顾名思义,子流程是一个包含其他活动、网关、事件等的活动,这些活动本身形成了一个流程,该流程是更大流程的一部分。
使用子流程确实有一些限制:
考虑下面这个流程图


用多实例子流程实现了类似会签的功能。(当然了,不用子流程,用多实例任务也能实现会签功能。)
上面这个流程会根据传入的人数来决定开启几个子流程,在每个子流程中第一个任务审批时指定下一个审批人(PS:流程变量)
代码使用的是7.1.0.M6这个版本
<dependency>
<groupId>org.activiti</groupId>
<artifactId>activiti-spring-boot-starter</artifactId>
<version>7.1.0.M6</version>
</dependency>测试代码如下
package com.example.demo222;
import org.activiti.engine.RepositoryService;
import org.activiti.engine.RuntimeService;
import org.activiti.engine.TaskService;
import org.activiti.engine.runtime.ProcessInstance;
import org.activiti.engine.task.Task;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@SpringBootTest
class Demo222ApplicationTests {
@Autowired
private RepositoryService repositoryService;
@Autowired
private RuntimeService runtimeService;
@Autowired
private TaskService taskService;
@Test
void testDeply() {
repositoryService.createDeployment()
.addClasspathResource("processes/test.bpmn20.xml")
.name("test")
.key("test")
.deploy();
}
@Test
void testStart() {
Map<String, Object> variables = new HashMap<>();
variables.put("assigneeList", Arrays.asList("zhangsanfeng", "lixiaoyao", "zhaolinger"));
ProcessInstance processInstance = runtimeService.startProcessInstanceById("test:8:c76442ee-398a-11ed-b16c-84a9386654d8", variables);
System.out.println(processInstance);
}
@Test
void testCompleteTask2() {
Map<String, Object> variables = new HashMap<>();
variables.put("manager", "guanyu");
taskService.complete("da51fa72-22d4-11ed-834c-84a9386654d8", variables);
}
}
可以看到,流程启动的时候,act_ru_execution表中插入了8条记录,因为有1个主流程,3个子流程,所以 (3+1)×2=8
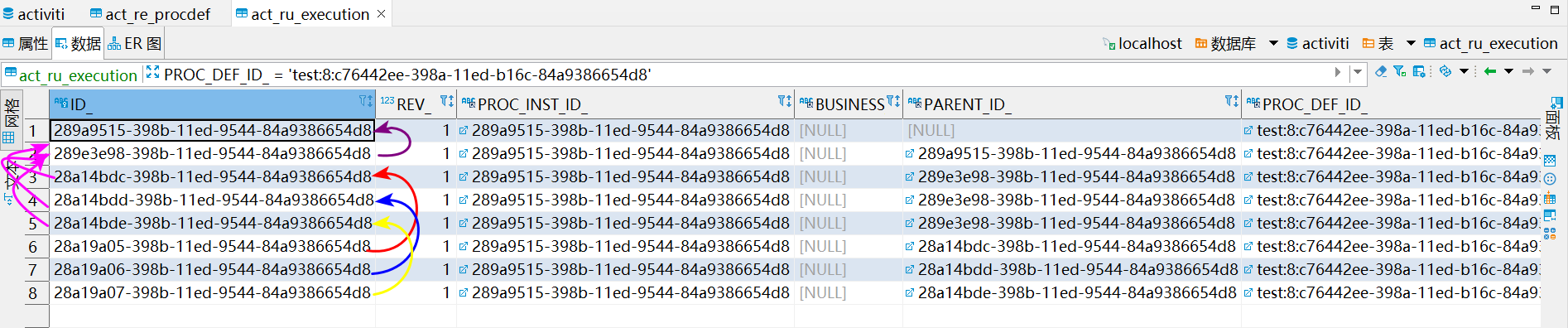
每个子流程当前一个任务,总共3个激活的任务

每个流程有6个变量,3×6=18
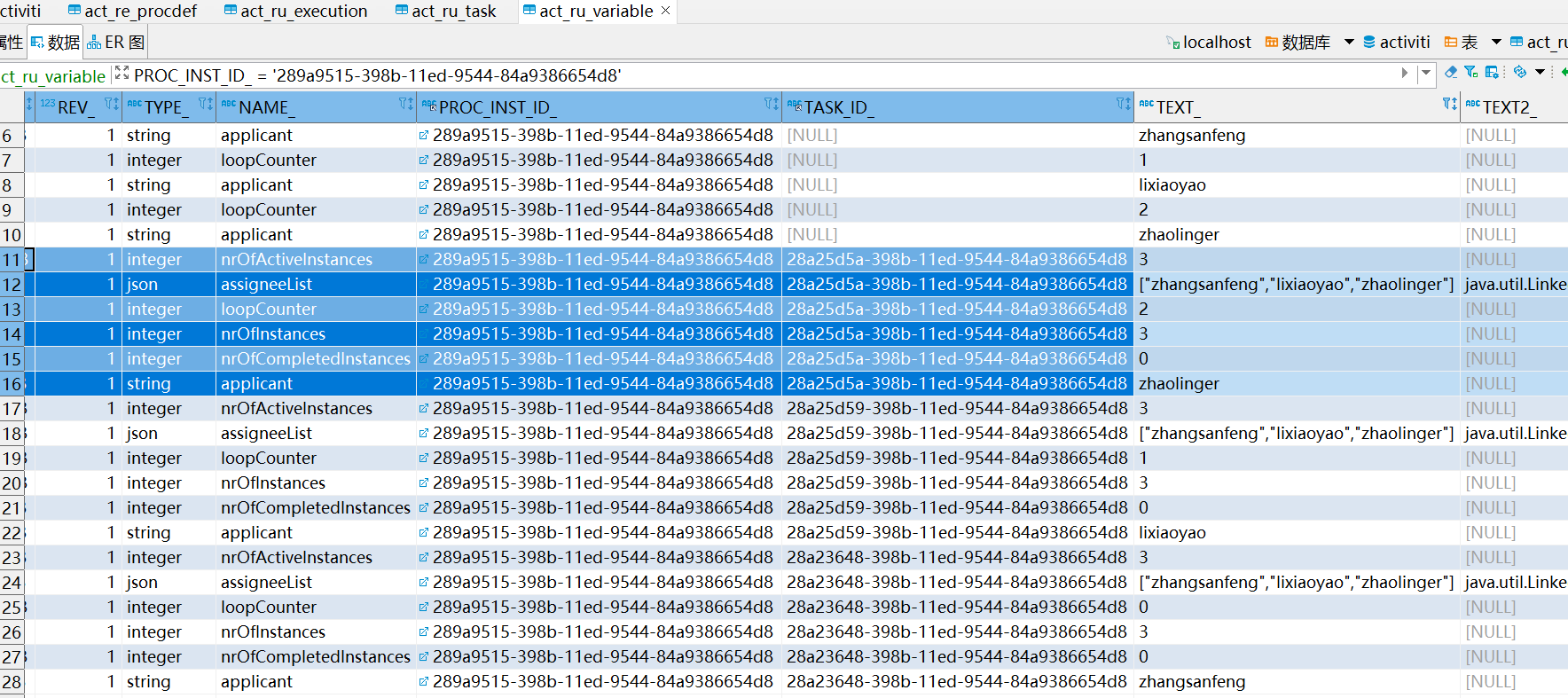
当至少有2个子流程结束后,才会回到主流程节点
下面再看另一个流程
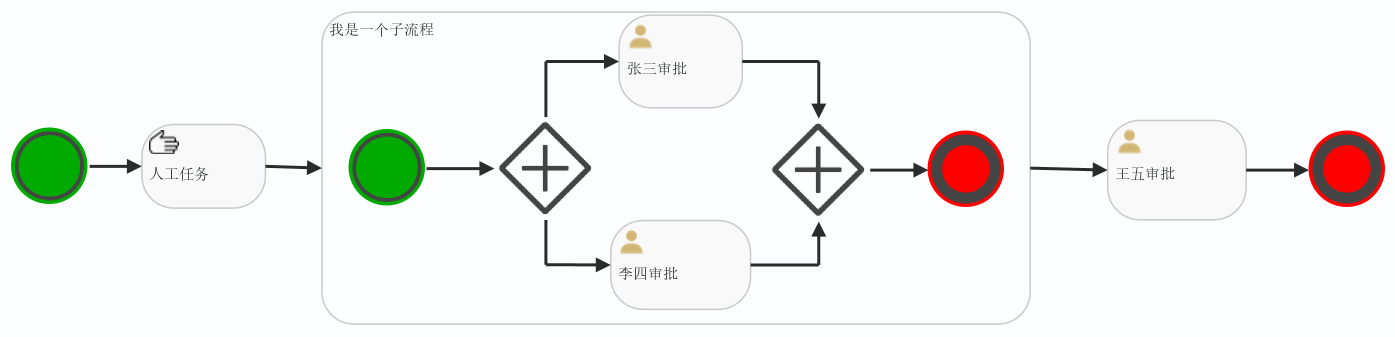

这个流程跟前面一个实现的功能有一点点类似,只有一个子流程,子流程中有两个并行的任务,当这两个任务都完成后子流程就结束了
启动流程以后,act_ru_execution表中应该新增4条记录,因为有主子2个流程

2个并行的任务

当张三完成任务以后,这个流程实例当前只剩下一个激活的任务

当李四也完成任务后,子流程结束,回归主流程。于是act_ru_execution表应该只剩2条记录,act_ru_task表新增了一条王五的任务


王五完成任务后,整个流程就结束了
一、系统定级信息系统运营使用单位按照等级保护管理办法和定级指南,自主确定信息系统的安全保护等级。有上级主管部门的,应当经上级主管部门审批。跨省或全国统一联网运行的信息系统可以由其主管部门统一确定安全保护等级。定级需要根据信息系统的实际情况合理定级。二、系统备案第二级以上信息系统定级单位到所在地设区的市级以上公安机关办理备案手续。省级单位到省公安厅网安总队备案,各地市单位一般直接到市级网安支队备案,也有部分地市区县单位的定级备案资料是先交到区县公安网监大队的,具体根据各地市要求来。信息系统运营、使用单位或者其主管部门应当在信息系统安全保护等级确定后30日内,到公安机关办理备案手续。三、初次测评信
目录1. 研究范围定义2. 流程中台市场分析3. 厂商评估:微宏科技4. 入选证书 1. 研究范围定义近年来,随着外部市场环境快速变化、客户需求愈发多样,企业逐渐意识到,自身业务需要更加敏捷、高效,具备根据市场需求快速迭代的能力。业务流程的自动化能够帮助企业实现业务的敏捷高效,因此受到越来越多企业的关注。企业的“自动化武器库”品类丰富,包括低/零代码平台、RPA、BPM、AI等。企业可以使用多项自动化工具,但结果往往是各项自动化工具处于各自的“自动化烟囱”之中,仅能实现碎片式自动化。例如,某企业的IT团队可能在使用低代码平台、财务团队可能在使用RPA、呼叫中心则可能在使用聊天机器人。自动
我想了解使用rspec测试多步骤工作流的习惯用法或最佳实践。我们以“购物车”系统为例,其中的购买流程可能是当用户提交购物篮并且我们没有使用https时,重定向到https当用户提交购物篮并且我们使用https并且没有cookie时,创建并显示一个新的购物篮并发回cookie当用户提交到购物车并且我们使用https并且有一个有效的cookie并且新商品与第一个商品用于不同的产品时,向购物车添加一行并显示这两行当用户提交到购物篮并且我们使用https并且有一个有效的cookie并且新商品与之前的商品相同时,增加该购物篮行的数量并显示这两条线当用户点击购物车页面上的“结帐”并使用https并
我问了一个关于目录监视的不同问题,有人回答了这个问题,但问题的另一半是如何最好地在ruby中创建一个永无止境的进程来做到这一点。以下是要求:永远奔跑可监控(即知道它是在运行还是在运行)有某种方法可以重新启动它并确保它正常运行(上帝?)开始/停止使用Capistrano(会很好!)我们看过BackgroundRb,但它似乎有点过时而且老实说不可靠!我们查看了DelayedJob,但这似乎适合一次性工作(因为永无止境的工作似乎会阻止任何其他工作完成,因为工作是按顺序完成的)。我们正在运行构成我们环境的一堆Ubuntu服务器。有什么想法吗? 最佳答案
BigData/CloudComputing:基于阿里云技术产品的人工智能与大数据/云计算/分布式引擎的综合应用案例目录来理解技术交互流程目录一、云计算网站建设:部署与发布网站建设:简单动态网站搭建云服务器管理维护云数据库管理与数据迁移云存储:对象存储管理与安全超大流量网站的负载均衡二、大数据MOOC网站日志分析搭建企业级数据分析平台基于LBS的热点店铺搜索基于机器学习PAI实现精细化营销基于机器学习的客户流失预警分析使用DataV制作实时销售数据可视化大屏使用MaxCompute进行数据质量核查使用Quick BI制作图形化报表使用时间序列分解模型预测商品销量三、云安全云平台使用安全云上服务
基于ffmpeg的视频处理与MPEG的压缩试验ffmpeg介绍与基础知识对提取到的图像进行处理RGB并转化为YUV对YUV进行DCT变换对每个8*8的图像块进行进行量化操作ffmpeg介绍与基础知识ffmpeg是视频和图像处理的工具包,它的下载网址是https://ffmpeg.org/download.html。页面都是英文且下载正确的包的路径笔者找的时候还费点劲,这里记录一下也方便读者。选中这个Windows下的下午files,选择第一个这里有essential和full版本的,大家根据需要自行选择版本包下载下载好之后,在官网上下载ffmpeg的full包,一共300+MB解压,然后安装b
我有一个关于如何在示例之间共享rspec-mocks的double的问题。我正在使用rspec-mocks3.1.3编写一个新的Rails应用程序。我习惯于使用旧的(我有一个模型方法:defself.from_strava(activity_id,race_id,user)@client||=Strava::Api::V3::Client.new(access_token:'abc123')activity=@client.retrieve_an_activity(activity_id)result_details={race_id:race_id,user:user}result_
ElasticSearch——刷盘原理流程刷盘原理流程名词和操作解释相关设置刷盘原理流程整个过程会分成几步:数据会同时写入buffer缓冲区和translog日志文件buffer缓冲区满了或者到时间了(默认1s),就会将其中的数据转换成新的segment并写入系统文件缓存,这一步叫refresh其中后台会自动合并小的segment成大的segment;这一步叫段合并当translog达到大小的阈值(默认512M)或者flush默认时长(30m),则会执行flush操作:内存中数据写入新的segment放入缓存(清空内存区)一个commitpoint写入磁盘,表示哪些segment已写入磁盘将缓
尤其是在考虑新的Rails项目时,您的版本控制和部署工作流程是什么样的?你使用什么工具?我对Mac、*nix和Windows工作机器的答案很感兴趣。假设一个*nix服务器。如果需要,我会为清楚起见进行编辑。 最佳答案 使用预装的插件和卡住的gem创建我的个人Rails2.1.1模板的副本。更改数据库密码、session密码/名称和deploy.rb。根据需要在GitHub上创建私有(private)或公共(public)存储库。将空的Rails项目推送到GitHub。SSH到服务器并配置apache(从旧项目复制虚拟主机文件和mon
我正在尝试了解如何监控travis-ci的resqueworker|与god以这样一种方式停止resquewatchviagod不会留下陈旧的工作进程。在下文中,我谈论的是工作进程,而不是fork作业子进程(即队列一直是空的)。当我像这样手动启动resqueworker时:$QUEUE=buildsrakeresque:work我会得到一个进程:$psx|grepresque7041s001S+0:05.04resque-1.13.0:Waitingforbuilds一旦我停止工作任务,这个过程就会消失。但是当我开始与上帝(exactconfigurationishere,基本上与re