我相信每一位开发同学多多少少都想参与或负责一个高用户、高访问、高并发的系统吧😁。一来可以增加自己实际的项目经验,有应对高并发场景的解决方案,二来是有个高并发的项目经验无疑是自己简历的一个大大的加分项。但是奈何很多人都没有机会可以参与这样的项目,本文从以下几点介绍一下设计一个高流量高并发的系统需要经历哪些步骤以及考虑哪些因素(
文章中的不足之处还请大佬们多多指点
\color{red}{文章中的不足之处还请大佬们多多指点}
文章中的不足之处还请大佬们多多指点)。
在设计一个系统之前,我们先要有一个统一且清晰的认知:不要想着一下就能设计出完美的系统,好的系统是迭代出来的。不要复杂化,要先解决核心问题。但是要有先行的规划,对现有的问题有方案,对未来系统有预案。
在设计高并发的系统时要遵循以下几个原则:
无状态原则
什么是无状态?服务器不保存状态,对单次请求的处理不依赖别的请求就是无状态,主要是为了在应对高并发时方便水平扩展。
拆分原则
在我们的系统体积过于庞大或者承载不了大量的请求时,就要考虑拆分系统,将复杂问题简单化或将流量分散不同子系统分担压力。可以按照以下几个维度进行拆分:
服务化原则
当我们的系统被拆分的足够大时,一旦发生故障靠人工来处理是非常耗时耗力。这个时候就可以通过注册发现、限流、熔断、降级等方案让每个服务可以自己处理问题来帮助我们减少排障成本。
在进行业务设计时要遵循一些最基本的原则比如:
在高并发高流量的系统客户端的优化是必不可少的,如果没有做好客户端的优化影响用户体验是一方面,有时候甚至是致命的。
这里分享下我之前惨痛的教训:之前参与过一个秒杀的业务,就是因为前端的没有做优化,大量用户在刷新页面时服务器的带宽被打爆,页面加载不出来,影响了系统的发展,这是非常致命的。主要原因还是没有经验,以为后端做好高并发抵抗就可以。
客户端优化主要集中以下几点( 前端大佬帮忙更正补充 \color{red}{前端大佬帮忙更正补充} 前端大佬帮忙更正补充):
下面代码作为参考<meta http-equiv="x-dns-prefetch-control" content="on">
<link rel='dns-prefetch" href="www.baidu.com" >
<link rel='preload" href="..js" >
<link rel='prefetch" href="..js" >
CDN应用在客户端——>服务端之前,能够实时的根据网络流量和各节点的连接、负载情况以及到用户的距离和响应时间等综合信息将用户的请求导向离用户最近的服务节点上,使用户可以就近取得所需内容,解决网络拥挤的状况,提高用户访问网站的响应速度和成功率。我们可以通过CDN服务商购买CDN服务,绑定我们的域名,其他的事就不用我们管了。
借用一张网络上的图片帮助理解下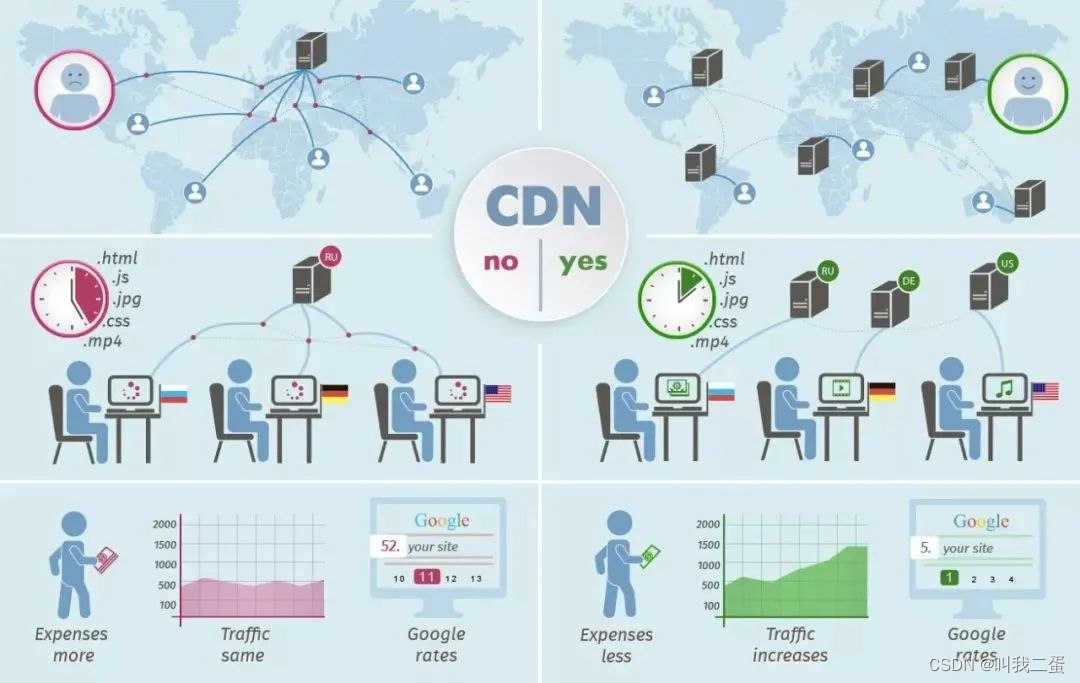
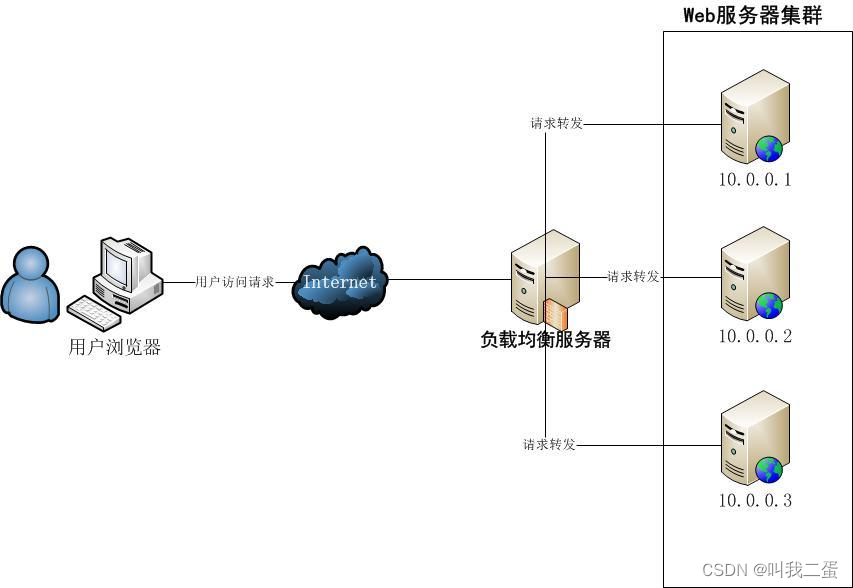
通常高并发系统都存在集群节点,为了抵抗大量的请求,也为了系统的高可用。根据业务场景利用负载策略将一个请求分发到集群中的某个计算节点。通过Nginx、LVS、Keepalived等集群组件可以轻松的实现这一功能。
依然是借用一张网络上的图片😁
缓存的介入其实就是空间换时间,常见的缓存组件redis、memcache、guava都可以起到减少响应时间的作用,在高并发的项目中经常被使用到,适合读多写少、耗时长的查询场景。但是会带来开发人员学习、写代码、部署机器、维护的成本。在设计key时要有以下几点认知:
否则使用缓存的收益是非常低甚至没有必要的。
当然,缓存技术的引入也是可能会带来一些列缓存问题,比如缓存击穿、缓存穿透、缓存雪崩等,依然需要代码层面去解决,在使用时需要注意这些问题。
我们知道所有的业务数据最终都会落到数据库,随着数据量的增加会带来响应时间的增加,以及系统的负载不断上升,数据库单点压力会越来越大,这个时候对数据库的优化就不单仅是冗余、反范式、索引,可以根据业务场景参考以下方案:
在高并发的项目中,往往我们的后端服务是很庞大的,因为服务拆分所引发的如:服务调用、服务雪崩、节点故障问题,以及处理高并发请求的问题。如何解决这些问题,让服务更稳定地运行,我们管它叫作服务治理。通常有以下几种方案:
做好一个高流量高并发的系统,不论前端还是后端,过程中每一个步骤都是至关重要的。设计一个系统除了满足功能性,还要考虑兼容性、易用性、可靠性、安全性、可维护性、可移植性等软件质量。同时要对系统的吞吐量、并发数、平均响应时间等指标要完全掌握,在指标异常时可以快速做出决策避免一系列问题发生。
当我使用Bundler时,是否需要在我的Gemfile中将其列为依赖项?毕竟,我的代码中有些地方需要它。例如,当我进行Bundler设置时:require"bundler/setup" 最佳答案 没有。您可以尝试,但首先您必须用鞋带将自己抬离地面。 关于ruby-我需要将Bundler本身添加到Gemfile中吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/4758609/
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
如果您尝试在Ruby中的nil对象上调用方法,则会出现NoMethodError异常并显示消息:"undefinedmethod‘...’fornil:NilClass"然而,有一个tryRails中的方法,如果它被发送到一个nil对象,它只返回nil:require'rubygems'require'active_support/all'nil.try(:nonexisting_method)#noNoMethodErrorexceptionanymore那么try如何在内部工作以防止该异常? 最佳答案 像Ruby中的所有其他对象
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
我将应用程序升级到Rails4,一切正常。我可以登录并转到我的编辑页面。也更新了观点。使用标准View时,用户会更新。但是当我添加例如字段:name时,它不会在表单中更新。使用devise3.1.1和gem'protected_attributes'我需要在设备或数据库上运行某种更新命令吗?我也搜索过这个地方,找到了许多不同的解决方案,但没有一个会更新我的用户字段。我没有添加任何自定义字段。 最佳答案 如果您想允许额外的参数,您可以在ApplicationController中使用beforefilter,因为Rails4将参数
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?