目录
🦖 3.3.1 怎么判定某个对象是否是垃圾 (引用计数/可达性分析)
🦖 3.3.2 具体是怎么回收的 (标记清除/复制算法/标记整理/分代回收)
JVM是一个比较大的话题,但面试主要从这三个方面考
- JVM 内容划分
- JVM 类加载
- JVM 的垃圾回收
Java程序, 就是一个名字为 Java 的进程. 这个进程就是所说的 "JVM"
JVM 就会先从操作系统这里申请一大块内存空间,在这个基础上再把这个内存空间划分成几个小的区域
区域划分:
- 堆: 放的是 new 的对象
- 方法区: 放的是 类对象 (加载好的类)
- 栈: 放的是方法之间的调用关系 (虚拟机栈: java 里面用来保存调用关系的内存空间; 本地方法栈: 本地方法,也就是 JVM 内部 C++ 写的代码,调用关系的内存空间)
- 程序计数器: 放的是下一个要执行的指令的地址

Java 程序在运行之前,需要先编译 .java --> .class文件(二进制字节码文件)
运行的时候, .java进程(JVM) 就会读取对应的 .class文件,并且解析内容,在内存中构造出类对象并进行初始化
类 从 文件 加载到 内存 中
类对象: 在前面中类对象出现在反射,jackson,synchronized 中
主要就是描述了这个类是啥样子的
有哪些属性(属性名字,类型,private/public)
有哪些方法(方法名字,参数个数,类型,返回值类型,private/public)
继承自哪个父类,实现哪些接口
类对象也是创建实例的具体依据
1. 加载: 找到 .class 文件,读取文件内容, 并且按照 .class 规范的格式来解析
2. 连接
1. 验证: 检查看当前的 .class 里的内容格式是否符合要求
(不同版本的 JDK 得到的 .class 是不兼容的)
2. 准备: 给类中的静态变量分配内存空间
3. 解析: 初始化字符串变量,把 符号引用(占位符) 替换成 直接引用(内存地址)
3. 初始化: 针对类进行初始化, 初始化静态成员, 执行静态代码块, 并且加载父类
使用到一个类的时候,就触发类加载
(类并不一定是程序一启动就加载了,而是第一次使用才加载 [有点类似于懒汉模式])
使用一个类,这里指的是
- 创建这个类的实例
- 使用了类的静态方法 / 静态属性
- 使用类的子类 (加载子类会触发加载父类)
决定了按照啥样的规则来在哪些目录里去找 .class 文件
也就是描述了加载器相互配合的工作过程,就是双亲委派模型
JVM 加载类, 是由 类加载器 (class loader) 这样的模块来负责的
JVM 自带了多个类加载器,每个类加载器各自负责一个区域
- Bootstrap ClassLoader (负责加载标准库中的类)
- Extension ClassLoader (负责加载 JVM 扩展库的类(语言规范中没有,但是JVM实现的))
- Application ClassLoader (负责加载我们自己项目中的自定义的类)

按照这样的顺序加载, 最大的好处在于
如果我们自己写个类,刚好 全限定类名和标准库中的类名冲突了,(比如我们自己写个类就叫,java.lang.Thread)
此时仍然可以保证类加载时,可以加载到标准库的类,防止代码加载错了带来问题
GC (垃圾回收) 是一个主流的内存回收的方案, Java/Python/JS/GO/PHP 都是使用GC
我们只需要负责申请内存, 而释放内存的工作, 交给 JVM 来完成, JVM 会自动判定当前的内容是啥时候需要释放, 当认为这个内存不再使用了, 就自动释放了

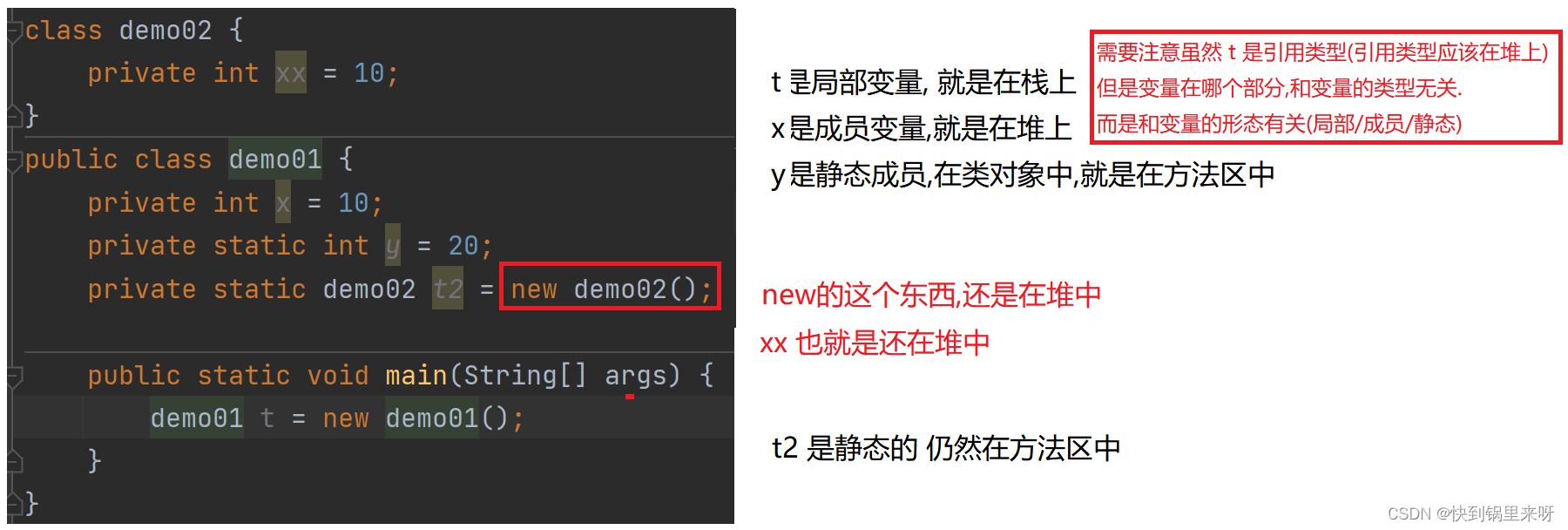
JVM 主要内存分为这几个部分
- 堆 : 存放的时 new 的对象 (GC 主要就是针对堆来进行回收)
- 栈 : 保存方法之间的调用关系(释放时机确定, 不必回收)
- 方法区 : 放的是 类对象 (类加载, 加载之后也不太会卸载)
- 程序计数器 : 保存下一条要执行的指令地址 (固定内存空间, 不必回收)
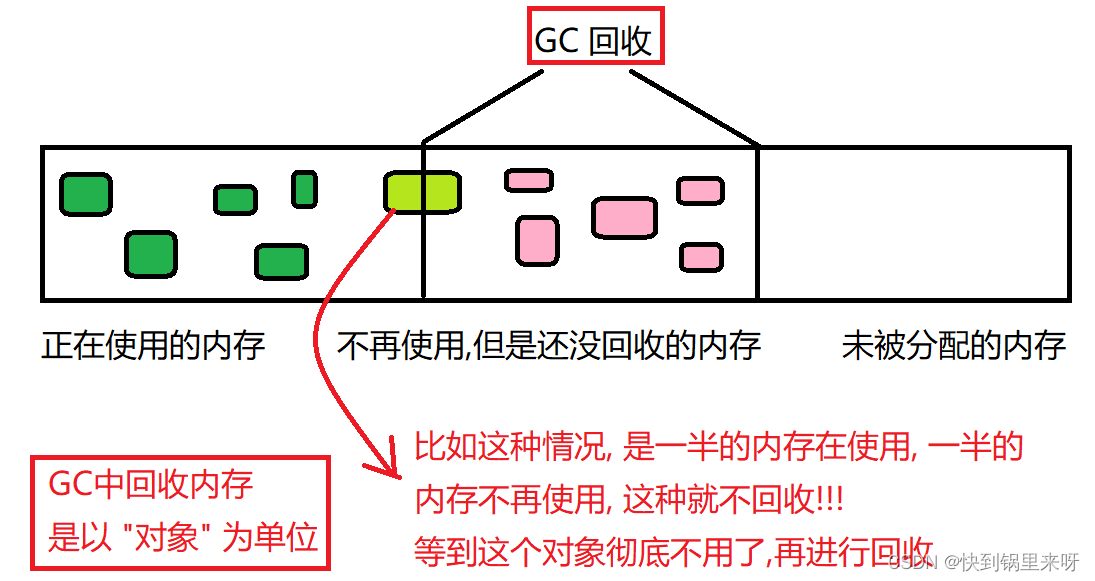
- 先找出垃圾 (看看谁是垃圾)
- 再回收垃圾 (释放内存)
如果一个对象不再用了,就说明是垃圾了
在 Java 中,对象的使用,需要凭借 引用
假设如果有一个对象,已经没有任何引用能够指向他了,这个对象自然也就无法再被使用了
所以最关键的要点就是:
通过引用来判定当
前对象是否还能被使用了,没有引用指向就视为是无法被使用
两种常见的,判定对象是否存在引用的方法
1. 引用计数 [不是 JVM 采取的方法, 比如 Python,PHP]
给每个对象都加上个计数器,这个计数器就表示 "当前的对象有几个引用"
当引用计数器, 数值为 0 时, 就说明当前这个对象已经无人能够使用了,此时就可以进行释放了
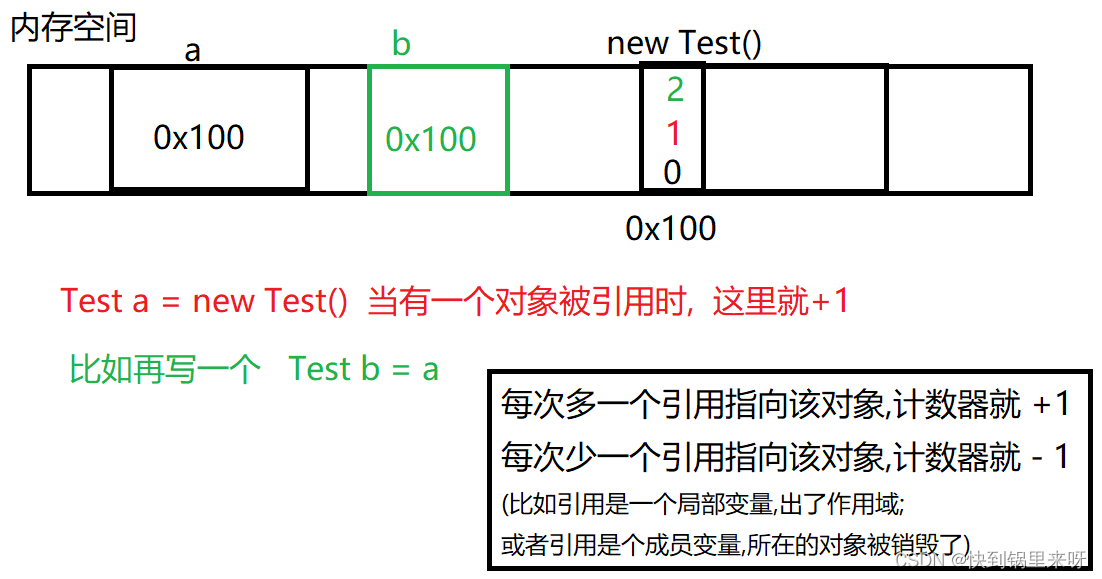
引用计数的优点: 简单,容易实现,执行效率比较高
缺点:
(1) 空间利用率比较低, 尤其是小对象
(比如,计数器是个 int, 如果你的对象本身里面只有一个 int 成员,利用率低)
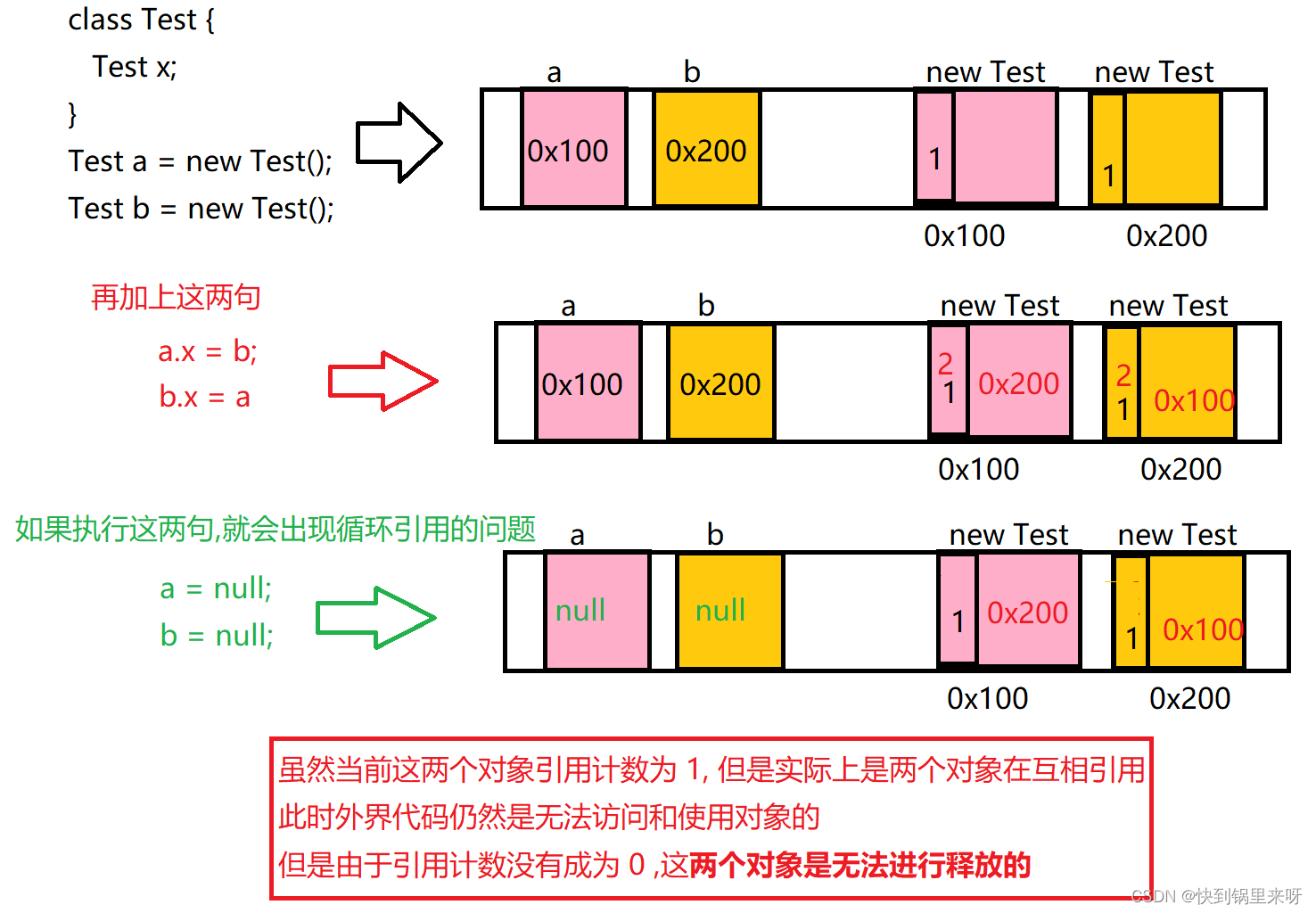
(2) 可能会出现循环引用的情况
2. 可达性分析 [是 JVM 采用的方法, java]
约定一些特定的变量,成为 "GC roots"
每隔一段时间,从 GC toots 出发, 进行遍历, 看看当前哪些变量是能够被访问到的
能被访问到的遍历就称为是 "可达" (否则就是 "不可达")
- 标记清除
- 复制算法
- 标记整理
- 分代回收
(1) 标记清除

这种方式有一个最大的问题: 内存碎片
会导致整个内存 "支离破碎"
比如假设上述每个深色的区域是 1k,此时整个有 4k 空闲空间,但是由于此时内存是分散的,导致如果想申请 2k 的内存空间,是申请不了的
(2) 复制算法
复制算法,可以很好的解决 标记清除 带来的 内存碎片问题
但是 复制算法 的缺点是:
- 空间利用率更低了 (用一半丢一半)
- 如果一轮 GC 过去,大部分对象要保留,只有少部分对象要回收,此时这个复制的开销就很大了
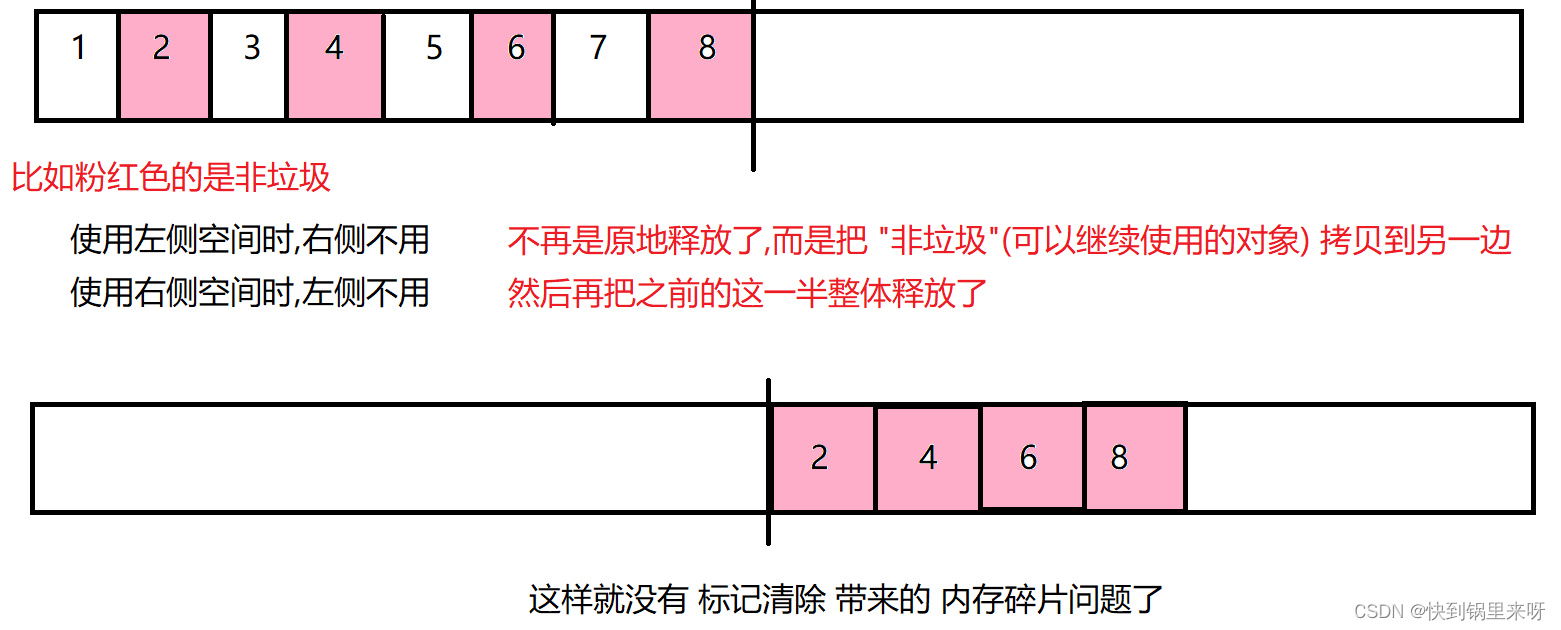
(3) 标记整理
类似于 顺序表 删除元素, 标记整理主要就是 搬运操作
这个方式,相对于上述的复制算法来说,空间利用率比之前高,同时也还是能够解决内存碎片问题,但是搬运操作是比较耗时的

(4) 分代回收
上面的三种方式,都是很非常好的方法,都有各自的特点
所以就需要根据实际的场景,选择对应的解决方法
这就有了 "分代回收" 的策略, 就是把上面的方法都综合在一起
根据对象不同的特点,采取不同的回收方式
这里的根据对象不同的特点: 是根据对象的年龄(依据 GC 的轮次来算的)来划分的
有一组线程,周期性的扫描代码中所有的对象,如果一个对象,经历了一次 GC 没有被回收,就认为年龄 +1
根据对象的年龄进行分类,把堆中的对象分为了,
新生代(年龄小的对象) 和 老年代 (年龄大的对象)

但是还有个特殊情况就是
如果对象是一个非常大的对象,则直接进入老年代
因为对一个大的对象进行复制算法,开销太大了
并且这是一个比较大的对象, 既然能创建这么大的对象,那肯定也不是立即就销毁的
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序
我一直致力于让我们的Rails2.3.8应用程序在JRuby下正确运行。一切正常,直到我启用config.threadsafe!以实现JRuby提供的并发性。这导致lib/中的模块和类不再自动加载。使用config.threadsafe!启用:$rubyscript/runner-eproduction'pSim::Sim200Provisioner'/Users/amchale/.rvm/gems/jruby-1.5.1@web-services/gems/activesupport-2.3.8/lib/active_support/dependencies.rb:105:in`co
我们目前正在为ROR3.2开发自定义cms引擎。在这个过程中,我们希望成为我们的rails应用程序中的一等公民的几个类类型起源,这意味着它们应该驻留在应用程序的app文件夹下,它是插件。目前我们有以下类型:数据源数据类型查看我在app文件夹下创建了多个目录来保存这些:应用/数据源应用/数据类型应用/View更多类型将随之而来,我有点担心应用程序文件夹被这么多目录污染。因此,我想将它们移动到一个子目录/模块中,该子目录/模块包含cms定义的所有类型。所有类都应位于MyCms命名空间内,目录布局应如下所示:应用程序/my_cms/data_source应用程序/my_cms/data_ty
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
如何只加载map边界内的标记gmaps4rails?当然,在平移和/或缩放后加载新的。与此直接相关的是,如何获取map的当前边界和缩放级别? 最佳答案 我是这样做的,我只在用户完成平移或缩放后替换标记,如果您需要不同的行为,请使用不同的事件监听器:在你看来(index.html.erb):{"zoom"=>15,"auto_adjust"=>false,"detect_location"=>true,"center_on_user"=>true}},false,true)%>在View的底部添加:functiongmaps4rail
我需要做这样的事情classUser'User',:foreign_key=>'abuser_id'belongs_to:gameendclassGame['JOINabuse_reportsONusers.id=abuse_reports.abuser_id','JOINgamesONgames.id=abuse_reports.game_id'],:group=>'users.id',:select=>'users.*,count(distinctgames.id)ASgame_count,count(abuse_reports.id)asabuse_report_count',: