Java顺序表和链表
大家好,我是晓星航。今天我们将为大家讲解的是我们Java数据结构中顺序表和链表的用法及相关概念!😀
线性表(linear list)是n个具有相同特性的数据元素的有限序列。 线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表、链表、栈、队列、字符串…
线性表在逻辑上是线性结构,也就说是连续的一条直线。但是在物理结构上并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储。
其实就是一个数组。【增删查改】那为什么还有写一个顺序表,直接用数组就好了嘛?不一样,写到类里面 将来就可以 面向对象了。
顺序表是用一段物理地址连续的存储单元依次存储数据元素的线性结构,一般情况下采用数组存储。在数组上完成数据的增删查改。
顺序表一般可以分为:
静态顺序表适用于确定知道需要存多少数据的场景.
静态顺序表的定长数组导致N定大了,空间开多了浪费,开少了不够用.
相比之下动态顺序表更灵活, 根据需要动态的分配空间大小.
我们来实现一个动态顺序表. 以下是需要支持的接口.

这里我们挨个拆解出来:
public class MyArrayList {
public int[] elem;
public int usedSize;//有效的数据个数
public MyArrayList() {
this.elem = new int[10];
}
// 打印顺序表
public void display() {
}
System.out.println();
}
// 获取顺序表长度
public int size() {
return 0;
}
// 在 pos 位置新增元素
public void add(int pos, int data) {
}
// 判定是否包含某个元素
public boolean contains(int toFind) {
return true;
}
// 查找某个元素对应的位置
public int search(int toFind) {
return -1;
}
// 获取 pos 位置的元素
public int getPos(int pos) {
return -1;
}
// 给 pos 位置的元素设为 value
public void setPos(int pos, int value) {
}
//删除第一次出现的关键字key
public void remove(int toRemove) {
}
// 清空顺序表
public void clear() {
}
}
这是我们顺序表的基本结构。下面我们就把顺序表的功能一个一个拆解出来:
打印数据表:
public void display() {
for (int i = 0; i < this.usedSize; i++) {
System.out.print(this.elem[i] + " ");
}
System.out.println();
}
获取顺序表长度:
public int size() {
return this.usedSize;
}
在 pos 位置新增元素:
public void add(int pos, int data) {
if(pos < 0 || pos > this.usedSize) {
System.out.println("pos 位置不合法");
return;
}
if(isFull()){
this.elem = Arrays.copyOf(this.elem,2*this.elem.length);
}
for (int i = this.usedSize-1; i >= pos; i--) {
this.elem[i + 1] = this.elem[i];
}
this.elem[pos] = data;
this.usedSize++;
}
//判断数组元素是否等于有效数据个数
public boolean isFull() {
return this.usedSize == this.elem.length;
}
判断是否包含某个元素:
public boolean contains(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if (this.elem[i] == toFind) {
return true;
}
}
return false;
}
查找某个元素对应的位置:
public int search(int toFind) {
for (int i = 0; i < this.usedSize; i++) {
if (this.elem[i] == toFind) {
return i;
}
}
return -1;
}
获取 pos 位置的元素:
public int getPos(int pos) {
if (pos < 0 || pos >= this.usedSize){
System.out.println("pos 位置不合法");
return -1;//所以 这里说明一下,业务上的处理,这里不考虑
}
if(isEmpty()) {
System.out.println("顺序表为空!");
return -1;
}
return this.elem[pos];
}
//判断数组链表是否为空
public boolean isEmpty() {
return this.usedSize == 0;
}
给 pos 位置的元素设为 value:
public void setPos(int pos, int value) {
if(pos < 0 || pos >= this.usedSize) {
System.out.println("pos 位置不合法");
return;
}
if(isEmpty()) {
System.out.println("顺序表为空!");
return;
}
this.elem[pos] = value;
}
//判断数组链表是否为空
public boolean isEmpty() {
return this.usedSize == 0;
}
删除第一次出现的关键字key:
public void remove(int toRemove) {
if(isEmpty()) {
System.out.println("顺序表为空!");
return;
}
int index = search(toRemove);//index记录删除元素的位置
if(index == -1) {
System.out.println("没有你要删除的数字!");
}
for (int i = index; i < this.usedSize - 1; i++) {
this.elem[i] = this.elem[i + 1];
}
this.usedSize--;
//this.elem[usedSize] = null;引用数组必须这样做才可以删除
}
清空顺序表:
public void clear() {
this.usedSize = 0;
}
顺序表中间/头部的插入删除,时间复杂度为O(N)
增容需要申请新空间,拷贝数据,释放旧空间。会有不小的消耗。
增容一般是呈2倍的增长,势必会有一定的空间浪费。例如当前容量为100,满了以后增容到200,我们再继续插入了5个数据,后面没有数据插入了,那么就浪费了95个数据空间。
思考: 如何解决以上问题呢?下面给出了链表的结构来看看。

链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。
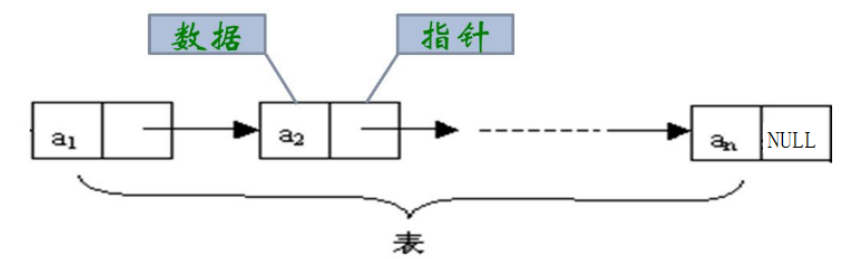
实际中链表的结构非常多样,如果按一般来分的话就是四种:
如果细分的话就有以下情况组合起来就有8种链表结构:
这八种分别为:
注:上述加粗是我们重点需要学习的!!!
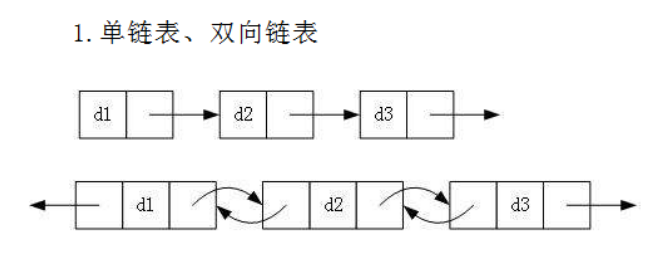
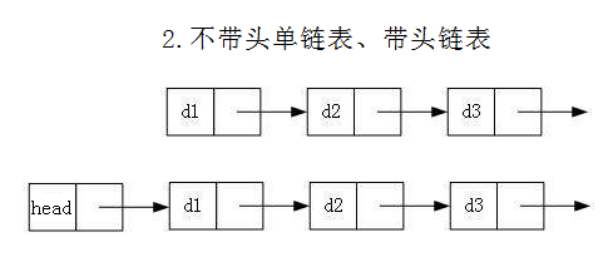
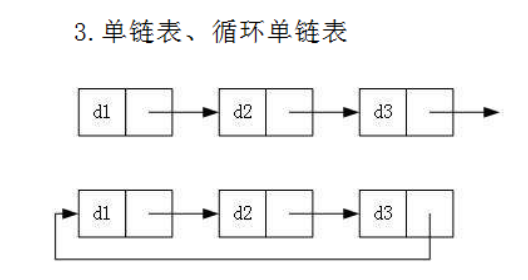
虽然有这么多的链表的结构,但是我们重点掌握两种:
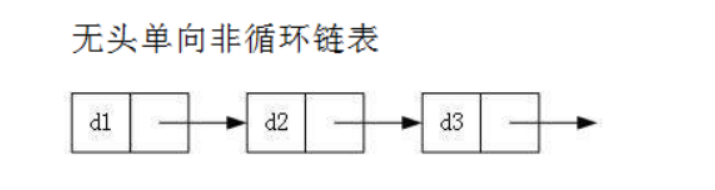
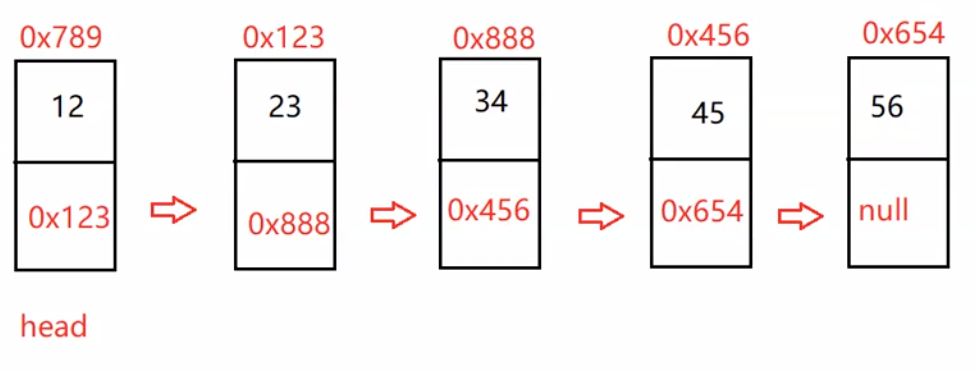
head:里面存储的就是第一个节点(头节点)的地址
head.next:存储的就是下一个节点的地址
尾结点:它的next域是一个null
最上面的数字是我们每一个数值自身的地址。
prev:指向前一个元素地址
next:下一个节点地址
data:数据
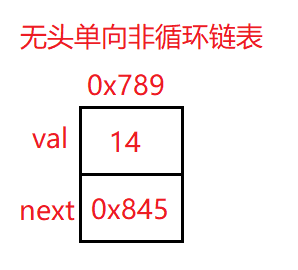
上面地址为改结点元素的地址
val:数据域
next:下一个结点的地址
head:里面存储的就是第一个结点(头结点)的地址
head.next:存储的就是下一个结点的地址
无头单向非循环链表实现:
class ListNode {
public int val;
public ListNode next;//ListNode储存的是结点类型
public ListNode (int val) {
this.val = val;
}
}
public class MyLinkedList {
public ListNode head;//链表的头引用
public void creatList() {
ListNode listNode1 = new ListNode(12);
ListNode listNode2 = new ListNode(23);
ListNode listNode3 = new ListNode(34);
ListNode listNode4 = new ListNode(45);
ListNode listNode5 = new ListNode(56);
listNode1.next = listNode2;
listNode2.next = listNode3;
listNode3.next = listNode4;
listNode4.next = listNode5;
this.head = listNode1;
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
return true;
}
//得到单链表的长度
public int size(){
return -1;
}
//头插法
public void addFirst(int data) {
}
//尾插法
public void addLast(int data) {
}
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data) {
return true;
}
//删除第一次出现关键字为key的节点
public void remove(int key) {
}
//删除所有值为key的节点
public ListNode removeAllKey(int key) {
}
//打印链表中的所有元素
public void display() {
}
//清除链表中所有元素
public void clear() {
}
}
上面是我们链表的初步结构(未给功能赋相关代码,大家可以复制他们到自己的idea中进行练习,答案在下文中) 这里我们将他们一个一个拿出来实现 并实现!
打印链表中所有元素:
public void display() {
ListNode cur = this.head;
while(cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
查找是否包含关键字key是否在单链表当中:
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
得到单链表的长度:
public int size(){
int count = 0;
ListNode cur = this.head;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
头插法(一定要记住 绑定位置时一定要先绑定后面的数据 避免后面数据丢失):
public void addFirst(int data) {
ListNode node = new ListNode(data);
node.next = this.head;
this.head = node;
/*if (this.head == null) {
this.head = node;
} else {
node.next = this.head;
this.head = node;
}*/
}
尾插法:
public void addLast(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
} else {
ListNode cur = this.head;
while (cur.next != null) {
cur = cur.next;
}
cur.next = node;
}
}
任意位置插入,第一个数据结点为0号下标(插入到index后面一个位置):
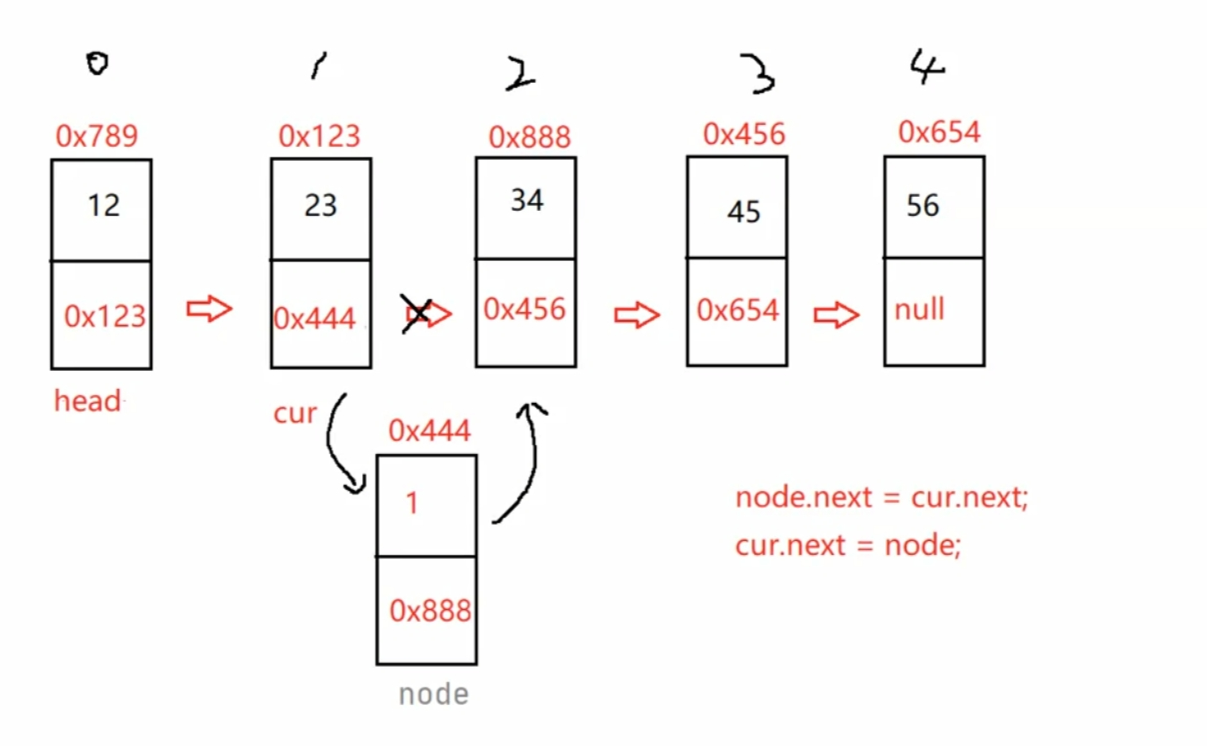
/**
* 找到index - 1位置的节点的地址
* @param index
* @return
*/
public ListNode findIndex(int index) {
ListNode cur = this.head;
while (index - 1 != 0) {
cur = cur.next;
index--;
}
return cur;
}
//任意位置插入,第一个数据节点为0号下标
public void addIndex(int index,int data) {
if(index < 0 || index > size()) {
System.out.println("index 位置不合法!");
return;
}
if(index == 0) {
addFirst(data);
return;
}
if(index == size()) {
addLast(data);
return;
}
ListNode cur = findIndex(index);
ListNode node = new ListNode(data);
node.next = cur.next;
cur.next = node;
}
注意:单向链表找cur时要-1,但双向链表不用 直接返回cur就好
删除第一次出现关键字为key的结点:
/**
* 找到 要删除的关键字key的节点
* @param key
* @return
*/
public ListNode searchPerv(int key) {
ListNode cur = this.head;
while(cur.next != null) {
if(cur.next.val == key) {
return cur;
}
cur = cur.next;
}
return null;
}
//删除第一次出现关键字为key的节点
public void remove(int key) {
if(this.head == null) {
System.out.println("单链表为空");
return;
}
if(this.head.val == key) {
this.head = this.head.next;
return;
}
ListNode cur = searchPerv(key);
if(cur == null) {
System.out.println("没有你要删除的节点");
return;
}
ListNode del = cur.next;
cur.next = del.next;
}
删除所有值为key的结点:
public ListNode removeAllKey(int key) {
if(this.head == null) {
return null;
}
ListNode prev = this.head;
ListNode cur = this.head.next;
while(cur != null) {
if(cur.val == key) {
prev.next = cur.next;
cur = cur.next;
} else {
prev = cur;
cur = cur.next;
}
}
//最后处理头
if(this.head.val == key) {
this.head = this.head.next;
}
return this.head;
}
清空链表中所有元素:
public void clear() {
while (this.head != null) {
ListNode curNext = head.next;
head.next = null;
head.prev = null;
head = curNext;
}
last = null;
}
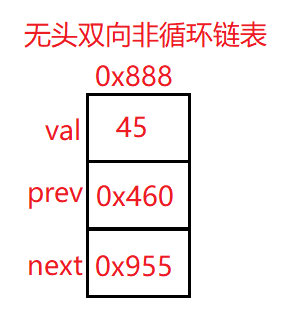
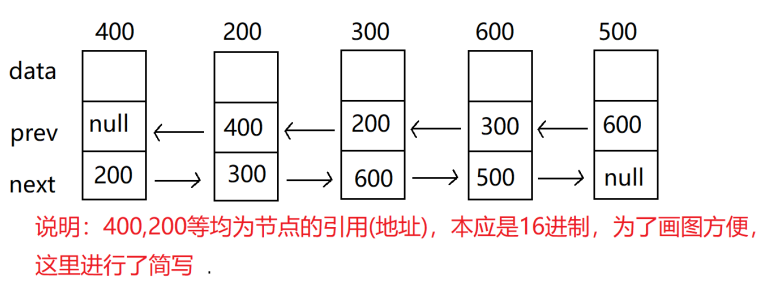
上面的地址0x888为该结点的地址
val:数据域
prev:上一个结点地址
next:下一个结点地址
head:头结点 一般指向链表的第一个结点
class ListNode {
public int val;
public ListNode prev;
public ListNode next;
public ListNode (int val) {
this.val = val;
}
}
public class MyLinkedList {
public ListNode head;//指向双向链表的头结点
public ListNode last;//只想双向链表的尾结点
//打印链表
public void display() {
}
//得到单链表的长度
public int size() {
return -1;
}
//查找是否包含关键字key是否在单链表当中
public boolean contains(int key) {
return true;
}
//头插法
public void addFirst(int data) {
}
//尾插法
public void addLast(int data) {
}
//删除第一次出现关键字为key的节点
public void remove(int key) {
}
//删除所有值为key的节点
public void removeAllKey(int key) {
}
//任意位置插入,第一个数据节点为0号下标
public boolean addIndex(int index,int data) {
return true;
}
//清空链表
public void clear() {
}
}
上面是我们链表的初步结构(未给功能赋相关代码,大家可以复制他们到自己的idea中进行练习,答案在下文中) 这里我们将他们一个一个拿出来实现 并实现!
打印链表:
public void display() {
ListNode cur = this.head;
while (cur != null) {
System.out.print(cur.val + " ");
cur = cur.next;
}
System.out.println();
}
得到单链表的长度:
public int size() {
ListNode cur = this.head;
int count = 0;
while (cur != null) {
count++;
cur = cur.next;
}
return count;
}
查找是否包含关键字key是否在单链表当中:
public boolean contains(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
return true;
}
cur = cur.next;
}
return false;
}
头插法:
public void addFirst(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
this.last = node;
} else {
node.next = this.head;
this.head.prev = node;
this.head = node;
}
}
尾插法:
public void addLast(int data) {
ListNode node = new ListNode(data);
if (this.head == null) {
this.head = node;
this.last = node;
} else {
ListNode lastPrev = this.last;
this.last.next = node;
this.last = this.last.next;
this.last.prev = lastPrev;
/**
* 两种方法均可
* this.last.next = node;
* node.prev = this.last;
* this.last = node;
*/
}
}
注:第一种方法是先让last等于尾结点 再让他的前驱等于上一个地址 而第二种方法是先使插入的尾结点的前驱等于上一个地址 再使其等于尾结点
删除第一次出现关键字为key的结点:
public void remove(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;
if (head != null) {
head.prev = null;
} else {
last = null;
}
} else if (cur == last) {
last = last.prev;
last.next = null;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
return;
}
cur = cur.next;
}
}
删除所有值为key的结点:
public void removeAllKey(int key) {
ListNode cur = this.head;
while (cur != null) {
if (cur.val == key) {
if (cur == head) {
head = head.next;
if (head != null) {
head.prev = null;
} else {
last = null;
}
} else if (cur == last) {
last = last.prev;
last.next = null;
} else {
cur.prev.next = cur.next;
cur.next.prev = cur.prev;
}
//return;
}
cur = cur.next;
}
}
注:他和remove的区别就是删除完后是不是直接return返回,如果要删除所有的key值则不return,让cur继续往后面走。
任意位置插入,第一个数据节点为0号下标:
public void addIndex(int index,int data) {
if (index < 0 || index > size()) {
System.out.println("index 位置不合法");
}
if (index == 0) {
addFirst(data);
return;
}
if (index == size()) {
addLast(data);
return;
}
ListNode cur = searchIndex(index);
ListNode node = new ListNode(data);
node.next = cur;
cur.prev.next = node;
node.prev = cur.prev;
cur.prev = node;
}
public ListNode searchIndex(int index) {
ListNode cur = this.head;
while (index != 0) {
cur = cur.next;
index--;
}
return cur;
}
思路:先判断 在头位置就头插 在尾位置就尾插 在中间就改变四个位置的值。
注意:单向链表找cur时要-1,但双向链表不用 直接返回cur就好
清空链表:
public void clear() {
while (this.head != null) {
ListNode curNext = head.next;
head.next = null;
head.prev = null;
head = curNext;
}
last = null;
}

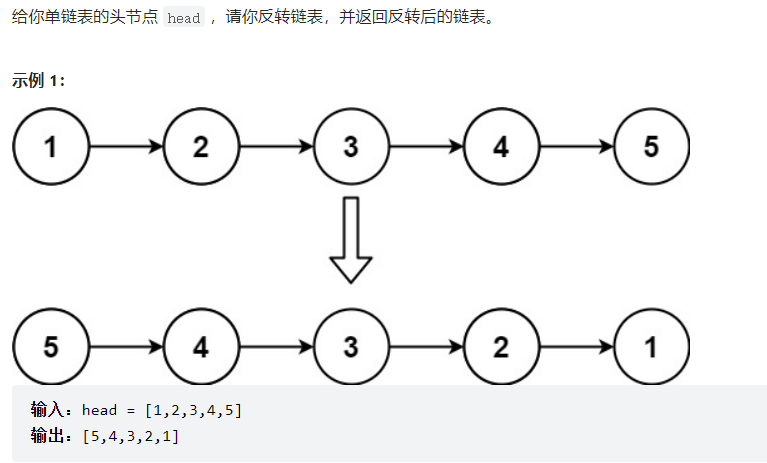

这里的
cur = this.head;
prev = null;
curNext = cur.next;
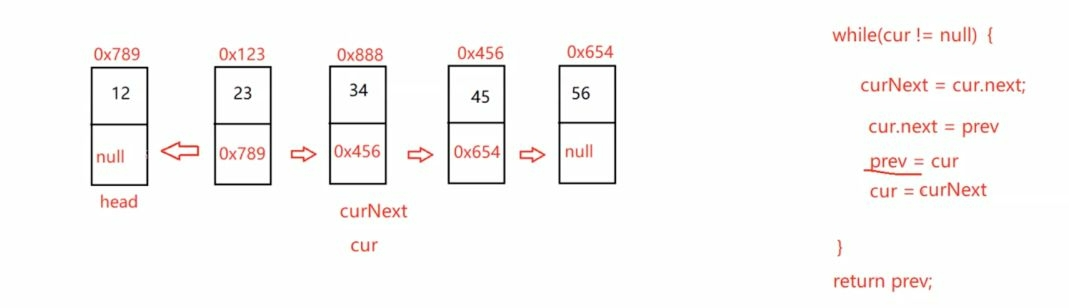
public ListNode reverseList() {
if (this.head == null) {
return null;
}
ListNode cur = this.head;
ListNode prev = null;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = prev;
prev = cur;
cur = curNext;
}
return prev;
}


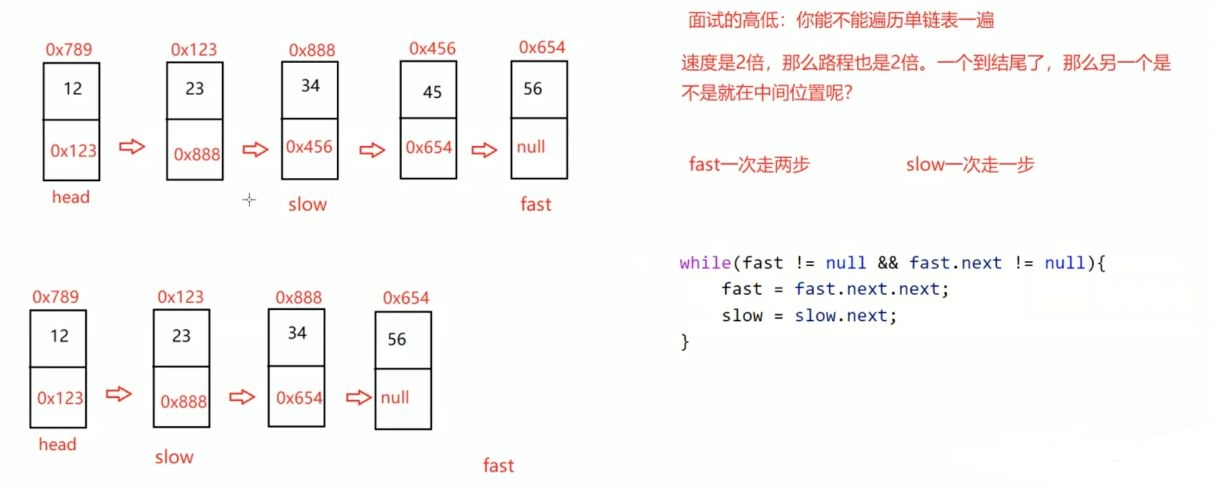
public ListNode middleNode() {
if (head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
if (fast == null) {
return slow;
}
slow = slow.next;
}
return slow;
}

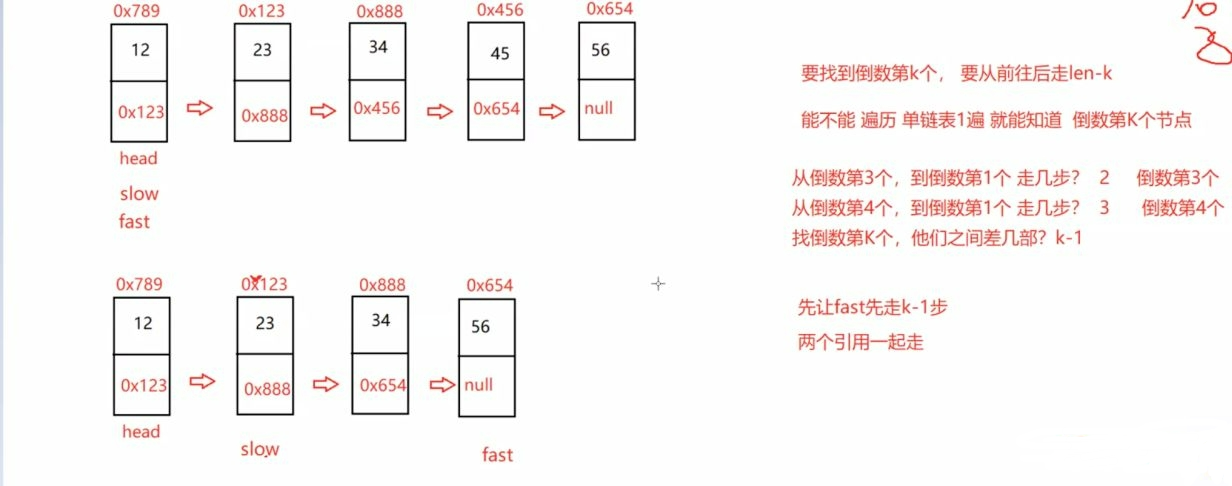
public ListNode findKthToTail(ListNode head,int k) {
if (k <= 0 || head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (k - 1 != 0) {
fast = fast.next;
if (fast == null) {
return null;
}
k--;
}
while (fast.next != null) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
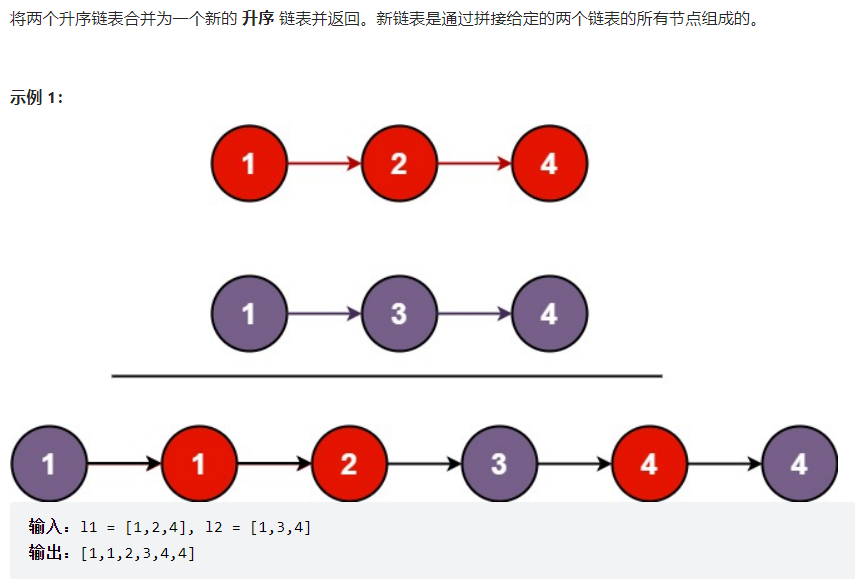

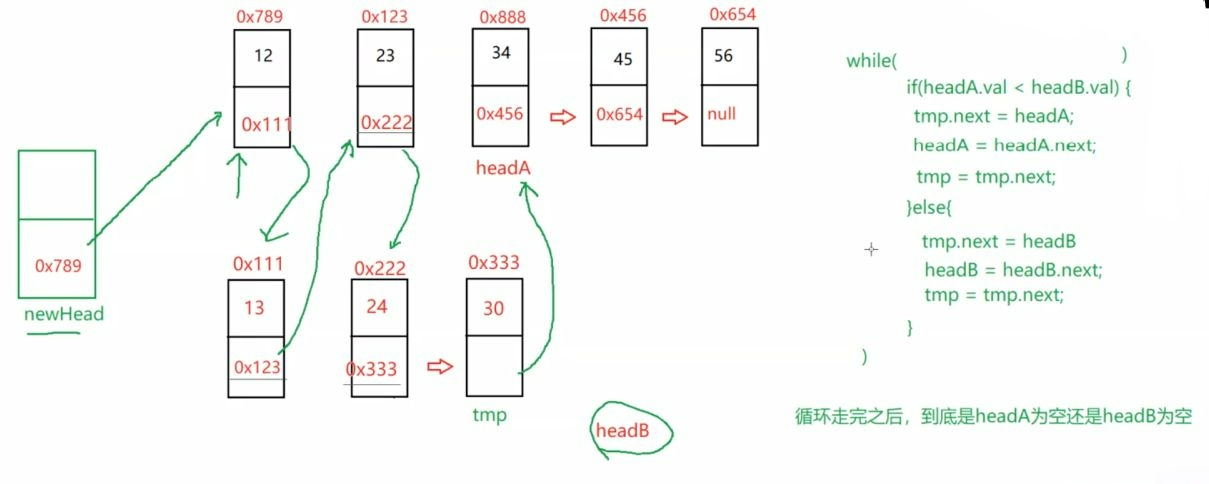
public static ListNode mergeTwoLists(ListNode headA,ListNode headB) {
ListNode newHead = new ListNode(-1);
ListNode tmp = newHead;
while (headA != null && headB != null) {
if(headA.val <headB.val) {
tmp.next = headA;
headA = headA.next;
tmp = tmp.next;
} else {
tmp.next = headB;
headB = headB.next;
tmp = tmp.next;
}
}
if (headA != null) {
tmp.next = headA;
}
if (headB != null) {
tmp.next = headB;
}
return newHead.next;
}
最后返回的是傀儡结点的下一个 即newHead.next

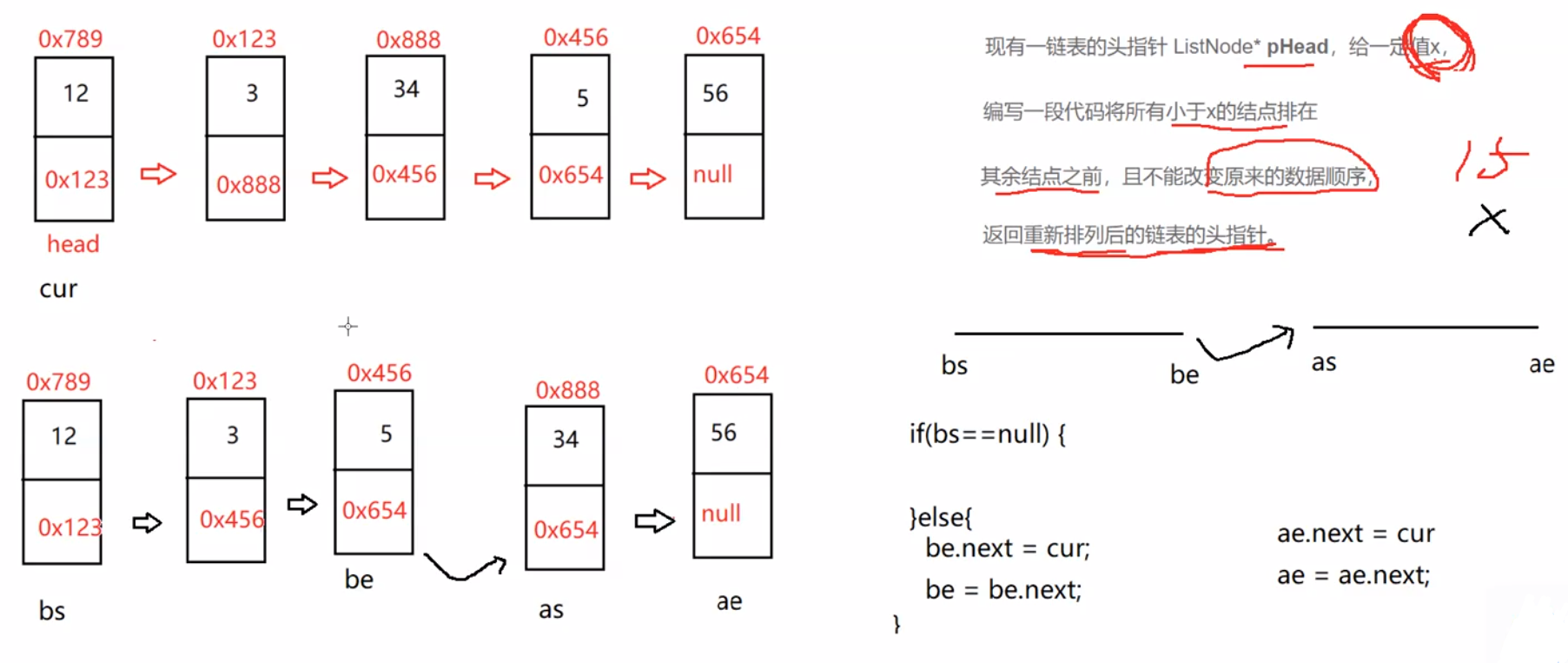
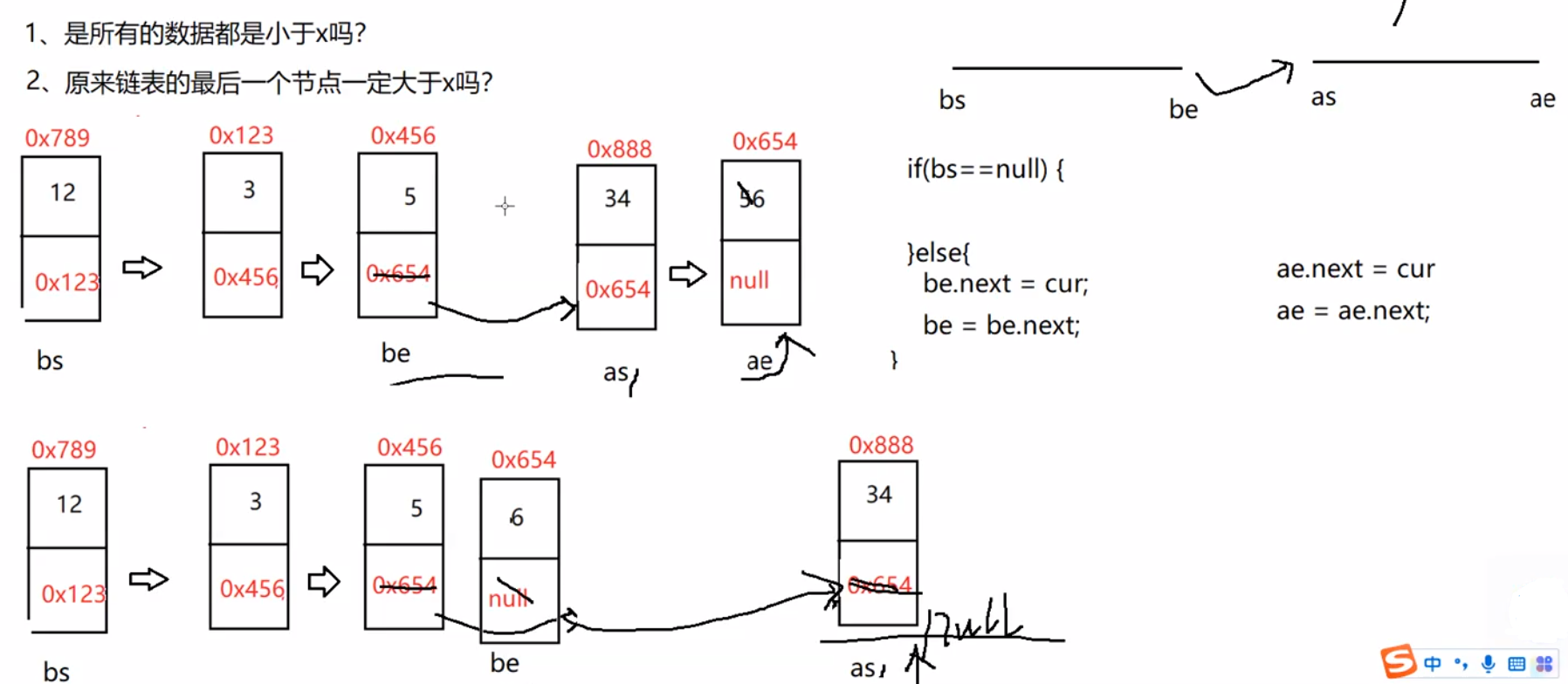
//按照x和链表中元素的大小来分割链表中的元素
public ListNode partition(int x) {
ListNode bs = null;
ListNode be = null;
ListNode as = null;
ListNode ae = null;
ListNode cur = head;
while (cur != null) {
if(cur.val < x){
//1、第一次
if (bs == null) {
bs = cur;
be = cur;
} else {
//2、不是第一次
be.next = cur;
be = be.next;
}
} else {
//1、第一次
if (as == null) {
as = cur;
as = cur;
} else {
//2、不是第一次
ae.next = cur;
ae = ae.next;
}
}
cur = cur.next;
}
//预防第1个段为空
if (bs == null) {
return as;
}
be.next = as;
//预防第2个段当中的数据,最后一个节点不是空的。
if (as != null) {
ae.next = null;
}
return be;
}
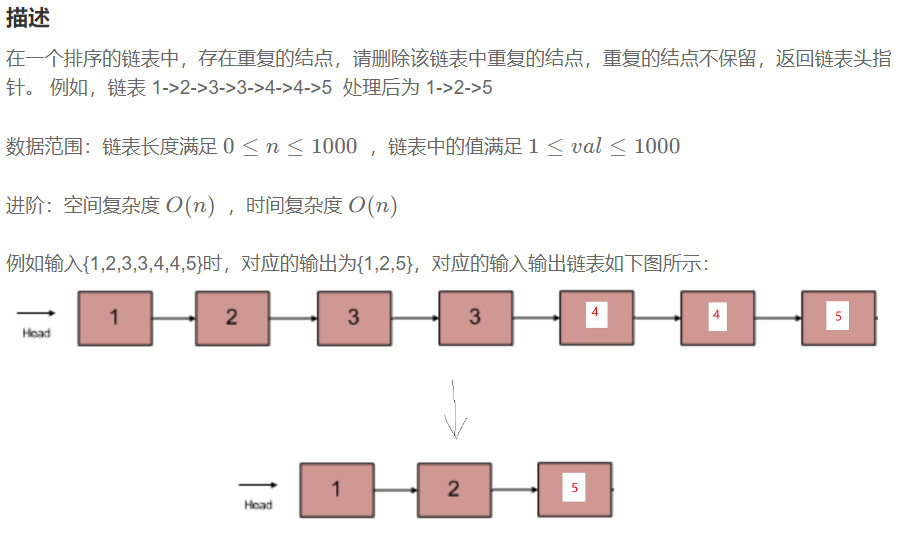

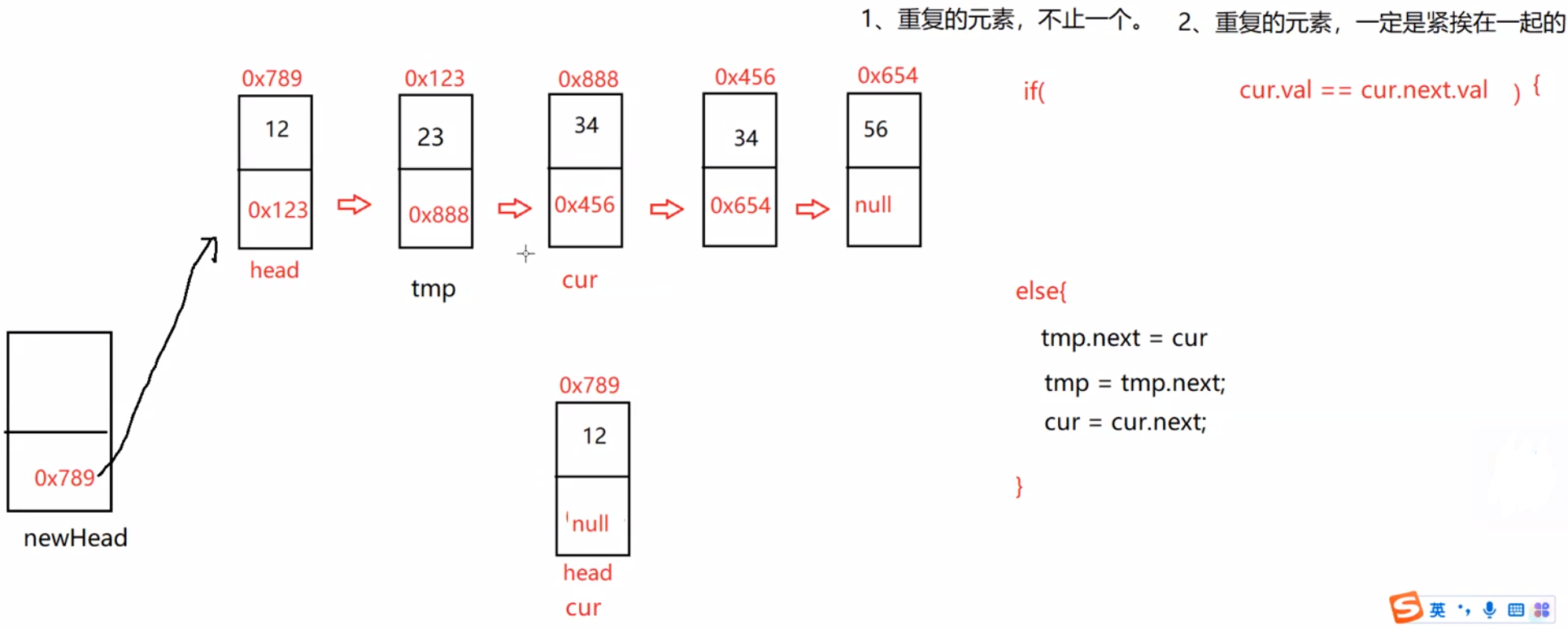
public ListNode deleteDuplication() {
ListNode cur = head;
ListNode newHead = new ListNode(-1);
ListNode tmp = newHead;
while (cur != null) {
if (cur.next != null && cur.val == cur.next.val) {
while (cur.next != null && cur.val == cur.next.val) {
cur = cur.next;
}
//多走一步
cur = cur.next;
} else {
tmp.next = cur;
tmp = tmp.next;
cur = cur.next;
}
}
//防止最后一个结点的值也是重复的
tmp.next = null;
return newHead.next;
}

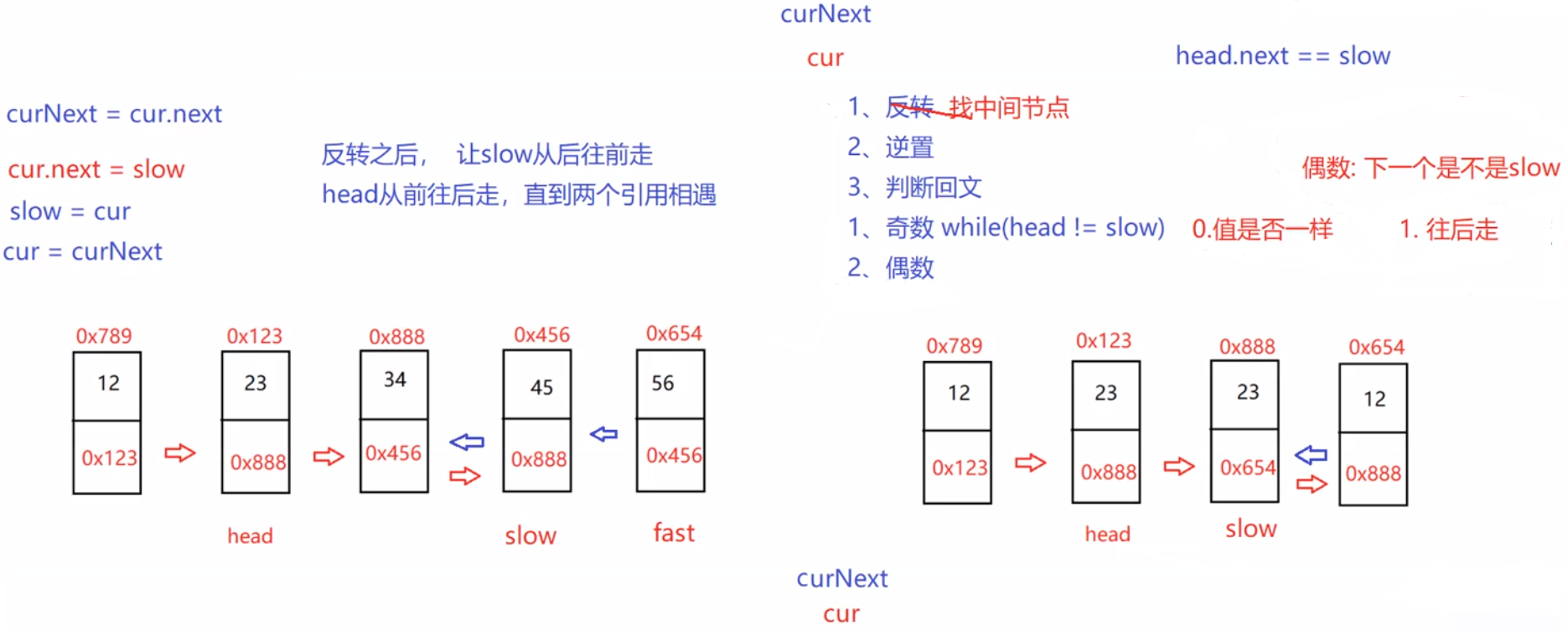
public boolean chkPalindrome(ListNode head) {
if (head == null) {
return true;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
}
//slow走到了中间位置
ListNode cur = slow.next;
while (cur != null) {
ListNode curNext = cur.next;
cur.next = slow;
slow = cur;
cur = curNext;
}
//反转完成
while (head != slow) {
if(head.val != slow.val) {
return false;
} else {
if (head.next == slow) {
return true;
}
head = head.next;
slow = slow.next;
}
return true;
}
return true;
}
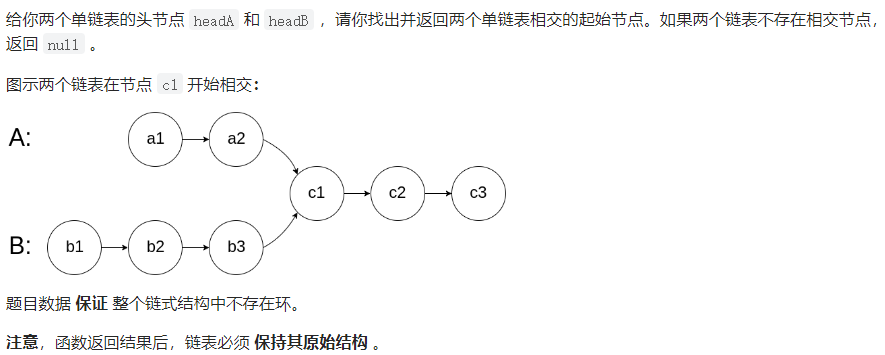
他是一个Y字形
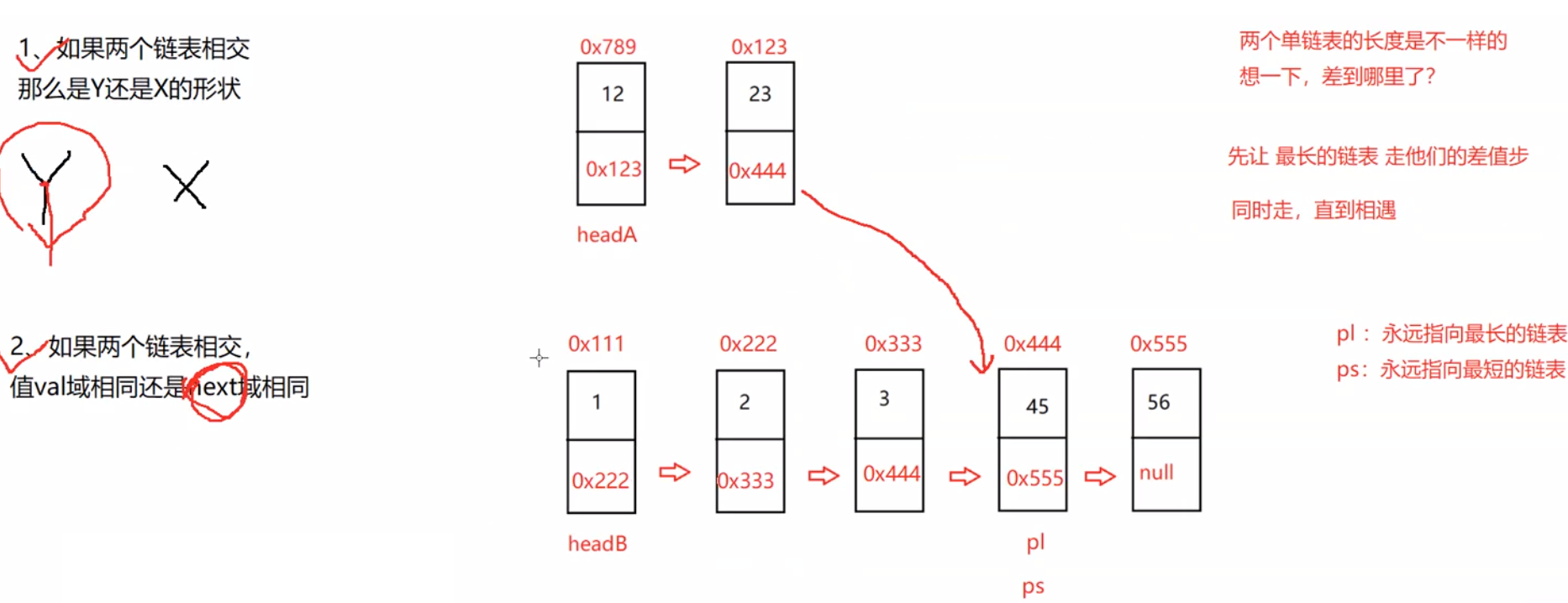

public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pl = headA;
ListNode ps = headB;
int lenA = 0;
int lenB = 0;
//求lenA的长度
while (pl != null) {
lenA++;
pl = pl.next;
}
pl = headA;
//求lenB的长度
while (ps != null) {
lenB++;
ps = ps.next;
}
ps = headB;
int len = lenA - lenB;//差值步
if (len < 0) {
pl = headB;
ps = headA;
len = lenB - lenA;
}
//1、pl永远指向了最长的链表,ps永远指向了最短的链表 2、求到了插值len步
//pl走差值len步
while (len != 0) {
pl = pl.next;
len--;
}
//同时走直到相遇
while (pl != ps) {
pl = pl.next;
ps = ps.next;
}
return pl;
}

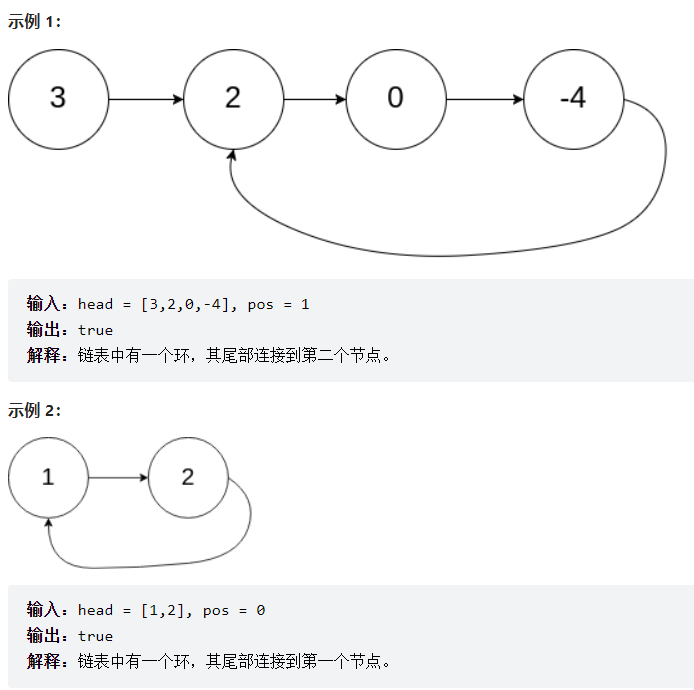

提问:为啥么fast一次走两步,不走三步?
答:如果链表只有两个元素他们则永远相遇不了(如上图的示例2),而且走三步的效率没有走两步的效率高。
public boolean hasCycle(ListNode head) {
if (head == null) {
return false;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
return true;
}
}
return false;
}

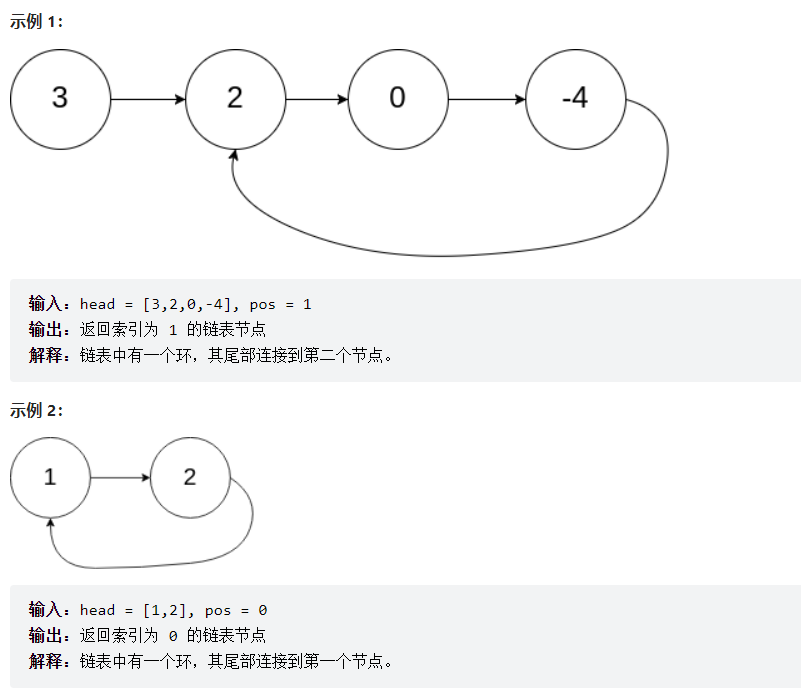

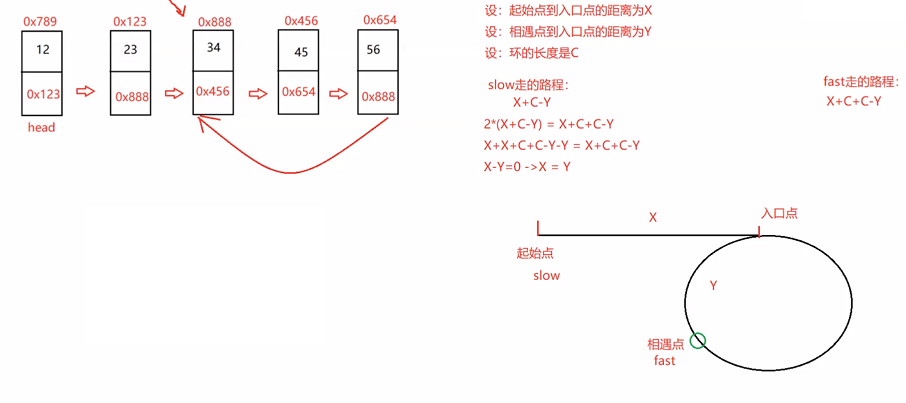
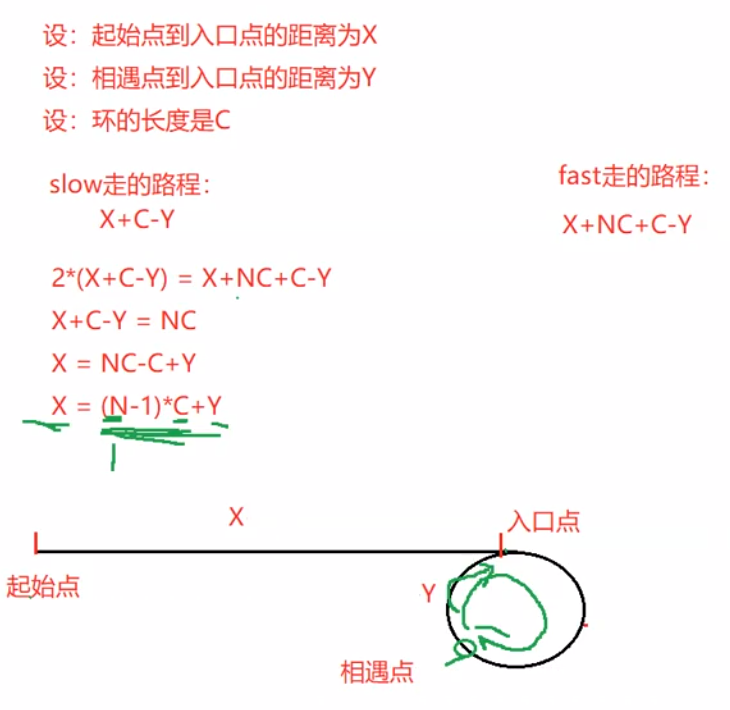
public ListNode detectCycle(ListNode head) {
if (head == null) {
return null;
}
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (fast == slow) {
break;
}
}
if (fast == null || fast.next == null) {
return null;
}
fast = head;
while (fast != slow) {
fast = fast.next;
slow = slow.next;
}
return fast;
}
牛客网链表题大全:
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网 (nowcoder.com)
力扣链表题大全:

顺序表:一白遮百丑
白:空间连续、支持随机访问
丑:
链表:一(胖黑)毁所有
胖黑:以节点为单位存储,不支持随机访问
所有:
组织:
1、顺序表底层是一个数组,他是一个逻辑上和物理上都是连续的
2、链表是一个由若干结点组成的一个数据结构,逻辑上是连续的 但是在物理上[内存上]是不一定连续的。
操作:
1、顺序表适合,查找相关的操作,因为可以使用下标,直接获取到某个位置的元素
2、链表适合于,频繁的插入和删除操作。此时不需要像顺序表一样,移动元素。链表的插入 只需要修改指向即可。
3、顺序表还有不好的地方,就是你需要看满不满,满了要扩容,扩容了之后,不一定都能放完。所以,他空间上的利用率不高。
链表随用随取 要一个new一个
而数组则不一样 数组是一开始就确定好的
集合框架当中的两个类
集合框架就是将 所有的数据结构,封装成Java自己的类
以后我们要是用到顺序表了 直接使用ArrayList就可以。

数据结构就是要多动手写代码,必须独立将我们上面写的顺序表和链表的相关代码自己独立重新写两遍以上(为了加强我们对代码的理解,也可以帮助我们更快熟悉数据结构代码的套路,进而更快的上手数据结构的代码,偷偷告诉各位博主自己对着这些代码每一个都写了3遍噢!),这里强调独立就是不要看着我们的代码进行抄写,要看一遍之后,创建一个新的代码类来联系,这样对我们代码的长进会有很大的帮助!!!
感谢各位读者的阅读,本文章有任何错误都可以在评论区发表你们的意见,我会对文章进行改正的。如果本文章对你有帮助请动一动你们敏捷的小手点一点赞,你的每一次鼓励都是作者创作的动力哦!😘
我遵循了教程http://gettingstartedwithchef.com/,第1章。我的运行list是"run_list":["recipe[apt]","recipe[phpap]"]我的phpapRecipe默认Recipeinclude_recipe"apache2"include_recipe"build-essential"include_recipe"openssl"include_recipe"mysql::client"include_recipe"mysql::server"include_recipe"php"include_recipe"php::modul
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
HashMap中为什么引入红黑树,而不是AVL树呢1.概述开始学习这个知识点之前我们需要知道,在JDK1.8以及之前,针对HashMap有什么不同。JDK1.7的时候,HashMap的底层实现是数组+链表JDK1.8的时候,HashMap的底层实现是数组+链表+红黑树我们要思考一个问题,为什么要从链表转为红黑树呢。首先先让我们了解下链表有什么不好???2.链表上述的截图其实就是链表的结构,我们来看下链表的增删改查的时间复杂度增:因为链表不是线性结构,所以每次添加的时候,只需要移动一个节点,所以可以理解为复杂度是N(1)删:算法时间复杂度跟增保持一致查:既然是非线性结构,所以查询某一个节点的时候
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
我基本上来自Java背景并且努力理解Ruby中的模运算。(5%3)(-5%3)(5%-3)(-5%-3)Java中的上述操作产生,2个-22个-2但在Ruby中,相同的表达式会产生21个-1-2.Ruby在逻辑上有多擅长这个?模块操作在Ruby中是如何实现的?如果将同一个操作定义为一个web服务,两个服务如何匹配逻辑。 最佳答案 在Java中,模运算的结果与被除数的符号相同。在Ruby中,它与除数的符号相同。remainder()在Ruby中与被除数的符号相同。您可能还想引用modulooperation.
Java的Collections.unmodifiableList和Collections.unmodifiableMap在Ruby标准API中是否有等价物? 最佳答案 使用freeze应用程序接口(interface):Preventsfurthermodificationstoobj.ARuntimeErrorwillberaisedifmodificationisattempted.Thereisnowaytounfreezeafrozenobject.SeealsoObject#frozen?.Thismethodretur