🌲“种一棵树最好的时间是十年前,其次是现在”
目录
HTML: 描述网页的骨架。标签化的语言。
<html>
<head></head>
<body>hello world</body>
</html>
html 的执行是浏览器的工作,浏览器会解析 html 的内容,根据里面的内容往浏览器放东西。浏览器的工作归根结底还是以汇编的形式在 CPU 上执行。
浏览器就像 JVM 一样, Java 是执行在 JVM 上的,JVM 又是执行在 CPU上的
浏览器对于 html 的语法格式检查没有很严格,即使你写的代码有一些不合规范之处,浏览器也会尽可能的去执行。称为"鲁棒性"。
直接在记事本编写代码,直接在浏览器运行代码。
浏览器的功能就是解析运行网页(HTML, CSS, JS)
开发,是在程序员的电脑上完成的写代码的过程;运行,则是在用户电脑上完成的具体的程序跑起来的过程。
一次开发,N 次运行。
1.打开目录,
2.创建代码文件
3.编辑代码
写完代码要 ctrl + s 保存。如果没保存,右上角有个 实心小圆点
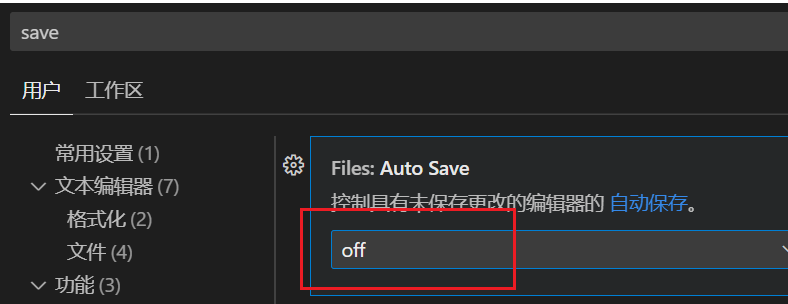

这里 off 可以改成自动保存。
4.运行代码(仍然是使用浏览器运行)
在弹出的文件资源管理器中 双击 html 或 拖拽到浏览器中运行
1.HTML 代码是通过标签来组织的,形如 用尖括号组织的,成对出现的这个就是标签(tag),也可以叫做元素(element).
2.一个标签通常是成对出现的,开始标签结束标签,这俩之间是标签的内容。(少数标签是可以只有一个开始标签的,单标签)
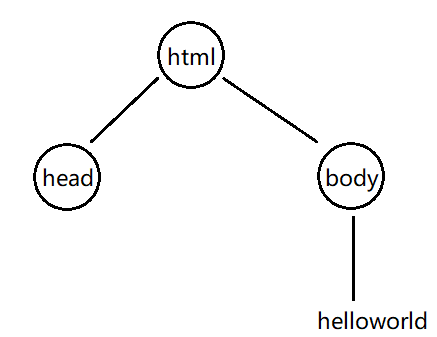
3.标签是可以嵌套的,一个标签的内容可以是其他一个或者多个标签,此时这些标签构成了一个"树形结构"。
4.可以在开始标签中给标签赋予属性(attribute),属性相当于键值对,可以有一个或者多个。
XML 和 HTML 的区别:
XML 也是标签化的格式,有哪些标签,标签叫什么名字?有啥作用?有啥属性。都是程序员你根据你的需求场景自定义的。
HTML 也是标签化的格式,这里有哪些标签?标签叫啥名字?有啥作用?有啥属性?都是有一批大佬们规定好的,浏览器跟按照这份规定来解析实现的。HTML 不支持自定义标签
html:这是一个 html 文件最顶层标签(树根节点)。
head :存放了这个页面的一些属性(元数据meta data)
body :存放了这个页面,包含哪些内容。
现在我有个文本文件,这个文件的内容是 hello world
这个文件的属性:文件的大小、文件的创建者、文件的修改时间、文件的默认打开程序
!(英文) + tab, 此时能自动生成代码的主体框架.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
</body>
</html>
只需要编辑 body 的内容即可。
这个功能叫做 emmet 快捷键。
主流开发工具都有。(WebStorm 和 idea 也有)

<!-- 这是注释 -->
// /**/ # 这些都不是 html中合法的注释
注释的内容是不会在页面中显示的。(但是如果右键,查看网页源代码是可以看到注释的)
vscode 可以使用 ctrl + / 快速注释代码
webstorm 同理
h1 最大最粗,h6 最小最细。
<body>
<h1>一级标题</h1>
<h2>二级标题</h2>
<h3>三级标题</h3>
<h4>四级标题</h4>
<h5>五级标题</h5>
<h6>六级标题</h6>
</body>

HTML 网页最初只是用来代替传统的媒体的报纸/杂志,把报纸杂志搬到电脑里
注意到,这里每个标题都是独占一行的,这和代码的编写没有关系,
<body>
<h1>一级标题</h1><h2>二级标题</h2>
<h3>三级标题</h3>
<h4>四级标题</h4>
<h5>五级标题</h5>
<h6>六级标题</h6>
</body>
这样写,运行效果不变。
在 html 里面,标签是否换行和代码编写无关,和 标签自身有关。(有的标签独占一行,有的标签不独占)
在 html 源代码中,写的 换行会被忽略。写的多个连续空格会被视为一个。
换行快捷键:
ctrl + enter
lorem:自动生成一段随机的文本,帮我们调试效果。

每个段落之间,要换行,还有一个明显的段落间距。(这个 间距 通过 css 才能调)


<body>
<strong>变粗!</strong>
<b>变粗!</b>
<em>倾斜</em>
<i>倾斜</i>
<del>删除线</del>
<s>删除线</s>
<ins>下划线</ins>
<u>下划线</u>
</body>

这些标签都是不独占一行的。
网页上是可以显示图片的。
img 有个核心属性,src(必填项)
src 描述了该图片的路径,路径可以是一个本地的绝对路径,也可以是一个相对路径,还可以是网络路径。
绝对路径写法:
<body>
<img src="d:/xiaojiejie.jpg" >
</body>

这里 src 填的是 绝对路径。
如果填相对路径,一定要明确工作目录是哪个。
html 的工作目录就是 html 文件所在的目录。
相对路径写法:
<body>
<img src="./xiaojiejie.jpg" >
</body>
./可以省略
<body>
<img src="xiaojiejie.jpg" >
</body>
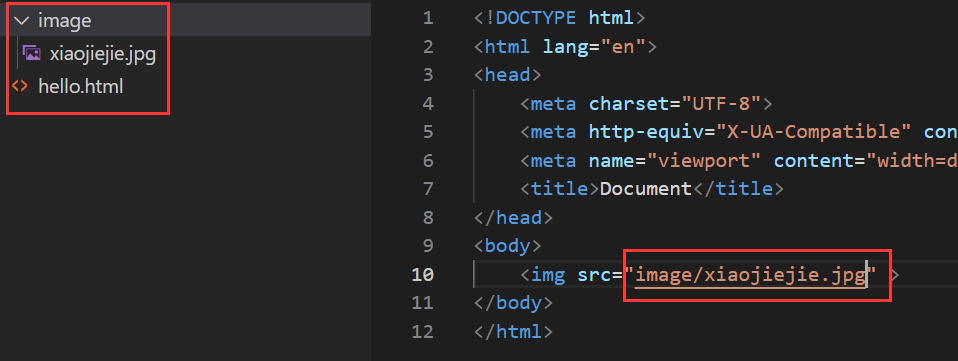
右键图片,复制图片地址,此时就得到了图片的网络路径,拿着这个网络路径填写到浏览器里,就能直接打开图片。
或者把这个路径写到 img 里也能显示这个图片。
<body>
<img src="https://img02.sogoucdn.com/app/a/100520093/f9d5c084396d06f6-0c7006bf1d0bb8d5-44cfb308fd53675f90401be304dc572d.jpg" >
</body>
img 别的属性
如果图片地址是错的,
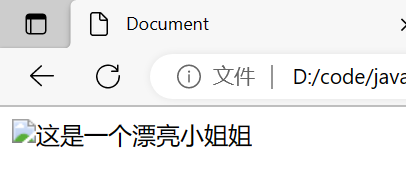
鼠标悬停在 图片上会给出一个提示。
描述图片的尺寸
宽度和高度可以同时设置,也可以只设置一个。如果只设置一个,另外一个会等比例缩放。
<body>
<img width="1000px" title="这是一个小姐姐" alt="这是一个漂亮小姐姐" src="https://img02.sogoucdn.com/app/a/100520093/f9d5c084396d06f6-0c7006bf1d0bb8d5-44cfb308fd53675f90401be304dc572d.jpg" >
</body>
px 像素。(前端开发中常用单位)
关于图片的尺寸,也可以使用 css 来设置。
链接 link(快捷方式)
"超"链接跳转到的页面是当前网站之外的。
<body>
<a href="https://www.sogou.com">搜狗</a>
<a href="https://www.baidu.com">百度</a>
</body>
这里的域名可以换成 ip 地址
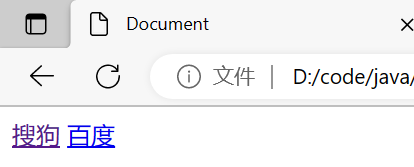
还有个属性,target, 一般都是写作 target = “_blank”,就可以打开一个新的标签页,而不是替换原有标签页。
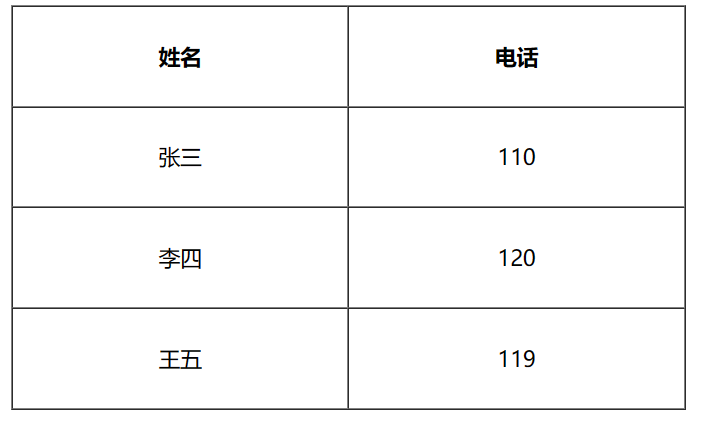
table 标签表示整个表格
tr 表示一行
td 表示一个单元格
th 表示表头中的一个单元格
<body>
<table>
<tr>
<th>姓名</th>
<th>电话</th>
</tr>
<tr>
<td>张三</td>
<td>110</td>
</tr>
<tr>
<td>李四</td>
<td>120</td>
</tr>
<tr>
<td>王五</td>
<td>119</td>
</tr>
</table>
</body>

<style>
td{
text-align: center;
}
</style>
</head>
<body>
<table width="500px" height="300px" border="1px" cellspacing="0">
<tr>
<th>姓名</th>
<th>电话</th>
</tr>
<tr>
<td>张三</td>
<td>110</td>
</tr>
<tr>
<td>李四</td>
<td>120</td>
</tr>
<tr>
<td>王五</td>
<td>119</td>
</tr>
</table>
</body>
这个操作就是让页面中 所有的 td 标签中的文字都水平居中(CSS)
有序列表 ol :ordered list
无序列表 ul :unordered list
列表项 li :list item
<body>
<!-- 有序列表 -->
<h3>四大名著</h3>
<ol>
<li>三国演义</li>
<li>水浒传</li>
<li>西游记</li>
<li>红楼梦</li>
</ol>
<!-- 无序列表 -->
<ul>
<li>三国演义</li>
<li>水浒传</li>
<li>西游记</li>
<li>红楼梦</li>
</ul>
</body>

表单是让用户输入信息的重要途径.
使用 form 进行前后端交互,把页面上用户进行的操作/输入提交到服务器上(暂时不展开,后面学了HTTP协议再说)
1)文本框
<body>
<input type="text">//单行文本框
</body>

2)密码框
<body>
<input type="password">//也是单行文本框,是用来输入密码的
</body>

3)单选框
<body>
请选择性别:
<input type="radio"> 男
<input type="radio"> 女
</body>

对于单选框需要加个 name 属性,name 属性相同的单选框, 值之间是互斥的。

<body>
请选择性别:
<input type="radio" name="gender"> 男
<input type="radio" name="gender"> 女
</body>
加入 checked 属性,默认选择
<body>
请选择性别:
<input type="radio" name="gender"> 男
<input type="radio" name="gender" checked="checked"> 女
</body>
4)复选框
<body>
大学生每天都干啥
<input type="checkbox"> 吃饭
<input type="checkbox"> 睡觉
<input type="checkbox"> 学习
</body>

也可以加上默认选项
<body>
大学生每天都干啥
<input type="checkbox" checked="checked"> 吃饭
<input type="checkbox"> 睡觉
<input type="checkbox"> 学习
</body>

5)按钮
<body>
<input type="button" value="我是个按钮">
</body>
对于按钮点击之后要干啥, 需要通过 JS 来配合
<body>
<input type="button" value="我是个按钮" onclick="alert('hello')">
</body>
alert 是 JS 里的一个函数,作用是弹出一个对话框,对话框的内容就是 hello
6)提交按钮
type="submit"
外表和 button 差不多,会触发 form 和服务器的交互。
7)上传文件
<body>
<input type="file">
</body>

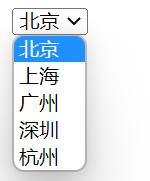
下拉菜单
<body>
<select>
<option>北京</option>
<option>上海</option>
<option>广州</option>
<option>深圳</option>
<option>杭州</option>
</select>
</body>
多行编辑框
<body>
<textarea cols="30" rows="10"></textarea>
</body>

上述这些标签也可以称为是"控件", 构成一个图形化界面的基本要素。
前面的标签都是有特定含义的,而无语义标签是没有特定含义的。无语义标签可以用在各种场景。
div 默认是独占一行的。(块级元素)
span 默认是不独占一行的。(行内元素)
<body>
<div style="border: 3px solid black;">
<h1>xxx的简历</h1>
<h2>基本信息</h2>
<img src="头像.jpg" alt="" height="200px">
<p>
求职意向:软件开发工程师
</p>
<p>
联系方式:110
</p>
<p>
邮箱:123456@qq.com
</p>
<p>
<a href="https://www.csdn.com">我的博客</a>
</p>
<p>
<a href="https://github.com">我的 github</a>
</p>
<h2>教育背景</h2>
<ol>
<li>
1990-1996 xxx小学
</li>
<li>
1997-2000 xxx初中
</li>
<li>
2001-2004 xxx高中
</li>
<li>
2005-2008 xxx大学
</li>
</ol>
<h2>专业技能</h2>
<ul>
<li>
熟练掌握 Java 的基本语法,熟悉面向对象程序设计思想
</li>
<li>
熟练常用的数据结构和算法,比如顺序表,链表,二叉树,堆,哈希表等
</li>
<li>
熟练操作系统中的典型概念,熟练掌握并发编程,对于多线程,线程安全,加锁等操作有深刻的认识
</li>
<li>
熟练掌握网络编程,熟悉网络通信原理,熟悉 TCP/IP 协议栈中的典型协议工作机制
</li>
<li>
熟练掌握 SQL,能够进行基础的增删改查, 熟悉 mysql 的索引和事务等机制
</li>
</ul>
<h2>我的项目</h2>
<ol>
<li>
<h3>留言墙</h3>
<p>开发时间: 2008-2011</p>
<div>功能介绍</div>
<ul>
<li>支持留言发布</li>
<li>支持匿名留言</li>
</ul>
</li>
<li>
<h3>学习小助手</h3>
<p>开发时间: 2011-2012</p>
<div>功能介绍</div>
<ul>
<li>支持错题检索</li>
<li>支持同学探讨</li>
</ul>
</li>
</ol>
<h2>个人评价</h2>
在校期间,学习成绩优异, 多次获得奖学金
</div>
</body>

HTML 只是描述了页面的骨架结构. 使用 CSS 可以针对页面进行进一步美化.
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我正在使用Rails构建一个简单的聊天应用程序。当用户输入url时,我希望将其输出为html链接(即“url”)。我想知道在Ruby中是否有任何库或众所周知的方法可以做到这一点。如果没有,我有一些不错的正则表达式示例代码可以使用... 最佳答案 查看auto_linkRails提供的辅助方法。这会将所有URL和电子邮件地址变成可点击的链接(htmlanchor标记)。这是文档中的代码示例。auto_link("Gotohttp://www.rubyonrails.organdsayhellotodavid@loudthinking.
我正在学习http://ruby.railstutorial.org/chapters/static-pages上的RubyonRails教程并遇到以下错误StaticPagesHomepageshouldhavethecontent'SampleApp'Failure/Error:page.shouldhave_content('SampleApp')Capybara::ElementNotFound:Unabletofindxpath"/html"#(eval):2:in`text'#./spec/requests/static_pages_spec.rb:7:in`(root)'
我正在尝试将一个简单的CSV文件读入HTML表格以在浏览器中显示,但我遇到了麻烦。这就是我正在尝试的:Controller:defshow@csv=CSV.open("file.csv",:headers=>true)end查看:输出:NameStartDateEndDateQuantityPostalCode基本上我只获取标题,而不会读取和呈现CSV正文。 最佳答案 这最终成为最终解决方案:Controller:defshow#OpenaCSVfile,andthenreaditintoaCSV::Tableobjectforda
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
考虑一下:现在这些情况:#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2#output:http://domain.com/?foo=1&bar=2我需要用其他字符串输出URL。我如何保证&符号不会被转义?由于我无法控制的原因,我无法发送&。求助!把我的头发拉到这里:\编辑:为了澄清,我实际上有一个像这样的数组:@images=[{:id=>"fooid",:url=>"http://
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
我正在尝试使用nokogirigem提取页面上的所有url及其链接文本,并将链接文本和url存储在散列中。FooBar我想回去{"Foo"=>"#foo","Bar"=>"#bar"} 最佳答案 这是一个单行:Hash[doc.xpath('//a[@href]').map{|link|[link.text.strip,link["href"]]}]#=>{"Foo"=>"#foo","Bar"=>"#bar"}拆分一点可以说更具可读性:h={}doc.xpath('//a[@href]').eachdo|link|h[link.t