Lucene 作为 Apache 开源的一款搜索工具,一直以来是实现搜索功能的神兵利器,现今火热的 Solr 和 Elasticsearch 均基于该工具包进行开发,而 Lucene 之所以能在搜索中发挥至关重要的作用正是因为倒排索引。因此,本文将介绍一下倒排索引的概念以及倒排索引在 Lucene 中的实现。
搜索的核心需求是全文检索,全文检索简单来说就是要在大量文档中找到包含某个单词出现的位置,在传统关系型数据库中,数据检索只能通过 like 来实现。
例如需要在酒店数据中查询名称包含公寓的酒店,需要通过如下 sql 实现:
select * from hotel_table where hotel_name like '%公寓%';这种实现方式实际会存在很多问题:
搜索的核心目标实际上是保证搜索的效果和性能,为了高效的实现全文检索,我们可以通过倒排索引来解决。
倒排索引是区别于正排索引的概念:
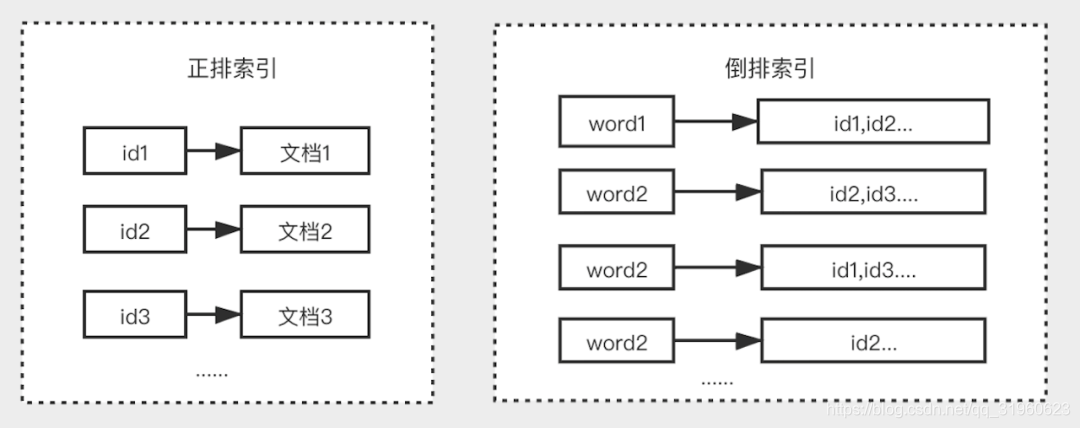
下面通过一个例子来说明下倒排索引的生成过程。
假设目前有以下两个文档内容:
苏州街维亚大厦
桔子酒店苏州街店
其处理步骤如下:
1、正排索引给每个文档进行编号,作为其唯一的标识。
| 文档 id | content |
|---|---|
| 1 | 苏州街维亚大厦 |
| 2 | 桔子酒店苏州街店 |
2、生成倒排索引:
| Word | 文档 id |
|---|---|
| 苏州街 | 1,2 |
| 维亚大厦 | 1 |
| 维亚 | 1 |
| 桔子 | 2 |
| 酒店 | 2 |
| 大赛 | 1 |
有了倒排索引,能快速、灵活地实现各类搜索需求。整个搜索过程中我们不需要做任何文本的模糊匹配。
例如,如果需要在上述两个文档中查询 苏州街桔子 ,可以通过分词后 苏州街 查到 1、2,通过 桔子 查到 2,然后再进行取交取并等操作得到最终结果。
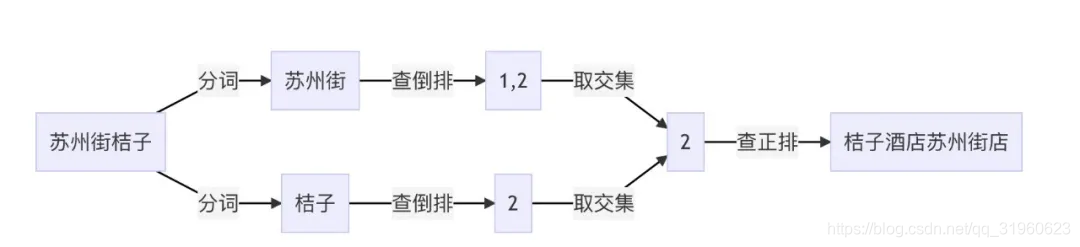
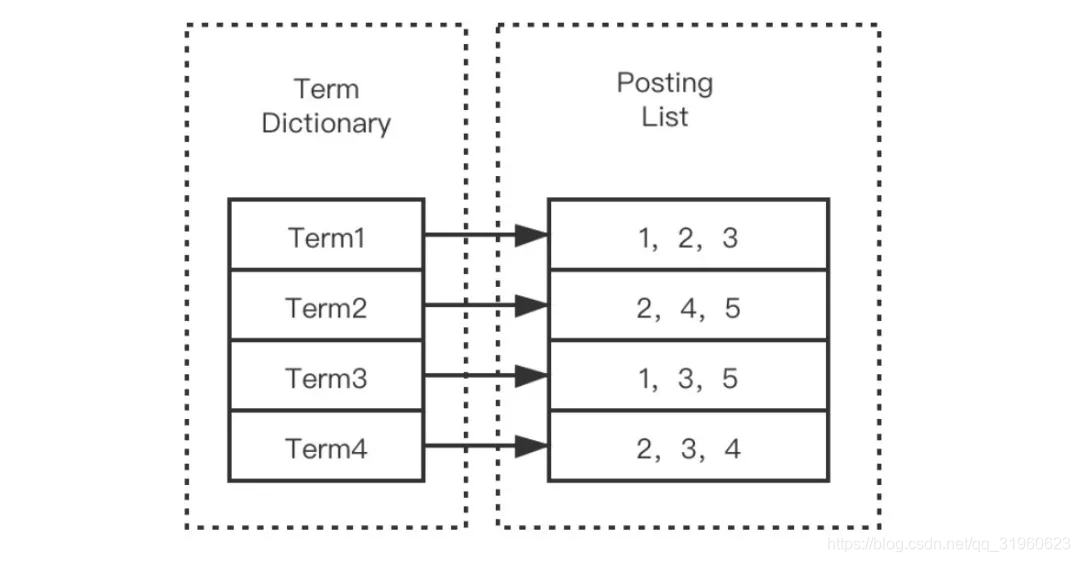
根据倒排索引的概念,我们可以用一个 Map来简单描述这个结构。这个 Map 的 Key 的即是分词后的单词,这里的单词称为 Term,这一系列的 Term 组成了倒排索引的第一个部分 —— Term Dictionary (索引表,可简称为 Dictionary)。
倒排索引的另一部分为 Postings List(记录表),也对应上述 Map 结构的 Value 部分集合。
记录表由所有的 Term 对应的数据(Postings) 组成,它不仅仅为文档 id 信息,可能包含以下信息:
全文搜索引擎在海量数据的情况下是需要存储大量的文本,所以面临以下问题:
因此上面说的基于 Map 的实现方式几乎是不可行的。
在海量数据背景下,倒排索引的实现直接关系到存储成本以及搜索性能。
为此,Lucene 引入了多种巧妙的数据结构和算法。其倒排索引实现拥有以下特性:
下面将根据倒排索引的结构,按 Posting List 和 Terms Dictionary 两部分来分析 Lucene 中的实现。
PostingList 包含文档 id、词频、位置等多个信息,这些数据之间本身是相对独立的,因此 Lucene 将 Postings List 被拆成三个文件存储:
基本所有的查询都会用 .doc 文件获取文档 id,且一般的查询仅需要用到 .doc 文件就足够了,只有对于近似查询等位置相关的查询则需要用位置相关数据。
三个文件整体实现差不太多,这里以.doc 文件为例分析其实现。
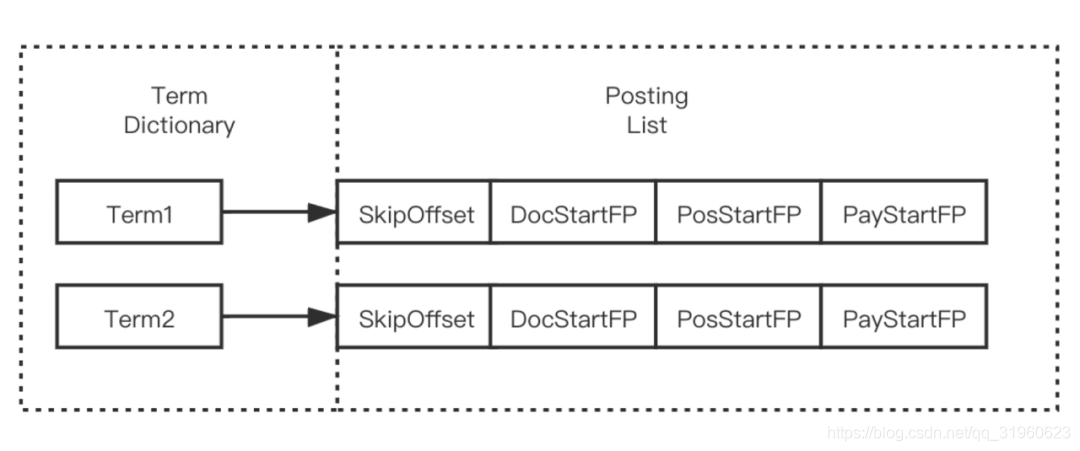
.doc 文件存储的是每个 Term 对应的文档 Id 和词频。每个 Term 都包含一对 TermFreqs 和 SkipData 结构。
其中 TermFreqs 存放 docId 和词频信息,SkipData 为跳表信息,用于实现 TermFreqs 内部的快速跳转。

Terms Dictionary(索引表)存储所有的 Term 数据,同时它也是 Term 与 Postings 的关系纽带,存储了每个 Term 和其对应的 Postings 文件位置指针。
其他更多介绍请参考:ES之倒排索引详解_wh柒八九的博客-CSDN博客_es倒排索引
我发现自己需要这个。假设cart是一个包含用户列表的模型。defindex_of_itemcart.users.each_with_indexdo|u,i|ifu==current_userreturniendend获取此类关联索引的更简单方法是什么? 最佳答案 indexArray上的方法与您的index_of_item方法相同,例如cart.users.index(current_user)返回数组中第一个对象的索引==给obj。如果未找到匹配项,则返回nil。 关于ruby-on-
因此,当我遵循MichaelHartl的RubyonRails教程时,我注意到在用户表中,我们为:email属性添加了一个唯一索引,以提高find的效率方法,因此它不会逐行搜索。到目前为止,我们一直在根据情况使用find_by_email和find_by_id进行搜索。然而,我们从未为:id属性设置索引。:id是否自动索引,因为它在默认情况下是唯一的并且本质上是顺序的?或者情况并非如此,我应该为:id搜索添加索引吗? 最佳答案 大多数数据库(包括sqlite,这是RoR中的默认数据库)会自动索引主键,对于RailsMigration
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
在我的场景中,Logstash收到的系统日志行的“时间戳”是UTC,我们在Elasticsearch输出中使用事件“时间戳”:output{elasticsearch{embedded=>falsehost=>localhostport=>9200protocol=>httpcluster=>'elasticsearch'index=>"syslog-%{+YYYY.MM.dd}"}}我的问题是,在UTC午夜,Logstash在外时区(GMT-4=>America/Montreal)结束前将日志发送到不同的索引,并且索引在20小时(晚上8点)之后没有日志,因为“时间戳”是UTC。我们已
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
我想从特定索引开始遍历数组。我该怎么做?myj.eachdo|temp|...end 最佳答案 执行以下操作:your_array[your_index..-1].eachdo|temp|###end 关于ruby-从特定索引开始迭代数组,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/44151758/
我一直在努力学习如何处理由数组组成的数组。假设我有这个数组:my_array=[['ORANGE',1],['APPLE',2],['PEACH',3]我将如何找到包含'apple'的my_array索引并删除该索引(删除子数组['APPLE',2]因为'apple'包含在该索引的数组中)?谢谢-我非常感谢这里的帮助。 最佳答案 您可以使用Array.select过滤掉项目:>>a=[['ORANGE',1],['APPLE',2],['PEACH',3]]=>[["ORANGE",1],["APPLE",2],["PEACH",3
我想使用部分字符串搜索数组,然后获取找到该字符串的索引。例如:a=["Thisisline1","Wehaveline2here","andfinallyline3","potato"]a.index("potato")#thisreturns3a.index("Wehave")#thisreturnsnil使用a.grep将返回完整的字符串,使用a.any?将返回正确的true/false语句,但都不会返回匹配的索引找到了,或者至少我不知道该怎么做。我正在编写一段代码,该代码读取文件、查找特定header,然后返回该header的索引,以便它可以将其用作future搜索的偏移量。如果
如何在rakedb:migrate:status中删除带有“**NOFILE**”的迁移ID列表?例如:StatusMigrationIDMigrationName--------------------------------------------------up20131017204224Createusersup20131218005823**********NOFILE**********up20131218011334**********NOFILE**********我不明白为什么当我自己手动删除它时它仍然保留旧的迁移文件,因为我正在研究迁移的工作原理。这是为了记录吗?但
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>