文章目录
在C语言中其实也有可变参数:

C++库里面也有很多使用可变参数函数模板的:

template <class ...Args>
void fun(Args... args)
{}
Args是一个模板参数包,args是一个函数形参参数包
声明一个参数包Args…args,这个参数包中可以包含0到任意个模板参数
以前只能传递一个对象做参数,有了可变参数包就可以传递0~n个参数:
template <class ...Args>
void fun(Args... args)
{
// 获取参数包中有几个参数
cout << sizeof...(args) << endl;
}
int main()
{
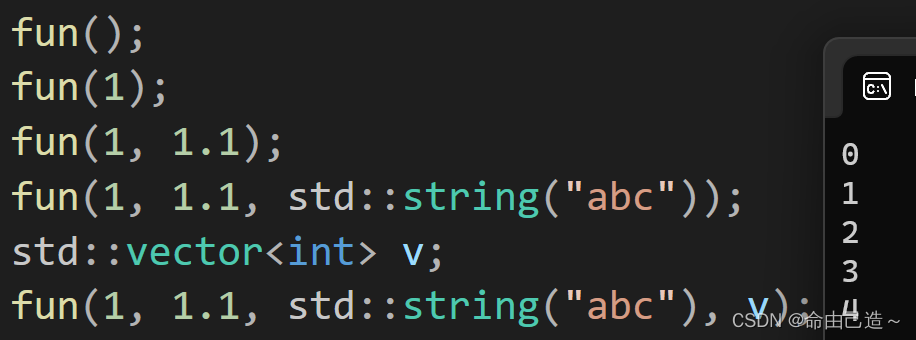
fun();
fun(1);
fun(1, 1.1);
fun(1, 1.1, std::string("abc"));
std::vector<int> v;
fun(1, 1.1, std::string("abc"), v);
return 0;
}
那么怎么把这些参数取出来呢?
void fun()
{
cout << endl;
}
template <class T, class ...Args>
void fun(T val, Args... args)
{
cout << val << " ";
fun(args...);
}
int main()
{
fun();
fun(1);
fun(1, 1.1);
fun(1, 1.1, std::string("abc"));
return 0;
}

解释:
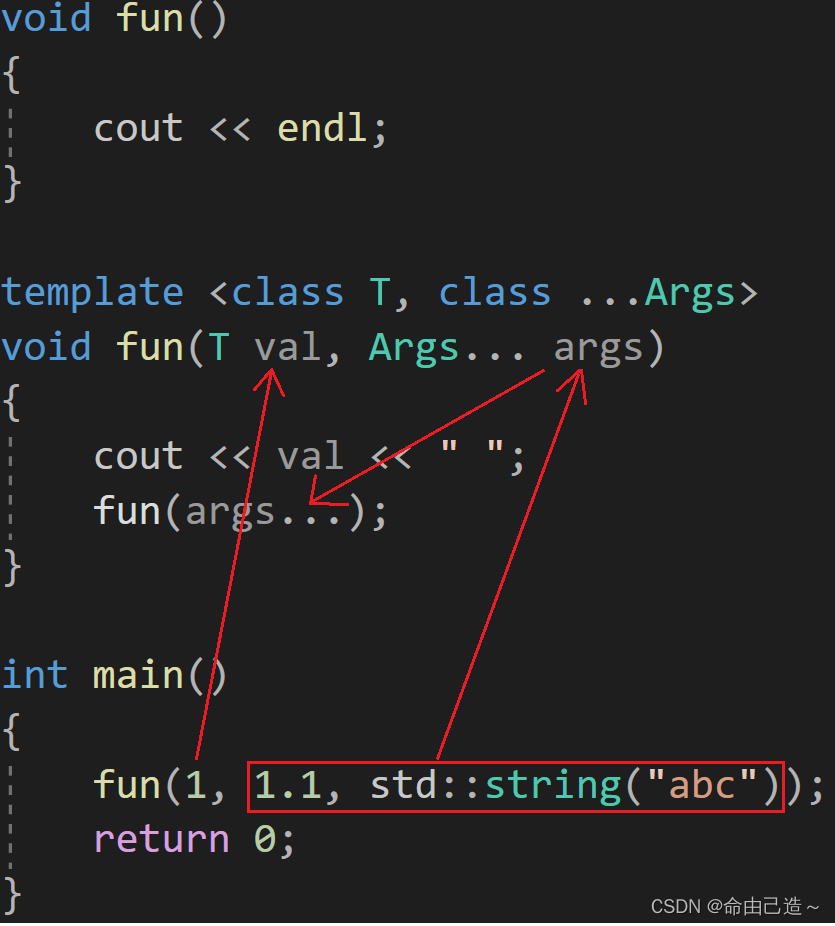
按照箭头的方式调用,最后当没有参数的时候就会走最上面的函数
template <class T>
void printArg(T val)
{
cout << val << " ";
}
template <class ...Args>
void fun(Args... args)
{
int arr[] = { (printArg(args), 0)... };
cout << endl;
}
int main()
{
fun(1, 1.1, std::string("abc"));
return 0;
}
这种展开参数包的方式,不需要通过递归终止函数,printArg不是一个递归终止函数,只是一个处理参数包中每一个参数的函数。
(printArg(args), 0):先执行printArg(args),再得到逗号表达式的结果0。通过初始化列表来初始化一个变长数组, {(printArg(args), 0)...}将会展开成((printArg(arg1),0),(printArg(arg2),0), (printArg(arg3),0), etc... ),最终会创建一个元素值都为0的数组。在创建数组的过程中会先执行逗号表达式前面的部分printArg(args)打印出参数,也就是说在构造int数组的过程中就将参数包展开了,这个数组的目的纯粹是为了在数组构造的过程展开参数包。
比较:
insert:
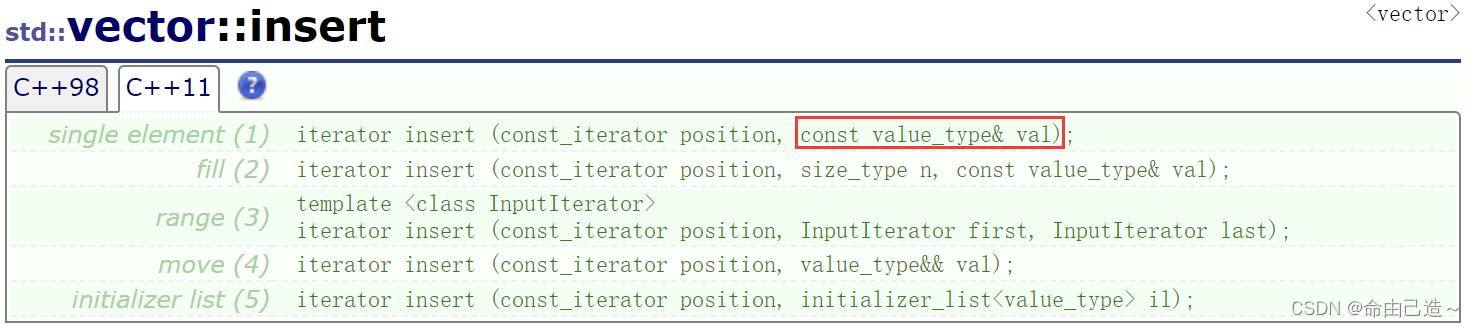
emplace:

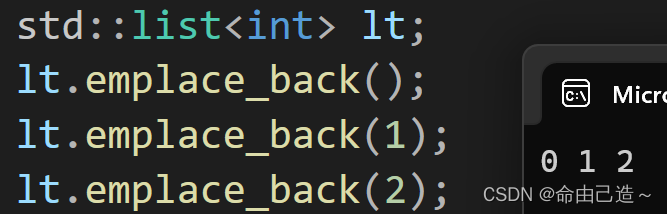
emplace的使用:
int main()
{
std::list<int> lt;
lt.emplace_back();
lt.emplace_back(1);
lt.emplace_back(2);
for (auto& e : lt)
{
cout << e << " ";
}
cout << '\n';
return 0;
}
而emplace在插入自定义类型数据的时候会有区别:
struct A
{
A(int a = 1, double b = 2)
: _a(a)
, _b(b)
{}
int _a;
double _b;
};
int main()
{
std::list<A> lt;
lt.push_back({ 1, 1.0 });
lt.emplace_back(2, 2.0);
//lt.push_back(3, 3.0);// error
for (auto& e : lt)
{
cout << e._a << endl;
}
cout << '\n';
return 0;
}
上面使用push_back是先构造再拷贝构造,而使用emplace_back就可以直接构造(使用参数包)。
验证一下:
引入之前写过的string类
namespace yyh
{
class string
{
public:
typedef char* iterator;
iterator begin()
{
return _str;
}
iterator end()
{
return _str + _size;
}
string(const char* str = "")
: _size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];// _capacity表示有效字符个数
strcpy(_str, str);
cout << "string(const char* str) -- 构造函数" << endl;
}
void swap(string& s)
{
std::swap(_str, s._str);
std::swap(_size, s._size);
std::swap(_capacity, s._capacity);
}
// 拷贝构造
string(const string& s)
: _size(strlen(s._str))
, _capacity(s._size)
{
_str = new char[_capacity + 1];
strcpy(_str, s._str);
cout << "string(const string& s) -- 深拷贝" << endl;
}
// 移动构造
string(string&& s)
{
cout << "string(string&& s) -- 移动拷贝" << endl;
swap(s);
}
// 赋值重载
string& operator=(const string& s)
{
cout << "string& operator=(string s) -- 深拷贝" << endl;
string tmp(s);
swap(tmp);
return *this;
}
~string()
{
delete[] _str;
_str = nullptr;
}
char& operator[](size_t pos)
{
assert(pos < _size);
return _str[pos];
}
void reserve(size_t n)
{
if (n > _capacity)
{
char* tmp = new char[n + 1];
strcpy(tmp, _str);
delete[] _str;
_str = tmp;
_capacity = n;
}
}
void push_back(char ch)
{
if (_size >= _capacity)
{
size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2;
reserve(newcapacity);
}
_str[_size] = ch;
++_size;
_str[_size] = '\0';
}
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
const char* c_str() const
{
return _str;
}
private:
char* _str = nullptr;
size_t _size = 0;
size_t _capacity = 0;
};
}
struct A
{
A(int a = 1, const char* str = " ")
: _a(a)
, _str(str)
{}
int _a;
yyh::string _str;
};
push_back:

emplace_back:

总结:
如果是左值,使用push_back或者emplace_back没什么区别。
对于右值,emplace_back把构造和拷贝构造合二为一成构造函数。
但是如果没有移动拷贝效率差距会很大,emplace_back还是直接构造,但是push_back就会走深拷贝。
其实包装器function就是一个类模板。先来看一段代码:
template <class F, class T>
void func(F fun, T val)
{
static int cnt = 1;
cout << "cnt: " << cnt++ << endl;
cout << "&cnt: " << &cnt << endl;
}
int f1(int x)
{
return x * 2;
}
struct f2
{
int operator()(int x)
{
return x * 2;
}
};
int main()
{
// 函数名
func(f1, 2);
// 仿函数对象
func(f2(), 2);
// lambda表达式
func([](int x)->int { return x * 2; }, 2);
return 0;
}
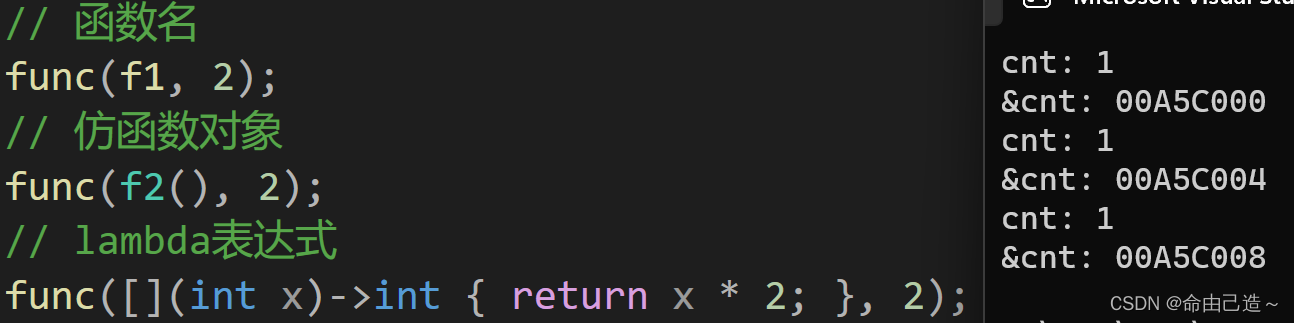
可以看到以三种不同的方式调用func函数,func函数就会被实例化出三份。
包装器可以很好的解决上面的问题


如果参数是两个int的话就是:
function<int(int, int)> fun1
int f1(int x)
{
return x * 2;
}
struct f2
{
int operator()(int x)
{
return x * 2;
}
};
class f3
{
public:
static int muli(int x)
{
return x * 2;
}
double muld(double x)
{
return x * 2;
}
};
int main()
{
// 普通函数
function<int(int)> fun1(f1);
cout << fun1(2) << endl;
// 仿函数
function<int(int)> fun2;
fun2 = f2();
cout << fun2(2) << endl;
// lambda表达式
function<int(int)> fun3;
fun3 = [](int x)->int {return 2 * x; };
cout << fun3(2) << endl;
// 静态成员函数指针
function<int(int)> fun4 = &f3::muli;
cout << fun4(2) << endl;
// 非静态成员函数指针
function<int(f3/*this指针*/, int)> fun5 = &f3::muld;
cout << fun5(f3(), 2) << endl;
return 0;
}
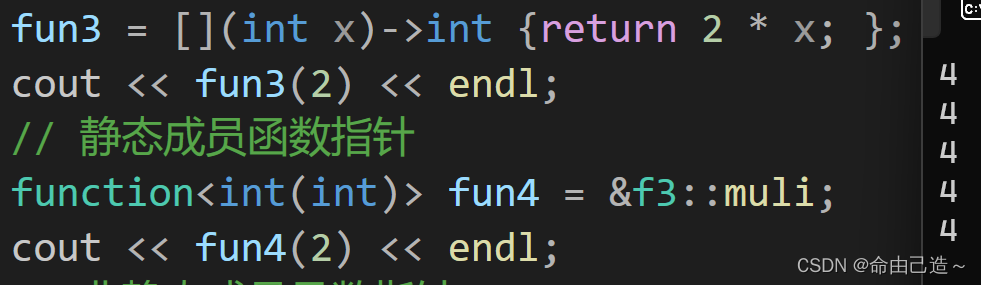
这里要注意类成员函数的调用方法:
对于静态成员函数,因为没有this指针,所以正常调用,后面也可以不加&
对于非静态成员函数,因为含有this指针,而this指针不能显示传递,所以要传递对象。必须加&。
当然也可以不在()内部加上对象,可以使用lambda表达式中的[]捕获:
f3 ff;
function<int(int)> fun6 = [&ff](int x)->double {return ff.muld(x); };
题目链接
具体做法就不多叙述,这里主要展示怎么使用function函数:
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int> st;
map<string, function<int(int, int)>> hash =
{
{"+", [](int x, int y)->int{return x + y;}},
{"-", [](int x, int y)->int{return x - y;}},
{"*", [](int x, int y)->int{return x * y;}},
{"/", [](int x, int y)->int{return x / y;}},
};
for(auto& e : tokens)
{
if(hash.count(e) == 0)
{
st.push(stoi(e));
}
else
{
int right = st.top();
st.pop();
int left = st.top();
st.pop();
st.push(hash[e](left, right));
}
}
return st.top();
}
};
在2.1中我们看道以那种方式会实例化三个模板函数。
而我们可以用function来解决这个问题:
template <class F, class T>
T func(F fun, T val)
{
static int cnt = 1;
cout << "cnt: " << cnt << endl;
cout << "&cnt: " << &cnt << endl;
return fun(val);
}
int f1(int x)
{
return x * 2;
}
struct f2
{
int operator()(int x)
{
return x * 2;
}
};
class f3
{
public:
static int muli(int x)
{
return x * 2;
}
double muld(double x)
{
return x * 2;
}
};
int main()
{
// 函数名
func(function<int(int)>(f1), 2);
// 仿函数对象
f2 ff;
func(function<int(int)>(ff), 2);
// lambda表达式
func(function<int(int)>([](int x)->int {return x * 2; }), 2);
return 0;
}

可以看出只实例化出了一份函数。

int Plus(int a, int b)
{
return a - b;
}
int main()
{
function<int(int, int)> fun1 = bind(Plus, placeholders::_1, placeholders::_2);
cout << fun1(1, 2) << endl;
function<int(int, int)> fun2 = bind(Plus, placeholders::_2, placeholders::_1);
cout << fun2(1, 2) << endl;
return 0;
}

从这里就可以看出_1代表第一个参数,_2代表第二个参,对于fun2就相当于把传参的顺序改变了。
class fun
{
public:
static int muli(int x)
{
return x * 2;
}
double muld(double x)
{
return x * 2;
}
};
int main()
{
// 非静态成员函数指针
function<int(fun/*this指针*/, int)> fun1 = &fun::muld;
cout << fun1(fun(), 2) << endl;
return 0;
}
上面说过了使用非静态成员函数的时候得传递对象进去。如果我们不想传递这个参数呢?
class fun
{
public:
static int muli(int x)
{
return x * 2;
}
double muld(double x)
{
return x * 2;
}
};
int main()
{
// 非静态成员函数指针
function<int(fun/*this指针*/, int)> fun1 = &fun::muld;
cout << fun1(fun(), 2) << endl;
// 绑定参数
function<int(int)> fun2 = bind(&fun::muld, fun(), std::placeholders::_1);
cout << fun2(2) << endl;
return 0;
}

exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我正在使用puppet为ruby程序提供一组常量。我需要提供一组主机名,我的程序将对其进行迭代。在我之前使用的bash脚本中,我只是将它作为一个puppet变量hosts=>"host1,host2"我将其提供给bash脚本作为HOSTS=显然这对ruby不太适用——我需要它的格式hosts=["host1","host2"]自从phosts和putsmy_array.inspect提供输出["host1","host2"]我希望使用其中之一。不幸的是,我终其一生都无法弄清楚如何让它发挥作用。我尝试了以下各项:我发现某处他们指出我需要在函数调用前放置“function_”……这
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
它不等于主线程的binding,这个toplevel作用域是什么?此作用域与主线程中的binding有何不同?>ruby-e'putsTOPLEVEL_BINDING===binding'false 最佳答案 事实是,TOPLEVEL_BINDING始终引用Binding的预定义全局实例,而Kernel#binding创建的新实例>Binding每次封装当前执行上下文。在顶层,它们都包含相同的绑定(bind),但它们不是同一个对象,您无法使用==或===测试它们的绑定(bind)相等性。putsTOPLEVEL_BINDINGput
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一