本文介绍基于Python语言arcpy模块,实现栅格影像图层建立与多幅遥感影像数据批量拼接(Mosaic)的操作。
首先,相关操作所需具体代码如下:
import os
import arcpy
file_path="G:/Postgraduate/LAI_Glass_RTlab/A2018161_Dif/DRT/"
out_file_path="G:/Postgraduate/LAI_Glass_RTlab/A2018161_Dif/DRT/"
out_file_name="Global.tif"
file_name_list=os.listdir(file_path)
tif_file_path=file_path+file_name_list[0]
cell_size_x=arcpy.GetRasterProperties_management(tif_file_path,"CELLSIZEX")
cell_size=cell_size_x.getOutput(0)
value_type=arcpy.GetRasterProperties_management(tif_file_path,"VALUETYPE")
describe=arcpy.Describe(tif_file_path)
spatial_reference=describe.spatialReference
arcpy.CreateRasterDataset_management(out_file_path,out_file_name,cell_size,"16_BIT_SIGNED",
spatial_reference,"1")
out_file=out_file_path+out_file_name
for file in file_name_list:
file_path_name=file_path+file
print(file_path_name)
arcpy.Mosaic_management([file_path_name],out_file)
其中,file_path为存放有多景初始遥感影像的路径格式为.tif栅格文件(如果不是.tif格式,例如是.hdf等文件,需首先进行文件格式的转换);out_file_path为拼接后所得结果栅格图层的存放路径;out_file_name为拼接后所得结果栅格图层的文件名称,其可选格式有很多,如下图所示。

在这里,我们默认所得拼接结果图层为一个(也就是file_path文件夹中全部的待处理遥感影像最终全拼接在一起);如果大家需要使得拼接结果图层是多幅(也就是file_path文件夹中待处理遥感影像依据区域、时间等分为很多不同的部分,每一部分拼接在一起),可以参考Python GDAL读取栅格数据并基于质量评估波段QA对指定数据加以筛选掩膜,利用其中的循环方式实现需求。
随后,通过os.listdir()函数获取file_path路径下的栅格文件,并存储于file_name_list列表中。
接下来需要创建一个新的栅格图层。之所以要进行这一步骤,是因为本文后期选择用arcpy.Mosaic_management()函数进行栅格的批量拼接,因此需要首先创建一个新的、空的栅格图层作为拼接的基准。如果大家的需求不是批量拼接栅格数据,而是单纯想利用arcpy进行新栅格的创建,那就只看这一部分的代码即可。
在这里,我们选择用file_path路径下的第一个栅格数据(下称“第一栅格”)作为新栅格图层中各项属性(例如像素边长、像素数据格式等)的依据。首先,arcpy.GetRasterProperties_management()函数获取第一栅格的像素x边边长;因为一般栅格数据中像素都是正方形,因此我们就通过cell_size=cell_size_x.getOutput(0)将第一栅格的像素x边边长作为新栅格图层像素x边与y边二者的边长。再利用arcpy.GetRasterProperties_management()函数获取第一栅格的数据格式;最后利用中间变量describe获取第一栅格的空间参考信息。
完成以上步骤后,将已获取的第一栅格的各类信息通过函数arcpy.CreateRasterDataset_management()带入新栅格中。在这里需要注意:尽可能在将要拼接时选择新栅格为"16_BIT_SIGNED"及以下的数据格式(具体数据格式类别如下图),且将file_path路径下待拼接的栅格数据的数据格式也全部修改为这一格式;否则可能会由于数据量大而导致拼接过程极慢。我之前就是由于选用了32 bit float格式的栅格数据进行拼接,导致全球范围的MODIS一个植被产品数据拼接花了将近一天的时间。如果大家的栅格像素数据包含小数,可以通过乘上一个缩放系数的方式进行数据整数化。

代码最后的一个for循环,就是遍历file_name_list中的各个栅格数据,并通过arcpy.Mosaic_management()函数加以拼接即可。
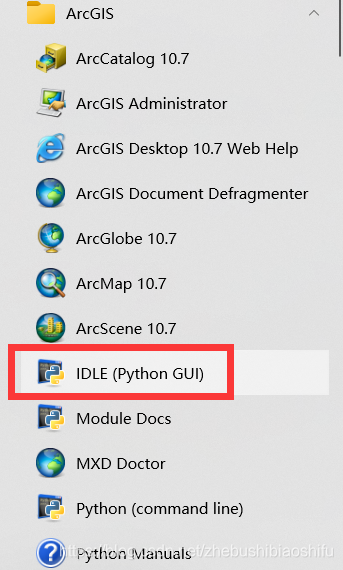
以上,便完成了本次批量拼接的操作。这里还有一点需要注意:由于arcpy模块的限制,如果大家的Python版本是3.0及以上,往往不能直接运行上述代码,最好是在ArcMap的Python运行框或其对应IDLE(如下图所示)中运行。
至此,大功告成。
出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我对最新版本的Rails有疑问。我创建了一个新应用程序(railsnewMyProject),但我没有脚本/生成,只有脚本/rails,当我输入ruby./script/railsgeneratepluginmy_plugin"Couldnotfindgeneratorplugin.".你知道如何生成插件模板吗?没有这个命令可以创建插件吗?PS:我正在使用Rails3.2.1和ruby1.8.7[universal-darwin11.0] 最佳答案 随着Rails3.2.0的发布,插件生成器已经被移除。查看变更日志here.现在
如何使用RSpec::Core::RakeTask初始化RSpecRake任务?require'rspec/core/rake_task'RSpec::Core::RakeTask.newdo|t|#whatdoIputinhere?endInitialize函数记录在http://rubydoc.info/github/rspec/rspec-core/RSpec/Core/RakeTask#initialize-instance_method没有很好的记录;它只是说:-(RakeTask)initialize(*args,&task_block)AnewinstanceofRake
关闭。这个问题需要detailsorclarity.它目前不接受答案。想改进这个问题吗?通过editingthispost添加细节并澄清问题.关闭8年前。Improvethisquestion为什么SecureRandom.uuid创建一个唯一的字符串?SecureRandom.uuid#=>"35cb4e30-54e1-49f9-b5ce-4134799eb2c0"SecureRandom.uuid方法创建的字符串从不重复?
我正在阅读SandiMetz的POODR,并且遇到了一个我不太了解的编码原则。这是代码:classBicycleattr_reader:size,:chain,:tire_sizedefinitialize(args={})@size=args[:size]||1@chain=args[:chain]||2@tire_size=args[:tire_size]||3post_initialize(args)endendclassMountainBike此代码将为其各自的属性输出1,2,3,4,5。我不明白的是查找方法。当一辆山地自行车被实例化时,因为它没有自己的initialize方法
我正在尝试按0-9和a-z的顺序创建数字和字母列表。我有一组值value_array=['0','1','2','3','4','5','6','7','8','9','a','b','光盘','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','','u','v','w','x','y','z']和一个组合列表的数组,按顺序,这些数字可以产生x个字符,比方说三个list_array=[]和一个当前字母和数字组合的数组(在将它插入列表数组之前我会把它变成一个字符串,]current_combo['0','0','0']
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
我正在尝试在Rails上安装ruby,到目前为止一切都已安装,但是当我尝试使用rakedb:create创建数据库时,我收到一个奇怪的错误:dyld:lazysymbolbindingfailed:Symbolnotfound:_mysql_get_client_infoReferencedfrom:/Library/Ruby/Gems/1.8/gems/mysql2-0.3.11/lib/mysql2/mysql2.bundleExpectedin:flatnamespacedyld:Symbolnotfound:_mysql_get_client_infoReferencedf