目录

本文主要目标是对数据进行分析,数据抓取具有时效性,在这里对抓取的方法不进行赘述,有不懂的可以看Python爬虫-抓取数据到可视化全流程的实现
从数据库中取出数据,可以看到共有1260条评论数据,分为8列
#导包
import pandas as pd
import numpy as np
import pymysql
import matplotlib.pyplot as plt
import re
import jieba.posseg as psg
db_info={
'host':"***",
'user':"***",
'passwd':'***',
'database':'cx',# 这里说明我要连接哪个库
'charset':'utf8'
}
conn = pymysql.connect(**db_info)
cursor = conn.cursor()
sql = 'select * from jdsppl'
result = pd.read_sql(sql,conn)
result
result.shape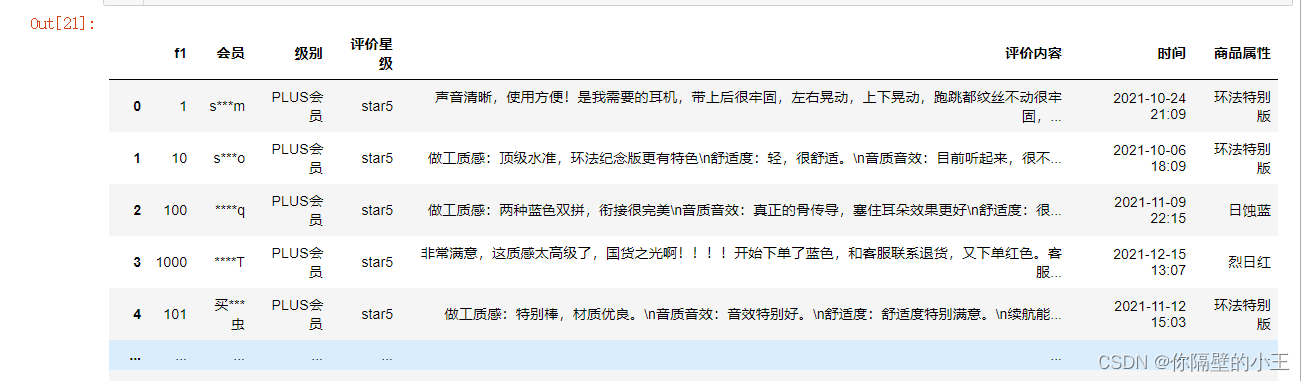
部分电商平台对长时间未完成订单评价的客户会进行默认评价,此类数据没有分析价值,但是本次爬取的数据来自于京东,京东默认只保留前100页的评论数据,其他数据归为帮助不大的数据,因此在此次爬取的数据中,不存在这样的情况,同时如果在某个商品的评论中出现了完全相同的评论,一次两次或者多次,那么这种情况下的数据肯定是毫无意义的问题数据,这种评论数据只认为其第一条即首次出现时认为其存在一定价值。在评论中会出现一部分评论相似程度很高,但并不完全相同,个别词语还存在明显差异,对于这种情况,全部删除是不正确和不合适的,可以只删除重复的部分,保留有用的文本评论信息,留下更多有用的语料。
reviews = reviews[['content', 'content_type']].drop_duplicates()
content = reviews['content']
reviews
可以看到有17条重复数据已经被删除
通过人工观察数据发现,评论中夹杂着许多数字与字母,对于本案例的挖掘目标而言,这类数据本身并没有实质性帮助。另外,由于该评论文本数据主要是围绕京东商城中韶音 AfterShokz Aeropex AS800骨传导蓝牙耳机进行评价的,其中“京东”“京东商城”“韶音”“耳机”“蓝牙耳机”等词出现的频数很大,但是对分析目标并没有什么作用,因此可以在分词之前将这些词去除,对数据进行清洗
# 去除去除英文、数字等
# 由于评论中不重要词语
strinfo = re.compile('[0-9a-zA-Z]|京东|京东商城|韶音|耳机|蓝牙耳机|')
content=result['评价内容']
content = content.apply(lambda x: strinfo.sub('', x))
content
字段已经去除
# 分词
worker = lambda s: [(x.word, x.flag) for x in psg.cut(s)] # 自定义简单分词函数
seg_word = content.apply(worker)
# 删除标点符号
result = result[result['nature'] != 'x'] # x表示标点符号
# 构造各词在对应评论的位置列
n_word = list(result.groupby(by = ['index_content'])['index_content'].count())
index_word = [list(np.arange(0, y)) for y in n_word]
index_word = sum(index_word, []) # 表示词语在改评论的位置
# 合并评论id,评论中词的id,词,词性,评论类型
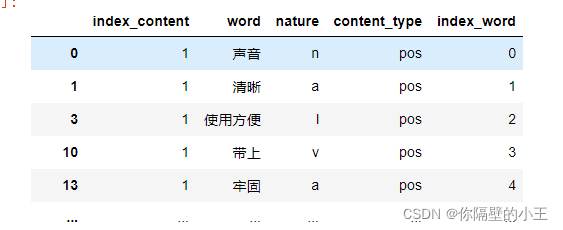
result['index_word'] = index_word
result处理后表格样式
提取含有名词的评论
由于本次分析的目标是对产品特征的优缺点进行分析,类似“不错,很好的产品”“很不错,继续支持”等评论虽然表达了对产品的情感倾向,但是实际上无法根据这些评论提取出哪些产品特征是用户满意的。评论中只有出现明确的名词,如机构团体及其他专有名词时,才有意义,因此需要对分词后的词语进行词性标注。之后再根据词性将含有名词类的评论提取出来。jieba关于词典词性标记,采用ICTCLAS 的标记方法,对于词性标注大家可以看:ICTCLAS汉语词性标注集
提取评论中词性含有“n”(名词)的评论,
# 提取含有名词类的评论
ind = result[['n' in x for x in result['nature']]]['index_content'].unique()
result = result[[x in ind for x in result['index_content']]]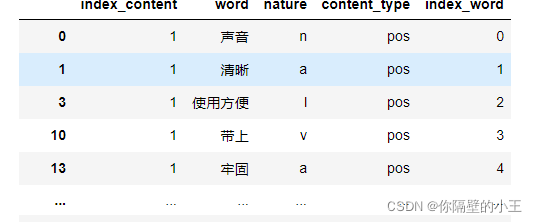
