
大家好,又见面了。
到这里呢,已经是本SpringData JPA系列文档的第四篇了,先来回顾下前面三篇:
在第1篇《Spring Data JPA系列1:JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?给你个选择SpringDataJPA的理由!》中,我们对JPA的整体概念有了全面的了解。
在第2篇《Spring Data JPA系列2:快速在SpringBoot项目中熟练使用JPA》中也知晓了SpringBoot项目快速集成SpringData JPA以及快速上手使用JPA来进行基本的项目开发的技能。
在第3篇《Spring Data JPA系列3:JPA项目中核心场景与进阶用法介绍》进一步的聊一下项目中使用JPA的一些高阶复杂场景的实践指导,覆盖了主要核心的JPA使用场景。
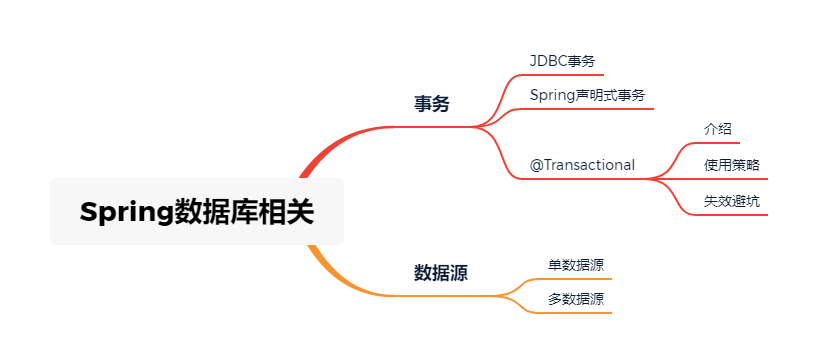
本篇在前面几篇的基础上,再来聊一下数据库相关操作经常会涉及的事务问题与多数据源支持问题。
在大部分涉及到数据库操作的项目里面,事务控制、事务处理都是一个无法回避的问题。得益于Spring框架的封装,业务代码中进行事务控制操作起来也很简单,直接加个@Transactional注解即可,大大简化了对业务代码的侵入性。那么对@Transactional事务注解了解的够全面吗?知道有哪些场景可能会导致@Transactional注解并不会如你预期的方式生效吗?知道应该怎么使用@Transactional才能保证对性能的影响最小化吗?
下面我们一起探讨下这些问题。
基于JDBC进行数据库操作的时候,如果需要进行事务的控制与处理,整体的一个处理流程如下图所示:
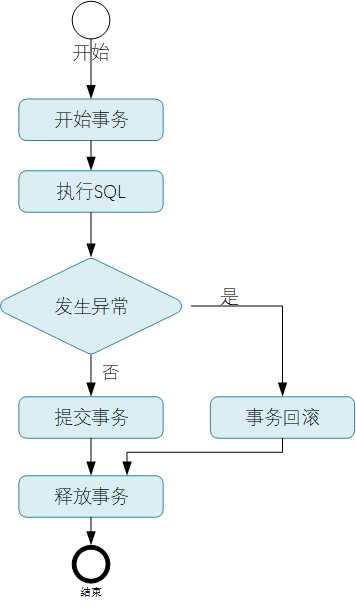
其中蓝色的部分为需要开发人员去进行实现的,也即JDBC场景下的事务保护与处理,整个事务过程的处理都是需要开发人员进行关注与处理的。
按照这个流程的逻辑,写一下对应的实现代码:
public void testJdbcTransactional(DataSource dataSource) {
Connection conn = null;
int result = 0;
try {
// 获取链接
conn = dataSource.getConnection();
// 禁用自动事务提交,改为手动控制
conn.setAutoCommit(false);
// 设置事务隔离级别
conn.setTransactionIsolation(
TransactionIoslationLevel.READ_COMMITTED.getLevel()
);
// 执行SQL
PreparedStatement ps =
conn.prepareStatement("insert into user (id, name) values (?, ?)");
ps.setString(1, "123456");
ps.setString(2, "Tom");
result = ps.executeUpdate();
// 执行成功,手动提交事务
conn.commit();
} catch (Exception e) {
// 出现异常,手动回滚事务
if (conn != null) {
try {
conn.rollback();
} catch (Exception e) {
// write log...
}
}
} finally {
// 执行结束,最终不管成功还是失败,都要释放资源,断开连接
try {
if (conn != null && !conn.isClosed()) {
conn.close();
}
} catch (Exception e) {
// write log...
}
}
}
Spring数据库事务约定处理逻辑流程如下:
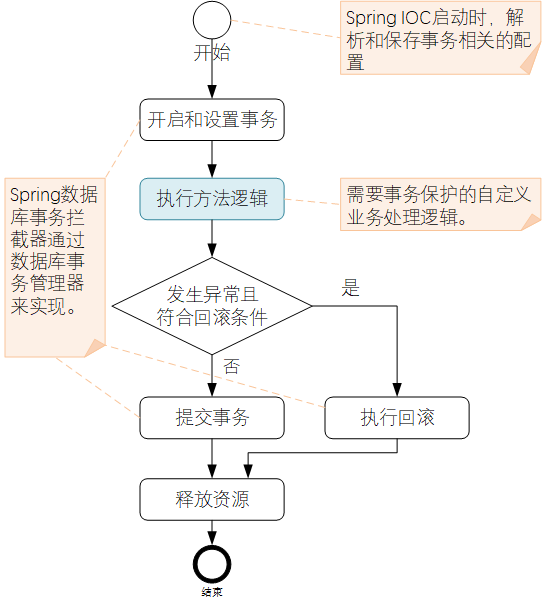
对比上一章节的JDBC的事务处理,Spring场景下,事务的处理操作交给了Spring框架处理,开发人员仅需要实现自己的业务逻辑即可,大大简化了事务方面的处理投入。
基于Spring事务机制,实现上述DB操作事务控制的代码,可以按照如下方式:
@Transactional
public void insertUser() {
userDao.insertUser();
}
与JDBC事务实现代码相比,基于Spring的方式只需要添加一个@Transactional注解即可,代码中只需要实现业务逻辑即可,实现了事务控制机制对业务代码的低侵入性。
Spring支持的基于Spring AOP实现的声明式事务功能,所谓声明式事务,即使用@Transactional注解进行声明标注,告诉Spring框架在什么地方启用数据库事务控制能力。@Transactional注解,可以添加在类或者方法上。如果其添加在类上时,表明此类中所有的public非静态方法都将启用事务控制能力。
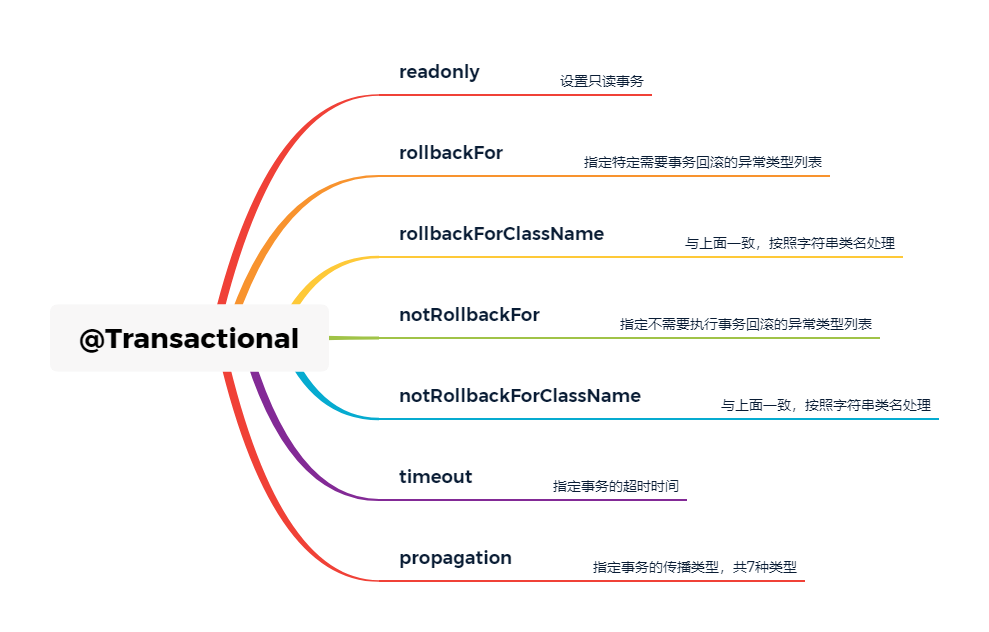
指定当前事务是否为一个只读事务。设置为true标识此事务是个只读事务,默认情况为false。
只读事务
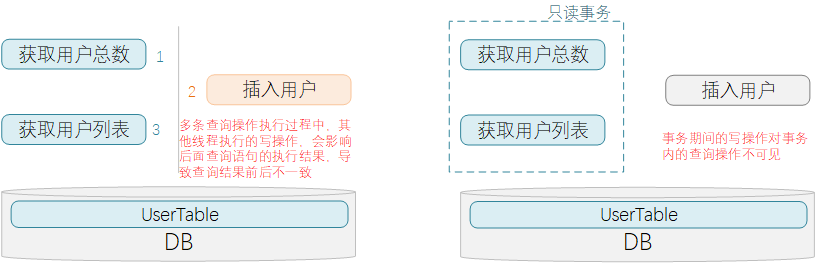
在多条查询语句一起执行的场景里面会涉及到的概念。表示在事务设置的那一刻开始,到整个事务执行结束的过程中,其他事务所提交的写操作数据,对该事务都不可见。
举个例子:
现在有一个复合查询操作,包含2条SQL查询操作:先获取用户表count数,再获取用户表中所有数据。
执行过程:
(1) 先执行完获取用户表count数,得到结果10
(2) 在还没开始执行后一条语句的时候,另一个进程操作了DB并往用户表中插入一条新数据
(3) 复合操作的第二条SQL语句,获取用户列表的操作被执行,返回了11条记录
很明显,复合操作中的两条SQL语句获取的数据结果无法匹配上。
为了避免此情况的发生,可以给复合查询操作添加上只读事务,这样事务控制范围内,事务外的写操作就不可见,这样就保证了事务内多条查询语句执行结果的一致性。
那为什么要设置为只读事务、而不是常规的事务呢?
主要是从执行效率角度的考虑。因为这个里的操作都是一些只读操作,所以设置为只读事务,数据库会为只读事务提供一些优化手段,比如不启动回滚段、不记录回滚log之类的。
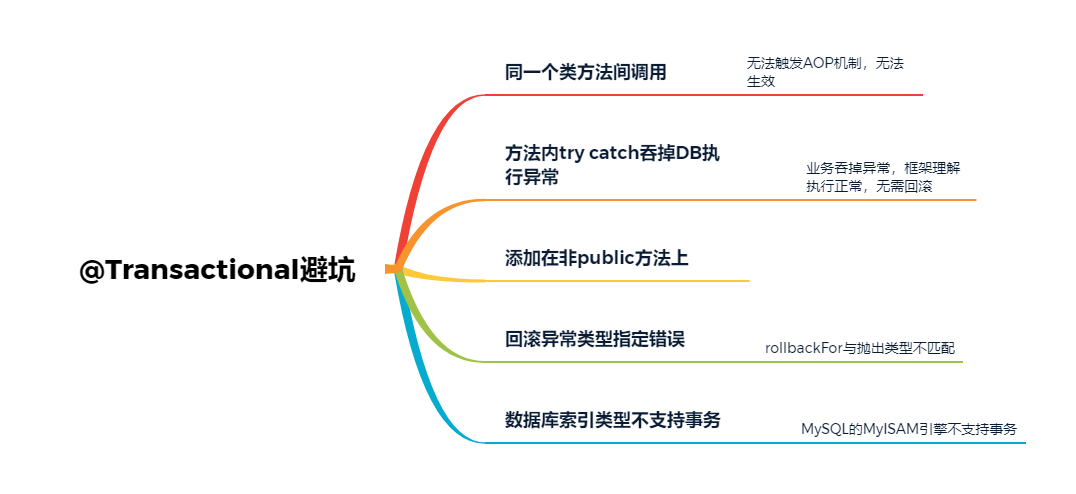
用于指定需要回滚的特定异常类型,可以指定一个或者多个。当指定rollbackFor或者rollbackForClassName之后,方法执行逻辑中只有抛出指定的异常类型,才会触发事务回滚。
// 指定单个异常
@Transactional(rollbackFor = DemoException.class)
public void insertUser() {
// do something here
}
// 指定多个异常
@Transactional(rollbackFor = {DemoException.class, DemoException2.class})
public void insertUser2() {
// do something here
}
rollbackFor和rollbackForClassName作用相同,只是提供了2个不同的指定方法,允许执行Class类型或者ClassName字符串。
// 指定异常名称
@Transactional(rollbackForClassName = {"DemoException"})
public void insertUser() {
// do something here
}
用于指定不需要进行回滚的异常类型,当方法中抛出指定类型的异常时,不进行事务回滚。
用于设置事务的超时秒数,默认值为-1,表示永不超时。
用于指定此事务对应的传播类型。所谓的事务传播类型,即当前已经在一个事务的上下文中时,又需要开始一个事务,这个时候来处理这个将要开启的新事务的处理策略。
主要有7种类型的事务传播类型:
- REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
- SUPPORTS:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
- MANDATORY:如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。
- REQUIRES_NEW:创建一个新的事务,如果当前存在事务,则把当前事务挂起。
- NOT_SUPPORTED:以非事务方式运行,如果当前存在事务,则把当前事务挂起。
- NEVER:以非事务方式运行,如果当前存在事务,则抛出异常。
- NESTED:如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于REQUIRED。
实际编码的时候,可以通过@Transactional注解中的propagation参数来指定具体的传播类型,取值由org.springframework.transaction.annotation.Propagation枚举类提供。如果不指定,则默认取值为Propagation.REQUIRED,也即如果当前存在事务,则加入该事务,如果当前没有事务,则创建一个新的事务。
/**
* The transaction propagation type.
* <p>Defaults to {@link Propagation#REQUIRED}.
* @see org.springframework.transaction.interceptor.TransactionAttribute#getPropagationBehavior()
*/
Propagation propagation() default Propagation.REQUIRED;
Spring的事务实现原理是AOP,而AOP的原理是动态代理。
在类内部方法之间相互调用的时候,本质上是类对象自身的调用,而不是使用代理对象去调用,也就不会触发AOP,这样其实Spring也就无法将事务控制的代码逻辑织入到调用代码流程中,所以这里的事务控制就无法生效。
所以遇到同一个类中多个方法之间相互调用,且调用的方法需要做事务控制的时候需要特别注意下这个问题。解决方式,可以建2个不同的类,然后将方法放到两个类中,这样跨类调用,Spring事务机制就可以生效。
如果将@Transactional注解添加在protected、private修饰的方法上,虽然代码不会有任何的报错,但是实际上注解是不会生效的。
这个其实很容易理解,业务代码中将所有的异常给catch并吞掉了,等同于业务代码认为被捕获的异常不需要去触发回滚。对框架而言,因为异常被捕获了,业务逻辑执行都在正常往下运行,所以也不会触发异常回滚机制。
// catch了可能的异常,导致DB操作失败的时候事务不会触发回滚
@Transactional
public void insertUser() {
try {
// do something here...
userRepository.save(user);
} catch (Exception e) {
log.error("failed to create user");
// 直接吞掉了异常,这样不会触发事务回滚机制
}
}
在业务处理逻辑中,如果确实需要知晓并捕获相关处理的异常进行一些额外的业务逻辑处理,如果要保证事务回滚机制生效,最后需要往外抛出RuntimeException异常,或者是继承RuntimeException实现的业务自定义异常。如下:
// catch了可能的异常,对外抛出RuntimeException或者其子类,可触发事务回滚
@Transactional
public void insertUser() {
try {
// do something here...
userRepository.save(user);
} catch (Exception e) {
log.error("failed to create user");
// @Transactional没有指定rollbackFor,所以抛出RuntimeException或者其子类,可触发事务回滚机制
throw new RuntimeException(e);
}
}
当然,如果@Transactional注解指定了rollbackFor为某个具体的异常类型,则最终需要保证异常时对外抛出相匹配的异常类型,才可以触发事务处理逻辑。如下:
// catch了指定异常,对外抛出对应类型的异常,可触发事务回滚
@Transactional(rollbackFor = DemoException.class)
public void insertUser() {
try {
// do something here...
userRepository.save(user);
} catch (Exception e) {
log.error("failed to create user");
// @Transactional有指定rollbackFor,抛出异常要与rollbackFor指定异常类型一致
throw new DemoException();
}
}
以MySQL数据库而言,常见的数据库引擎有InnoDB和Myisam等类型,但是MYISAM引擎类型是不支持事务的。所以如果建表时设置的引擎类型设置为MYISAM的话,即使代码里面添加了@Transactional最终事务也不会生效的。
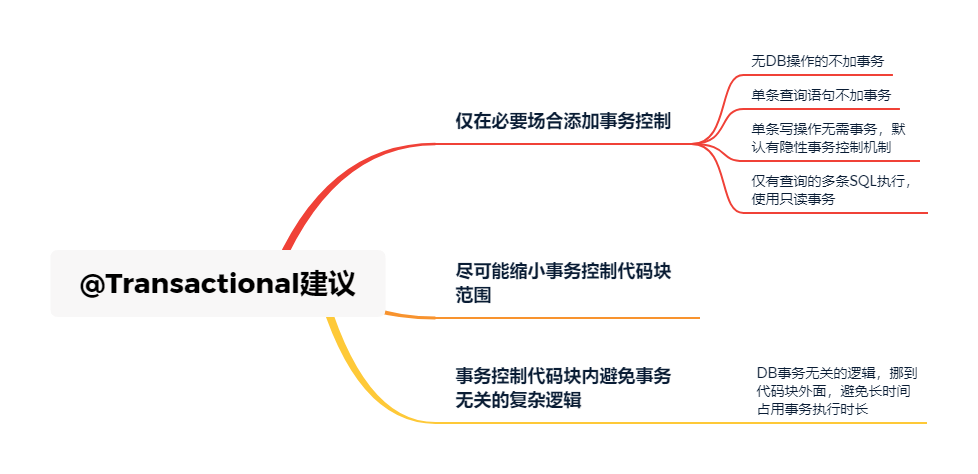
因为事务处理对性能会有一定的影响,所以事务也不是说任何地方都可以随便添加的。对于一些性能敏感场景,需要注意几点:
(1)不含有DB操作相关,无需添加事务控制
(2)单条查询语句,没必要添加事务控制
(3)仅有查询操作的多条SQL执行场景,可以添加只读事务控制
(4)单条insert/update/delete语句,其实也不需要添加@Transactional事务处理,因为单条语句执行其实数据库有隐性事务控制机制,如果执行失败,是属于SQL报错,数据不会更新成功,自然也无需回滚。
主要从性能层面考虑,事务机制,类似于并发场景的加锁处理,范围越大对性能影响越明显
也是从性能层面考虑,尽量将耗时的逻辑放到事务控制之外执行,事务内仅保留与DB操作切实相关的逻辑
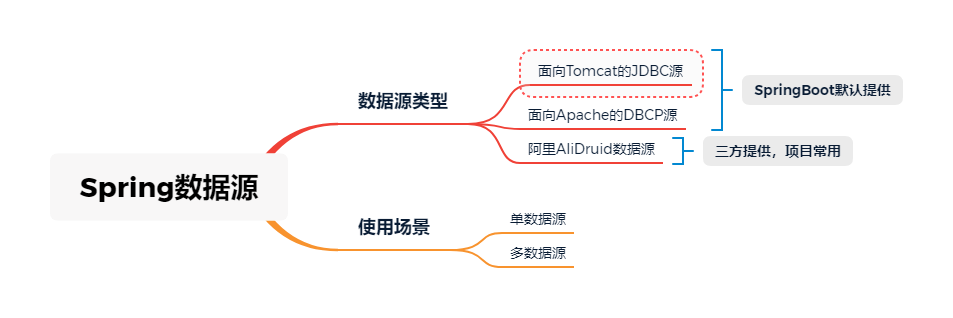
SpringBoot为DataSource提供了两种最为常见的默认配置:
至于具体使用哪一个,主要是看项目pom.xml中引入了哪个jar了。
对于使用SpringBoot默认配置的项目而言,SpringBoot默认使用的是Tomcat容器,所以默认情况也是使用的Tomcat的JDBC的DataSource及其连接池。
看一下配置数据加载类DataSourceProperties的写法:
所以我们的数据源配置信息,相关配置项需要以spring.datasource开头,如下:
spring.datasource.url=jdbc:mysql://<ip>:<port>/vzn-demo?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai
spring.datasource.username=vzn-demo
spring.datasource.password=<password>
除了SpringBoot自带的DataSource类型,还有一些其他三方提供的DataSource。项目开发工作中比较常用的有AliDruid DataSource,这里也介绍下。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.22</version>
</dependency>
# 数据库连接信息
spring.datasource.druid.url=jdbc:mysql://<ip>:<port>/<db-name>?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai
spring.datasource.druid.username=<userName>
# 可以设置配置的密码是否加密
spring.datasource.druid.connect-properties.config.decrypt=false
spring.datasource.druid.password=<password>
在大型的项目中,可能会涉及到服务需要同时连接多个数据库进行数据操作的场景,这里就会涉及到多个DataSource的配置。
举个例子,现在有一个社交论坛服务,其发帖(Post)和评论(Comment)分别对应两个DB,使用AliDruidDataSource的情况下,应该如何配置呢?
前面内容有提过,所有的数据源相关配置项需要以spring.datasource开头。而我们使用AliDruid进行多个数据源的配置时,我们需要设定各个数据源的若干配置都以spring.datasource.druid.{xxx}开头。比如本例中,我们可以对发帖DB、评论DB两个数据源约定前缀分别为spring.datasource.druid.post以及spring.datasource.druid.comment。
在application.properties中配置两个数据源的信息:
# Post数据源信息
spring.datasource.druid.post.url=jdbc:mysql://<ip>:<port>/<db-name>?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai
spring.datasource.druid.post.username=<userName>
spring.datasource.druid.post.connect-properties.config.decrypt=false
spring.datasource.druid.post.password=<password>
# Comment数据源信息
spring.datasource.druid.comment.url=jdbc:mysql://<ip>:<port>/<db-name>?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai
spring.datasource.druid.comment.username=<userName>
spring.datasource.druid.comment.connect-properties.config.decrypt=false
spring.datasource.druid.comment.password=<password>
接前面的例子,在application.properties中配置了两个数据源之后,需要实现两个JAVA类用于读取配置并做相关的配置处理。
针对Post数据源:
@Configuration
@EnableTransactionManagement
@EnableConfigurationProperties(JpaProperties.class)
@EnableJpaRepositories(
entityManagerFactoryRef="entityManagerFactoryPost",
transactionManagerRef="transactionManagerPost",
basePackages = {"com.vzn.demo.post.repository"} // 设置哪些package下面的repository使用此数据源
)
public class DataSourcePostConfig {
@Primary
@Bean
@ConfigurationProperties("spring.datasource.druid.post")
public DataSource dataSourcePost() {
return DruidDataSourceBuilder.create().build();
}
@Autowired
private DataSource dataSourcePost;
@Primary
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryPost(EntityManagerFactoryBuilder builder) {
return builder
.dataSource(dataSourcePost)
.packages("com.vzn.demo.post.entity") // 设置哪些package下面的实体使用此数据源
.build();
}
@Primary
@Bean
public EntityManager entityManagerPost(EntityManagerFactoryBuilder builder) {
return entityManagerFactoryPost(builder).getObject().createEntityManager();
}
@Autowired
private JpaProperties jpaProperties;
@Primary
@Bean
public PlatformTransactionManager transactionManagerPost(EntityManagerFactoryBuilder builder) {
return new JpaTransactionManager(entityManagerFactoryPost(builder).getObject());
}
}
针对Comment数据源:
@Configuration
@EnableTransactionManagement
@EnableConfigurationProperties(JpaProperties.class)
@EnableJpaRepositories(
entityManagerFactoryRef="entityManagerFactoryComment",
transactionManagerRef="transactionManagerComment",
basePackages = {"com.vzn.demo.comment.repository"} // 设置哪些package下面的repository使用此数据源
)
public class DataSourceCommentConfig {
@Primary
@Bean
@ConfigurationProperties("spring.datasource.druid.comment")
public DataSource dataSourceComment() {
return DruidDataSourceBuilder.create().build();
}
@Autowired
private DataSource dataSourceComment;
@Primary
@Bean
public LocalContainerEntityManagerFactoryBean entityManagerFactoryComment(EntityManagerFactoryBuilder builder) {
return builder
.dataSource(dataSourceComment)
.packages("com.vzn.demo.comment.entity") // 设置哪些package下面的实体使用此数据源
.build();
}
@Primary
@Bean
public EntityManager entityManagerComment(EntityManagerFactoryBuilder builder) {
return entityManagerFactoryComment(builder).getObject().createEntityManager();
}
@Autowired
private JpaProperties jpaProperties;
@Primary
@Bean
public PlatformTransactionManager transactionManagerPost(EntityManagerFactoryBuilder builder) {
return new JpaTransactionManager(entityManagerFactoryPost(builder).getObject());
}
}
上述数据源配置类中,有指定了不同package下面的代码,使用对应不同的DataSource,所以具体使用的时候与正常情况无异,按照约定将不同数据源对应处理DAO类放到各自指定的package下即可,service层代码可以按照正常逻辑调用,无需感知DAO层的数据源差异。当然,如果某些例外场景下,可以通过@Transactional(rollbackFor = Exception.class, transactionManager= "transactionManagerPost")这种方式显式的指定要使用某个具体数据源。
虽然,对于多数据源有明确的处理与支持手段,但是多数据源加剧了代码维护的难度与开发过程中的复杂度,所以笔者认为代码架构层面需要多一些思考与优化,可以通过微服务化拆分的方式来尽量避免出现多数据源的场景。
好啦,本篇内容就介绍到这里。
通过本篇的内容,我们对Spring项目里面的数据库事务处理相关的概念有了一个相对全面的了解,也知道了一些可能导致Spring事务失效的因素。
通过前面的系列文档,我们一起对SpringData JPA从浅入深的进行了全方位的探讨。正所谓“工欲善其事、必先利其器”,面对一个优秀的框架,如果再结合一些外部的工具,其实可以让我们的开发效率与程序员开发过程的体验更上一层楼的。在下一篇文档里,我们将一起聊聊如何利用工具来让我们的开发过程进一步的简化。
如果对本文有自己的见解,或者有任何的疑问或建议,都可以留言,我们一起探讨、共同进步。
补充
Spring Data JPA作为Spring Data中对于关系型数据库支持的一种框架技术,属于ORM的一种,通过得当的使用,可以大大简化开发过程中对于数据操作的复杂度。本文档隶属于《
Spring Data JPA用法与技能探究》系列的第4篇。本系列文档规划对Spring Data JPA进行全方位的使用介绍,一共分为5篇文档,如果感兴趣,欢迎关注交流。《Spring Data JPA用法与技能探究》系列涵盖内容:
- 开篇介绍 —— 《Spring Data JPA系列1:JDBC、ORM、JPA、Spring Data JPA,傻傻分不清楚?给你个选择SpringDataJPA的理由!》
- 快速上手 —— 《Spring Data JPA系列2:SpringBoot集成JPA详细教程,快速在项目中熟练使用JPA》
- 深度进阶 —— 《Spring Data JPA系列3:JPA项目中核心场景与进阶用法介绍》
- 可靠保障 —— 《Spring Data JPA系列4——Spring声明式事务处理与多数据源支持》
- 周边扩展 —— 《JPA开发辅助效率提升方案介绍》
我是悟道,聊技术、又不仅仅聊技术~
如果觉得有用,请点个关注,也可以关注下我的公众号【架构悟道】,获取更及时的更新。
期待与你一起探讨,一起成长为更好的自己。

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA
我发现ActiveRecord::Base.transaction在复杂方法中非常有效。我想知道是否可以在如下事务中从AWSS3上传/删除文件:S3Object.transactiondo#writeintofiles#raiseanexceptionend引发异常后,每个操作都应在S3上回滚。S3Object这可能吗?? 最佳答案 虽然S3API具有批量删除功能,但它不支持事务,因为每个删除操作都可以独立于其他操作成功/失败。该API不提供任何批量上传功能(通过PUT或POST),因此每个上传操作都是通过一个独立的API调用完成的
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
我已经开始使用mysql2gem。我试图弄清楚一些基本的事情——其中之一是如何明确地执行事务(对于批处理操作,比如多个INSERT/UPDATE查询)。在旧的ruby-mysql中,这是我的方法:client=Mysql.real_connect(...)inserts=["INSERTINTO...","UPDATE..WHEREid=..",#etc]client.autocommit(false)inserts.eachdo|ins|beginclient.query(ins)rescue#handleerrorsorabortentirelyendendclient.commi