MyBatis-Plus 是基于 MyBatis 进行封装的一套优秀的持久层框架,它提供了丰富的便捷操作方法和强大的代码生成器,大大简化了 MyBatis 的使用。在 MyBatis-Plus 中,我们可以使用 insertBatchSomeColumn 方法来实现批量新增指定字段的操作。
mybatis-plus的 IService接口 默认提供 saveBatch批量插入,也是唯一一个默认批量插入,在数据量不是很大的情况下可以直接使用,但这种是一条一条执行的效率上会有一定的瓶颈,在这里先看下saveBatch的执行情况



可以看到sql语句是一条一条执行的,插入多少条数据就相当于执行了多少次的插入sql, 点进saveBatch方法,看看内部是怎么实现的

注意看,方法有一个事务注解,说明插入整批数据会作为一个事务进行,
默认1000条一次,怪不得执行时每隔1000条会处于一个准备执行状态,等待几秒后才会往下执行(这里等待的时间就是1000个单条的insert语句执行的时间)
再往下点是一个saveBatch接口,参数分别是插入的对象集合、插入批次数量也就是默认的1000
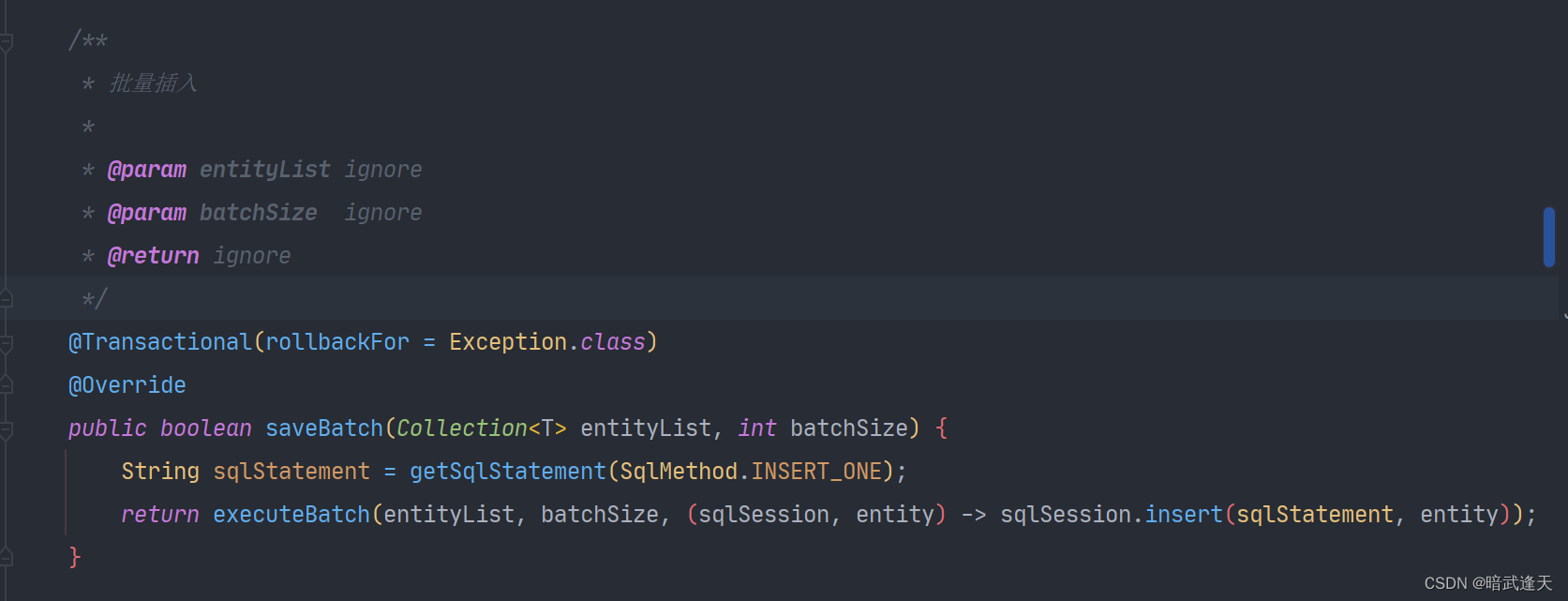
这里也有一个事务的注解,这是因为saveBatch是一个重载方法,插入的时候也可以指定插入批次数量调用
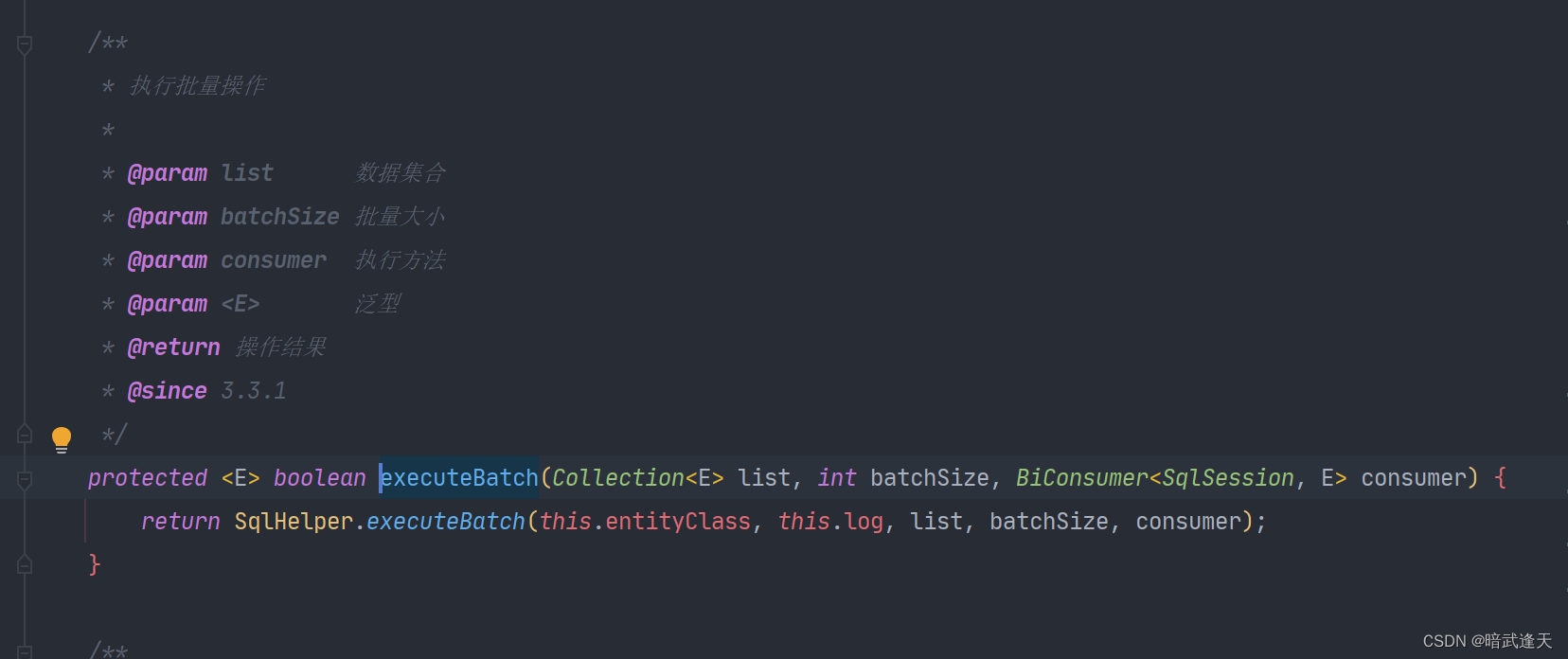
继续往下进入executeBatch
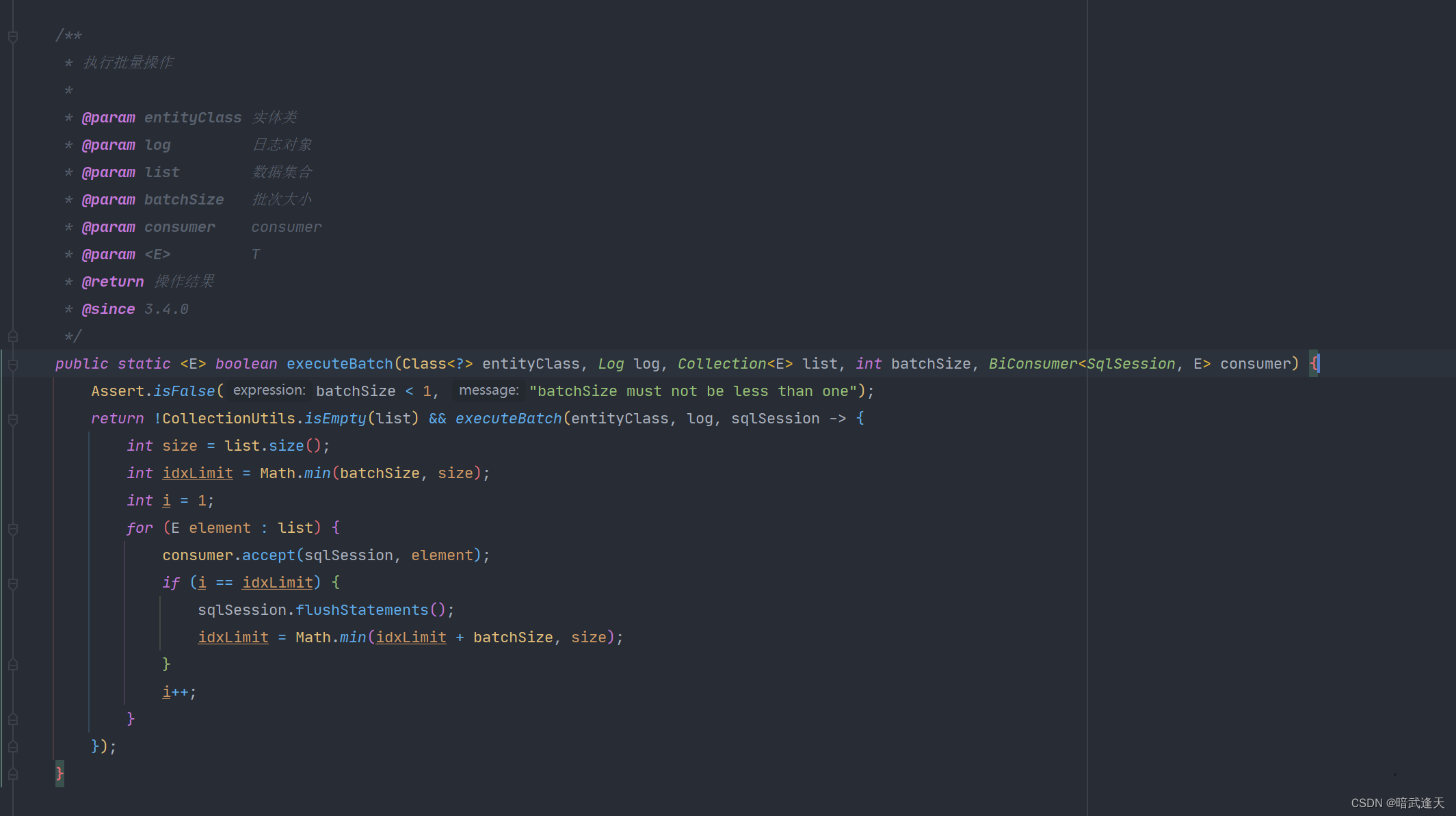
这里就是真正执行的方法了,idxLimit会对比DEFAULT_BATCH_SIZE和集合长度两个数中的最小数,作为批量大小,也就是说当集合长度不够1000,那么执行的时候批量大小就是集合的长度,就执行一次。
for循环中的consumer:对应的类型是一个函数式接口,代表一个接受两个输入参数且不返回任何内容的操作符。意思是给定两个参数sqlSession、循环中当前element对象,执行一次传递过来的consumer匿名函数。也就是上边源码里的插入匿名函数。
当i == indLimit时:执行一次预插入,并重新计算idxLimit的值
if中idxLimit计算规则:当前idxLimit加batchSize(默认1000) 和 集合长度 取最小值,计算出来的结果肯定不会超过集合的长度,最后的批次时idxLimit等于集合的长度,将这个值作为下一次执行预插入的时间点。
sqlSession.flushStatements():当有处于事务中的时候,起到一种预插入的作用,执行了这行代码之后,要插入的数据会锁定数据库的一行记录,并把数据库默认返回的主键赋值给插入的对象,这样就可以把该对象的主键赋值给其他需要的对象中去了,这里不是事务提交啊。
最后方法执行完后@Transactional注解会默认提交事务,如果调用的方法上还有@Transactional注解,默认的事务传播类型是Propagation.REQUIRED,不会新开启事务,如果没有@Transactional注解才会新开起事务
下面我们使用真正的批量新增方法insertBatchSomeColumn,看看两者的区别
批量新增指定字段是指在一次 SQL 语句中执行多条 INSERT 语句,但是只插入指定的字段。批量新增指定字段可以提高数据操作效率,减少数据库与应用程序之间的网络传输次数,减轻数据库服务器的压力,提高系统的并发性能。
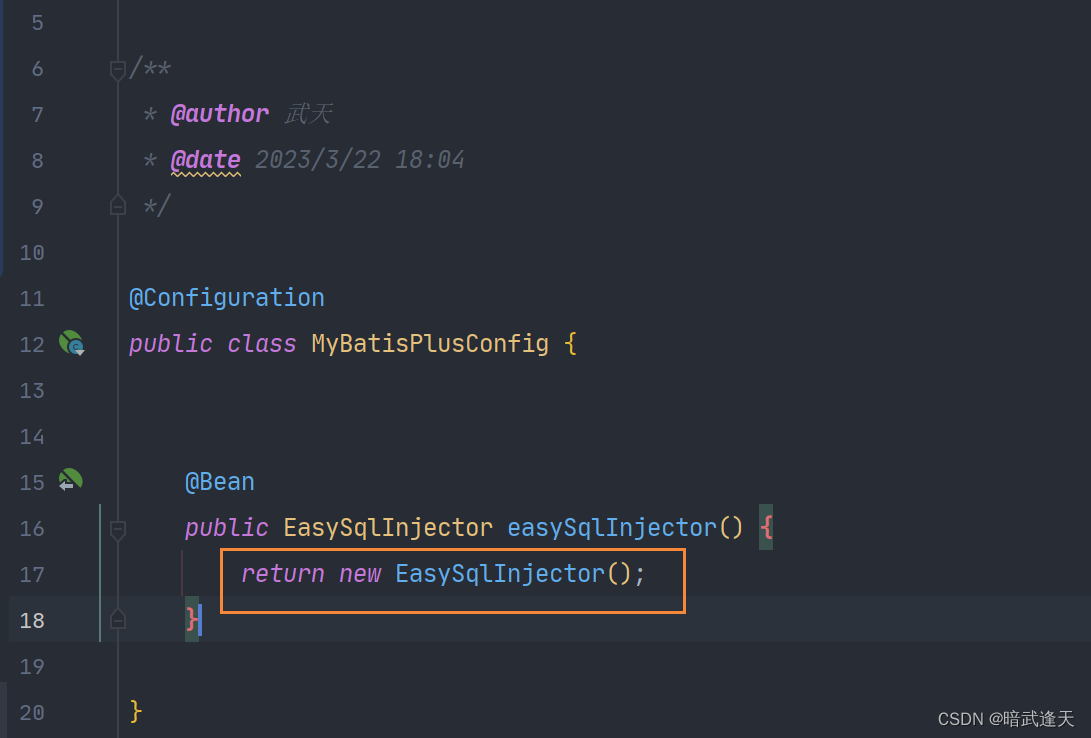
mybatis-plus提供了InsertBatchSomeColumn批量insert方法。通过SQL 自动注入器接口 ISqlInjector注入通用方法 SQL 语句 然后继承 BaseMapper 添加自定义方法,全局配置 sqlInjector 注入 MP 会自动将类所有方法注入到 mybatis 容器中。我们需要通过这种方式注入下。
/**
* 自定义Sql注入
*
*/
public class EasySqlInjector extends DefaultSqlInjector {
@Override
public List<AbstractMethod> getMethodList(Class<?> mapperClass, TableInfo tableInfo) {
// 注意:此SQL注入器继承了DefaultSqlInjector(默认注入器),调用了DefaultSqlInjector的getMethodList方法,保留了mybatis-plus的自带方法
List<AbstractMethod> methodList = super.getMethodList(mapperClass, tableInfo);
methodList.add(new InsertBatchSomeColumn(i -> i.getFieldFill() != FieldFill.UPDATE));
return methodList;
}
}
自定义EasyBaseMapper
/**
* @author 武天
* @date 2023/3/22 18:19
*/
public interface EasyBaseMapper<T> extends BaseMapper<T> {
/**
* 批量插入 仅适用于mysql
*
* @param entityList 实体列表
* @return 影响行数
*/
Integer insertBatchSomeColumn(Collection<T> entityList);
}/**
*
*
* @author wutian
* @email ${email}
* @date 2022-10-03 22:12:06
*/
@Mapper
public interface BreakDownCluesDao extends EasyBaseMapper<ExcelBreakdownClues> {
}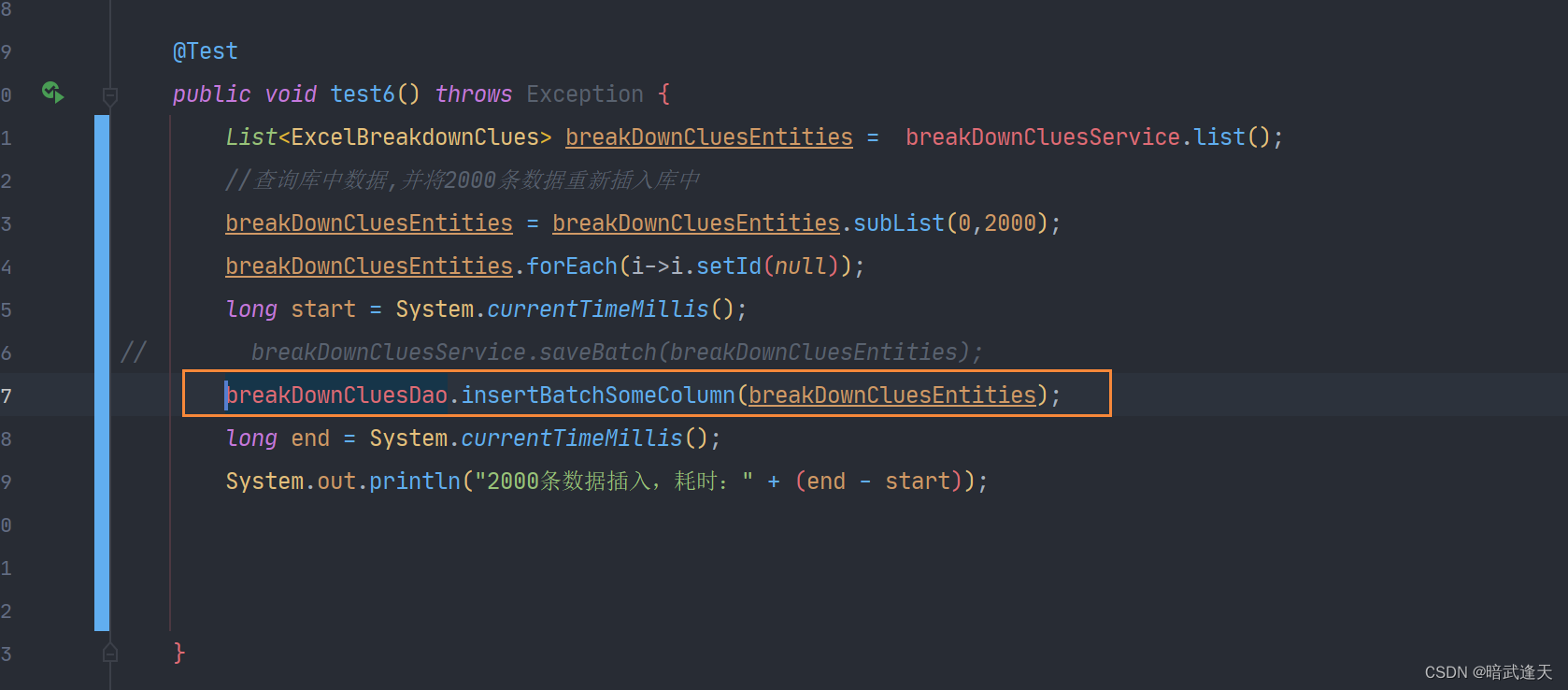

 可以看到明显的区别,sql只执行了一条,后面都是入参逗号相隔的形式,耗时也有所优化,这是插入数量不是很多的情况,如果是上万条或者上千万条数据,这种形式的优越性就体现出来了
可以看到明显的区别,sql只执行了一条,后面都是入参逗号相隔的形式,耗时也有所优化,这是插入数量不是很多的情况,如果是上万条或者上千万条数据,这种形式的优越性就体现出来了
在使用 MyBatis-Plus 进行批量新增指定字段时,需要注意以下几点:
我想使用Ruby检查数千对文件中的每对文件是否包含相同的信息。有人能指出我正确的方向吗? 最佳答案 require'fileutils'FileUtils.compare_file('file1','file2')当且仅当文件file1和file2相同时返回true。 关于ruby-如何批量检查文件内容是否相同,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/33769865/
假设你有这个结构:classHouse请注意,Tv的用户是故意不可访问的。所以你有一个三层嵌套的表单,允许你在一个页面上输入房子、房间和电视。这是Controller的创建方法:defcreate@house=House.new(params[:house])if@house.save#...standardstuffelse#...standardstuffendend问题:您究竟如何为每台电视填充user_id(它应该来自current_user.id)?什么是好的做法?这是我在其中看到的catch22。将user_ids直接填充到params散列中(它们嵌套得很深)保存将失败,因
我运行的是OSX,对视频转换一无所知。但我有大约200个视频都是mp4格式,无法在Firefox中播放。我需要将它们转换为ogg才能使用html5视频标签。这些文件位于一个文件夹结构中,这使得一次一个地处理一个文件变得困难。我希望bash命令或Ruby命令遍历所有子文件夹并找到所有.mp4并转换它们。我找到了一份关于如何使用Google执行此操作的引用资料:http://athmasagar.wordpress.com/2011/05/12/a-bash-script-to-convert-mp4-files-to-oggogv/#!/bin/bashforfin$(ls*mp4|se
一、解决痛点使用spring-kafka客户端,每次新增topic主题,都需要硬编码客户端并重新发布服务,操作麻烦耗时长。kafkaListener虽可以支持通配符消费topic,缺点是并发数需要手动改并且重启服务。对于业务逻辑相似场景,创建新主题动态监听可以用kafka-batch-starter组件二、组件能力1、新增topic名称为:auto.topic1(由于配置spring.kafka.consumer.prefix为auto,因此只有auto前缀的topic,才会被组件动态监听。)2、应用输出日志,监听到新增auto.topic1,并初始化客户端(主题刷新间隔为10s)3、发新的消
是否可以使用Sequel在一次调用中进行多次更新??例如,在我的服务器上进行大约200次更新可能需要几分钟,但如果我伪造一个SQL查询,它会在几秒钟内运行。我想知道Sequel是否可以用来伪造那个SQL查询,或者更好的是,自己完成整个操作。 最佳答案 我遇到的解决方案涉及update_sql方法。它不是自己执行操作,而是输出原始SQL查询。要批量更新多个更新,只需将它们与;连接起来即可。在此期间,使用结果字符串调用run方法,一切就绪。批处理解决方案比多次更新快得多。 关于sql-是否可
我有一个Rails应用,其用户模型包含一个admin属性。它使用attr_accessible锁定。我的模型如下所示:attr_accessible:name,:email,:other_email,:plant_id,:password,:password_confirmationattr_accessible:name,:email,:other_email,:plant_id,:password,:password_confirmation,:admin,:as=>:admin下面是我的用户Controller中的更新方法:defupdate@user=User.find(par
查看原文>>>基于”PLUS模型+“生态系统服务多情景模拟预测实践技术应用目录第一章、理论基础与软件讲解第二章、数据获取与制备第三章、土地利用格局模拟第四章、生态系统服务评估第五章、时空变化及驱动机制分析第六章、论文撰写技巧及案例分析基于ArcGISPro、Python、USLE、INVEST模型等多技术融合的生态系统服务构建生态安全格局基于生态系统服务(InVEST模型)的人类活动、重大工程生态成效评估、论文写作等具体应用基于ArcGISPro、R、INVEST等多技术融合下生态系统服务权衡与协同动态分析实践应用 本文从数据、方法、实践三方面对生态系统服务多情景预测进行讲解。内容涵盖多
我正在读取一个大小为10mb且包含一些ID的文件。我将它们读入ruby列表。我担心将来可能会导致内存问题,因为文件中的id数量可能会增加。有没有一种批量读取大文件的有效方法?谢谢 最佳答案 与LazyEnumerators和each_slice,您可以两全其美。中间切线不用担心,可以批量迭代多行。batch_size可以自由选择。header_lines=1batch_size=2000File.open("big_file")do|file|file.lazy.drop(header_lines).each_slice(batch
我一直在尝试编写一个基于ruby的文件重命名程序,作为我自己的编程练习(我知道linux下有rename,但我想学习Ruby,而rename在Mac中没有)。从下面的代码来看,问题是.include?方法总是返回false,即使我看到文件名包含这样的搜索模式。如果我注释掉include?检查,gsub()似乎根本不会生成新文件名(即文件名保持不变)。那么有人可以看看我做错了什么吗?提前致谢!这是预期的行为:假设当前文件夹下有三个文件:a1.jpg、a2.jpg、a3.jpgRuby脚本应该可以将其重命名为b1.jpg、b2.jpg、b3.jpg#!/Users/Antony/.rvm/
当我第一次实现用户模型时,我允许用户输入大写或小写的电子邮件作为他们的登录信息。问题是它是一个移动应用程序,有时会发生自动上限,因此用户无法通过身份验证。我已经更改了CREATE方法以首先将电子邮件小写。但是,这会导致现有帐户的人不一致那么如何添加一个迁移来批量更新用户表中的电子邮件字段以将其小写? 最佳答案 最有效的方法是避免使用Ruby迭代器,而是直接在SQL中执行。在正常的迁移文件中,您可以将此SQL用于MySQL:execute("UPDATEusersSETemail=LOWER(email)")