一个 Lucene 索引 我们在 Elasticsearch 称作 分片 。 一个Elasticsearch 索引 是分片的集合。 当 Elasticsearch 在索引中搜索的时候, 他发送查询到每一个属于索引的分片(Lucene 索引),然后合并每个分片的结果到一个全局的结果集。
分片很重要,主要有两方面的原因:
1、允许水平分割 / 扩展我们的内容容量。
2、允许在分片之上进行分布式的、并行的操作,进而提高性能/吞吐量。
分片的配置必须在创建索引的时候就指定分片数量,因为这直接决定了数据的路由规则,索引不支持在运行中的索引进行动态修改,副本则可以。
Elasticsearch 允许你创建分片的一份或多份拷贝,这些拷贝叫做副本分片,目的就是解决在在某个分片或节点因出现问题时候,能提供故障转移的机制。
副本分片很重要,有两个主要原因:
1、在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到副本分片从不与主分片置于同一节点上是非常重要的。
2、扩展你的搜索量/吞吐量,因为搜索可以在所有的副本上并行运行。
在运行中的集群上是可以动态调整副本分片数目的,我们可以按需伸缩集群。让我们把
副本数从默认的 1 增加到 2。
PUT your_index/_settings
{
"number_of_replicas" : 2
}
PUT your_index
{
"mappings" : {
"properties" : {
#索引字段(略)
}
}
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
配置之后总共有3个主分片f1,f2,f3,并且每个分片有自己的一个副本分片,f1-back,f2-back,f3-back,总共6个分片。
1、分片肯定以为着es的集群部署,那么怎样设置分配和副本才能使得集群部署合理呢?
如果我们按照1那样配置,并且只有一台机器
集群健康值:yellow( 3 of 6 ):表示当前集群的全部主分片都正常运行,但是副本分片没有全部处在正常状态。
在同一个节点上既保存原始数据又保存副本是没有意义的,因为一旦失去了那个节点,我们也将丢失该节点 上的所有副本数据。
虽然当前集群是正常运行的,但存在丢失数据的风险。
2、当我们有3台服务器,并且在每个启动的es都配置文件中都完成了集群监听配置
#在节点1配置节点2和3的地址
discovery.seed_hosts: ["localhost:9302", "localhost:9303"]
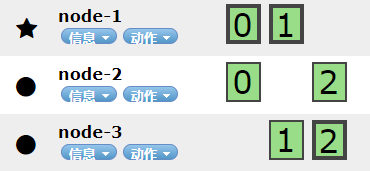
集群健康值:green( 3 of 6 ):表示所有 6 个分片(包括 3 个主分片和 3 个副本分片)都在正常运行。
边框加粗的是主分片,没加粗的是副本分片,从中我们也可以看出es自动分片并没有强迫症,但是却严格遵守水平扩容,以及故障转移的配置规格,但节点一挂了(服务器node-1),此时,副本0(node-2)副本1(node-3)会通过选举成为主分片,保证了索引的正常运行。
当索引一个文档的时候,文档会被存储到一个主分片中。 Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 1 还是分片 2 中呢?首先这肯定不会是随机的,否则将来要获取文档的时候我们就不知道从何处寻找了。实际上,这个过程是根据下面这个公式决定的:
shard = hash(routing) % number_of_primary_shards
新建、删除请求都是写操作, 必须在主分片上面完成之后才能被复制到相关的副本分片。
当删除某个数据时,es并不会直接物理删除,而是将原文档的数据标记为删除,然后重新写入新的文档数据,被标记删除的文档数据,会有一定的策略进行统一收集再真正进行物理删除操作

更新一个文档的部分数据
当主分片把更改转发到副本分片时, 它不会转发更新请求。 相反,它转发完整文档的新版本。请记住,这些更改将会异步转发到副本分片,并且不能保证它们以发送它们相同的顺序到达。 如果 Elasticsearch 仅转发更改请求,则可能以错误的顺序应用更改,导致得到损坏的文档。

Lucene 在新增数据时,采用了延迟写入的策略,默认情况下索引的refresh_interval 为1 秒。
Lucene 将待写入的数据先写到内存中,超过 1 秒(默认)时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将 Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的 Heap 内存。
Flush 的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到 512MB 或者 30 分钟时,会触发一次 Flush。
index.translog.flush_threshold_size 参数的默认值是 512MB,我们进行修改。
增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
ES 为了保证集群的可用性,提供了 Replicas(副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。
当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢。
如果我们需要大批量进行写入操作,可以先禁止Replica复制,设置
index.number_of_replicas: 0 关闭副本。在写入完成后, Replica 修改回正常的状态。
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我在使用omniauth/openid时遇到了一些麻烦。在尝试进行身份验证时,我在日志中发现了这一点:OpenID::FetchingError:Errorfetchinghttps://www.google.com/accounts/o8/.well-known/host-meta?hd=profiles.google.com%2Fmy_username:undefinedmethod`io'fornil:NilClass重要的是undefinedmethodio'fornil:NilClass来自openid/fetchers.rb,在下面的代码片段中:moduleNetclass
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
我想设置一个默认日期,例如实际日期,我该如何设置?还有如何在组合框中设置默认值顺便问一下,date_field_tag和date_field之间有什么区别? 最佳答案 试试这个:将默认日期作为第二个参数传递。youcorrectlysetthedefaultvalueofcomboboxasshowninyourquestion. 关于ruby-on-rails-date_field_tag,如何设置默认日期?[rails上的ruby],我们在StackOverflow上找到一个类似的问
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我正在玩HTML5视频并且在ERB中有以下片段:mp4视频从在我的开发环境中运行的服务器很好地流式传输到chrome。然而firefox显示带有海报图像的视频播放器,但带有一个大X。问题似乎是mongrel不确定ogv扩展的mime类型,并且只返回text/plain,如curl所示:$curl-Ihttp://0.0.0.0:3000/pr6.ogvHTTP/1.1200OKConnection:closeDate:Mon,19Apr201012:33:50GMTLast-Modified:Sun,18Apr201012:46:07GMTContent-Type:text/plain
我在Rails应用程序中使用CarrierWave/Fog将视频上传到AmazonS3。有没有办法判断上传的进度,让我可以显示上传进度如何? 最佳答案 CarrierWave和Fog本身没有这种功能;你需要一个前端uploader来显示进度。当我不得不解决这个问题时,我使用了jQueryfileupload因为我的堆栈中已经有jQuery。甚至还有apostonCarrierWaveintegration因此您只需按照那里的说明操作即可获得适用于您的应用的进度条。 关于ruby-on-r
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon