树状数组是一种基于二进制拆分的思想,用来动态维护序列的前缀和的树形数据结构。在全国青少年信息学奥林匹克竞赛大纲内难度评级为 6,是提高级中开始学习的数据结构。
树状数组的基本操作:
\(lowbit(x)\) 表示将 x 写成二进制表示后,最低位的 1 所代表的数值,如 \(10 = (1010)_2 , lowbit(10)=(10)_2=2\)
以下是 \(lowbit(x)\) 的求法,具体证明可参见 《算法竞赛进阶指南》 0x01 二进制 章节。
#define lowbit(x) ((x)&(-(x)))
对于原序列 \(a[n]\),树状数组用一个数组 \(c[n]\),其中,\(c[i]\) 表示以 \(i\) 结尾长度为 \(lowbit(i)\) 的区间和,即区间 \([i-lowbit(i)+1,i]\)。
这时如果把整个数组视作一个树型结构(如下图,图来自《算法竞赛进阶指南》),则有以下性质:
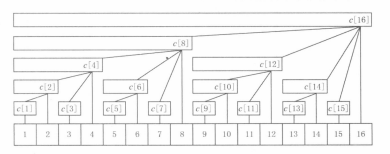
可以发现,树的深度是 \(O(\log n)\),所以树状数组的两种基本操作的时间复杂度都是 \(O(\log n)\)。
a[n] 表示原序列,c[n] 表示树状数组,其中 n 是序列长度。
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5e5 + 5;
int c[N], n;
#define lowbit(x) ((x)&(-(x)))
inline void add(int id, int x) {
for (int i = id;i <= n;i += lowbit(i)) c[i] += x;
}
inline int query(int id) {
int ans = 0;
for (int i = id;i > 0;i -= lowbit(i)) ans += c[i];
return ans;
}
inline int query(int l, int r) {
// 前缀和思想求区间和
return query(r) - query(l - 1);
}
signed main() {
int m;
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = 1;i <= n;i++) {
int a;cin >> a;
add(i, a);
}
for (int i = 1;i <= m;i++) {
int op, x, y;
cin >> op >> x >> y;
if (op == 1) add(x, y);
else cout << query(x, y) << endl;
}
return 0;
}
如果把树状数组当作一个桶使用,则可以用树状数组进行求逆序对等操作。
具体地,因为树状数组可以查询前缀和,所以可以查询比某个数小的数量,据此可统计逆序对数目。
注意:此题值域较大,需要对数据进行离散化。
参考代码:
// https://www.luogu.com.cn/problem/P1908
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5e5 + 5;
int n,
a[N], // 原序列
b[N], m, // 离散化用序列
c[N]; // 树状数组(当桶使用)
long long ans;
#define lowbit(x) ((x)&(-(x)))
void add(int id, int x) {
for (int i = id; i <= n; i += lowbit(i))
c[i] += x;
}
int sum(int id) {
int ans = 0;
for (int i = id;i;i -= lowbit(i)) ans += c[i];
return ans;
}
int query(int x) {
return lower_bound(b + 1, b + 1 + n, x) - b;
}
signed main() {
ios::sync_with_stdio(0);
#ifndef ONLINE_JUDGE
freopen("data.in", "r", stdin);freopen("data.out", "w", stdout);
#endif
cin >> n;
for (int i = 1;i <= n;i++) {
cin >> a[i];
b[i] = a[i];
}
sort(b + 1, b + 1 + n);
m = unique(b + 1, b + 1 + n) - b - 1;
for (int i = 1;i <= n;i++) a[i] = query(a[i]);
for (int i = n;i;i--) {
ans += sum(a[i] - 1);
add(a[i], 1);
}
cout << ans << endl;
}
如果再对当桶使用的树状数组进行拓展,即权值树状数组,可实现一些平衡树的操作,见拓展阅读。
朴素的前缀和区间查询和单点修改的时间复杂度分别是 \(O(1)\), \(O(n)\)。
树状数组可以将其优化为 \(O(\log n)\),\(O(\log n)\)。
朴素的差分单点查询和区间修改的时间复杂度分别是 \(O(n)\), \(O(1)\)。
树状数组同样可以将其优化为 \(O(\log n)\),\(O(\log n)\)。
代码实现如下:
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 5e5 + 5;
int a[N], c[N], n;
inline int lowbit(int x) { return x & (-x); }
inline void add(int id, int x) {
for (int i = id;i <= n;i += lowbit(i)) c[i] += x;
}
void add(int l, int r, int x) {
add(l, x), add(r + 1, -x);
}
inline int query(int id) {
int ans = 0;
for (int i = id;i > 0;i -= lowbit(i)) ans += c[i];
return ans;
}
signed main() {
int m;
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = 1;i <= n;i++) cin >> a[i];
for (int i = 1;i <= n;i++) {
if (i == 1) add(1, a[1]);
else add(i, a[i] - a[i - 1]); // 差分
}
for (int i = 1;i <= m;i++) {
int op, x;
cin >> op;
if (op == 1) {
int y, k;
cin >> x >> y >> k;
add(x, y, k);
}
else cin >> x, cout << query(x) << endl;
}
return 0;
}
考虑区间查询,有:\(\sum_{i=1}^x a[i]\)
而差分(\(b[i]\)是差分数组)有: \(a[i]=\sum_{j=1}^i b[i]\)
考虑每一个 \(b[i]\) 被求和的次数(如图,图来自《算法竞赛进阶指南》),化简一下式子:

用树状数组分别维护 \(b[i]\) 和 \(i*b[i]\) 即可维护上面式子,区间查询和区间修改的时间复杂度都是 \(O(\log n)\)。
代码实现如下:
// https://loj.ac/p/132
#include <iostream>
using namespace std;
#define lowbit(x) ((x)&(-(x)))
#define int long long
const int N = 1e6 + 5;
int a[N]; // 原数组
int b[N]; // 差分数组
int c[3][N], n; // 树状数组,c[1]维护b[i],c[2]维护i*b[i]
void add(int k, int id, int x) {
for (int i = id;i <= n;i += lowbit(i)) c[k][i] += x;
}
void add(int k, int l, int r, int x) {
if (k == 1) add(k, l, x), add(k, r + 1, -x);
else add(k, l, l * x), add(k, r + 1, -(r + 1) * x);
}
int query(int k, int id) {
int ans = 0;
if (k > 0) {
for (int i = id;i;i -= lowbit(i)) ans += c[k][i];
return ans;
}
return (id + 1) * query(1, id) - query(2, id);
}
int query(int k, int l, int r) {
return query(k, r) - query(k, l - 1);
}
signed main() {
ios::sync_with_stdio(0);
#ifndef ONLINE_JUDGE
freopen("data.in", "r", stdin);
freopen("data.out", "w", stdout);
#endif
int q;
cin >> n >> q;
for (int i = 1;i <= n;i++) {
cin >> a[i];
b[i] = a[i] - a[i - 1];
}
for (int i = 1;i <= n;i++) {
add(1, i, b[i]);
add(2, i, i * b[i]);
}
while (q--) {
int op;
cin >> op;
if (op == 1) {
int l, r, x;
cin >> l >> r >> x;
add(1, l, r, x);
add(2, l, r, x);
}
else {
int l, r;
cin >> l >> r;
cout << query(0, l, r) << endl;
}
}
return 0;
}
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我的代码目前看起来像这样numbers=[1,2,3,4,5]defpop_threepop=[]3.times{pop有没有办法在一行中完成pop_three方法中的内容?我基本上想做类似numbers.slice(0,3)的事情,但要删除切片中的数组项。嗯...嗯,我想我刚刚意识到我可以试试slice! 最佳答案 是numbers.pop(3)或者numbers.shift(3)如果你想要另一边。 关于ruby-多次弹出/移动ruby数组,我们在StackOverflow上找到一
我需要读入一个包含数字列表的文件。此代码读取文件并将其放入二维数组中。现在我需要获取数组中所有数字的平均值,但我需要将数组的内容更改为int。有什么想法可以将to_i方法放在哪里吗?ClassTerraindefinitializefile_name@input=IO.readlines(file_name)#readinfile@size=@input[0].to_i@land=[@size]x=1whilex 最佳答案 只需将数组映射为整数:@land边注如果你想得到一条线的平均值,你可以这样做:values=@input[x]
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
这个问题在这里已经有了答案:Checktoseeifanarrayisalreadysorted?(8个答案)关闭9年前。我只是想知道是否有办法检查数组是否在增加?这是我的解决方案,但我正在寻找更漂亮的方法:n=-1@arr.flatten.each{|e|returnfalseife
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>