Elasticsearch SQL 是一个 X-Pack 组件,它允许对 Elasticsearch 实时执行类似 SQL 的查询。无论是使用 REST 接口、命令行还是 JDBC,任何客户机都可以使用 SQL 在 Elasticsearch 中本地搜索和聚合数据。我们可以把 Elasticsearch SQL 看作一个翻译器,它同时理解 SQL 和 Elasticsearch,并且通过 Elasticsearch 的功能,可以方便地实时读取和处理数据。
官方文档:
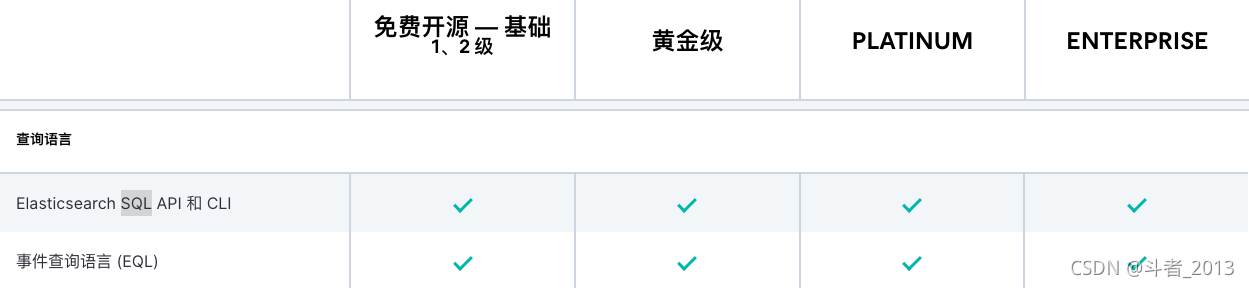
根据版本级别的特征支持说明:https://www.elastic.co/cn/subscriptions
免费开源的版本中,已经提供了对Elasticsearch SQL API功能的支持。
我们通过对官网链接的版本号修改会发现:
1、6.3版本还能正常访问到sql-overview相关介绍
https://www.elastic.co/guide/en/elasticsearch/reference/6.3/sql-overview.html#sql-introduction
2、切换成6.2后,出现页面不可用的提示。
https://www.elastic.co/guide/en/elasticsearch/reference/6.2/sql-overview.html#sql-introduction
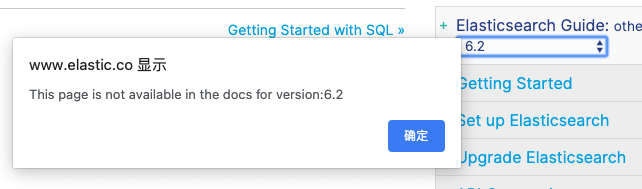
可以初步得出结论,ES6.3之后的版本才提供免费的Elasticsearch SQL的特性。
2019年5月21日,Elastic官方发布消息: Elastic Stack 新版本6.8.0 和7.1.0的核心安全功能现免费提供。
这意味着用户现在能够对网络流量进行加密、创建和管理用户、定义能够保护索引和集群级别访问权限的角色,并且使用 Spaces 为 Kibana提供全面保护。
免费提供的核心安全功能如下:
1)TLS 功能。 可对通信进行加密;
2)文件和原生 Realm。 可用于创建和管理用户;
3)基于角色的访问控制。 可用于控制用户对集群 API 和索引的访问权限;通过针对 Kibana Spaces 的安全功能,还可允许在Kibana 中实现多租户。

1)5.X版本之前:没有x-pack,是独立的:security安全,watch查看,alert警告等独立单元。
2)5.X版本:对原本的安全,警告,监视,图形和报告做了一个封装,形成了x-pack。
3)6.3 版本之前:需要额外安装。
4)6.3版本及之后:已经集成在一起发布,无需额外安装,基础安全属于付费黄金版内容。
5)6.8.0和7 .1版本:基础安全免费。
2018年2月28日X-Pack 特性的所有代码开源,主要包含:
Security、Monitoring、Alerting、Graph、Reporting、专门的 APM UI、Canvas、Elasticsearch SQL、Search Profiler、Grok Debugger、Elastic Maps Service zoom levels 以及 Machine Learning。
2019年5月21日免费开放了文章开头的基础安全功能,在这之前的版本都是仅有1个月的适用期限的。
如下功能点仍然是收费的。
付费黄金版&白金版提供功能:
付费白金版提供安全功能:
PUT /library/book/_bulk?refresh
{"index":{"_id": "Leviathan Wakes"}}
{"name": "Leviathan Wakes", "author": "James S.A. Corey", "release_date": "2011-06-02", "page_count": 561}
{"index":{"_id": "Hyperion"}}
{"name": "Hyperion", "author": "Dan Simmons", "release_date": "1989-05-26", "page_count": 482}
{"index":{"_id": "Dune"}}
{"name": "Dune", "author": "Frank Herbert", "release_date": "1965-06-01", "page_count": 604}
POST /_sql?format=txt
{
"query": "SELECT * FROM library WHERE release_date < '2000-01-01'"
}
响应结果:
author | name | page_count | release_date
---------------+---------------+---------------+------------------------
Dan Simmons |Hyperion |482 |1989-05-26T00:00:00.000Z
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z
主要有如下格式化类型:
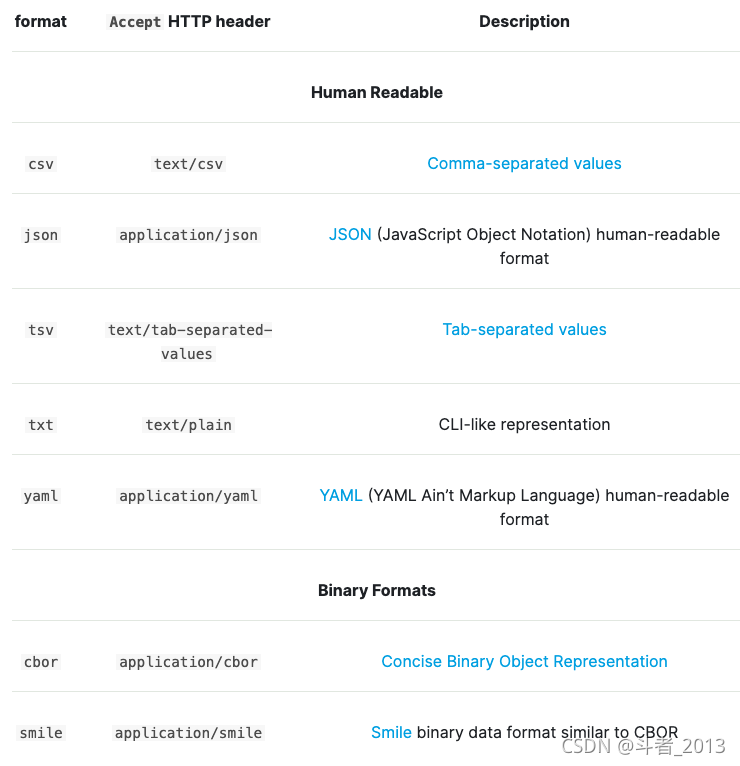
其中用的最多的主要是csv、json、text。
JSON:
POST /_sql?format=json
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
{
"columns": [
{"name": "author", "type": "text"},
{"name": "name", "type": "text"},
{"name": "page_count", "type": "short"},
{"name": "release_date", "type": "datetime"}
],
"rows": [
["Peter F. Hamilton", "Pandora's Star", 768, "2004-03-02T00:00:00.000Z"],
["Vernor Vinge", "A Fire Upon the Deep", 613, "1992-06-01T00:00:00.000Z"],
["Frank Herbert", "Dune", 604, "1965-06-01T00:00:00.000Z"],
["Alastair Reynolds", "Revelation Space", 585, "2000-03-15T00:00:00.000Z"],
["James S.A. Corey", "Leviathan Wakes", 561, "2011-06-02T00:00:00.000Z"]
],
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWWWdrRlVfSS1TbDYtcW9lc1FJNmlYdw==:BAFmBmF1dGhvcgFmBG5hbWUBZgpwYWdlX2NvdW50AWYMcmVsZWFzZV9kYXRl+v///w8="
}
CSV:
POST /_sql?format=csv
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
author,name,page_count,release_date
Peter F. Hamilton,Pandora's Star,768,2004-03-02T00:00:00.000Z
Vernor Vinge,A Fire Upon the Deep,613,1992-06-01T00:00:00.000Z
Frank Herbert,Dune,604,1965-06-01T00:00:00.000Z
Alastair Reynolds,Revelation Space,585,2000-03-15T00:00:00.000Z
James S.A. Corey,Leviathan Wakes,561,2011-06-02T00:00:00.000Z
POST /_sql?format=txt
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"filter": {
"range": {
"page_count": {
"gte" : 100,
"lte" : 200
}
}
},
"fetch_size": 5
}
可以直接将参数组装成完整的SQL语句,也可以使用?占位符来传参。
POST /_sql?format=txt
{
"query": "SELECT YEAR(release_date) AS year FROM library WHERE page_count > ? AND author = ? GROUP BY year HAVING COUNT(*) > ?",
"params": [300, "Frank Herbert", 0]
}
POST _sql?format=txt
{
"runtime_mappings": {
"release_day_of_week": {
"type": "keyword",
"script": """
emit(doc['release_date'].value.dayOfWeekEnum.toString())
"""
}
},
"query": """
SELECT * FROM library WHERE page_count > 300 AND author = 'Frank Herbert'
"""
}
响应结果:
author | name | page_count | release_date |release_day_of_week
---------------+---------------+---------------+------------------------+-------------------
Frank Herbert |Dune |604 |1965-06-01T00:00:00.000Z|TUESDAY
POST /_sql/translate
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 10
}
响应结果:
{
"size": 10,
"_source": false,
"fields": [
{
"field": "author"
},
{
"field": "name"
},
{
"field": "page_count"
},
{
"field": "release_date",
"format": "strict_date_optional_time_nanos"
}
],
"sort": [
{
"page_count": {
"order": "desc",
"missing": "_first",
"unmapped_type": "short"
}
}
]
}
查看支持的所有函数:
SHOW FUNCTIONS;
查看支持的天数相关函数:
SHOW FUNCTIONS LIKE '%DAY%';
name | type
---------------+---------------
DAY |SCALAR
DAYNAME |SCALAR
DAYOFMONTH |SCALAR
DAYOFWEEK |SCALAR
DAYOFYEAR |SCALAR
DAY_NAME |SCALAR
DAY_OF_MONTH |SCALAR
DAY_OF_WEEK |SCALAR
DAY_OF_YEAR |SCALAR
HOUR_OF_DAY |SCALAR
ISODAYOFWEEK |SCALAR
ISO_DAY_OF_WEEK|SCALAR
MINUTE_OF_DAY |SCALAR
TODAY |SCALAR
Elasticsearch SQL 提供了一整套内置的操作符和函数:
官网说明:sql-functions

使用子选择(SELECT x FROM (SELECT y))在很小程度上是受支持的: Elasticsearch SQL 可以将任何子选择“扁平化”为单个 SELECT。
SELECT * FROM (SELECT first_name, last_name FROM emp WHERE last_name NOT LIKE '%a%') WHERE first_name LIKE 'A%' ORDER BY 1;
first_name | last_name
---------------+---------------
Alejandro |McAlpine
Anneke |Preusig
Anoosh |Peyn
Arumugam |Ossenbruggen
注意:
如果子查询中包含 GROUP BY 或 HAVING 或封闭的 SELECT语句,这些比 SELECT X FROM (SELECT ...) WHERE [simple_condition]更复杂的查询,目前不支持。
更多ES中SQL查询的限制,可以查看官网说明SQL Limitations
1)使用limit限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT * FROM library limit 2"
}
2)使用top函数限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT top 2 * FROM library"
}
3)使用fetch_size参数限制返回记录数:
POST /_sql?format=txt
{
"query": "SELECT * FROM library",
"fetch_size":2
}
4)采用limit结合自查询进行分页查询:
POST /_sql?format=txt
{
"query": "SELECT * FROM (SELECT * FROM library limit 2) limit 1"
}
5)通过游标访问下一页:
说明:
在采用CSV, TSV 和 TXT 格式化返回时, 会返回一个游标值cursor,通过游标值我们可以继续访问下一页。
这种方式非常时候大数据量的分页返回。
POST /_sql?format=json
{
"query": "SELECT * FROM library ORDER BY page_count DESC",
"fetch_size": 5
}
响应结果:
```csharp
{
"columns": [
{"name": "author", "type": "text"},
{"name": "name", "type": "text"},
{"name": "page_count", "type": "short"},
{"name": "release_date", "type": "datetime"}
],
"rows": [
["Peter F. Hamilton", "Pandora's Star", 768, "2004-03-02T00:00:00.000Z"],
["Vernor Vinge", "A Fire Upon the Deep", 613, "1992-06-01T00:00:00.000Z"],
["Frank Herbert", "Dune", 604, "1965-06-01T00:00:00.000Z"],
["Alastair Reynolds", "Revelation Space", 585, "2000-03-15T00:00:00.000Z"],
["James S.A. Corey", "Leviathan Wakes", 561, "2011-06-02T00:00:00.000Z"]
],
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWWWdrRlVfSS1TbDYtcW9lc1FJNmlYdw==:BAFmBmF1dGhvcgFmBG5hbWUBZgpwYWdlX2NvdW50AWYMcmVsZWFzZV9kYXRl+v///w8="
}
通过游标访问下一页:
POST /_sql?format=json
{
"cursor": "sDXF1ZXJ5QW5kRmV0Y2gBAAAAAAAAAAEWYUpOYklQMHhRUEtld3RsNnFtYU1hQQ==:BAFmBGRhdGUBZgVsaWtlcwFzB21lc3NhZ2UBZgR1c2Vy9f///w8="
}
虽然 SQL 和 Elasticsearch 对于数据的组织方式(以及不同的语义)有不同的术语,但本质上它们的用途是相同的。
SQL
Elasticsearch
说明
column
field
在 Elasticsearch 字段时,SQL 将这样的条目调用为 column。注意,在 Elasticsearch,一个字段可以包含同一类型的多个值(本质上是一个列表) ,而在 SQL 中,一个列可以只包含一个表示类型的值。Elasticsearch SQL 将尽最大努力保留 SQL 语义,并根据查询的不同,拒绝那些返回多个值的字段。
row
document
列和字段本身不存在; 它们是行或文档的一部分。两者的语义略有不同: 行row往往是严格的(并且有更多的强制执行),而文档往往更灵活或更松散(同时仍然具有结构)。
table
index
在 SQL 还是 Elasticsearch 中查询针对的目标
schema
无
在关系型数据库中,schema 主要是表的名称空间,通常用作安全边界。Elasticsearch没有为它提供一个等价的概念。
本文主要介绍了Elasticsearch SQL的使用。如果你对DSL查询语句不熟悉,那么采用SQL查询索引数据将是一个非常简单,0门槛入门的好方法。
1、注意ES在6.3版本之后才原生支持SQL查询。
2、可以通过translate API将sql语句转为DSL语句。
3、ES的SQL查询提供对自查询的简单支持。
4、通过SHOW FUNCTIONS可以查看ES的SQL查询支持的函数。
5、ES的SQL查询可以通过游标cursor实现分页查询。
先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级java工程师,想要升技能,往往是需要自己摸索成长或是报班学习,但对于培训机构动则近万元的学费,着实压力不小。自己不成体系的自学效率很低又漫长,而且容易碰到天花板技术停止不前。因此我收集了一份《java开发全套学习资料》送给大家,初衷也很简单,就是希望帮助到想自学又不知道该从何学起的朋友,同时减轻大家的负担。添加下方名片,即可获取全套学习资料哦
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
我在Rails上使用带有ruby的solr。一切正常,我只需要知道是否有任何现有代码来清理用户输入,比如以?开头的查询。或* 最佳答案 我不知道执行此操作的任何代码,但理论上可以通过查看parsingcodeinLucene来完成并搜索thrownewParseException(只有16个匹配!)。在实践中,我认为您最好只捕获代码中的任何solr异常并显示“无效查询”消息或类似信息。编辑:这里有几个“sanitizer”:http://pivotallabs.com/users/zach/blog/articles/937-s
我正在为锦标赛开发一个Rails应用程序。我在这个查询中使用了三个模型:classPlayertruehas_and_belongs_to_many:tournamentsclassTournament:destroyclassPlayerMatch"Player",:foreign_key=>"player_one"belongs_to:player_two,:class_name=>"Player",:foreign_key=>"player_two"在tournaments_controller的显示操作中,我调用以下查询:Tournament.where(:id=>params
我想用sunspot重现以下原始solr查询q=exact_term_text:fooORterm_textv:foo*ORalternate_text:bar*但我无法通过标准的太阳黑子界面理解这是否可能以及如何实现,因为看起来:fulltext方法似乎不接受多个文本/搜索字段参数我不知道将什么参数作为第一个参数传递给fulltext,就好像我通过了"foo"或"bar"结果不匹配如果我传递一个空参数,我得到一个q=*:*范围过滤器(例如with(:term).starting_with('foo*')(顾名思义)作为过滤器查询应用,因此不参与评分。似乎可以手动编写字符串(或者可能使
例如,假设我有一个名为Products的模型,并且在ProductsController中,我有以下代码用于product_listView以显示已排序的产品。@products=Product.order(params[:order_by])让我们想象一下,在product_listView中,用户可以使用下拉菜单按价格、评级、重量等进行排序。数据库中的产品不会经常更改。我很难理解的是,每次用户选择新的order_by过滤器时,rails是否必须查询,或者rails是否能够以某种方式缓存事件记录以在服务器端重新排序?有没有一种方法可以编写它,以便在用户排序时rails不会重新查询结果