由于在2月13日,Autojs的作者发出公告将审查所有代码,并在最新版删除了无障碍截图、通知监听等功能,在打开所有版本都会提示强制更新,之前关注的公众号都连夜删除了教程文章,在搜索时,发现教程作者的文章在其它平台还未删除,为了保险起见,备份一下他的文章。由于他写的文章很多,文章将通过爬虫的方式去获取并保存为markdown文件。
参考文章:
在浏览器按F12打开调试模式,访问专栏链接,查看网络请求,可以发现这个就是我们想要的内容。某乎比较友好,返回的是json,直接json解析即可。

def downloadZhuanLanToLocalHtml(zhuanLan,htmlSavePath):
"""
下载知乎专栏文章存入html
:param zhuanLan: 专栏地址 https://www.zhihu.com/column/c_1341718720926887936 地址是c_1341718720926887936
:htmlSavePath: html文件存放路径
"""
# 获取总的文章数量
urlIndex=f"https://www.zhihu.com/api/v4/columns/{zhuanLan}/items"
res=requests.get(urlIndex,headers=headers)
# 知乎比较友好,返回的是json
totals=json.loads(res.text)["paging"]["totals"]
totalPage=totals//100+1 # 获取总页数
for i in range(totalPage):
# limit最大是100,超过会报错
urlpage = 'https://www.zhihu.com/api/v4/columns/{}/items?limit={}&offset={}'.format(zhuanLan, 100, 100*i)
respage = requests.get(urlpage, headers=headers)
data=json.loads(respage.content)['data']
for article in data:
title=article["title"]
content=article["content"]
# 替换标题中的特殊符号,不然创建文件会报错
with open(f'{htmlSavePath}\\{title.replace("?","").replace("?","")}.html',"w",encoding="utf-8") as f:
f.write(content)
print("下载完成")
将保存的html转换为markdown,我们使用第三方库html2text,在使用前请先安装pip install htm2text。
def convertHtml2Markdow(htmlSavePath,mdSavePath):
'''
将所有html转换为md
: htmlSavePath: 存放html文件的文件夹路径
: mdSavePath: 存放markdown文件的文件夹路径
'''
for file in os.listdir(htmlSavePath):
# 获取文件名称
filename=os.path.basename(file).split(".")[0]
text_maker = ht.HTML2Text()
# 读取html格式文件
with open(htmlSavePath+"/"+file, 'r', encoding='UTF-8') as f:
htmlpage = f.read()
# 处理html格式文件中的内容
text = text_maker.handle(htmlpage)
# 写入处理后的内容
with open(mdSavePath+"/"+filename+".md", 'w', encoding='UTF-8') as f:
f.write(text)
获取md文件中的链接,采用正则方式来提取。
def lambdaToGetMarkdownPicturePosition(content):
"""
从markdownd代码中提取图片链接
:param content:
:return:
"""
# 该正则只适合某乎的文章,其它的请自行调整
pattern = re.compile(r"!\[.*?\]\([https|http].*?source=.*?\)")
resultList = pattern.finditer(content)
urlList = []
for item in resultList:
curStr = item.group()
curStr = curStr.split('(')[1]
curStr = curStr.strip(')')
urlList.append(curStr)
print(curStr)
return urlList
将获取到的图片链接,先下载到本地,同时保存号md文件中图片链接和本地图片路径的映射关系,方便后文替换为新的图床的图片链接。
def downloadPic(urls,picSavePath):
'''
下载图片至本地
: urls: 图片路径
:picSavePath: 本地存放图片的文件夹
'''
picMap={}
for url in urls:
res=requests.get(url)
if res.status_code==200:
savePicName=url.split("/")[-1]
with open(f"{picSavePath}/{savePicName.split('?')[0]}","wb") as f:
f.write(res.content)
picMap[url]=f"{picSavePath}/{savePicName.split('?')[0]}"
else:
print("图片下载失败")
return picMap
这一步将本地的图片上传到gitee的图床,gitee提供了开放的api,通过api可以将图片上传至指定仓库。
开放api地址:
https://gitee.com/api/v5/swagger#/postV5ReposOwnerRepoContentsPath
def uploadPicToGitee(picFullPath,access_token="你自己的token",owner="登录的用户名",repo="仓库名",branch="存放的分支",giteeRepoSavePath="仓库下某个目录"):
'''
上传文件到gitee
:picFullPath: 本地图片路径
:giteeRepoSavePath: gitee仓库中文件存放路径
'''
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Connection': 'keep-alive',
'Content-Type': 'application/json;charset=UTF-8',
'Origin': 'https://gitee.com',
'Referer': 'https://gitee.com/api/v5/swagger',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36',
'sec-ch-ua': '"Not_A Brand";v="99", "Google Chrome";v="109", "Chromium";v="109"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
# 将图片进行bas4编码
with open(picFullPath,"rb") as f:
content=base64.b64encode(f.read())
picDir=os.path.dirname(os.path.abspath(picFullPath))
# 切换目录
os.chdir(picDir)
picName=os.path.basename(picFullPath)
data = {
'access_token': access_token,
'content': content,
'message': f'upload-{picName}',
'branch': branch,
}
# 上传文件需要处理data
data=MultipartEncoder(fields=data)
headers['Content-Type']=data.content_type
res = requests.post(f'https://gitee.com/api/v5/repos/{owner}/{repo}/contents/{giteeRepoSavePath}/{picName}', headers=headers, data=data,verify=False)
if res.status_code==201 or res.text=='{"message":"A file with this name already exists"}':
imgUrl=f'https://gitee.com/{owner}/{repo}/raw/{branch}/{giteeRepoSavePath}/{quote(picName)}'
return imgUrl
return None
if __name__=="__main__":
zhuanLan="c_1341718720926887936"
htmlSavePath=r"C:\Users\teisyogun\Desktop\脚本\python_learn\test\test" # 修改为自己html文件的存放地址
mdSavePath=r"C:\Users\teisyogun\Desktop\脚本\python_learn\test\test-md" # 修改为md文件的存放地址
downloadZhuanLanToLocalHtml(zhuanLan,htmlSavePath)
convertHtml2Markdow(htmlSavePath,mdSavePath)
mdSavePath1=r"C:\Users\teisyogun\Desktop\脚本\python_learn\test\test-md\test3" # gitee长时间上传会报超时错误,如果md文件很多,分成多批次上传
picSavePath=r"C:\Users\teisyogun\Desktop\脚本\python_learn\test\test-pic" # 修改为本地图片的存放路径
# 下面的逻辑就是在完成原md文件中图片链接替换为gitee图床的图片链接
for root,dirs,files in os.walk(mdSavePath1):
for filename in files:
mdFullPath=os.path.join(root,filename)
mdBakFullPath=os.path.join(root,filename.replace(".md","-bak.md"))
with open(mdFullPath,"r+",encoding="utf-8") as f,open(mdBakFullPath,"w",encoding="utf-8") as wf:
print(mdFullPath)
mdContent="".join(f.readlines())
urlList=lambdaToGetMarkdownPicturePosition(mdContent)
if len(urlList)!=0:
picMap=downloadPic(urlList,picSavePath)
print(picMap)
if bool(picMap):
for picUrl in picMap:
imgUrl=uploadPicToGitee(picMap[picUrl])
print(imgUrl)
if imgUrl is not None:
mdContent=mdContent.replace(picUrl,imgUrl)
else:
print(f"文件:{filename}中{picMap[picUrl]}替换失败")
wf.write(mdContent)
print(f"{filename}+===替换完成")
else:
wf.write(mdContent)
所有替换后的md文件
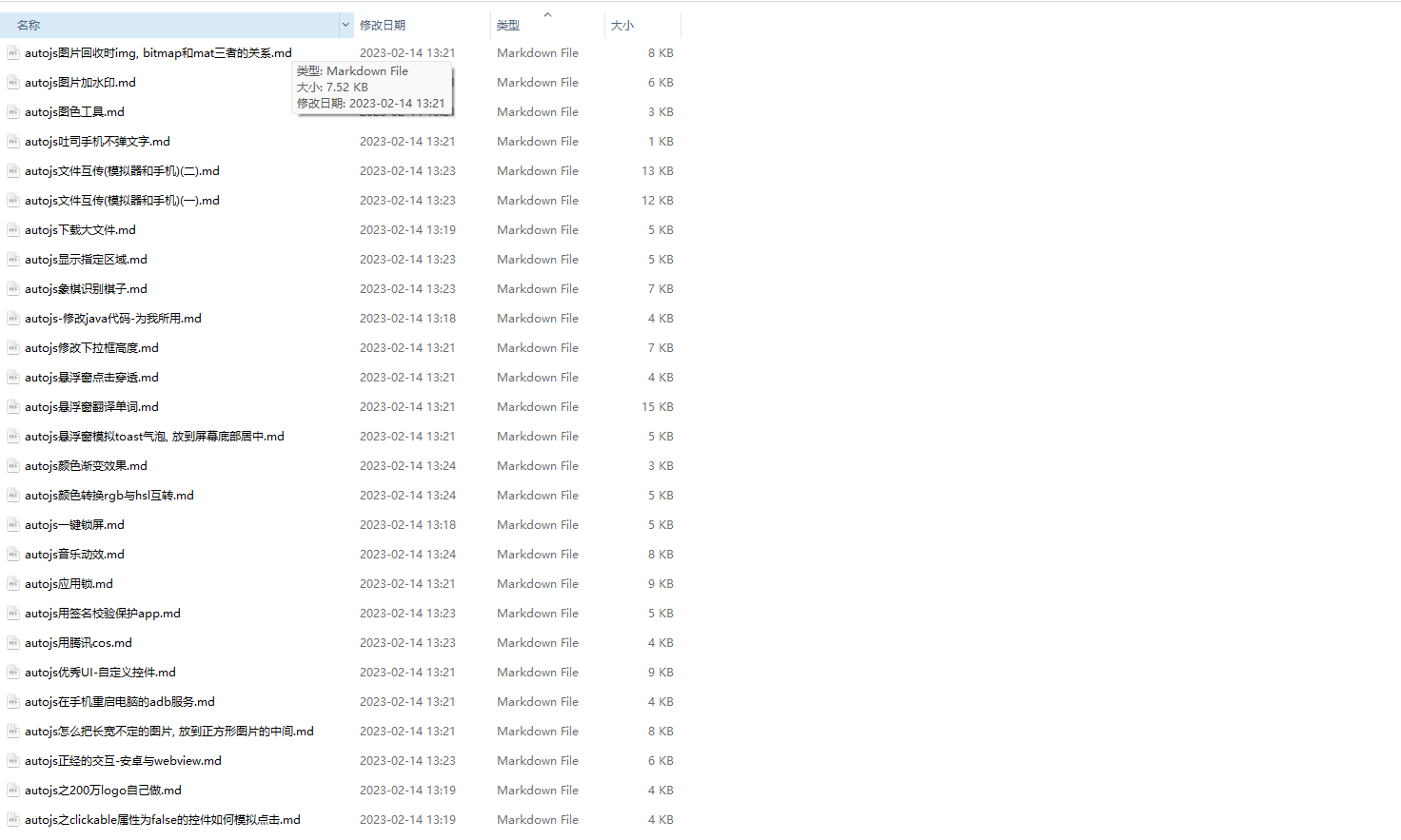
打开带图片的文件,查看源码,发现图片中的文件已经被替换。

在预览模式下查看,图片可以正常显示。至此我们完成了所有的功能。

获取完整代码,请在后台回复【专栏】或在评论区留言。
文章中只是简单实现了需求,代码比较乱,欢迎大家评论指正。
本文由【产品经理不是经理】gzh同步发布,欢迎关注
我正在编写一个小脚本来定位aws存储桶中的特定文件,并创建一个临时验证的url以发送给同事。(理想情况下,这将创建类似于在控制台上右键单击存储桶中的文件并复制链接地址的结果)。我研究过回形针,它似乎不符合这个标准,但我可能只是不知道它的全部功能。我尝试了以下方法:defauthenticated_url(file_name,bucket)AWS::S3::S3Object.url_for(file_name,bucket,:secure=>true,:expires=>20*60)end产生这种类型的结果:...-1.amazonaws.com/file_path/file.zip.A
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
我使用Jekyll运行博客,并认为我会解决RedcarpetMarkdown解释器,因为它是developedandusedbyGitHub.好吧,我只是碰巧遇到了一个错误,去检查问题,然后foundthis.Maintainersays,"Asyouprobablyhavenoticed(harharharhar)Idon'thavetimetomaintainRedcarpetanymore.It'snotapriorityforme(IfindMarkdownthoroughlyboring)andit'snotapriorityforGitHub,becausewenolong
我将Cucumber与Ruby结合使用。通过Selenium-Webdriver在Chrome中运行测试时,我想将下载位置更改为测试文件夹而不是用户下载文件夹。我当前的chrome驱动程序是这样设置的:Capybara.default_driver=:seleniumCapybara.register_driver:seleniumdo|app|Capybara::Selenium::Driver.new(app,:browser=>:chrome,desired_capabilities:{'chromeOptions'=>{'args'=>%w{window-size=1920,1
这会导致Ruby出现内存问题吗?我知道如果大小超过10KB,Open-URI会写入TempFile。但是HTTParty会在写入TempFile之前尝试将整个PDF保存到内存吗?src=Tempfile.new("file.pdf")src.binmodesrc.writeHTTParty.get("large_file.pdf").parsed_response 最佳答案 您可以使用Net::HTTP。参见thedocumentation(特别是标题为“流媒体响应机构”的部分)。这是文档中的示例:uri=URI('http://e
使用Redcarpet,当我在Markdown中包含类似以下内容时,它不考虑任何换行符或缩进。我在行尾尝试了两个空格。代码之间的额外行。似乎没有任何效果。```xml3```我明白了:3这里是Redcarpet设置:Redcarpet::Markdown.new(Redcarpet::Render::HTML,:autolink=>true,:space_after_headers=>true,:fenced_code_blocks=>true,:no_intra_emphasis=>true,:lax_html_blocks=>true)我需要做什么才能正确换行并保留缩进,就像这里或
我正在使用Maruku,将Markdown(超集)转换为HTML,你知道我该怎么做才能从HTML转换为Markdown吗? 最佳答案 Google发现了一个名为reverse_markdown的ruby脚本.它似乎可以满足您的需求。 关于ruby-on-rails-我需要从HTML转到markdown,有什么建议吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/175162
我要下载http://foobar.com/song.mp3作为song.mp3,而不是让Chrome在其native中打开它浏览器中的播放器。我怎样才能做到这一点? 最佳答案 您只需要确保发送这些header:Content-Disposition:attachment;filename=song.mp3;Content-Type:application/octet-streamContent-Transfer-Encoding:binarysend_file方法为您完成:get'/:file'do|file|file=File.
是否可以在不实际下载文件的情况下检查文件是否存在?我有这么大的(~40mb)文件,例如:http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm这与ruby不严格相关,但如果发件人可以设置内容长度就好了。RestClient.get"http://mirrors.sohu.com/mysql/MySQL-6.0/MySQL-6.0.11-0.glibc23.src.rpm",headers:{"Content-Length"=>100} 最佳答案