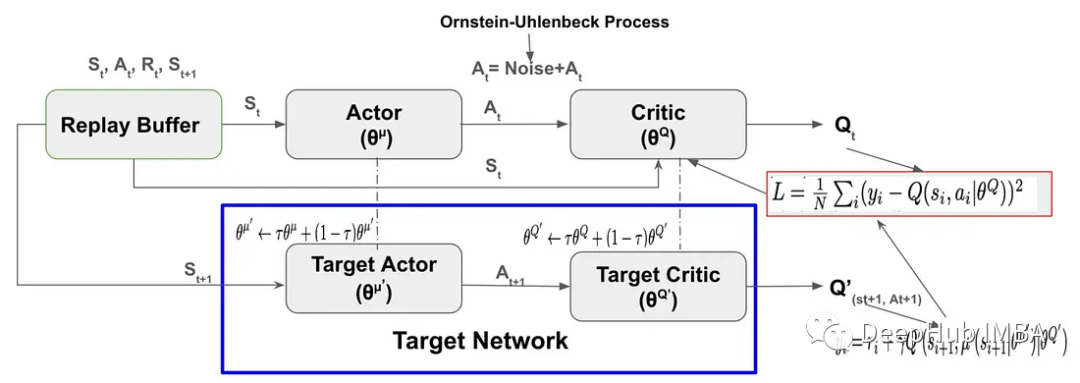
 DDPG的关键组成部分是
DDPG的关键组成部分是class Replay_buffer():
'''
Code based on:
https://github.com/openai/baselines/blob/master/baselines/deepq/replay_buffer.py
Expects tuples of (state, next_state, action, reward, done)
'''
def __init__(self, max_size=capacity):
"""Create Replay buffer.
Parameters
----------
size: int
Max number of transitions to store in the buffer. When the buffer
overflows the old memories are dropped.
"""
self.storage = []
self.max_size = max_size
self.ptr = 0
def push(self, data):
if len(self.storage) == self.max_size:
self.storage[int(self.ptr)] = data
self.ptr = (self.ptr + 1) % self.max_size
else:
self.storage.append(data)
def sample(self, batch_size):
"""Sample a batch of experiences.
Parameters
----------
batch_size: int
How many transitions to sample.
Returns
-------
state: np.array
batch of state or observations
action: np.array
batch of actions executed given a state
reward: np.array
rewards received as results of executing action
next_state: np.array
next state next state or observations seen after executing action
done: np.array
done[i] = 1 if executing ation[i] resulted in
the end of an episode and 0 otherwise.
"""
ind = np.random.randint(0, len(self.storage), size=batch_size)
state, next_state, action, reward, done = [], [], [], [], []
for i in ind:
st, n_st, act, rew, dn = self.storage[i]
state.append(np.array(st, copy=False))
next_state.append(np.array(n_st, copy=False))
action.append(np.array(act, copy=False))
reward.append(np.array(rew, copy=False))
done.append(np.array(dn, copy=False))
return np.array(state), np.array(next_state), np.array(action), np.array(reward).reshape(-1, 1), np.array(done).reshape(-1, 1)class Actor(nn.Module):
"""
The Actor model takes in a state observation as input and
outputs an action, which is a continuous value.
It consists of four fully connected linear layers with ReLU activation functions and
a final output layer selects one single optimized action for the state
"""
def __init__(self, n_states, action_dim, hidden1):
super(Actor, self).__init__()
self.net = nn.Sequential(
nn.Linear(n_states, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden1),
nn.ReLU(),
nn.Linear(hidden1, hidden1),
nn.ReLU(),
nn.Linear(hidden1, 1)
)
def forward(self, state):
return self.net(state)
class Critic(nn.Module):
"""
The Critic model takes in both a state observation and an action as input and
outputs a Q-value, which estimates the expected total reward for the current state-action pair.
It consists of four linear layers with ReLU activation functions,
State and action inputs are concatenated before being fed into the first linear layer.
The output layer has a single output, representing the Q-value
"""
def __init__(self, n_states, action_dim, hidden2):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(n_states + action_dim, hidden2),
nn.ReLU(),
nn.Linear(hidden2, hidden2),
nn.ReLU(),
nn.Linear(hidden2, hidden2),
nn.ReLU(),
nn.Linear(hidden2, action_dim)
)
def forward(self, state, action):
return self.net(torch.cat((state, action), 1))import numpy as np
import random
import copy
class OU_Noise(object):
"""Ornstein-Uhlenbeck process.
code from :
https://math.stackexchange.com/questions/1287634/implementing-ornstein-uhlenbeck-in-matlab
The OU_Noise class has four attributes
size: the size of the noise vector to be generated
mu: the mean of the noise, set to 0 by default
theta: the rate of mean reversion, controlling how quickly the noise returns to the mean
sigma: the volatility of the noise, controlling the magnitude of fluctuations
"""
def __init__(self, size, seed, mu=0., theta=0.15, sigma=0.2):
self.mu = mu * np.ones(size)
self.theta = theta
self.sigma = sigma
self.seed = random.seed(seed)
self.reset()
def reset(self):
"""Reset the internal state (= noise) to mean (mu)."""
self.state = copy.copy(self.mu)
def sample(self):
"""Update internal state and return it as a noise sample.
This method uses the current state of the noise and generates the next sample
"""
dx = self.theta * (self.mu - self.state) + self.sigma * np.array([np.random.normal() for _ in range(len(self.state))])
self.state += dx
return self.state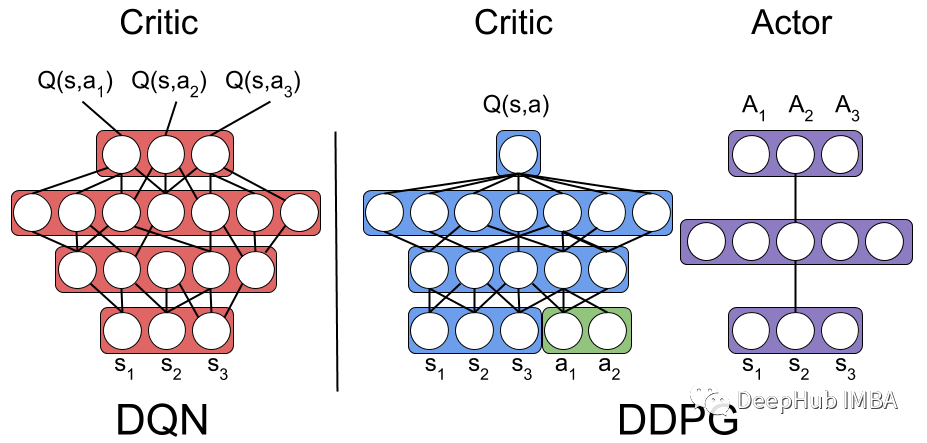 软目标的更新是从Actor-Critic网络传输到目标网络的称为目标更新率(τ)的权重的一小部分。软目标的更新公式如下:
软目标的更新是从Actor-Critic网络传输到目标网络的称为目标更新率(τ)的权重的一小部分。软目标的更新公式如下: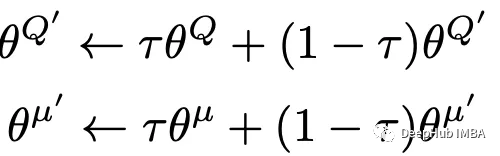 通过使用软目标技术,可以大大提高学习的稳定性。
通过使用软目标技术,可以大大提高学习的稳定性。#Set Hyperparameters
# Hyperparameters adapted for performance from
capacity=1000000
batch_size=64
update_iteration=200
tau=0.001 # tau for soft updating
gamma=0.99 # discount factor
directory = './'
hidden1=20 # hidden layer for actor
hidden2=64. #hiiden laye for critic
class DDPG(object):
def __init__(self, state_dim, action_dim):
"""
Initializes the DDPG agent.
Takes three arguments:
state_dim which is the dimensionality of the state space,
action_dim which is the dimensionality of the action space, and
max_action which is the maximum value an action can take.
Creates a replay buffer, an actor-critic networks and their corresponding target networks.
It also initializes the optimizer for both actor and critic networks alog with
counters to track the number of training iterations.
"""
self.replay_buffer = Replay_buffer()
self.actor = Actor(state_dim, action_dim, hidden1).to(device)
self.actor_target = Actor(state_dim, action_dim, hidden1).to(device)
self.actor_target.load_state_dict(self.actor.state_dict())
self.actor_optimizer = optim.Adam(self.actor.parameters(), lr=3e-3)
self.critic = Critic(state_dim, action_dim, hidden2).to(device)
self.critic_target = Critic(state_dim, action_dim, hidden2).to(device)
self.critic_target.load_state_dict(self.critic.state_dict())
self.critic_optimizer = optim.Adam(self.critic.parameters(), lr=2e-2)
# learning rate
self.num_critic_update_iteration = 0
self.num_actor_update_iteration = 0
self.num_training = 0
def select_action(self, state):
"""
takes the current state as input and returns an action to take in that state.
It uses the actor network to map the state to an action.
"""
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def update(self):
"""
updates the actor and critic networks using a batch of samples from the replay buffer.
For each sample in the batch, it computes the target Q value using the target critic network and the target actor network.
It then computes the current Q value
using the critic network and the action taken by the actor network.
It computes the critic loss as the mean squared error between the target Q value and the current Q value, and
updates the critic network using gradient descent.
It then computes the actor loss as the negative mean Q value using the critic network and the actor network, and
updates the actor network using gradient ascent.
Finally, it updates the target networks using
soft updates, where a small fraction of the actor and critic network weights are transferred to their target counterparts.
This process is repeated for a fixed number of iterations.
"""
for it in range(update_iteration):
# For each Sample in replay buffer batch
state, next_state, action, reward, done = self.replay_buffer.sample(batch_size)
state = torch.FloatTensor(state).to(device)
action = torch.FloatTensor(action).to(device)
next_state = torch.FloatTensor(next_state).to(device)
done = torch.FloatTensor(1-done).to(device)
reward = torch.FloatTensor(reward).to(device)
# Compute the target Q value
target_Q = self.critic_target(next_state, self.actor_target(next_state))
target_Q = reward + (done * gamma * target_Q).detach()
# Get current Q estimate
current_Q = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q, target_Q)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Compute actor loss as the negative mean Q value using the critic network and the actor network
actor_loss = -self.critic(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
"""
Update the frozen target models using
soft updates, where
tau,a small fraction of the actor and critic network weights are transferred to their target counterparts.
"""
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(tau * param.data + (1 - tau) * target_param.data)
self.num_actor_update_iteration += 1
self.num_critic_update_iteration += 1
def save(self):
"""
Saves the state dictionaries of the actor and critic networks to files
"""
torch.save(self.actor.state_dict(), directory + 'actor.pth')
torch.save(self.critic.state_dict(), directory + 'critic.pth')
def load(self):
"""
Loads the state dictionaries of the actor and critic networks to files
"""
self.actor.load_state_dict(torch.load(directory + 'actor.pth'))
self.critic.load_state_dict(torch.load(directory + 'critic.pth')) 下面定义算法的各种参数,例如最大训练次数、探索噪声和记录间隔等等。 使用固定的随机种子可以使得过程能够回溯。
下面定义算法的各种参数,例如最大训练次数、探索噪声和记录间隔等等。 使用固定的随机种子可以使得过程能够回溯。import gym
# create the environment
env_name='MountainCarContinuous-v0'
env = gym.make(env_name)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Define different parameters for training the agent
max_episode=100
max_time_steps=5000
ep_r = 0
total_step = 0
score_hist=[]
# for rensering the environmnet
render=True
render_interval=10
# for reproducibility
env.seed(0)
torch.manual_seed(0)
np.random.seed(0)
#Environment action ans states
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
min_Val = torch.tensor(1e-7).float().to(device)
# Exploration Noise
exploration_noise=0.1
exploration_noise=0.1 * max_action# Create a DDPG instance
agent = DDPG(state_dim, action_dim)
# Train the agent for max_episodes
for i in range(max_episode):
total_reward = 0
step =0
state = env.reset()
for t in range(max_time_steps):
action = agent.select_action(state)
# Add Gaussian noise to actions for exploration
action = (action + np.random.normal(0, 1, size=action_dim)).clip(-max_action, max_action)
#action += ou_noise.sample()
next_state, reward, done, info = env.step(action)
total_reward += reward
if render and i >= render_interval : env.render()
agent.replay_buffer.push((state, next_state, action, reward, np.float(done)))
state = next_state
if done:
break
step += 1
score_hist.append(total_reward)
total_step += step+1
print("Episode: \t{} Total Reward: \t{:0.2f}".format( i, total_reward))
agent.update()
if i % 10 == 0:
agent.save()
env.close()test_iteration=100
for i in range(test_iteration):
state = env.reset()
for t in count():
action = agent.select_action(state)
next_state, reward, done, info = env.step(np.float32(action))
ep_r += reward
print(reward)
env.render()
if done:
print("reward{}".format(reward))
print("Episode \t{}, the episode reward is \t{:0.2f}".format(i, ep_r))
ep_r = 0
env.render()
break
state = next_state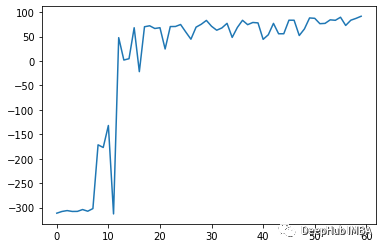
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
前言作为一名程序员,自己的本质工作就是做程序开发,那么程序开发的时候最直接的体现就是代码,检验一个程序员技术水平的一个核心环节就是开发时候的代码能力。众所周知,程序开发的水平提升是一个循序渐进的过程,每一位程序员都是从“菜鸟”变成“大神”的,所以程序员在程序开发过程中的代码能力也是根据平时开发中的业务实践来积累和提升的。提高代码能力核心要素程序员要想提高自身代码能力,尤其是新晋程序员的代码能力有很大的提升空间的时候,需要针对性的去提高自己的代码能力。提高代码能力其实有几个比较关键的点,只要把握住这些方面,就能很好的、快速的提高自己的一部分代码能力。1、多去阅读开源项目,如有机会可以亲自参与开源
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o