
for (i = 0; i < n; i++)
{
printf("%d ", arr[i]);
}
printf("\n");
}TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
基本思路如下:
1. 用数据集合中前K个元素来建堆,注意:
前k个最大的元素,则建小堆;
前k个最小的元素,则建大堆;
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素;
3.将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
我们可以从文件中读取数据,这样的实用性更高些;
假设找的是最大的前k个数据,所以建小堆;
具体:
1.创建一个k个元素的数组,模拟建堆,从文件中读取k个数据存入数组中;
2.从文件中取数据与数组的第一个元素比较,也就是堆顶的数据,因为是小堆,如果该数据比堆顶数据大,则将值赋给堆顶,成为新的堆顶,不用担心会出什么问题,因为是小堆,所以那些大的数据会往下沉,如果不大于堆顶的数据,则继续从文件中取数据出来比较;
3.当读取文件结束时就结束循环。
如果对文件操作不太熟悉的话,可参考->文件的基础操作
如要想检验你写的代码是否能解决topk问题时,可以在数据创建完成后,手动修改文件中的k个数据,如果是找最大的k个数据,那么只需要修改k个数据,且每个都大于原来文件的最大值,这样在测试代码时,输出的就是你修改的k个数据。
void Createdata(const char file,int n) //创建数据
{
int i = 0;
int x = 0;
FILE* fin = fopen("file", "w"); //打开文件
if (fin == NULL)
{
perror("fopen fail");
exit(-1);
}
for (i = 0; i < n; i++)
{
x = rand() % 100 + 1; //利用随机数生成函数,创建k个范围在1~100之间的数据
fprintf(fin, "%d\n", x); //将数据写入文件中
}
fclose(fin); //关闭文件
fin = NULL;
}
void topk(const char file, int k)
{
FILE* fout = fopen("file", "r");
if (fout == NULL)
{
perror("fopen fail");
exit(-1);
}
HPdatatype* arr = (HPdatatype*)malloc(sizeof(HPdatatype) * k);
if (arr == NULL)
{
perror("malloc fail");
exit(-1);
}
int i = 0;
for (i = 0; i < k; i++)
{
fscanf(fout, "%d", &arr[i]); //从文件中写入k个数据到数组中,模拟堆的创建
}
int val = 0, ret = 0;
ret = fscanf(fout, "%d", &val); //从文件中取数据
while (ret != EOF)
{
if (val > arr[0]) //将取出的数据与堆顶数据比较,若大于,则其成为新的堆顶
{
arr[0] = val;
AdjustDown(arr, 0, k); //向下调整,保持小堆或是大堆
}
ret = fscanf(fout, "%d", &val); //从文件中取数据
}
free(arr);
fclose(fout);
arr = NULL;
fout = NULL;
}
int main()
{
srand((unsigned int)time(NULL));
const char file = "data.txt";
int n = 1000;
int k = 10;
//Createdata(file,n);
topk(file, k);
return 0;
}🐬🤖本篇文章到此就结束了,若有错我或是建议的话,欢迎小伙伴们指出;🕊️👻
😄😆希望小伙伴们能支持支持博主啊,你们的支持对我很重要哦;🥰🤩
😍😁谢谢你的阅读。😸😼

对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我构建了两个需要相互通信和发送文件的Rails应用程序。例如,一个Rails应用程序会发送请求以查看其他应用程序数据库中的表。然后另一个应用程序将呈现该表的json并将其发回。我还希望一个应用程序将存储在其公共(public)目录中的文本文件发送到另一个应用程序的公共(public)目录。我从来没有做过这样的事情,所以我什至不知道从哪里开始。任何帮助,将不胜感激。谢谢! 最佳答案 无论Rails是什么,几乎所有Web应用程序都有您的要求,大多数现代Web应用程序都需要相互通信。但是有一个小小的理解需要你坚持下去,网站不应直接访问彼此
我尝试运行2.x应用程序。我使用rvm并为此应用程序设置其他版本的ruby:$rvmuseree-1.8.7-head我尝试运行服务器,然后出现很多错误:$script/serverNOTE:Gem.source_indexisdeprecated,useSpecification.Itwillberemovedonorafter2011-11-01.Gem.source_indexcalledfrom/Users/serg/rails_projects_terminal/work_proj/spohelp/config/../vendor/rails/railties/lib/r
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否可以在应用程序中包含的gem代码中知道应用程序的Rails文件系统根目录?这是gem来源的示例:moduleMyGemdefself.included(base)putsRails.root#returnnilendendActionController::Base.send:include,MyGem谢谢,抱歉我的英语不好 最佳答案 我发现解决类似问题的解决方案是使用railtie初始化程序包含我的模块。所以,在你的/lib/mygem/railtie.rbmoduleMyGemclassRailtie使用此代码,您的模块将在