进行数据预处理后,可绘制词云查看分词效果,词云会将文本中出现频率较高的“关键词”予以视觉上的突出。首先需要对词语进行词频统计,将词频按照降序排序,选择前100个词,使用wordcloud模块中的WordCloud绘制词云,查看分词效果(常用字体代码)
import matplotlib.pyplot as plt
from wordcloud import WordCloud
frequencies = result.groupby(by = ['word'])['word'].count()
frequencies = frequencies.sort_values(ascending = False)
backgroud_Image=plt.imread('../data/pl.jpg')
wordcloud = WordCloud(font_path="simkai.ttf",
max_words=100,
background_color='white',
mask=backgroud_Image)
my_wordcloud = wordcloud.fit_words(frequencies)
plt.imshow(my_wordcloud)
plt.axis('off')
plt.show()
从生成的词云图中可以初步判断用户比较在意的是音质、质感、续航、舒适度等关键词
import pandas as pd
import numpy as np
word = pd.read_csv("../tmp/result.csv")
# 读入正面、负面情感评价词
pos_comment = pd.read_csv("../data/正面评价词语(中文).txt", header=None,sep="\n",
encoding = 'utf-8', engine='python')
neg_comment = pd.read_csv("../data/负面评价词语(中文).txt", header=None,sep="\n",
encoding = 'utf-8', engine='python')
pos_emotion = pd.read_csv("../data/正面情感词语(中文).txt", header=None,sep="\n",
encoding = 'utf-8', engine='python')
neg_emotion = pd.read_csv("../data/负面情感词语(中文).txt", header=None,sep="\n",
encoding = 'utf-8', engine='python')
# 将分词结果与正负面情感词表合并,定位情感词
data_posneg = posneg.merge(word, left_on = 'word', right_on = 'word',
how = 'right')
data_posneg = data_posneg.sort_values(by = ['index_content','index_word'])# 根据情感词前时候有否定词或双层否定词对情感值进行修正
# 载入否定词表
notdict = pd.read_csv("../data/not.csv")
# 去除情感值为0的评论
emotional_value = emotional_value[emotional_value['amend_weight'] != 0]使用wordcloud包下的 WordCloud 函数分别对正面评论和负面评论绘制词云,以查看情感分析效果。
# 给情感值大于0的赋予评论类型(content_type)为pos,小于0的为neg emotional_value['a_type'] = '' emotional_value['a_type'][emotional_value['amend_weight'] > 0] = 'pos' emotional_value['a_type'][emotional_value['amend_weight'] < 0] = 'neg' # 将结果写出,每条评论作为一行 posdata.to_csv("../tmp/posdata.csv", index = False, encoding = 'utf-8') negdata.to_csv("../tmp/negdata.csv", index = False, encoding = 'utf-8')

可以看到在正面情感评论词云图中可以发现:“不错”、“喜欢”、“满意”、“舒服”等词出现的词频较高,且没有出现负面情感的词语。从负面情感评论中可以发现:“做工”、“客服”、“差”等出现词频较高,没有发现掺杂正面情感的词语,由此可以正面通过词表来分析文本的情感程度是有效的。
import pandas as pd import numpy as np import re import itertools import matplotlib.pyplot as plt # 载入情感分析后的数据 posdata = pd.read_csv("../data/posdata.csv", encoding = 'utf-8') negdata = pd.read_csv("../data/negdata.csv", encoding = 'utf-8') from gensim import corpora, models # 建立词典 pos_dict = corpora.Dictionary([[i] for i in posdata['word']]) # 正面 neg_dict = corpora.Dictionary([[i] for i in negdata['word']]) # 负面 # 建立语料库 pos_corpus = [pos_dict.doc2bow(j) for j in [[i] for i in posdata['word']]] # 正面 neg_corpus = [neg_dict.doc2bow(j) for j in [[i] for i in negdata['word']]] # 负面
- 基于相似度的自适应最优LDA模型选择方法,确定主题数并进行主题分析。实验证明该方法可以在不需要人工调试主题数目的情况下,用相对少的迭代找到最优的主题结构。具体步骤如下:
- 1)取初始主题数k值,得到初始模型,计算各主题之间的相似度(平均余弦距离)。
- 2)增加或减少k值,重新训练模型,再次计算各主题之间的相似度。
- 3 )重复步骤2直到得到最优k值。
- 利用各主题间的余弦相似度来度量主题间的相似程度。从词频入手,计算它们的相似度,用词越相似,则内容越相近。
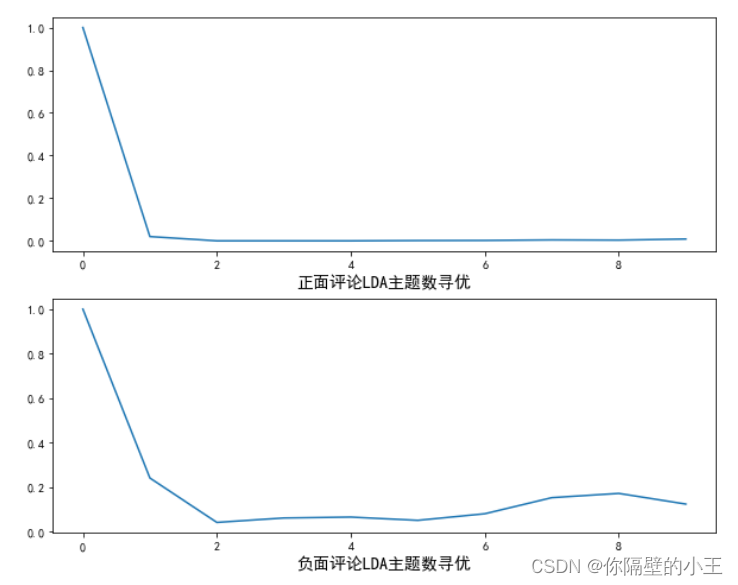
# 计算主题平均余弦相似度 pos_k = lda_k(pos_corpus, pos_dict) neg_k = lda_k(neg_corpus, neg_dict) # 绘制主题平均余弦相似度图形 from matplotlib.font_manager import FontProperties font = FontProperties(size=14) #解决中文显示问题 plt.rcParams['font.sans-serif']=['SimHei'] plt.rcParams['axes.unicode_minus'] = False fig = plt.figure(figsize=(10,8)) ax1 = fig.add_subplot(211) ax1.plot(pos_k) ax1.set_xlabel('正面评论LDA主题数寻优', fontproperties=font) ax2 = fig.add_subplot(212) ax2.plot(neg_k) ax2.set_xlabel('负面评论LDA主题数寻优', fontproperties=font)
从图中可以发现,当主题数为2时,主题间的余弦相似度达到最低,因此选择主题数为2
根据主题数寻优结果,使用Python的Gensim模块对正面评论数据和负面评论数据分别构建LDA主题模型,选取主题数为2,经过LDA主题分析后,每个主题下生成10个最有可能出现的词语及相应的概率
# LDA主题分析
pos_lda = models.LdaModel(pos_corpus, num_topics = 2, id2word = pos_dict)
neg_lda = models.LdaModel(neg_corpus, num_topics = 2, id2word = neg_dict)
pos_lda.print_topics(num_words = 10)
neg_lda.print_topics(num_words = 10)
整理:
正面评价潜在主题:
| 1 | 2 | 1 | 2 |
| 音质 | 耳朵 | 感觉 | 传到 |
| 喜欢 | 不错 | 骨 | 运动 |
| 做工 | 质感 | 舒适度 | 音效 |
| 满意 | 听 | 舒服 | 续航 |
| 耳朵 | 跑步 | 很快 | 值得 |

负面评价潜在主题:
| 1 | 2 | 1 | 2 |
| 客服 | 耳朵 | 几天 | 差 |
| 传导 | 骨 | 新 | 赠品 |
| 音质 | 快递 | 理解 | 做工 |
| 坏 | 不好 | 产品 | 找 |
| 声音 | 太 | 回来 | 中 |
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我意识到这可能是一个非常基本的问题,但我现在已经花了几天时间回过头来解决这个问题,但出于某种原因,Google就是没有帮助我。(我认为部分问题在于我是一个初学者,我不知道该问什么......)我也看过O'Reilly的RubyCookbook和RailsAPI,但我仍然停留在这个问题上.我找到了一些关于多态关系的信息,但它似乎不是我需要的(尽管如果我错了请告诉我)。我正在尝试调整MichaelHartl'stutorial创建一个包含用户、文章和评论的博客应用程序(不使用脚手架)。我希望评论既属于用户又属于文章。我的主要问题是:我不知道如何将当前文章的ID放入评论Controller。
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit