在搜索推荐中,通常使用相似Embedding进行推荐,此时就会有一个问题:如何快速找到与一个Embedding相近的其他Embedding
如果两个Embedding在同一个向量空间中,我们就可以通过很多种方式(内积、余弦、欧氏距离等)计算其相似度;例如在推荐系统中,用户和物品的Embedding都在同一个空间中,物品总数为\(n\),那么计算一个用户和所以物品向量相似度的时间复杂度是\(O(n)\),而\(n\)通常都能达到百万甚至上亿,这样的计算方式是无法接受的;
如果将相似点聚类在一起,在检索相似向量的时候则可以快速缩小范围,只计算目标Embedding所在的聚类范围内的相似度,这里可以使用叫常见的[[K-means]]聚类方法;
但是这种方法在聚类的边缘会出现些问题,如果只检索类别内的向量,则可能遗漏在其他类别中的相近点;另外,对于K-means方法,K值得选择也是一个问题,如果K选的太大,则迭代过程会很缓慢;K值选的太小,则搜索范围无法有效降低;
例如使用经典的[[Kd-tree]]向量空间索引算法中,同样存在边缘点的问题,Kd-tree会找到最邻近的区域,但是其他区域同样存在可能的最近点;另外Kd-tree的索引结构较为复杂,导致离线和在线的维护也相对复杂;
局部敏感哈希(Locality Sensitive Hashing, LSH)高效地解决了Embedding匹配的问题。
局部敏感哈希基本思想,是将相邻的点落入同一个“桶”,这样在进行最邻近搜索时,仅需要在一个桶内或邻近几个桶内进行搜索,只需要保证每个桶内的元素个数保持在一个较小的范围内;
如下图所示例子,首先需要确定一个结论:在[[欧式空间]]中,将高位空间的点映射到低维空间,原本接近的点在低维空间中肯定依然接近,但原本远离的点则有一定概率变成接近的点。
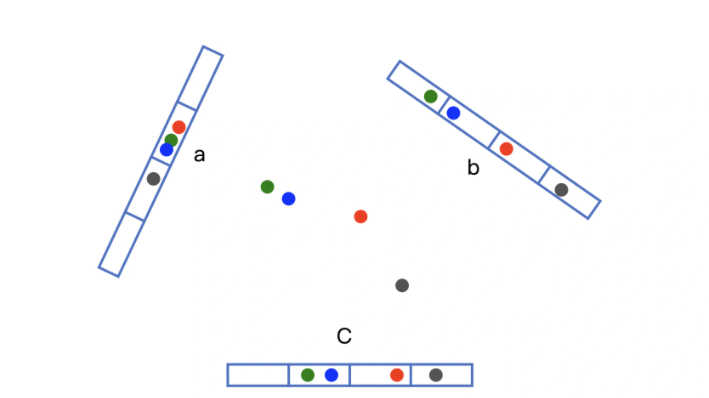
利用上面的低维空间保留高位空间相近距离关系的性质,我们可以设计构造多个“桶”。假设\(v\)是高位空间中的\(k\)维Embedding向量,\(x\)是随机生成的\(k\)维向量,可以得到一个数值\(h(v) = v \cdot x\)。
根据这个数值,我们设计哈希函数\(h(v)\)进行分桶:
上面公式中\(w\)是分桶宽度,\(b\)是0到\(w\)之间的一个均匀分布随机变量,其作用是避免分桶边界固化。为了避免映射操作损失信息,可以使用\(m\)个哈希函数进行分桶,如果同时掉入多个桶,则其相似的概率将会增加。在确定了桶后,就在其有限的集合内进行[[K近邻]]搜索即可。
当存在多个哈希函数的时候,聚合中的点可能以不同的分布方式落在多个桶当中。最简单的就是一个点在匹配的桶中都出现(AND)以及在任意一个桶中出现(OR)两种策略。多桶策略还可以更复杂,比如三个分桶,可以选择同时落入两个桶中的点作为候选点。下面有一些建议的策略:
例如在商品推荐系统中,商品称为(item)有对应的item_id,可以使用以下方案:
在召回的时候,先使用目标item_id找到对应的BucketId,然后再通过BucketId桶中的商品,实际上就是建立[[倒排索引]]的思路。
LSH相比一些朴素的方法,高效地解决了相似向量查找的问题,通过多桶机制减小其哈希分桶的损失;但是也存在一些问题,大数据量情况下哈希函数的个数不好确定,另外在进行哈希计算的时候,可能会存在哈希冲突,导致召回率降低。
此外向量相似查找,还有一些基于树、基于量化、基于图的方法,根据不同的场景也可一试。
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
我使用Nokogiri(Rubygem)css搜索寻找某些在我的html里面。看起来Nokogiri的css搜索不喜欢正则表达式。我想切换到Nokogiri的xpath搜索,因为这似乎支持搜索字符串中的正则表达式。如何在xpath搜索中实现下面提到的(伪)css搜索?require'rubygems'require'nokogiri'value=Nokogiri::HTML.parse(ABBlaCD3"HTML_END#my_blockisgivenmy_bl="1"#my_eqcorrespondstothisregexmy_eq="\/[0-9]+\/"#FIXMEThefoll
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
寻找有用的ruby的好网站是什么? 最佳答案 AgileWebDevelopment列出插件(虽然不是rubygems,我不确定为什么),并允许人们对它们进行评级。RubyToolbox按类别列出gem并比较它们的受欢迎程度。Rubygems有一个搜索框。StackOverflow对最有用的rails插件和rubygems有疑问。 关于ruby-如何搜索有用的ruby,我们在StackOverflow上找到一个类似的问题: https://stacko
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
我有很多这样的文档:foo_1foo_2foo_3bar_1foo_4...我想通过获取foo_[X]的所有实例并将它们中的每一个替换为foo_[X+1]来转换它们。在这个例子中:foo_2foo_3foo_4bar_1foo_5...我可以用gsub和一个block来做到这一点吗?如果不是,最干净的方法是什么?我真的在寻找一个优雅的解决方案,因为我总是可以暴力破解它,但我觉得有一些正则表达式技巧值得学习。 最佳答案 我(完全)不懂Ruby,但类似这样的东西应该可以工作:"foo_1foo_2".gsub(/(foo_)(\d+)/
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu