Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
(1)查询所有:查询出所有数据,一般测试用。例如:match_all
(2)全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
1️⃣match_query
2️⃣multi_match_query
(3)精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
1️⃣ids
2️⃣range
3️⃣term
(4)地理(geo)查询:根据经纬度查询。例如:
1️⃣geo_distance
2️⃣geo_bounding_box
(5)复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
1️⃣bool
2️⃣function_score
查询的基本语法如下:
GET /indexName/_search { "query": { "查询类型": { "查询条件": "条件值" } } }// 查询所有 GET /indexName/_search { "query": { "match_all": { } } }
全文检索查询,会对用户输入内容分词,常用于搜索框搜索
match查询:全文检索查询的一种,会对用户输入内容分词,然后去倒排索引库检索,语法:
GET /indexName/_search { "query": { "match": { "FIELD": "TEXT" } } }
multi_match:与match查询类似,只不过允许同时查询多个字段,语法:
GET /indexName/_search { "query": { "multi_match": { "query": "TEXT", "fields": ["FIELD1", " FIELD12"] } } }
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
(1)term:根据词条精确值查询(根据词条精确匹配,一般搜索keyword类型、数值类型、布尔类型、日期类型字段)
(2)range:根据值的范围查询(根据数值范围查询,可以是数值、日期的范围)
term查询:
// term查询 GET /indexName/_search { "query": { "term": { "FIELD": { "value": "VALUE" } } } }
range查询:
// range查询 GET /indexName/_search { "query": { "range": { "FIELD": { "gte": 10, "lte": 20 } } } }
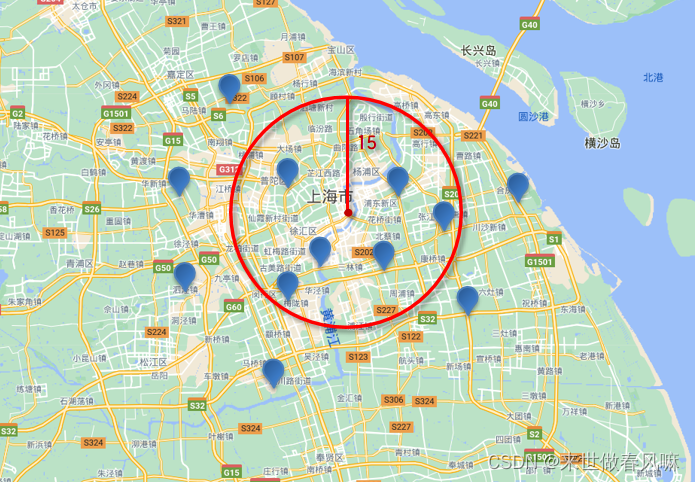
根据经纬度查询。常见的使用场景包括:
(1)携程:搜索我附近的酒店
(2)滴滴:搜索我附近的出租车
(3)微信:搜索我附近的人
根据经纬度查询
例如: geo_bounding_box:查询geo_point值落在某个矩形范围的所有文档
// range查询 GET /indexName/_search { "query": { "range": { "FIELD": { "gte": 10, "lte": 20 } } } }
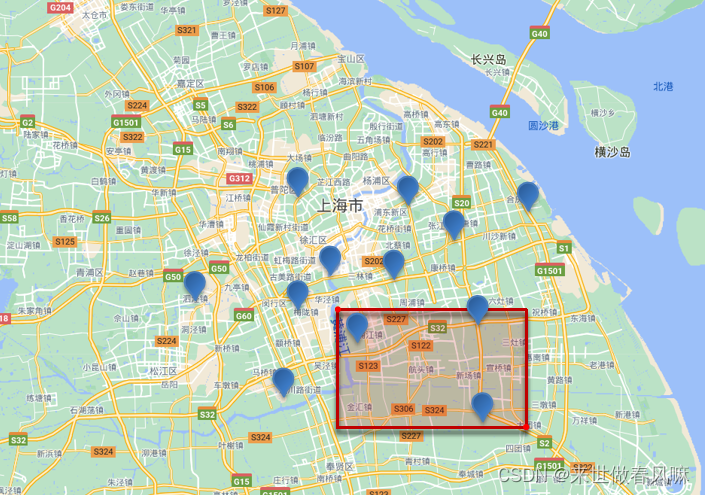
根据经纬度查询,
geo_distance:查询到指定中心点小于某个距离值的所有文档
// geo_distance 查询 GET /indexName/_search { "query": { "geo_distance": { "distance": "15km", "FIELD": "31.21,121.5" } } }
复合查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑,例如:
(1)fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名。例如百度竞价
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。 例如,我们搜索 "虹桥如家",结果如下:
[ { "_score" : 17.850193, "_source" : { "name" : "虹桥如家酒店真不错", } }, { "_score" : 12.259849, "_source" : { "name" : "外滩如家酒店真不错", } }, { "_score" : 11.91091, "_source" : { "name" : "迪士尼如家酒店真不错", } } ]
elasticsearch中的相关性打分算法是什么?
(1)TF-IDF:在elasticsearch5.0之前,会随着词频增加而越来越大
(2)BM25:在elasticsearch5.0之后,会随着词频增加而增大,但增长曲线会趋于水平
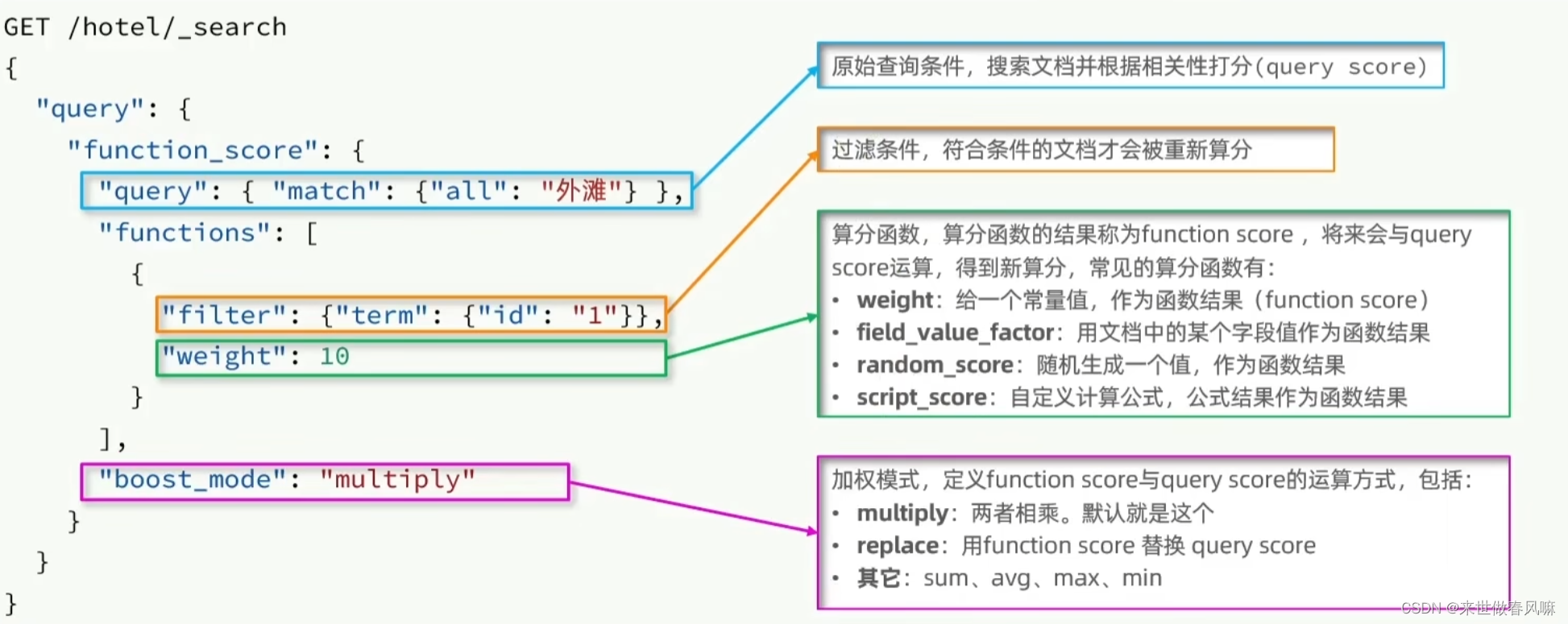
使用 function score query,可以修改文档的相关性算分(query score),根据新得到的算分排序。
案例:给“如家”这个品牌的酒店排名靠前一些
把这个问题翻译一下,function score需要的三要素:
(1)哪些文档需要算分加权? 品牌为如家的酒店
(2)算分函数是什么? weight就可以
(3)加权模式是什么? 求和
GET /hotel/_search { "query": { "function_score": { "query": {// ... }, "functions": [ // 算分函数 { "filter": { // 满足的条件,品牌必须是如家 "term": { "brand": "如家" } }, "weight": 2 // 算分权重为2 } ], "boost_mode": "sum" } } }
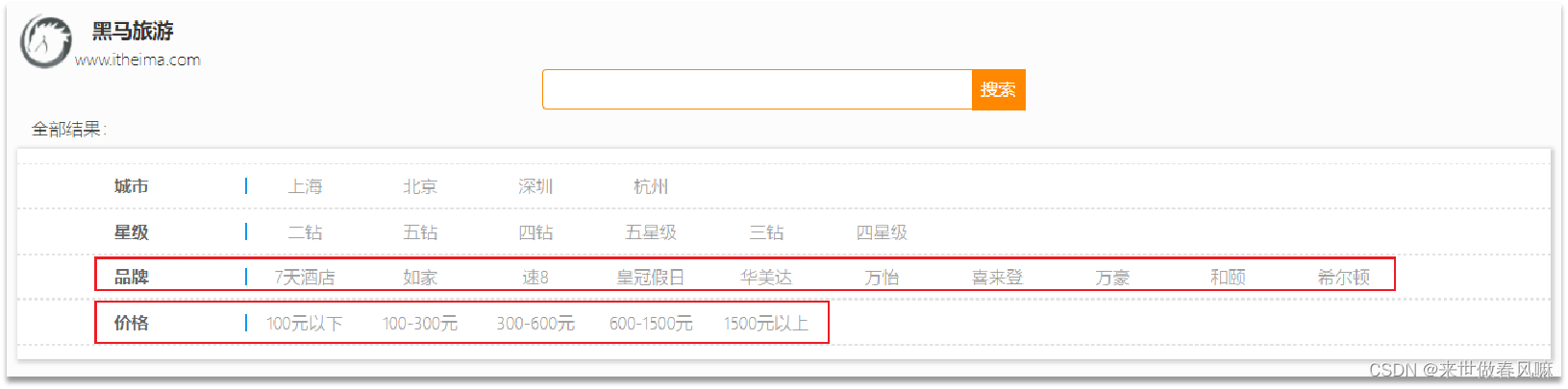
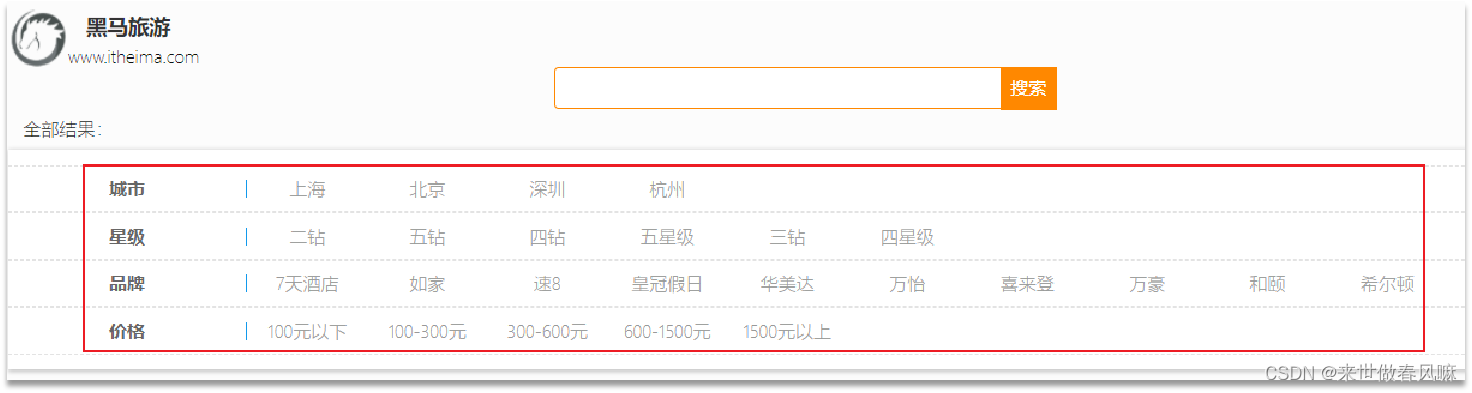
布尔查询是一个或多个查询子句的组合。子查询的组合方式有:
(1)must:必须匹配每个子查询,类似“与”
(2)should:选择性匹配子查询,类似“或”
(3)must_not:必须不匹配,不参与算分,类似“非”
(4)filter:必须匹配,不参与算分
GET /hotel/_search { "query": { "bool": { "must": [ {"term": {"city": "上海" }} ], "should": [ {"term": {"brand": "皇冠假日" }}, {"term": {"brand": "华美达" }} ], "must_not": [ { "range": { "price": { "lte": 500 } }} ], "filter": [ { "range": {"score": { "gte": 45 } }} ] } } }
案例:利用bool查询实现功能
需求:搜索名字包含“如家”,价格不高于400,在坐标31.21,121.5周围10km范围内的酒店。
GET /hotel/_search { "query": { "bool": { "must": [ { "match": {"name": "如家"} } ], "must_not": [ { "range": { "price": {"gt": 400}} } ], "filter": [ { "geo_distance": { "distance": "10km", "location": {"lat": 31.21, "lon": 121.5} } } ] } } }
elasticsearch支持对搜索结果排序,默认是根据相关度算分(_score)来排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
GET /indexName/_search { "query": { "match_all": {} }, "sort": [ { "FIELD": "desc" // 排序字段和排序方式ASC、DESC } ] }GET /indexName/_search { "query": { "match_all": {} }, "sort": [ { "_geo_distance" : { "FIELD" : "纬度,经度", "order" : "asc", "unit" : "km" } } ] }
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
GET /hotel/_search { "query": { "match_all": {} }, "from": 990, // 分页开始的位置,默认为0 "size": 10, // 期望获取的文档总数 "sort": [ {"price": "asc"} ] }
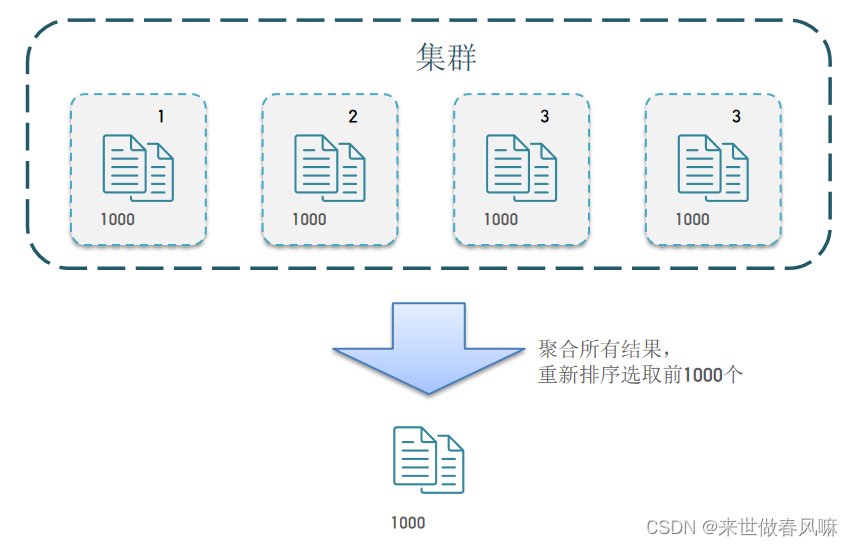
ES是分布式的,所以会面临深度分页问题。例如按price排序后,获取from = 990,size =10的数据:
(1)首先在每个数据分片上都排序并查询前1000条文档。
(2)然后将所有节点的结果聚合,在内存中重新排序选出前1000条文档
(3)最后从这1000条中,选取从990开始的10条文档
如果搜索页数过深,或者结果集(from + size)越大,对内存和CPU的消耗也越高。因此ES设定结果集查询的上限是10000
针对深度分页,ES提供了两种解决方案:
(1)search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
(2)scroll:原理将排序数据形成快照,保存在内存。官方已经不推荐使用。
高亮:就是在搜索结果中把搜索关键字突出显示。
原理是这样的:
(1)将搜索结果中的关键字用标签标记出来
(2)在页面中给标签添加css样式
语法:
GET /hotel/_search { "query": { "match": { "FIELD": "TEXT" } }, "highlight": { "fields": { // 指定要高亮的字段 "FIELD": { "pre_tags": "<em>", // 用来标记高亮字段的前置标签 "post_tags": "</em>" // 用来标记高亮字段的后置标签 } } } }
搜索结果处理整体语法:
GET /hotel/_search { "query": { "match": { "name": "如家" } }, "from": 0, // 分页开始的位置 "size": 20, // 期望获取的文档总数 "sort": [ { "price": "asc" }, // 普通排序 { "_geo_distance" : { // 距离排序 "location" : "31.040699,121.618075", "order" : "asc", "unit" : "km" } } ], "highlight": { "fields": { // 高亮字段 "name": { "pre_tags": "<em>", // 用来标记高亮字段的前置标签 "post_tags": "</em>" // 用来标记高亮字段的后置标签 } } } }
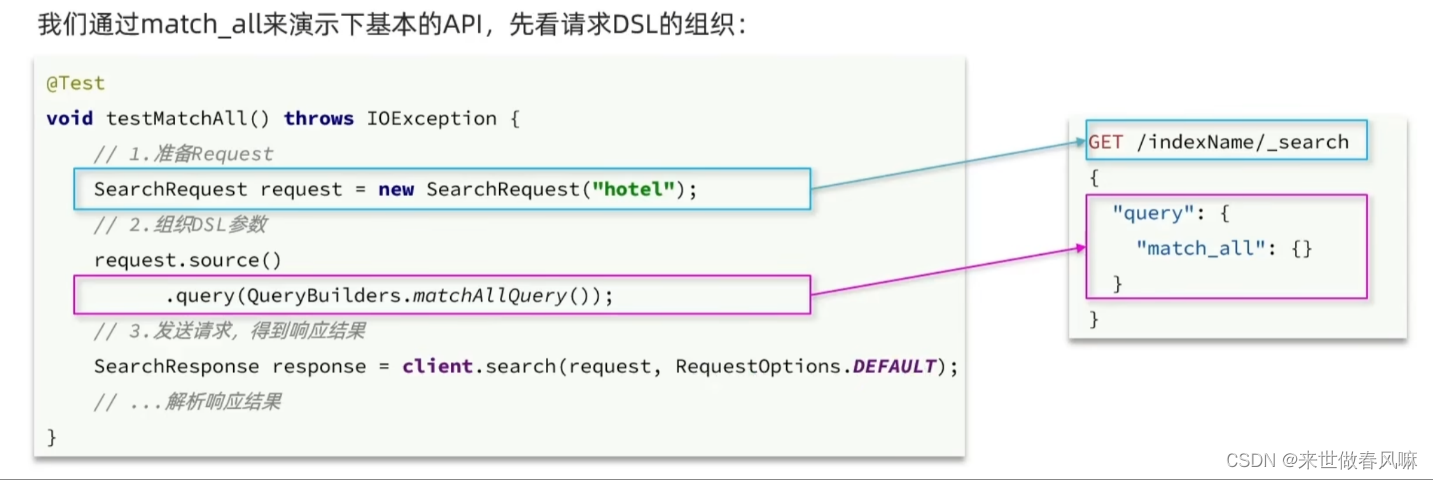
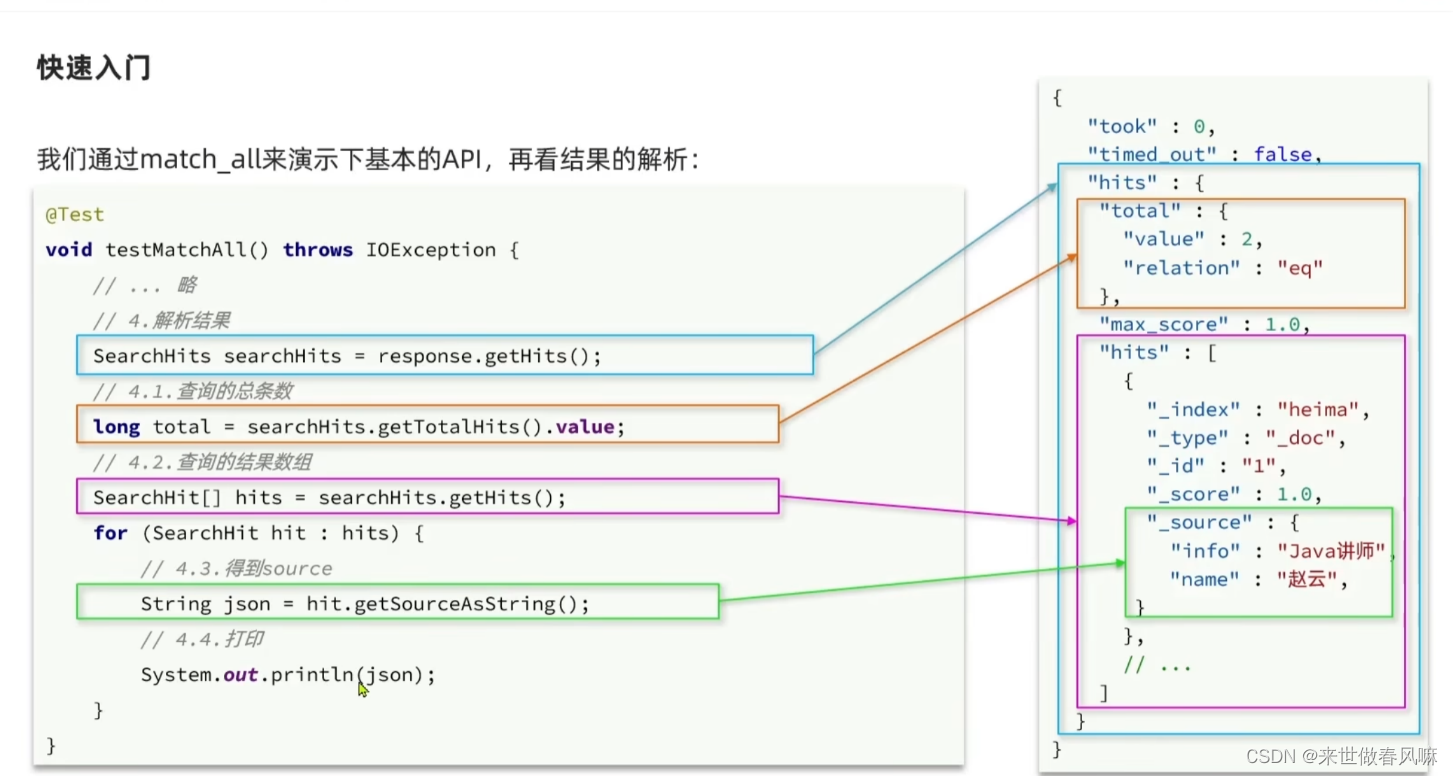
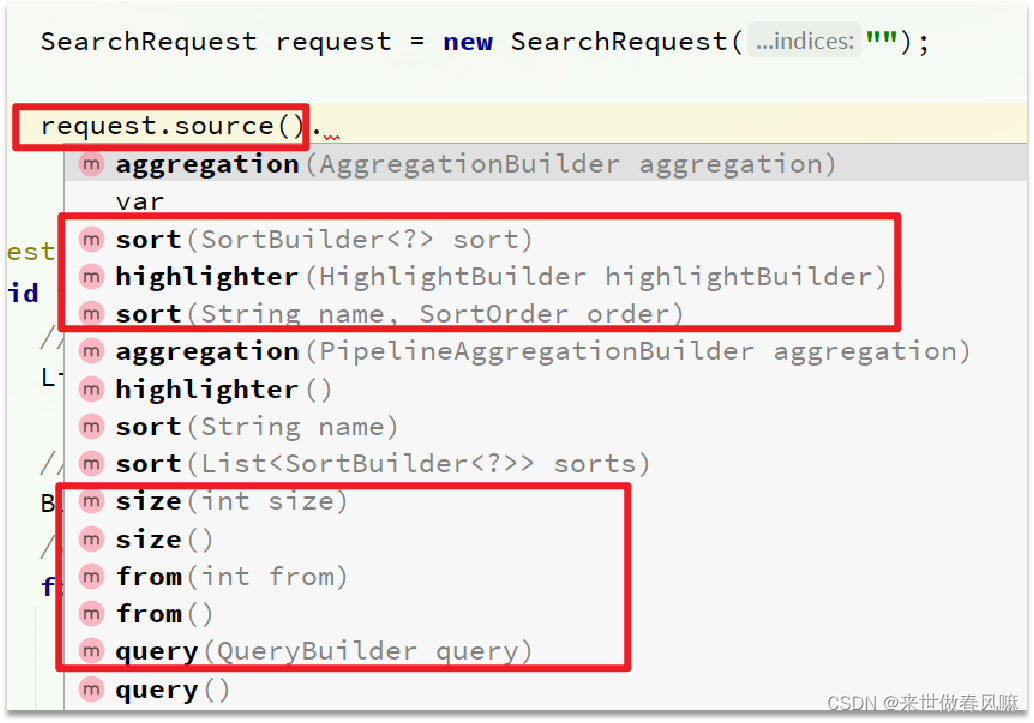
RestAPI中其中构建DSL是通过HighLevelRestClient中的resource()来实现的,其中包含了查询、排序、分页、高亮等所有功能:
RestAPI中其中构建查询条件的核心部分是由一个名为QueryBuilders的工具类提供的,其中包含了各种查询方法:
全文检索的match和multi_match查询与match_all的API基本一致。差别是查询条件,也就是query的部分。 同样是利用QueryBuilders提供的方法:
match查询 精确查询 复合查询 排序、分页、高亮
四、黑马旅游案例
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
只是想确保我理解了事情。据我目前收集到的信息,Cucumber只是一个“包装器”,或者是一种通过将事物分类为功能和步骤来组织测试的好方法,其中实际的单元测试处于步骤阶段。它允许您根据事物的工作方式组织您的测试。对吗? 最佳答案 有点。它是一种组织测试的方式,但不仅如此。它的行为就像最初的Rails集成测试一样,但更易于使用。这里最大的好处是您的session在整个Scenario中保持透明。关于Cucumber的另一件事是您(应该)从使用您的代码的浏览器或客户端的角度进行测试。如果您愿意,您可以使用步骤来构建对象和设置状态,但通常您
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
在Rails自动生成的功能测试(test/functional/products_controller_test.rb)中,我看到以下代码:classProductsControllerTest我的问题是:方法调用products()在哪里/如何定义?products(:one)到底是什么意思?看代码,大概意思是“创建一个产品”,但是它是如何工作的呢?注意我是Ruby/Rails的新手,如果这些是微不足道的问题,我深表歉意。 最佳答案 如果您查看test/fixtures文件夹,您会看到一个products.yml文件。这是在您创建
给定一个元素和一个数组,Ruby#index方法返回元素在数组中的位置。我使用二进制搜索实现了我自己的索引方法,期望我的方法会优于内置方法。令我惊讶的是,内置的在实验中的运行速度大约是我的三倍。有Rubyist知道原因吗? 最佳答案 内置#indexisnotabinarysearch,这只是一个简单的迭代搜索。但是,它是用C而不是Ruby实现的,因此自然可以快几个数量级。 关于Ruby#index方法VS二进制搜索,我们在StackOverflow上找到一个类似的问题:
在我的一些Controller中,我有一个before_filter检查用户是否登录?用于CRUD操作。application.rbdeflogged_in?unlesscurrent_userredirect_toroot_pathendendprivatedefcurrent_user_sessionreturn@current_user_sessionifdefined?(@current_user_session)@current_user_session=UserSession.findenddefcurrent_userreturn@current_userifdefine
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我有一个表,'jobs'和一个枚举字段'status'。status具有以下枚举集:enumstatus:[:draft,:active,:archived]使用ransack,我如何过滤表,比如说,所有事件记录? 最佳答案 你可以像这样在模型中声明自己的掠夺者:ransacker:status,formatter:proc{|v|statuses[v]}do|parent|parent.table[:status]end然后您可以使用默认的搜索语法_eq来检查相等性,如下所示:Model.ransack(status_eq:'ac