文章目录
上一篇文章中已经讲述了两种终止线程的方式,这里介绍第三种方式:
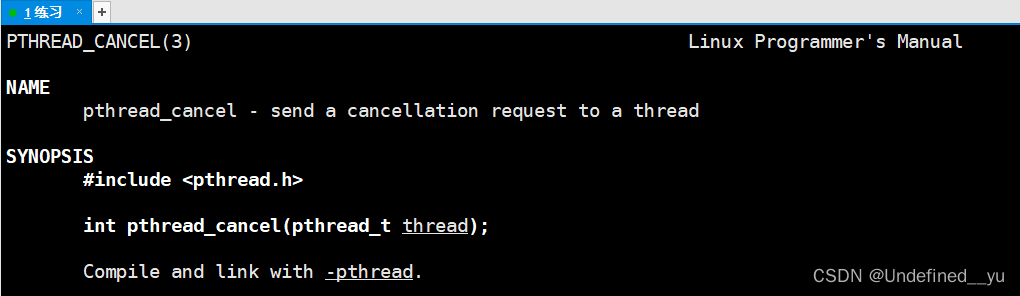
这里对上篇文章中的代码稍作修改:
#include <iostream>
#include <pthread.h>
#include <cassert>
#include <unistd.h>
#include <cstdio>
#include <vector>
using namespace std;
class ThreadData
{
public:
int number;
pthread_t tid;
char namebuffer[64];
};
//新线程
void *start_routine(void* args)
{
ThreadData* td=static_cast<ThreadData*>(args);
int cnt=3;
while(cnt)
{
cout<<"新线程running! name : "<<td->namebuffer<<"cnt : "<<cnt--<<endl;
sleep(1);
}
return (void*)td->number;
}
int main()
{
vector<ThreadData*> threads;
#define NUM 3
for(int i=0;i<NUM;i++)
{
ThreadData* td=new ThreadData();
snprintf(td->namebuffer,sizeof(td->namebuffer),"%s:%d","thread",i);
pthread_create(&td->tid,nullptr,start_routine,td);
td->number=i;
threads.push_back(td);
}
for(auto& iter:threads)
{
cout<<"create thread: "<<iter->namebuffer<<":"<<iter->tid<<"successfully!"<<endl;
}
sleep(3);
for(auto& iter:threads)
{
pthread_cancel(iter->tid);
cout<<"pthread_cancel: "<<iter->namebuffer<<"successfully!"<<endl;
}
for(auto& iter:threads)
{
void* ret=nullptr;
int n=pthread_join(iter->tid,&ret);
assert(n==0);
cout<<"join : "<<iter->namebuffer<<"successfully! exitcode:"<<(long long)ret<<endl;
delete iter;
}
cout<<"主线程退出!"<<endl;
return 0;
}
运行结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
新线程running! name : thread:0cnt : 新线程running! name : thread:1cnt : 33
新线程running! name : thread:2cnt : 3
create thread: thread:0:140206706472704successfully!
create thread: thread:1:140206698080000successfully!
create thread: thread:2:140206689687296successfully!
新线程running! name : thread:1cnt : 2
新线程running! name : thread:2cnt : 2
新线程running! name : thread:0cnt : 2
新线程running! name : thread:1cnt : 1
新线程running! name : 新线程running! name : thread:0cnt : 1
thread:2cnt : 1
pthread_cancel: thread:0successfully!
pthread_cancel: thread:1successfully!
pthread_cancel: thread:2successfully!
join : thread:0successfully! exitcode:-1
join : thread:1successfully! exitcode:-1
join : thread:2successfully! exitcode:-1
主线程退出!
根据记过可知,线程如果是被取消的,它的退出码是-1.
这里需要注意,线程可以被取消的前提是该线程已经运行起来了。
上一篇文章中以及这篇文章开头谈的都是Linux环境下的线程,下面先用C++的方式创建一个线程,代码如下:
#include <iostream>
#include <unistd.h>
#include <thread>
void thread_run()
{
std::cout<<"新线程running..."<<std::endl;
sleep(1);
}
int main()
{
std::thread t1(thread_run);
while(true)
{
std::cout<<"主线程running..."<<std::endl;
sleep(1);
}
t1.join();
return 0;
}
接下来将Makefile中内容作如下修改:
mythread:mythread.cpp
g++ -o $@ $^ -std=c++11
.PHONY:clean
clean:
rm -f mythread
将代码保存后,再运行,结果会报错,因为Makefile中并没有指定使用的线程库。当加上线程库之后就可以正常运行。
这说明,C++11中的多线程在Linux环境下,本质是对pthread的封装。
上一篇文章中说到使用pthread_join等待线程,本质上是阻塞式的等待,如果不等待线程就不能获取线程退出时的信息,也很有可能造成类似于僵尸进程的结果。
那如果我们现在不希望主线程一直等待新线程,又不想造成像僵尸进程这样的结果呢?
为解决这个问题,就要使用线程分离了。
- 默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄漏。
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线
程资源。
分离线程首先需要了解一个函数接口为pthread_self:
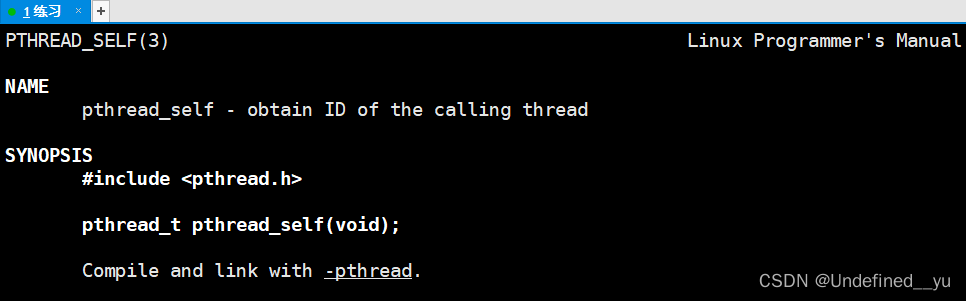
实例代码如下:
#include <iostream>
#include <pthread.h>
#include <string>
#include <unistd.h>
#include <cstdio>
std::string change_id(const pthread_t& thread_id)
{
char tid[128];
snprintf(tid,sizeof(tid),"0x%x",thread_id);
return tid;
}
void* start_routine(void* args)
{
std::string threadname=static_cast<const char*>(args);
while(true)
{
std::cout<<threadname<<"running..."<<change_id(pthread_self())<<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
//创建新线程,并让其执行start_routine函数
pthread_create(&tid,nullptr,start_routine,(void*)"线程1");
std::cout<<"主线程running... 新线程id:"<<change_id(tid)<<std::endl;
pthread_join(tid,nullptr);
return 0;
}
对应的Makefile内容如下:
mythread:mythread.cc
g++ -o $@ $^ -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f mythread
运行结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
主线程running... 新线程id:0xefdf5700线程1running...0xefdf5700
线程1running...0xefdf5700
线程1running...0xefdf5700
可以看到获取到的线程id是一样的
也可以将主线程的id输出出来,看二者是否相同,这需要将上述代码稍作改动:
int main()
{
pthread_t tid;
//创建新线程,并让其执行start_routine函数
pthread_create(&tid,nullptr,start_routine,(void*)"线程1");
std::cout<<"主线程id: "<<change_id(pthread_self())<<std::endl;
std::cout<<"主线程running... 新线程id:"<<change_id(tid)<<std::endl;
pthread_join(tid,nullptr);
return 0;
}
结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
主线程id: 线程10xd076b740running...0xcf6d7700
主线程running... 新线程id:0xcf6d7700
线程1running...0xcf6d7700
线程1running...0xcf6d7700
很明显二者id不同,以上就是pthread_self的用法。
随后,来介绍线程分离应该用到的函数接口:pthread_detach:
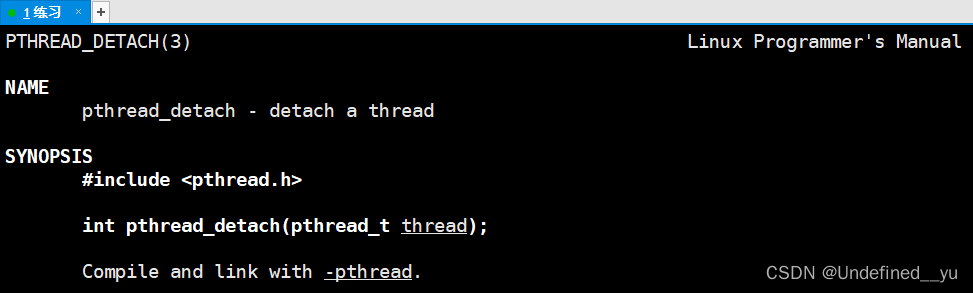
实例代码如下(对上文中的代码修改两个函数中的内容):
void* start_routine(void* args)
{
std::string threadname=static_cast<const char*>(args);
pthread_detach(pthread_self());//设置自己为分离状态
int cnt=3;
while(cnt--)
{
std::cout<<threadname<<"running..."<<change_id(pthread_self())<<std::endl;
sleep(1);
}
}
int main()
{
pthread_t tid;
//创建新线程,并让其执行start_routine函数
pthread_create(&tid,nullptr,start_routine,(void*)"线程1");
std::cout<<"主线程running... 新线程id:"<<change_id(tid)<<std::endl;
//通过观察等待结果验证“一个线程默认是joinable的线程分离后就不能继续等待了”
sleep(2);//让主线程sleep两秒已确保新线程已经分离
int n=pthread_join(tid,nullptr);
std::cout<<"线程等待结果:"<<n<<":"<<strerror(n)<<std::endl;
return 0;
}
结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
主线程running... 新线程id:0x3a42f700线程1running...0x3a42f700
线程1running...0x3a42f700
线程等待结果:22:Invalid argument
最终等待失败,“线程分离之后就不能进行等待了”验证成功!
这里再补充一点,使用pthread_detach分离线程时,最好让主线程来完成这个工作。
以上就是线程分离的操作。
在上一篇文章中还有一个未解决的问题,就是最终输出的线程id到底有什么含义?
以及之前说过的每一个线程都应该有自己独立的上下文结构、栈结构等等,那么又该怎么理解呢?
先来回顾一下之前解释过的原生的线程库中,可能同时存在多个线程,也可能有多个用户同时使用线程接口创建多个线程,所以我们需要将多个线程管理起来。虽然线程的属性较少,但同样需要管理。
而pthread原生线程库中会为每一个线程创建结构体来存放它们的属性,这些线程叫做用户级线程,由内核提供线程执行流的调度,Linux用户级线程:内核级轻量进程为1:1
那么用户级线程究竟是什么?
首先需要知道,我们一直在说的pthread线程库实际上就是一个磁盘文件,当某一进程需要创建新的线程的时候就将其加载到内存中使用,它被加载到内存中的位置叫做共享区。
而进程地址空间中有一个叫做mmap的区域,这个区域经过页表映射之后就能找到具体的物理内存中,线程库对应的位置。然后可以在其中为每一个线程创建自己的结构体、栈结构等等。如图:
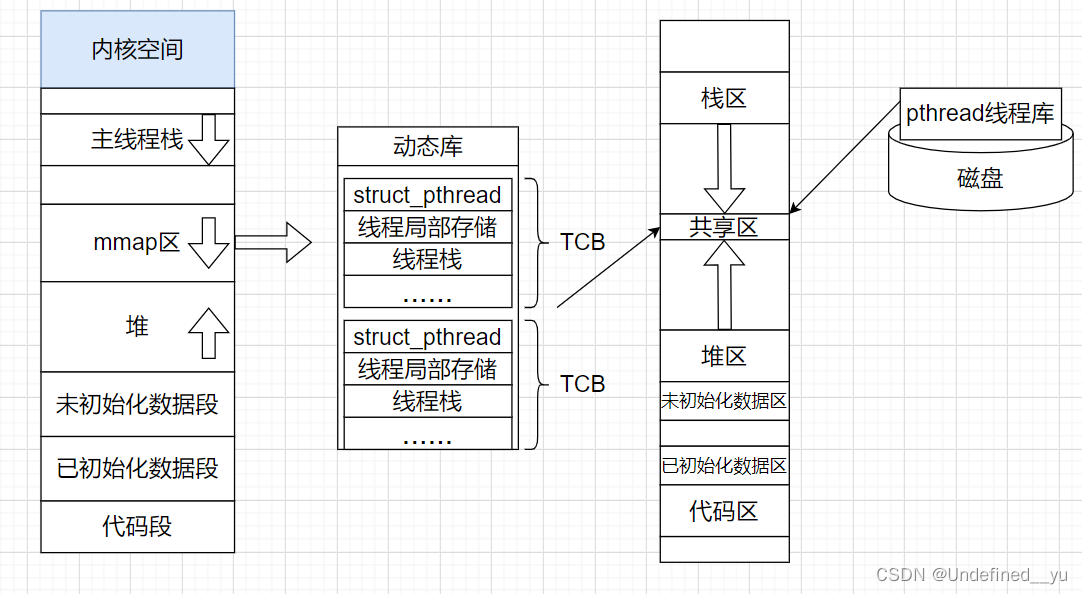
而所谓线程的id就是每一个TCB的起始位置,线程的独立站结构就是原生线程库中为每一个线程提供的线程栈。
再对线程局部存储做一个解释:
根据之前的解释,定义在全局的变量是一个进程中所有执行流的共享资源,即任意一个执行流对其进行修改,其他的所有执行流都可以看到,例如下面代码中的全局变量g_val:
int g_val=10;
std::string change_id(const pthread_t& thread_id)
{
char tid[128];
snprintf(tid,sizeof(tid),"0x%x",thread_id);
return tid;
}
void* start_routine(void* args)
{
std::string threadname=static_cast<const char*>(args);
while(true)
{
std::cout<<threadname<<"running..."<<"g_val:"<<g_val<<" &g_val:"<<&g_val<<std::endl;
g_val++;
sleep(1);
}
}
int main()
{
pthread_t tid;
pthread_create(&tid,nullptr,start_routine,(void*)"新线程");
while(true)
{
std::cout<<"主线程running... "<<"g_val:"<<g_val<<" &g_val:"<<&g_val<<std::endl;
sleep(1);
}
return 0;
}
执行结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
主线程running... g_val:10 &g_val:0x6020c4
新线程running...g_val:10 &g_val:0x6020c4
主线程running... g_val:11 &g_val:0x6020c4
新线程running...g_val:11 &g_val:0x6020c4
主线程running... g_val:12 &g_val:0x6020c4
新线程running...g_val:12 &g_val:0x6020c4
主线程running... g_val:13 &g_val:0x6020c4
新线程running...g_val:13 &g_val:0x6020c4
可以看到,新线程每一次修改全局变量,主线程都能看到,并且两个线程拿到的全局变量的地址都是一样的。
接下来在g_val前加一个__thread,如下:
__thread int g_val=10;
再次运行,结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
主线程running... g_val:10 &g_val:0x7fc6fd57a77c
新线程running...g_val:10 &g_val:0x7fc6fc4e66fc
主线程running... g_val:10 &g_val:0x7fc6fd57a77c
新线程running...g_val:11 &g_val:0x7fc6fc4e66fc
新线程running...主线程running... g_val:g_val:1012 &g_val: &g_val:0x7fc6fd57a77c0x7fc6fc4e66fc
主线程running... g_val:0xa &g_val:0x7fc6fd57a77c
新线程running...g_val:0xd &g_val:0x7fc6fc4e66fc
主线程running... g_val:0xa&g_val:0x7fc6fd57a77c
很明显的可以看到,这次新线程不停地修改全局变量的值,但主线程却看不到了,而且两个线程拿到的全局变量的地址都是不一样的。
所以,__thread可以将内置类型变为线程局部存储。
所谓的封装,就是将一些接口融合进一个类中,下次想要使用这些接口的功能时,直接调用类对象的成员函数即可,封装后的代码如下:
#pragma once
#include <iostream>
#include <string>
#include <functional>
#include <pthread.h>
#include <cassert>
class Thread;
class Context
{
public:
Thread* this_;
void* args_;
public:
Context()
:this_(nullptr)
,args_(nullptr)
{}
~Context()
{}
};
class Thread
{
typedef std::function<void*(void*)> func_t;
const int num=1024;
public:
Thread(func_t func,void* args,int number)
:func_(func)
,args_(args)
{
char buffer[num];
snprintf(buffer,sizeof buffer,"thread-%d",number);
name_=buffer;
Context* ctx=new Context();
ctx->this_=this;
ctx->args_=args_;
int n=pthread_create(&tid_,nullptr,start_routine,ctx);
assert(n==0);
(void)n;//主要是告诉编译器这个变量已经被使用了,因为assert在release下是失效的
}
//start直接使用func_会报错,该函数为辅助函数
//在类捏创建线程,要让线程执行对应的方法,需要将其设置为static
static void* start_routine(void* args) //有缺省参数this
{//静态成员不能调用成员变量和成员方法
Context* ctx=static_cast<Context*>(args);
void* ret=ctx->this_->run(ctx->args_);
delete ctx;
return ret;
}
void join()
{
int n=pthread_join(tid_,nullptr);
assert(n==0);
(void)n;
}
void* run(void* args)
{
func_(args);
}
~Thread()
{
//nothing
}
private:
std::string name_;
pthread_t tid_;
func_t func_;
void* args_;
};
接下来用上面封装后的类创建三个线程看看效果:
#include <iostream>
#include <pthread.h>
#include <string>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <memory>
#include "thread.hpp"
void* thread_run(void* args)
{
std::string work_type=static_cast<const char*>(args);
while(true)
{
std::cout<<"新线程 "<<work_type<<"ing"<<std::endl;
sleep(1);
}
}
int main()
{
std::unique_ptr<Thread> thread1(new Thread(thread_run,(void*)"mul",0));
std::unique_ptr<Thread> thread2(new Thread(thread_run,(void*)"add",1));
std::unique_ptr<Thread> thread3(new Thread(thread_run,(void*)"sub",2));
thread1->join();
thread2->join();
thread3->join();
return 0;
}
分别让三个线程执行按死不同的动作,结果如下:
[sny@VM-8-12-centos threaddone]$ ./mythread
新线程 muling新线程 adding
新线程 subing
新线程 adding
新线程 subing
新线程 muling
在以后创建线程时,也可以直接使用这个封装之后的类,会方便很多。
本篇完,青山不改,绿水长流!
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐
我正在尝试使用ruby编写一个双线程客户端,一个线程从套接字读取数据并将其打印出来,另一个线程读取本地数据并将其发送到远程服务器。我发现的问题是Ruby似乎无法捕获线程内的错误,这是一个示例:#!/usr/bin/rubyThread.new{loop{$stdout.puts"hi"abc.putsefsleep1}}loop{sleep1}显然,如果我在线程外键入abc.putsef,代码将永远不会运行,因为Ruby将报告“undefinedvariableabc”。但是,如果它在一个线程内,则没有错误报告。我的问题是,如何让Ruby捕获这样的错误?或者至少,报告线程中的错误?
我是ruby的新手,我认为重新构建一个我用C#编写的简单聊天程序是个好主意。我正在使用Ruby2.0.0MRI(Matz的Ruby实现)。问题是我想在服务器运行时为简单的服务器命令提供I/O。这是从示例中获取的服务器。我添加了使用gets()获取输入的命令方法。我希望此方法在后台作为线程运行,但该线程正在阻塞另一个线程。require'socket'#Getsocketsfromstdlibserver=TCPServer.open(2000)#Sockettolistenonport2000defcommandsx=1whilex==1exitProgram=gets.chomp
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
我有一个使用PDFKit呈现网页的pdf版本的Rails应用程序。我使用Thin作为开发服务器。问题是当我处于开发模式时。当我使用“bundleexecrailss”启动我的服务器并尝试呈现任何PDF时,整个过程会陷入僵局,因为当您呈现PDF时,会向服务器请求一些额外的资源,如图像和css,看起来只有一个线程.如何配置Rails开发服务器以运行多个工作线程?非常感谢。 最佳答案 我找到的最简单的解决方案是unicorn.geminstallunicorn创建一个unicorn.conf:worker_processes3然后使用它:
我在我的rails应用程序中安装了来自github.com的acts_as_versioned插件,但有一段代码我不完全理解,我希望有人能帮我解决这个问题class_eval我知道block内的方法(或任何它是什么)被定义为类内的实例方法,但我在插件的任何地方都找不到定义为常量的CLASS_METHODS,而且我也不确定是什么here,并且有问题的代码从lib/acts_as_versioned.rb的第199行开始。如果有人愿意告诉我这里的内幕,我将不胜感激。谢谢-C 最佳答案 这是一个异端。http://en.wikipedia
所以,Ruby1.9.1现在是declaredstable.Rails应该与它一起工作,并且正在慢慢地将gem移植到它。它具有native线程和全局解释器锁(GIL)。自从GIL到位后,原生线程是否比1.9.1中的绿色线程有任何优势? 最佳答案 1.9中的线程是原生的,但它们被“放慢了速度”,一次只允许一个线程运行。这是因为如果线程真的并行运行,它会混淆现有代码。优点:IO现在在线程中是异步的。如果一个线程阻塞在IO上,那么另一个线程将继续执行直到IO完成。C扩展可以使用真正的线程。缺点:任何非线程安全的C扩展都可能存在使用Thre