MySQL提供了多种字符集和排序规则选择,其中字符集设置和数据存储以及客户端与MySQL实例的交互相关,排序规则和字符串的对比规则相关
(1). 字符集的设置可以在MySQL实例、数据库、表、列四个级别
(2). MySQL设置字符集支持在InnoDB, MyISAM, Memory三个存储引擎
(3). 查看当前MySQL支持的字符集的方式有两种,一种是通过查看information_schema.character_set系统表,一种是通过命令【 show character set; 】查看。
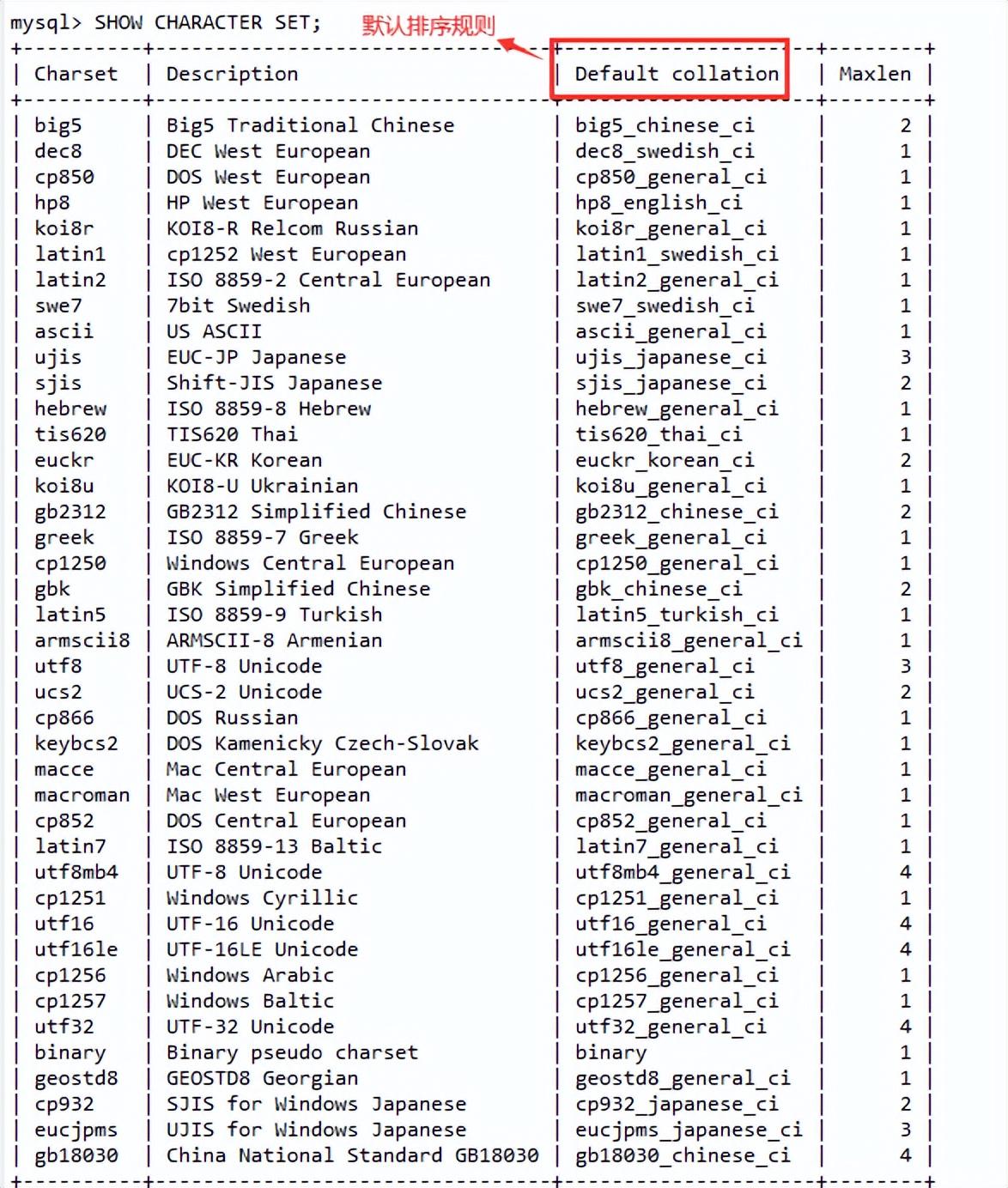
每个指定的字符集都会有一个或多个支持的排序规则,可以通过两种方式查看,一种是查看information_schema.collations表,另一种是通过【show collation】命令查看
(1). 查看utf8mb4字符集对应的排序规则有哪些。
show collation where charset ='utf8mb4';
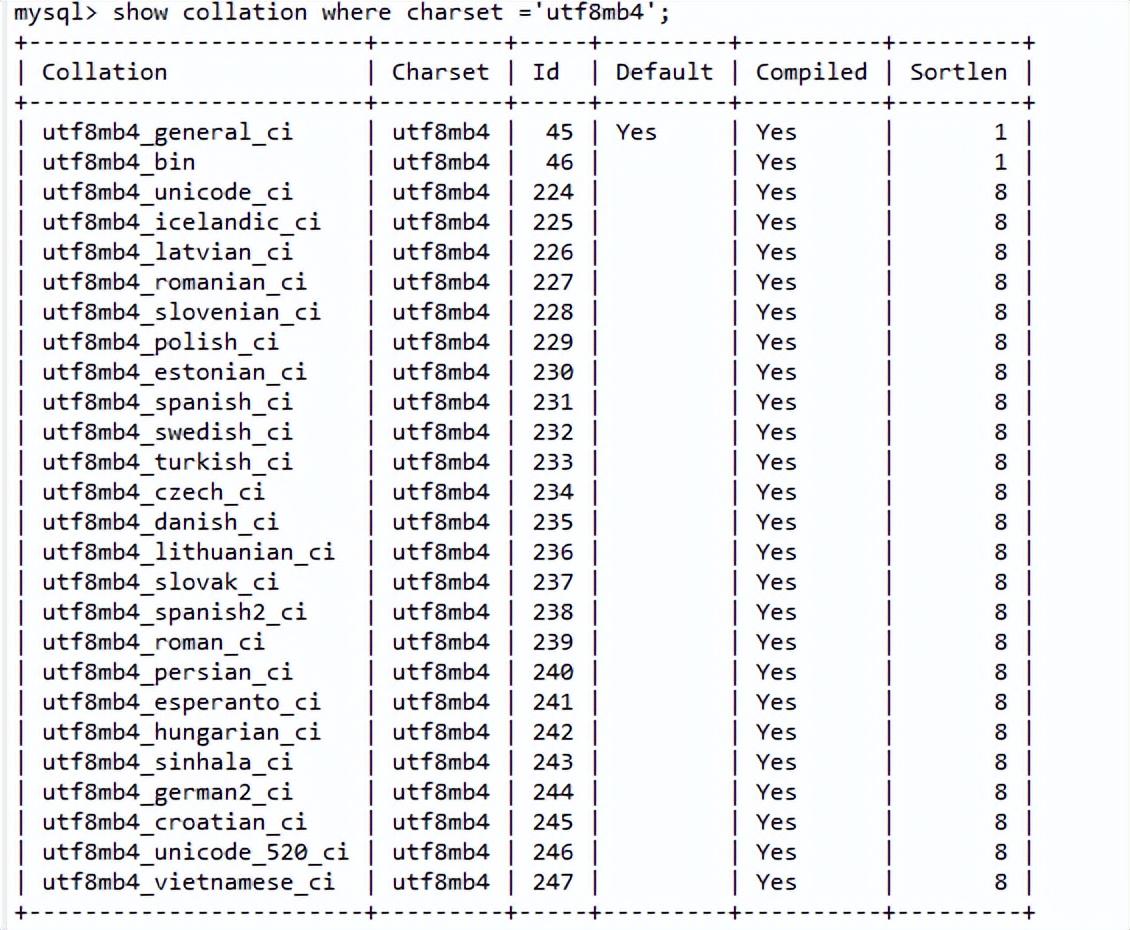
(2).剖析排序规则
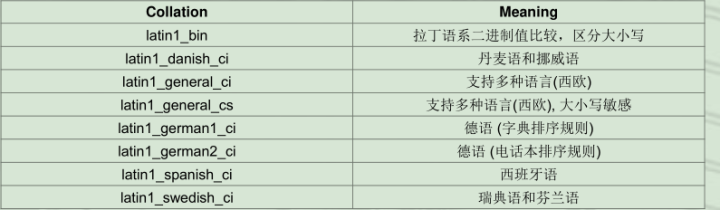
排序规则的命令通常是以对应的字符集的名字为开头,并以自己的特定属性结尾,比如排序规则utf8_general_ci和latin1_swedish_ci就分别是对应utf8和latin1字符集的排序规则
• 当排序规则特指某种语言时,则中间的部分就为这种语言的名字,比如utf8_turkish_ci和utf8_hungarian_ci就代表UTF8字符集中的土耳其语和匈牙利语
• 排序规则名字的结尾字符代表是否大小写敏感,重音敏感以及是否是二进制的

PS:
A. 当仅指定了字符集而没有指定排序规则时,则会使用该字符集的默认排序规则
B. 当仅指定了排序规则而没有字符集时,则在该排序规则名称上含有的字符集会被使用
C. 当数据库创建时没有指定这两项,则使用实例级别的字符集和排序规则
更多C++后台开发技术点知识内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,音视频开发,Linux内核,TCP/IP,协程,DPDK多个高级知识点。
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
【文章福利】另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以点击领取
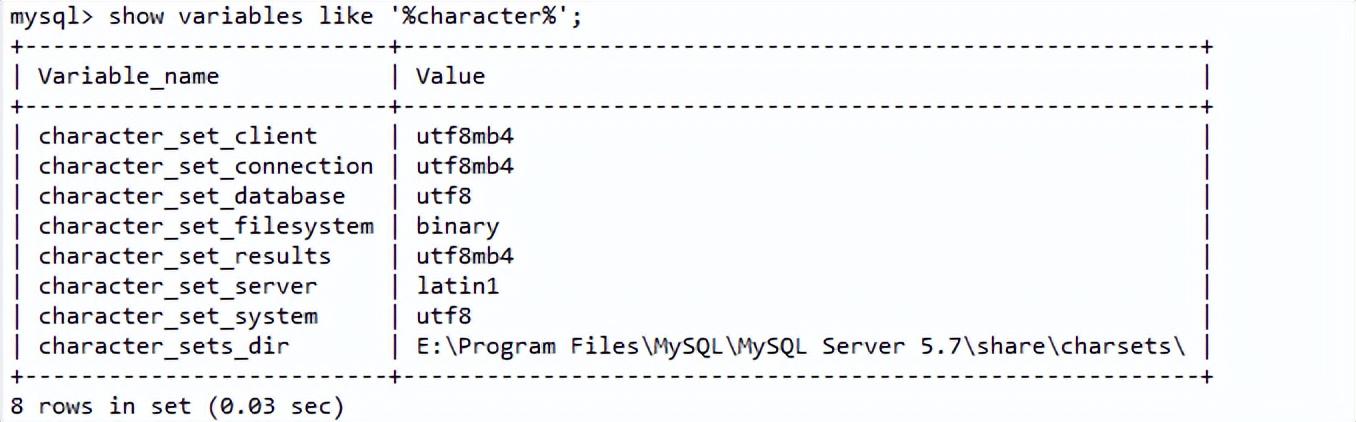
windows下mysql5.7默认编码如下图
show variables like '%character%';
PS:
(1). 每个数据库客户端连接都有自己的字符集和排序规则属性,客户端发送的语句的字符集是由character_set_client决定,而与服务端交互时会根据character_set_connection和collation_connection两个参数将接收到的语句转化。当涉及到显示字符串的比较时,由collation_connection参数决定,而当比较的是字段里的字符串时则根据字段本身的排序规则决定
(2). character_set_result 参数决定了语句的执行结果以什么字符集返回给客户端
(3). 客户端可以很方便的调整字符集和排序规则,比如使用SET NAMES'charset_name' [COLLATE 'collation_name']表明后续的语句都以该字符集格式传送给服务端,而执行结果也以此字符集格式返回。
SET character_set_client = utf8mb4; SET character_set_results = utf8mb4; SET character_set_connection = utf8mb4;
MySQL5.7以后,推荐使用utf8mb4编码来代替utf8编码。
无论window下还是linux下的mysql安装完成后首先要做的就是修改编码,下面蓝色部分是需要配置的。修改完成后,重启mysql服务,查看编码。
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
# 设置client连接mysql时的字符集,防止乱码
init_connect='SET NAMES utf8mb4'
init_connect='SET collation_connection = utf8mb4_general_ci'
# 数据库默认字符集
character-set-server=utf8mb4
#数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server=utf8mb4_general_ci
# 跳过mysql程序起动时的字符参数设置 ,使用服务器端字符集设置 (忽略即可)
#skip-character-set-client-handshake
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。但需要注意,如果开启该选项,则所有远程主机连接授权都要使用IP地址方式,否则MySQL将无法正常处理连接请求!(忽略即可)
#skip-name-resolve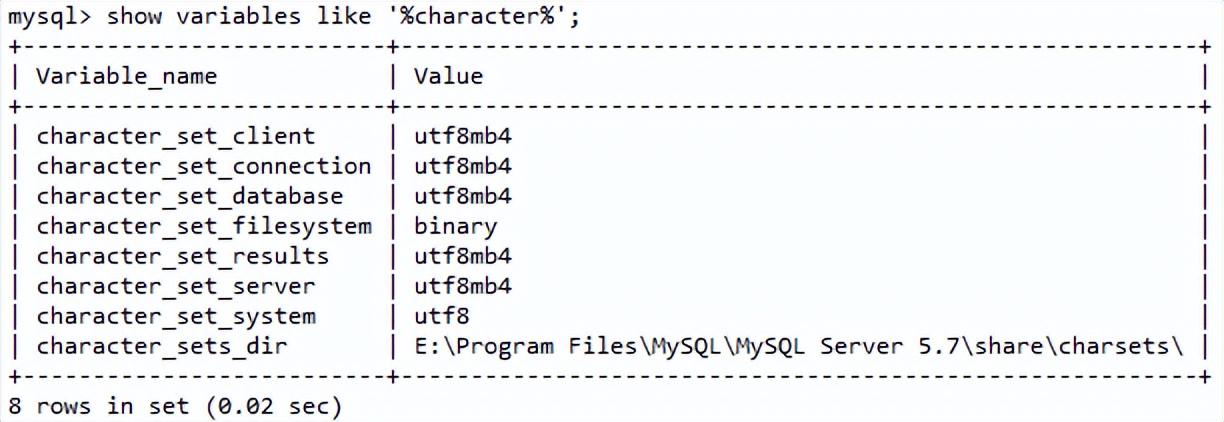
原文链接:第六节:MySQL字符集和排序规则详解 - Yaopengfei - 博客园
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
在我的Rails(2.3,Ruby1.8.7)应用程序中,我需要将字符串截断到一定长度。该字符串是unicode,在控制台中运行测试时,例如'א'.length,我意识到返回了双倍长度。我想要一个与编码无关的长度,以便对unicode字符串或latin1编码字符串进行相同的截断。我已经了解了Ruby的大部分unicode资料,但仍然有些一头雾水。应该如何解决这个问题? 最佳答案 Rails有一个返回多字节字符的mb_chars方法。试试unicode_string.mb_chars.slice(0,50)
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我试图获取一个长度在1到10之间的字符串,并输出将字符串分解为大小为1、2或3的连续子字符串的所有可能方式。例如:输入:123456将整数分割成单个字符,然后继续查找组合。该代码将返回以下所有数组。[1,2,3,4,5,6][12,3,4,5,6][1,23,4,5,6][1,2,34,5,6][1,2,3,45,6][1,2,3,4,56][12,34,5,6][12,3,45,6][12,3,4,56][1,23,45,6][1,2,34,56][1,23,4,56][12,34,56][123,4,5,6][1,234,5,6][1,2,345,6][1,2,3,456][123
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg