分为三步:第一步实现网页自动化打开,登录到需巡检的界面,第二步通过截图,保存巡检时状态图,第三步通过接口推送至手机app如企业微信,钉钉等。
第一:selenium环境部署和定位学习:https://blog.csdn.net/qq_54219272/article/details/123310772
第二:selenium使用:https://blog.csdn.net/qq_54219272/article/details/123338773
第三:快速下载vscode:
https://blog.csdn.net/thlchina/article/details/113940283
补充:
Microsoft Edge浏览器驱动安装:打开文件所在位置,可以直接看到版本,再到https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver下载对应驱动(接近版本号即可)
需要提前完成两步:
第一步:完成python、selenium环境部署
第二步:完成浏览器驱动安装
详见:https://blog.csdn.net/qq_54219272/article/details/123310772
# 1、导包/提供python的库
from time import sleep
from selenium import webdriver
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网址(此处可以替换你要巡检的网页)
driver.get('https://www.bilibili.com/')
# 4、操作命令插入到这里
# 5、时间轴看效果,等待3秒
sleep(3)
# 6、关闭页面
driver.quit()
使用方法:
driver.get_screenshot_as_file(imgepath)
#参数:
# imagepath:为图片要保存的目录地址及文件名称
#截图方法,建议使用png格式 , ./为当前路径, ../为上一级路径,如('./info.png')
加入到代码中
# 1、导包/提供python的库
from time import sleep
from selenium import webdriver
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网址(此处可以替换你要巡检的网页)
driver.get('https://www.bilibili.com/')
# 4、操作命令插入到这里
# 4.1、截图
driver.get_screenshot_as_file('./a.png')
# 5、时间轴看效果
sleep(3)
# 6、关闭页面
driver.quit()
import requests
import base64
import hashlib
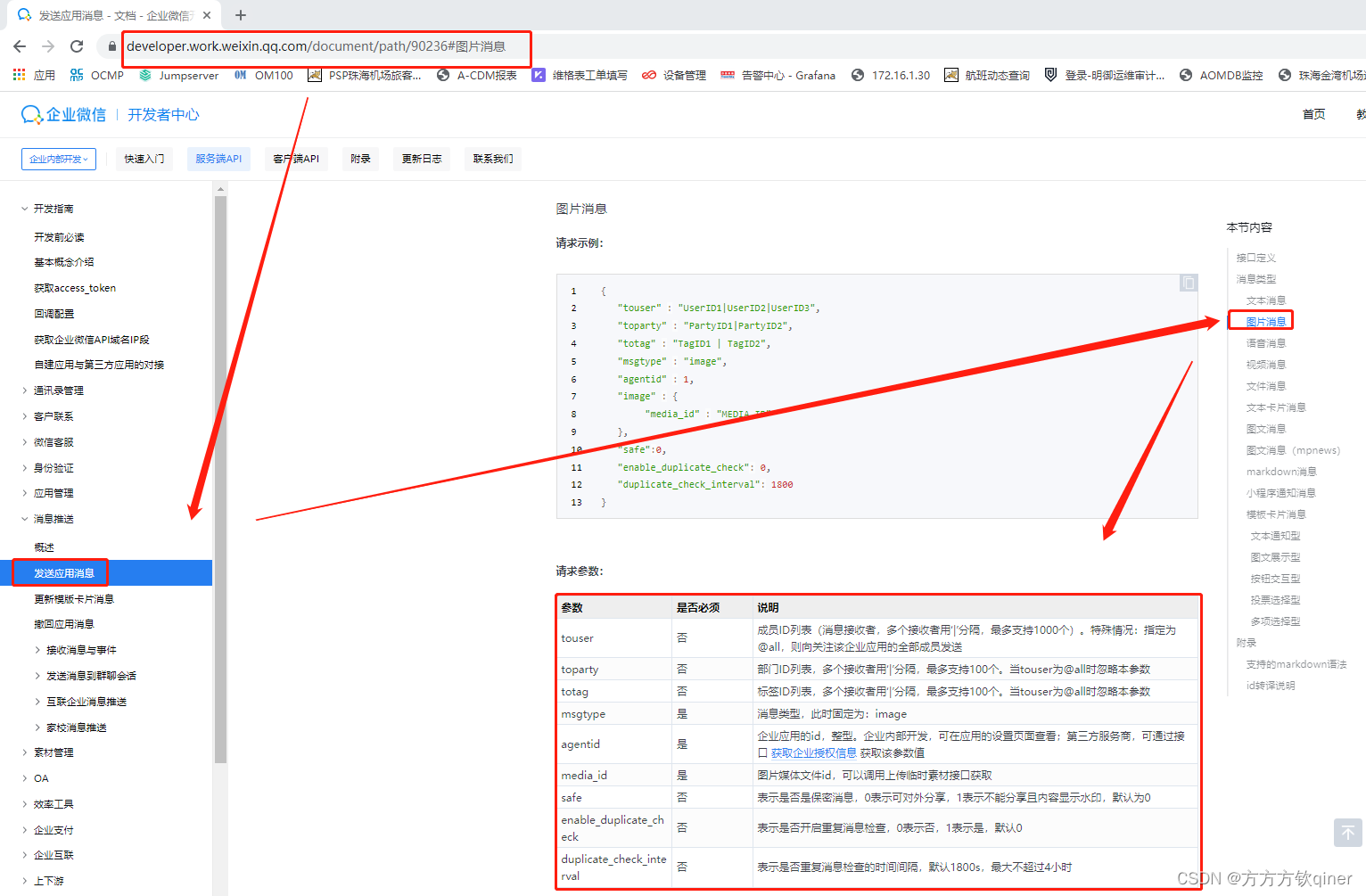
# 图片base64码
with open("./a.png", "rb") as f:
base64_data = base64.b64encode(f.read()).decode()
# base64.b64decode(base64data)
print(base64_data)
# 图片的md5值
file = open("./a.png", "rb")
md = hashlib.md5()
md.update(file.read())
res1 = md.hexdigest()
print(res1)
# 企业微信机器人发送消息
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=f6e7fcfd-ef6c-4145-88ee-3d2eeb3ccXXX"
headers = {"Content-Type": "text/plain"}
data = {
"msgtype": "image",
"image": {
"base64": base64_data,
"md5": res1
}
}
r = requests.post(url, headers=headers, json=data)
print(r.text)
插曲:出现如下报错【TypeError:Object of type bytes is not JSON】

解决方法如下:添加了.decode()
借鉴的文章:https://blog.csdn.net/xyl342300/article/details/109954038,不要轻易运行,不然很容易尴尬
插曲2:

谷歌浏览器的驱动有问题,重装新版的谷歌浏览器就可以解决,下载对应的驱动
插曲3:

将谷歌浏览器的驱动放到python的目录下解决
通过企业微信接口文档-发送文本写出data={ }部分的信息
import requests
# 10、企业微信机器人发送消息:文本消息
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=1bd9d632-1f3b-445d-98e8-429a1d7415ca"
headers = {"Content-Type": "text/plain"}
data = {
"msgtype": "text",
"text": {
"content" : "监控平台界面:正常标准为无异常告警"
}
}
r = requests.post(url, headers=headers)
print(r.text)
存在报错

查询后得知
import requests
# 10、企业微信机器人发送消息:文本消息
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=1bd9d632-1f3b-445d-98e8-429a1d7415xx"
headers = {"Content-Type": "text/plain"}
data = {
"msgtype": "text",
"text": {
"content" : "监控平台界面:正常标准为无异常告警"
}
}
r = requests.post(url,headers=headers,json=data,verify=False)#企业微信群机器人的消息虽然是“text”类型的,但是post发送过去的头部是“application/json”,是json格式的
print(r.text)
成功发送

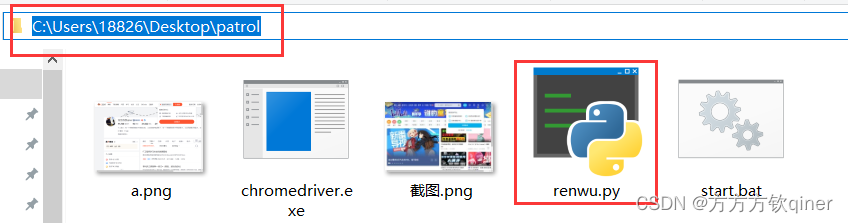
一、bat写法
@C:\Users\18826\AppData\Local\Programs\Python\Python38\python.exe C:\Users\18826\Desktop\patrol\renwu.py %*
上述路径是自身py所在的文件夹决定的,如下图
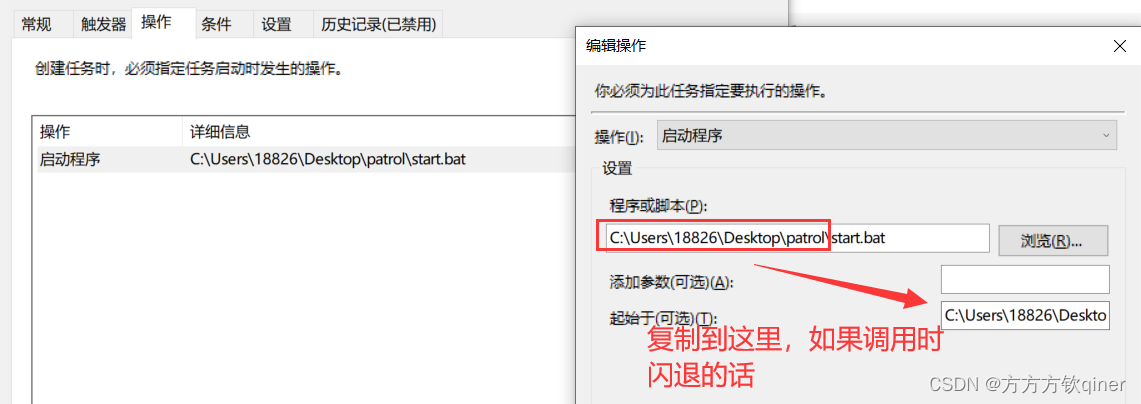
二、window自带的定时任务,需要注意以下更改点


以上满足常规巡检
以下是对维格表尝试登录,但是失败的案例
若需对网页进行操作,需学习:
1、利用元素定位进行网页操作
2、了解浏览器、键盘、鼠标操作
详见:https://developer.work.weixin.qq.com/tutorial/detail/54
常用命令如下:
driver.maximize_window() # 最大化浏览器
加入到代码中
# 1、导包/提供python的库
from time import sleep
from selenium import webdriver
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网址(此处可以替换你要巡检的网页)
driver.get('https://www.bilibili.com/')
# 4、操作命令插入到这里
# 4.1、截图
driver.maximize_window() # 最大化浏览器
# 5、时间轴看效果
sleep(3)
# 6、关闭页面
driver.quit()
此处引入登录维格表,截图发群里通知人执行工作
插曲1:

4.4.3版本无法使用_by_命令,改成4.1.0
pip uninstall selenim
pip install selenim==4.1.0

插曲2:无法定位元素的报错

是由于账号密码界面需要切换,引入鼠标点击
# 定位目标
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN"]/div[1]/div/button/span')
# 实例化 鼠标对象
action = ActionChains(driver)
# 鼠标单击
action.click(ele)
# 鼠标执行操作!!!不执行没效果
action.perform()
顺利切换到如下界面
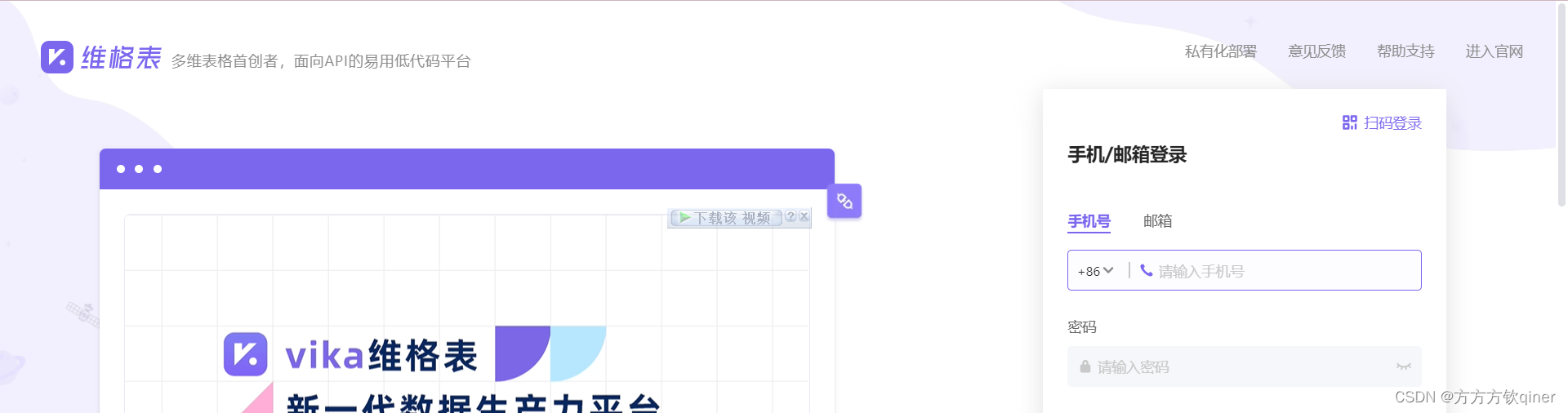
再通过元素定位法
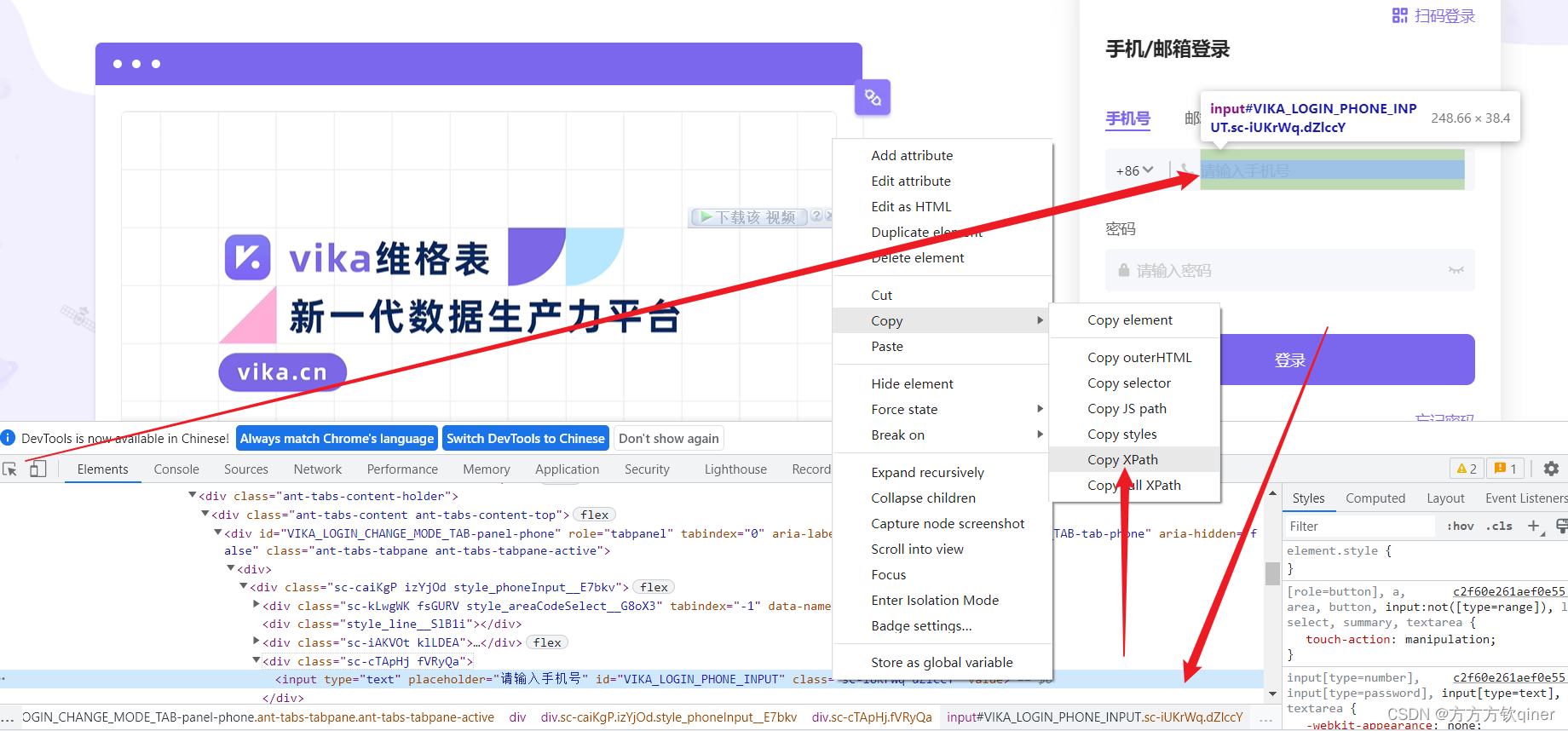
# 5.4、输入账号密码
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN_PHONE_INPUT"]')
ele.send_keys('18826227807')
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN_PASSWORD_INPUT"]')
ele.send_keys('Stqer686')
最后,点击确认
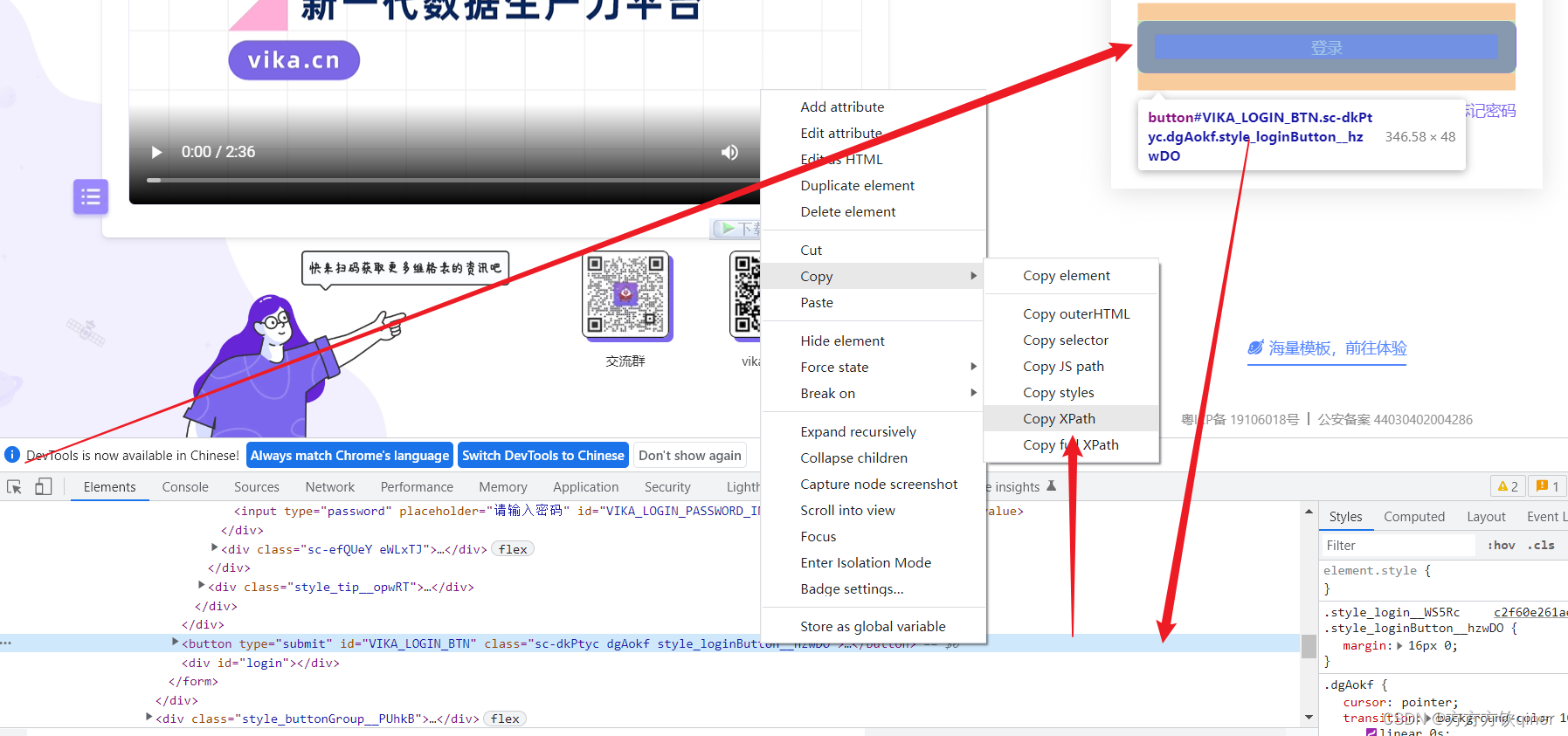
# 5.5、点击
# 定位目标
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN"]/div[1]/div/button/span')
# 实例化 鼠标对象
action = ActionChains(driver)
# 鼠标单击
action.click(ele)
# 鼠标执行操作!!!不执行没效果
action.perform()
但是,最后维格表有防范机制,点击确认后,还是不算登录成功,哭哭
# 1、导包/提供python的库
from time import sleep
from selenium import webdriver
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网址(此处可以替换你要巡检的网页)
driver.get('http://172.16.1.33:3000/d/WojOgXTmk/00-gao-jing-zhong-xin?orgId=1&refresh=5s')
# 4、时间轴看效果
sleep(6)
# 5、操作命令插入到这里
driver.get_screenshot_as_file('./a.png') #截图
driver.maximize_window() # 最大化浏览器
# 6、关闭页面
driver.quit()
import requests
import base64
import hashlib
# 7、图片base64码:提供给企业微信发送图片信息所需
with open("./a.png", "rb") as f:
base64_data = base64.b64encode(f.read()).decode()
# base64.b64decode(base64data)
print(base64_data)
# 8、图片的md5值
file = open("./a.png", "rb")
md = hashlib.md5()
md.update(file.read())
res1 = md.hexdigest()
print(res1)
# 9、企业微信机器人发送消息:提供给企业微信发送图片信息所需
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=1bd9d632-1f3b-445d-98e8-429a1d7415xx"
headers = {"Content-Type": "text/plain"}
data = {
"msgtype": "image",
"image": {
"base64": base64_data,
"md5": res1
}
}
r = requests.post(url, headers=headers, json=data)
print(r.text)
# 1、导包/提供python的库
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
# 2、实例化浏览器对象:类名()
driver = webdriver.Chrome()
# 3、打开网址(此处可以替换你要巡检的网页)
driver.get('https://vika.cn/workbench/mirPTLa3fERa5Vt3Jt/dstyWW2rd6RgoKBxml/viwPVtNmkrHSC')
# 4、时间轴看效果
sleep(5)
# 5、操作命令插入到这里
# 5.1、最大化
driver.maximize_window() # 最大化浏览器
# 5.2、截图
driver.get_screenshot_as_file('./a.png')
# 5.3、鼠标单击切换到账号密码登录界面
# 5.3.1、点击“手机/邮件登录”按钮
# 定位目标
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN"]/div[1]/div/button/span')
# 实例化 鼠标对象
action = ActionChains(driver)
# 鼠标单击
action.click(ele)
# 鼠标执行操作!!!不执行没效果
action.perform()
# 5.3.2、点击“密码登录”按钮
# 定位目标
ele = driver.find_element_by_xpath('//*[@id="VIKA_CHANGE_MODE_BTN"]/span')
# 实例化 鼠标对象
action = ActionChains(driver)
# 鼠标单击
action.click(ele)
# 鼠标执行操作!!!不执行没效果
action.perform()
# 5.4、输入账号密码
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN_PHONE_INPUT"]')
ele.send_keys('18826227807')
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN_PASSWORD_INPUT"]')
ele.send_keys('Stqer686')
# 5.5、点击“确认”按钮
# 定位目标
ele = driver.find_element_by_xpath('//*[@id="VIKA_LOGIN"]/div[1]/div/button/span')
# 实例化 鼠标对象
action = ActionChains(driver)
# 鼠标单击
action.click(ele)
# 鼠标执行操作!!!不执行没效果
action.perform()
# 6、时间轴看效果
sleep(20)
# 7、关闭页面
driver.quit()
import requests
import base64
import hashlib
# 8、图片base64码:提供给企业微信发送图片信息所需
with open("./a.png", "rb") as f:
base64_data = base64.b64encode(f.read()).decode()
# base64.b64decode(base64data)
print(base64_data)
# 9、图片的md5值
file = open("./a.png", "rb")
md = hashlib.md5()
md.update(file.read())
res1 = md.hexdigest()
print(res1)
# 10、企业微信机器人发送消息:提供给企业微信发送图片信息所需
url = "https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=1bd9d632-1f3b-445d-98e8-429a1d7415ca"
headers = {"Content-Type": "text/plain"}
data = {
"msgtype": "image",
"image": {
"base64": base64_data,
"md5": res1
}
}
r = requests.post(url, headers=headers, json=data)
print(r.text)
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
我想知道是否可以通过自动创建数组来插入数组,如果数组不存在的话,就像在PHP中一样:$toto[]='titi';如果尚未定义$toto,它将创建数组并将“titi”压入。如果已经存在,它只会推送。在Ruby中我必须这样做:toto||=[]toto.push('titi')可以一行完成吗?因为如果我有一个循环,它会测试“||=”,除了第一次:Person.all.eachdo|person|toto||=[]#with1billionofperson,thislineisuseless999999999times...toto.push(person.name)你有更好的解决方案吗?
电脑上可以截取图片吗?如果可以,该如何操作呢?相信很多小伙伴都只知道一两种截图的方式,知道的并不全面。其实,电脑上有多种方式截图的,而且非常方便。电脑怎么截图?今天我们就来教大家如何使用电脑截取图片的8种常用方式!操作环境:演示机型:Delloptiplex7050系统版本:Windows10方法一:系统自带截图具体操作:同时按下电脑的自带截图键【Windows+shift+S】,可以选择其中一种方式来截取图片:截屏有矩形截屏、任意形状截屏、窗口截屏和全屏截图。 方法二:QQ截图具体操作:在电脑登录QQ,然后同时按下【Ctrl+Alt+A】,可以任意截图你需要的界面,可以把截图的页面直接下载,