Mooncake是得物API一站式协作平台。从2022年3月份开始负责Mooncake,到现在已经一年了,回顾这一年,Mooncake大的阶段上,总共经历过两个版本:
1、Mooncake 1.0: 面向前端和客户端的mock平台,主要解决接口调用者的数据mock问题
2、Mooncake 2.0: 面向前后端的,融合了yapi和mock的一站式文档管理平台,从供需两端解决接口文档的流通效率问题
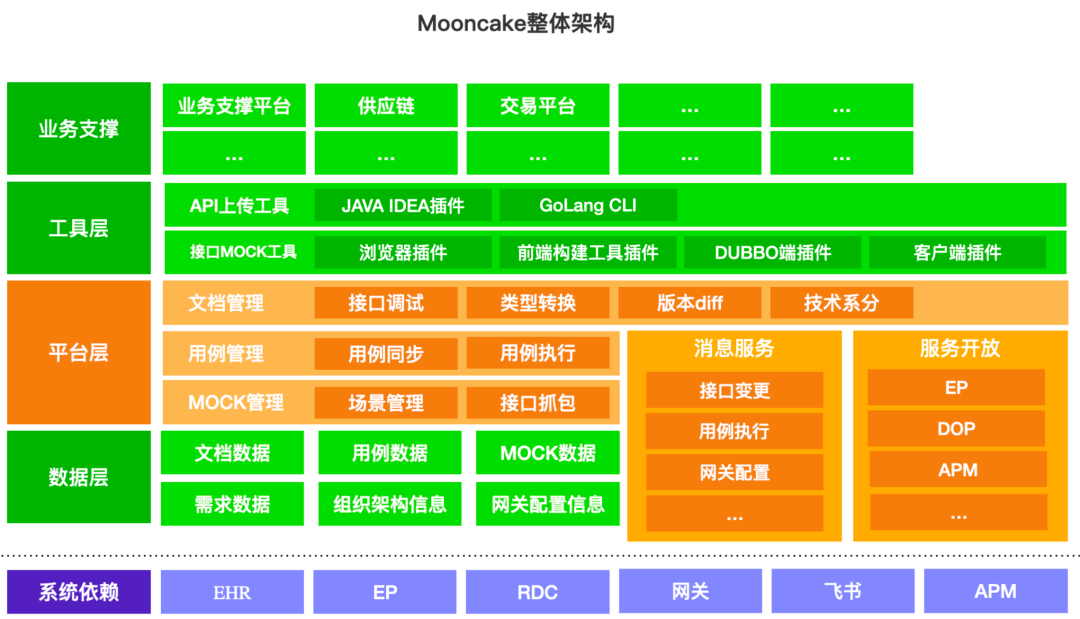
升级后的Mooncake产品架构如下:
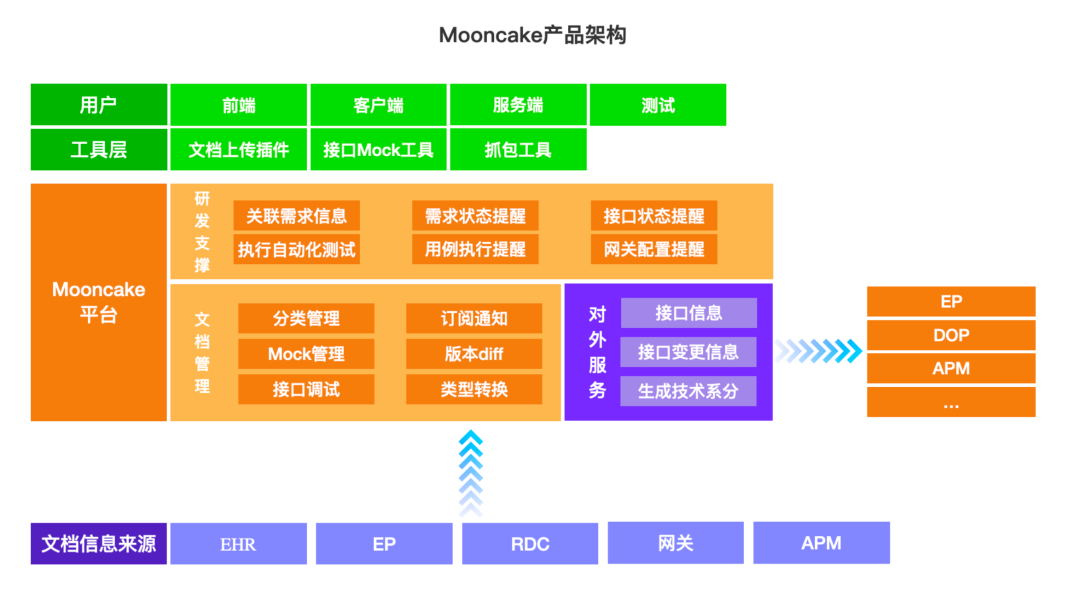
如上图所示,我们希望Mooncake是得物研发生态系统中的重要一环,为了实现这个目标,Mooncake不断推陈出新,发布了许多重要功能,例如支持染色环境调试、业务迭代信息报表、支持Dubbo协议的mock等;打通了RDC、EP、CMDB、网关等平台。此外,Mooncake还提供了openAPI,向外生长,支持EP、DOP、APM等平台,让开发同学在研发的各个阶段都能方便的通过文档进行顺畅的交流。
在这个过程当中,Mooncake具体做了什么,又为什么这么做,做了之后有什么用,针对这几个问题我简单的说一下我自己的思考。
2002年贝索斯曾经给亚马逊颁布了一份mandate,这份指令是这样的:
从今天起,所有的团队都要以服务接口的方式,提供数据和各种功能。
团队之间必须通过接口来通信。
不允许任何其他形式的互操作:不允许直接链接,不允许直接读其他团队的数据,不允许共享内存,不允许任何形式的后门。
唯一许可的通信方式,就是通过网络调用服务。
具体的实现技术不做规定,HTTP、Corba、PubSub、自定义协议皆可。
所有的服务接口,必须从一开始就以可以公开作为设计导向,没有例外。这就是说,在设计接口的时候,就默认这个接口可以对外部人员开放,没有讨价还价的余地。
不遵守上面规定者,一律开除。
谢谢;祝你过得愉快!
这份指令的出发点是,贝索斯认为人际沟通往往会造成组织执行不力,而他解决这个问题的方式,就是通过API,系统性的规范组织间的对话。
这个其实在当下很普遍的微服务架构之下,已经不是什么新鲜事了,还有我们大量使用三方开放API,这些都是通过API来完成系统间的调用;
但是在当时,如何让人们接受这个方案,积极的参与进来,同时也预防API泛滥,是个很大的问题。为此贝索斯建立了一套指标体系,通过激励最终形成一套正向的持续演进和迭代循环。
这套指标体系,我们可以理解为是一种公司或者组织层面的基建。
1934年,美国经济大萧条时期,罗斯福解决经济危机的两大新政之一的以工代赈,通过大兴基建的方式,刺激消费与生产均衡。
为什么罗斯福选择通过基建的方式来提振经济,其原因跟贝索斯这套指标体系是一样的原因。在兰小欢《置身事内:中国政府与经济发展》一书中提到,基建有三个特点:
1、扩展公共服务的规模 产生规模效益
2、提高信息沟通效率 降低信息复杂性
3、增强各方对资源的竞争 产生激励
由此可见,基建是可以降本增效,并且帮助组织形成一个正向的循环。
2022年3月份之前,得物通过Yapi平台,沉淀的HTTP接口有数万个,这是过去七年间得物自然增长的API数量,这已经是一个很庞大的数字,但是在这些http接口背后,还有数量更加庞大的rpc接口散落在语雀、飞书,更有大量的接口没有文档沉淀,在历史中默默发挥着余热。
那么如何让文档规范起来,如何让更多的开发同学把接口统一起来,如何让数量庞大的接口文档发挥更大的价值,Mooncake从三个方面提供服务做了一次升级:
1、从单一mock服务升级为围绕接口文档的一站式协作平台,用户从前端和客户端扩展到服务端、测试、前端、客户端
2、围绕接口研发生命周期,通过插件、飞书消息、一键mock、一键配置网关等一系列工具,提高信息沟通效率,降低前后端沟通复杂度
3、关联rdc提供迭代和团队两个维度的数据看板,通过文档质量分统计来刺激内部竞争,进而推动产出更高效的文档
接下来我从设计和技术两个层面简单回顾一下Mooncake这次升级都是如何做的。
Mooncake的升级,我们遵循了尼尔森的十大设计理念:
系统要在适当的时间内给予用户恰当的反馈,始终让用户知道当前正在发生什么。
——尼尔森
可以理解为包括⽤户在⻚⾯上的任何操作,系统需要给出相应的反馈,来确保⽤户在操作过程中的状态可⻅、变化可⻅、内容可⻅,从⽽帮助⽤户将交互引导到正确的⽅向,⽽不会浪费精⼒。
Mooncake通过按钮、消息提示的即时反馈,来响应用户的操作:


系统要使用用户的语言,用户熟悉的单词、短语和概念,而不是系统术语。遵循现实世界的约定,使信息以自然和合乎逻辑的顺序出现。 ——尼尔森
⽤户会习惯⽤现实世界中已有认知来看待问题,这个已有认知是⽤户根据⾃⼰掌握的经验、知识和想象所建⽴的⼼智模型。
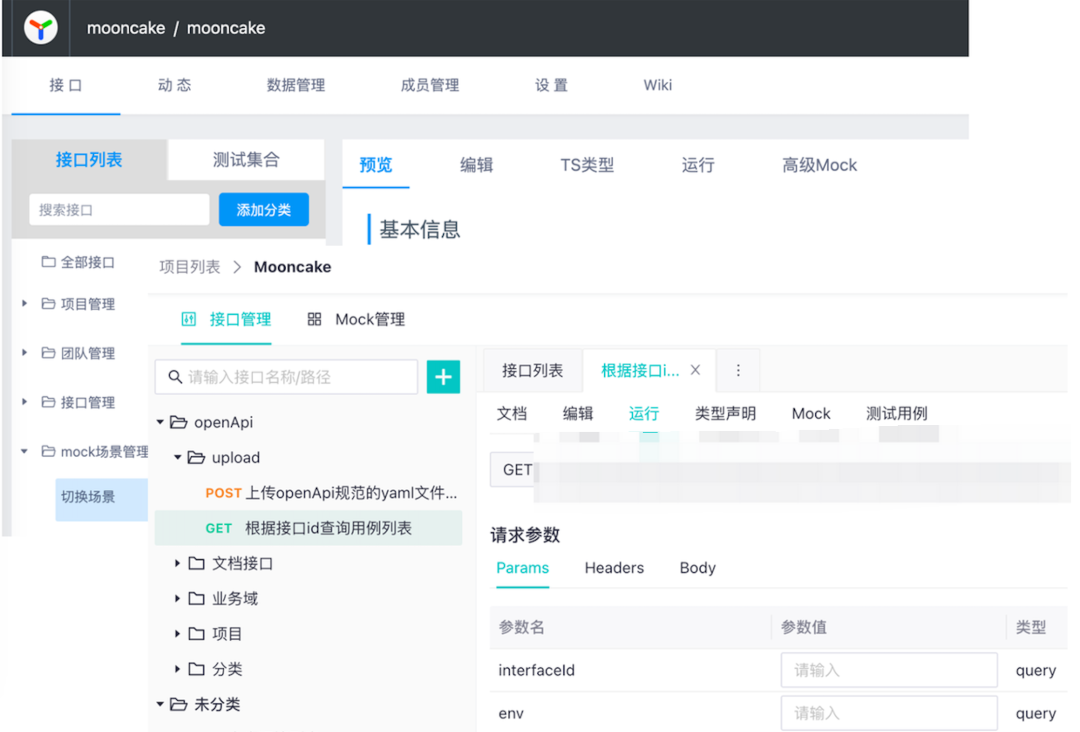
Mooncake这次升级,融合了Yapi和Mock,除了技术底层在数据上的融合,交互上,也尽可能的保留了原有的交互习惯,比如通过idea上传文档的习惯,比如按照文档、编辑、运行、类型声明去组织页面tab:
当用户错误地选择了的某个功能后,系统需要提供一个明确的「紧急出口」,来让用户离开其不想要的状态,而且无需额外的对话框,支持撤销和重做。
——尼尔森
Mooncake里,通过多tab的形式,方便用户打开多个接口文档,而无需频繁的刷新页面:

我们不应当让用户去怀疑不同的语句、状态或操作是否在表达同一件事,设计需遵循平台的惯例。
——尼尔森
⼀致性可以给⽤户统⼀的认知,帮助⽤户快速学习、记忆和熟悉产品的功能,从⽽建⽴⽤户稳定的⼼智模型。为了保障产品间的⽤户体验统⼀,通常都需要建⽴设计规范,来确保产品内部的⼀致性,这里的⼀致性包括视觉⼀致性、⾏为⼀致性和感知⼀致性。
Mooncake这次升级,字体、颜色、尺寸布局、组件库都遵循了得物设计体系规范:
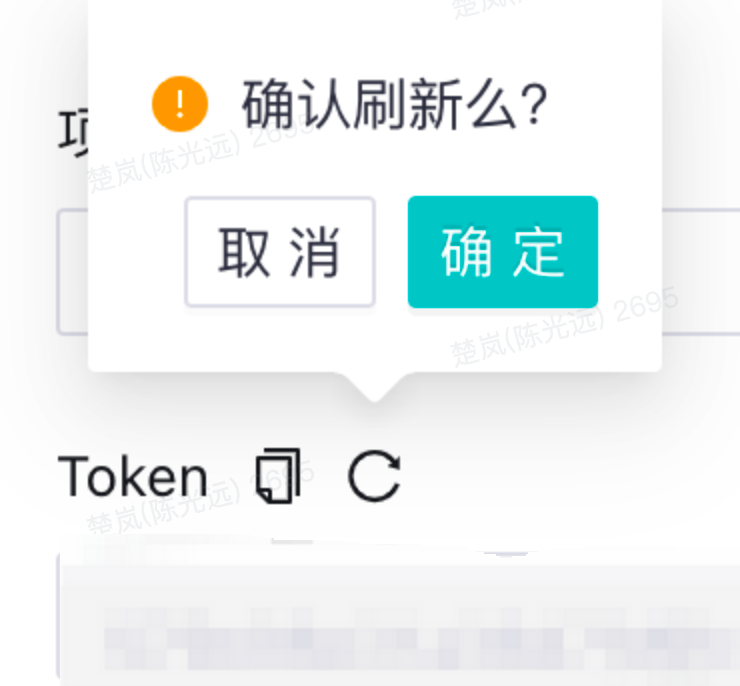
比报错提示更好的方法是,通过严谨的设计来防止错误的发生:要么消除容易出错的情况,要么把这些容易出错的情况找出来,并在用户采取行动之前提供确认选项。
——尼尔森
当操作不可逆时,给予⽤户⼆次确认的机会,避免⽤户由于误操作造成的后果:
通过将对象、操作和选项进行可视化,最大限度地减轻用户的记忆负担,用户不需要记住对话框中某一部分到另一部分的信息,系统操作的指示信息需要易于被用户发现和获取。
——尼尔森
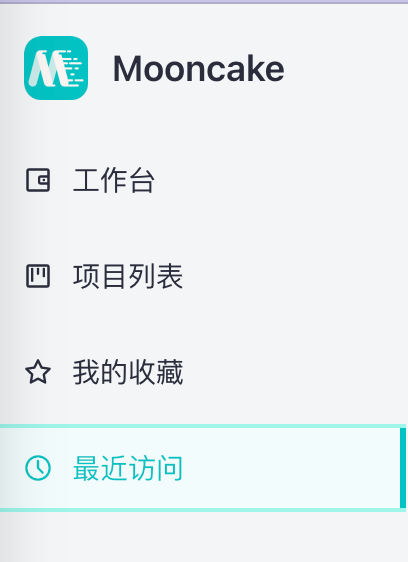
⽤户是不可能记住操作过程中的过多信息的,Mooncake提供了我的收藏和最近访问帮助同学们快速找到自己常用的项目文档:
一些快捷操作的功能,虽然会被新手用户忽略,但可能为专家用户所使用并帮助提升其使用效率,因此,系统需要同时满足新手用户和专家用户的需求,允许用户频繁地操作。
——尼尔森
这⼀点其实是在B端产品设计中⽐较容易忽视的⼀个原则,我们往往默认使⽤产品的是相对成熟的产品使⽤者。
Mooncake的菜单栏提供折叠和展开两种模式,并且会记住用户上次的选择,对于新同学,默认展开菜单,方便了解平台的功能;对于已经熟悉Mooncake 的同学可以收起菜单,文档的可视区域最大化,方便阅读:

对话框中不应包含无关或很少用到的信息,在对话框中每增加一个信息,就意味着降低了主要信息的相对可见性。
——尼尔森
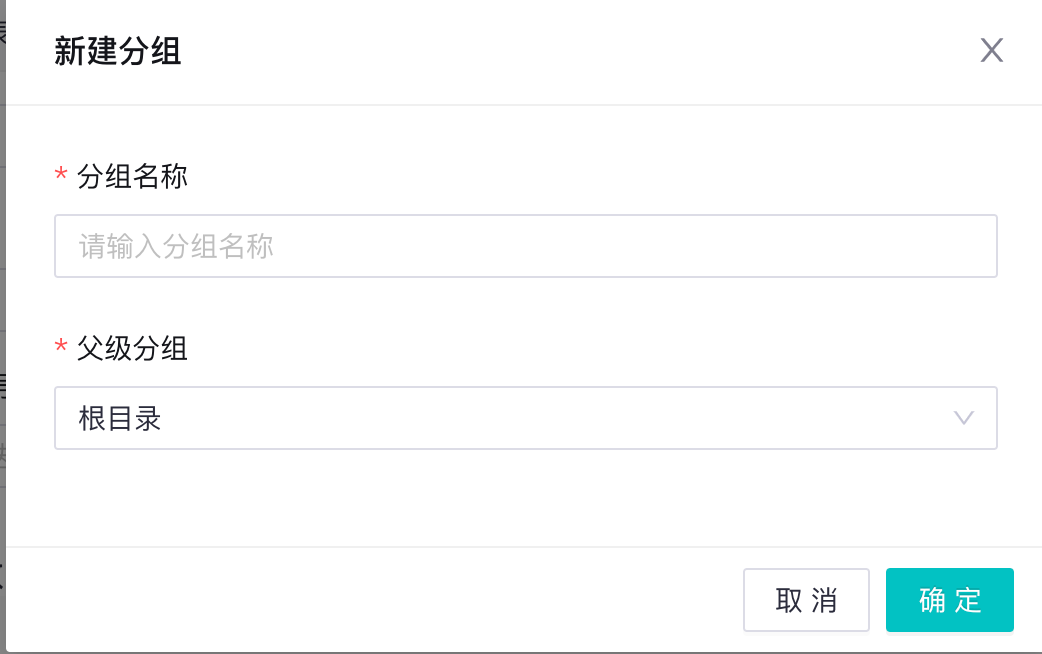
Mooncake的对话框,都尽可能的降低复杂度,一次只做一件事情,一次只搜集最重要的数据,并且尽可能的提供下拉选框减少用户输入:
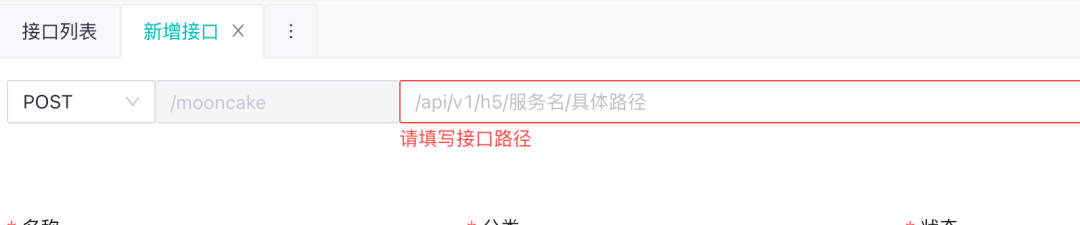
报错信息应该用通俗易懂的语言表达,而不是用代码,准确地反应问题,并且提出可行的解决方案。 ——尼尔森
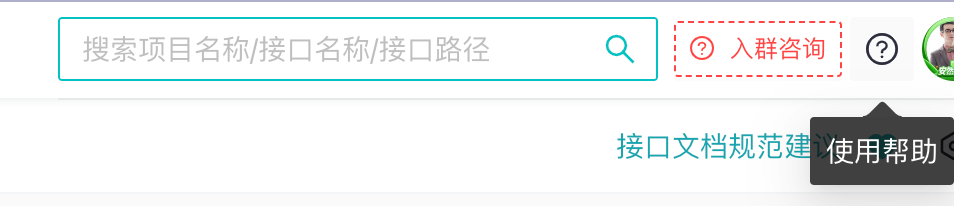
帮助文档的信息应该易于被搜索,聚焦于用户的任务,并列出具体的步骤,而且,不能太庞大。
——尼尔森
Mooncake提供全局搜索、一键进飞书答疑群、自助帮助文档帮助同学快速的找到文档,定位问题:
在这次升级之前,我们调研了一些业界关于API管理的实践,总的来说包含两大块内容:工具和平台。
工具是轮子,解决当下的问题,是生产力工具;
Mooncake 提供了一系列工具:
1、针对java开发的IDEA插件,针对golang开发的CLI工具,帮助开发同学快速的上传文档
2、覆盖 webpack、vite以及浏览器的代理插件,帮助前端同学方便的实现数据mock
3、覆盖iOS和android的客户端代理工具,帮助客户端同学mock数据
4、覆盖前端和客户端的抓包工具,用来快速的生成mock数据
平台的作用就是,通过一系列的资源整合,让平台内的资源互相作用,不断的磨合,创造出新的生产力工具。
在Mooncake平台化的过程中,遵循了两个原则:
第一是多元多维。这个概念来自穷查理宝典,Mooncake 融合打通了EP、CMDB、RDC、网关等平台,最大限度的发挥文档的价值,也最大限度的降低研发同学在API沟通上的成本。
第二分而治之,各个击破。架构本身是解决问题的过程,问题太复杂了,只能采用分而治之的办法。
怎么分?利用金字塔原理,同时在数据化上做思考,之后按照架构主题做拆分。Mooncake平台分为文档、用例、Mock三大块,围绕这三大块进行升级和优化。同时按照组织架构和迭代,进行数据统计和分析,提供各种指标帮助研发同学衡量项目的文档质量。
怎么击破?Mooncake采用了分层架构,优先解决文档的问题,围绕文档做深度;在解决了文档问题之后,在文档上下游和用例上持续迭代优化,通过openAPI的方式拓宽平台广度。
如果说Mooncake 1.0是青铜时代,2.0是白银时代,那么接下来一定是Mooncake的黄金时代。
1.0的Mooncake 覆盖了得物前端平台所有用户,以及接近50%的客户端用户。
2.0时代的Mooncake融合了yapi+mock,同时打通rdc、EP、网关平台等平台,在研发流程的各个阶段提供接口文档服务,共沉淀了数万接口,覆盖了得物技术部90%的研发同学,平台的NPS也一度达到57%。
目前的API建设、平台研发都还有很多问题:
1、在进度压力下,一些因为侥幸心理而遗留的技术债,比如网关环境和项目环境的切换,比如swagger定时扫描等等
2、一些屈从于短期目标的方案,比如简单版本的diff功能,比如简单版本的文档迁移功能等等
3、一些因为路径过长而放弃的远大目标,比如dubbo的调试,比如文档驱动开发等等
未来Mooncake还可以做很多,关于API体系建设、关于平台化、关于开放,Mooncake将不断推进产品和技术的创新和升级,为技术部的小伙伴提供更好的产品和服务。
我有用于控制用户任务的Rails5API项目,我有以下错误,但并非总是针对相同的Controller和路由。ActionController::RoutingError:uninitializedconstantApi::V1::ApiController我向您描述了一些我的项目,以更详细地解释错误。应用结构路线scopemodule:'api'donamespace:v1do#=>Loginroutesscopemodule:'login'domatch'login',to:'sessions#login',as:'login',via::postend#=>Teamroutessc
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
我正在使用Mandrill的RubyAPIGem并使用以下简单的测试模板:testastic按照Heroku指南中的示例,我有以下Ruby代码:require'mandrill'm=Mandrill::API.newrendered=m.templates.render'test-template',[{:header=>'someheadertext',:main_section=>'Themaincontentblock',:footer=>'asdf'}]mail(:to=>"JaysonLane",:subject=>"TestEmail")do|format|format.h
我正在尝试使用Ruby2.0.0和Rails4.0.0提供的API从imgur中提取图像。我已尝试按照Ruby2.0.0文档中列出的各种方式构建http请求,但均无济于事。代码如下:require'net/http'require'net/https'defimgurheaders={"Authorization"=>"Client-ID"+my_client_id}path="/3/gallery/image/#{img_id}.json"uri=URI("https://api.imgur.com"+path)request,data=Net::HTTP::Get.new(path
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我的公司有一个巨大的数据库,该数据库接收来自多个来源的(许多)事件,用于监控和报告目的。到目前为止,数据中的每个新仪表板或图形都是一个新的Rails应用程序,在巨大的数据库中有额外的表,并且可以完全访问数据库内容。最近,有一个想法让外部(不是我们公司,而是姊妹公司)客户访问我们的数据,并且决定我们应该公开一个只读的RESTfulAPI来查询我们的数据。我的观点是-我们是否也应该为我们的自己
我想找到在某些文本中找到一些(让它是两个)句子的好方法。什么会更好-使用正则表达式或拆分方法?你的想法?应JeremyStein的要求-有一些例子示例:输入:ThefirstthingtodoistocreatetheCommentmodel.We’llcreatethisinthenormalway,butwithonesmalldifference.IfwewerejustcreatingcommentsforanArticlewe’dhaveanintegerfieldcalledarticle_idinthemodeltostoretheforeignkey,butinthis
我读了"BingSearchAPI-QuickStart"但我不知道如何在Ruby中发出这个http请求(Weary)如何在Ruby中翻译“Stream_context_create()”?这是什么意思?"BingSearchAPI-QuickStart"我想使用RubySDK,但我发现那些已被弃用前(Rbing)https://github.com/mikedemers/rbing您知道Bing搜索API的最新包装器(仅限Web的结果)吗? 最佳答案 好吧,经过一个小时的挫折,我想出了一个办法来做到这一点。这段代码很糟糕,因为它是
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:AmazonAPIlibraryforPython?我正在寻找一个AmazonAPI,它可以让我:按书名或作者查找书籍显示书籍封面获取有关每本书的信息(价格、评级、评论数、格式、页数等)Python或Ruby库都可以(我只想要最容易使用的库)。有什么建议么?我知道在SO上还有其他一些关于此的帖子,但这些API似乎很快就过时了。[几个月前我尝试了几个建议的Ruby库,但无法让它们中的任何一个工作。]