前一段时间被人问了个问题:在使用ES的过程中有没有做过什么JVM调优措施?
在我搭建ES集群过程中,参照important-settings官方文档来的,并没有对JVM参数做过多的调整。但谈到JVM配置参数,少不了操作系统层面上的一些配置参数,比如 page cache 和文件描述符的个数:(/etc/security/limits.conf)。另外ES jvm.options配置文件也针对JVM参数做了一些优化,这里简要介绍一下ElasticSearch中与jvm相关的各个配置参数:
既然提到了这个参数,我想说一下Linux内存分配、Linux OOM Killer、内存交换vm.swappiness参数 之间的一些理解:当ES进程向操作系统MMU申请分配内存时,操作系统内核分配的是虚拟内存,比如指定 -Xms=16G 那么只是告诉内核这个ES进程在启动的时候最需要16G内存,但是ES进程在启动后并不是立即就用了16G的内存。因此,随着ES的运行,ES进程访问虚拟内存时产生缺页错误(page fault),然后内核为之分配实际的物理页面(这个过程也是需要开销的)。而如果在JVM启动时指定了AlwaysPreTouch,就会分配实际的物理内存,这样在发生YGC的时候,新生代对象晋升到老年代,减少老年代空间分配产生的缺页异常,从而减少YGC停顿时间。
正是由于Linux内存管理机制,应用程序进程可以申请比物理内存大得多的内存,而进程而言,它看到的是逻辑地址空间,因为通过内存交换(vm.swapiness),操作系统允许将那些长期不用的物理页面交换到磁盘上去,因此程序能够申请的内存空间范围是很大的。由于进程可以申请到一块很大的地址空间,但不一定把这些空间都使用了。但万一进程真的实实在在地占用了这么多空间,怎么办?于是OOM Killer 就出马了,OOM Killer 会选择一个进程将之杀死。
在使用CMS垃圾回收器时,jmap -heap 查看jvm实际为ES进程分配的新生代的大小。因为,影响新生代大小的参数有三个:第一个是:-XX:NewSize和-XX:MaxNewSize、第二个是:-Xmn、第三个是:-XX:NewRatio=2。根据参数XX:NewRatio=2 ,ES 进程 jvm新生代堆大小占配置的总的堆的1/3,但其实并没有,就是因为参数:-XX:NewSize和-XX:MaxNewSize 优先级比XX:NewRatio=2高,覆盖了这个参数配置的值。
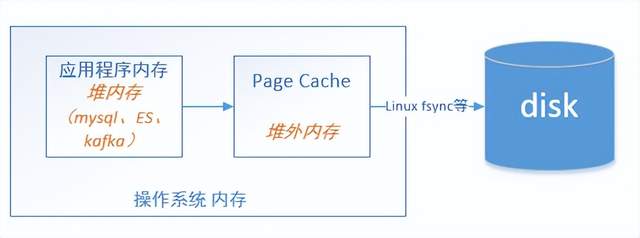
Linux内存可分成2种类型:Page cache和应用程序内存。应用程序内存会被Linux的swap机制交换出去,而page cache则是由Linux后台的异步flush策略刷盘。当OS内存满了时,就需要把一部分内存数据写入磁盘,因此就需要决定是swap应用程序内存呢?还是清理page cache?OS有个系统参数/proc/sys/vm/swappiness默认值60,一般将之设置成0,表示优先刷新page cache而不是将应用程序的内存交换出去。
那Linux的page cache的清除策略是什么呢?--优化了的LRU算法。LRU存在缺点:那些新读取的但却只使用一次的数据占满了LRU列表,反而把热点数据给evict 到磁盘上去了,因此还需要考虑数据的访问次数(频率)
很多存储系统针对LRU做了一些优化,比如Redis的键过期策略是基于LRU算法的思想,用若干个位记录每个key的idle time(空闲时间),将空闲时间较大的key存入pool,从pool中选择key evict出去,具体可参考:Redis的LRU算法。 再比如Mysql innodb 缓冲池管理page也是基于LRU,当新读入一页数据时不是立即放到LRU链表头,而是设置mid point(默认37%),即放到链表37%位置处 。关于如何理解page cache 与应用程序内存之间的区别,可参考这篇文章:从Apache Kafka 重温文件高效读写
Linux总会把系统中还没被应用使用的内存挪来给Page Cache,在命令行输入free,或者cat /proc/meminfo,"Cached"的部分就是Page Cache。
当Linux系统内存不足时,要么就回收page cache,要么就内存交换(swap),而内存交换就有可能把应用程序的数据换出到磁盘上去了,这就有可能造成应用的长时间停顿了。参考:在你的代码之外,服务时延过长的三个追查方向(上)
Linux有个很怪的癖好,当内存不足时,有很大机率不是把用作IO缓存的Page Cache收回,而是把冷的应用内存page out到磁盘上。当这段内存重新要被访问时,再把它重新page in回内存(所谓的主缺页错误),这个过程进程是停顿的。增长缓慢的老生代,池化的堆外内存,都可能被认为是冷内存,用 cat /proc/[pid]/status 看看 VmSwap的大小, 再dstat里看看监控page in发生的时间。
free -m 查看机器的内存使用情况时,其实一直被以下几个概念所困扰。Google了一圈,大部分只是"翻译",没有解释。其实我是想了解这些参数对系统的影响是什么?
man free 查看注释如下,free 命令输出的内容其实就是 /proc/meminfo 中的内容,因此真正的是要理解 /proc/meminfo 中每一行的内容。
free displays the total amount of free and used physical and swap memory in the system, as well as the buffers and caches used by the kernel
随着系统的运行,JVM堆内存会被使用,引用不可达对象就是垃圾对象,而操作系统有可能会把这些垃圾对象(长期未用的物理页面)交换到磁盘上去。当JVM堆使用到一定程度时,触发FullGC,FullGC过程中发现这些未引用的对象都被交换到磁盘上去了,于是JVM垃圾回收进程得把它们重新读回来到内存中,然而戏剧性的是:这些未引用的对象本身就是垃圾,读到内存中的目的是回收被丢弃它们!而这种来回读取磁盘的操作导致了FullGC 消耗了大量时间,(有可能)发生长时间的stop the world。因此,需要禁用内存交换以避免这种现象,这也是为什么在部署Kafka和ES的机器上都应该要禁用内存交换的原因吧(如果因长时间STW导致node与master之间的"心跳包"失效,集群的master节点认为该节点发生了故障,于是是自动进行failover,对于ES来说可能就发生自动rebalance分片迁移)。具体可参考这篇文章:Just say no to swapping!
本文以ES使用的JVM配置参数为示例,记录了一些关于JVM调优的参数理解,以及涉及到的一些关于page cache、应用程序内存区别,LRU算法思想等,它们在Mysql、Kafka、ElasticSearch都有所应用。文中所引用的参考链接都非常好,对深入理解系统底层运行原理有帮助。
ElasticSearch官方文档HowTo也给出了ElasticSearch搜索、索引(Indexing)的调优方案,也值得一看:general-recommendations
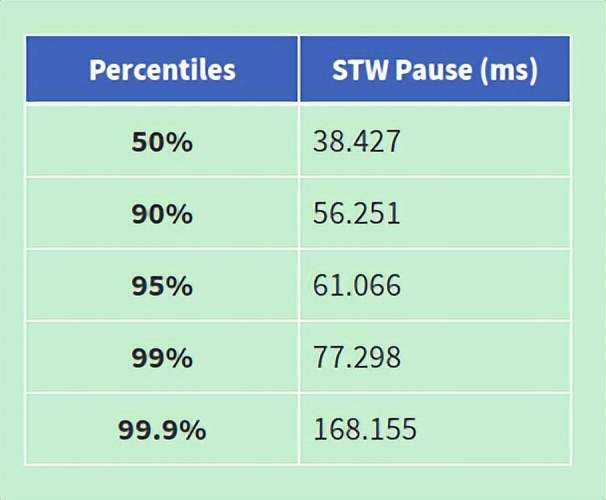
一个统计gc日志的工具:gcplot,以图形化方式显示gc情况。(分析一个ES进程的gc日志得到:99%的gc STW 时间控制在77ms以内)
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
,咱们下期见!答案获取方式:已赞 已评 已关~
学习更多JAVA知识与技巧,关注与私信博主(666)

总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我在我的项目中添加了一个系统来重置用户密码并通过电子邮件将密码发送给他,以防他忘记密码。昨天它运行良好(当我实现它时)。当我今天尝试启动服务器时,出现以下错误。=>BootingWEBrick=>Rails3.2.1applicationstartingindevelopmentonhttp://0.0.0.0:3000=>Callwith-dtodetach=>Ctrl-CtoshutdownserverExiting/Users/vinayshenoy/.rvm/gems/ruby-1.9.3-p0/gems/actionmailer-3.2.1/lib/action_mailer
刚入门rails,开始慢慢理解。有人可以解释或给我一些关于在application_controller中编码的好处或时间和原因的想法吗?有哪些用例。您如何为Rails应用程序使用应用程序Controller?我不想在那里放太多代码,因为据我了解,每个请求都会调用此Controller。这是真的? 最佳答案 ApplicationController实际上是您应用程序中的每个其他Controller都将从中继承的类(尽管这不是强制性的)。我同意不要用太多代码弄乱它并保持干净整洁的态度,尽管在某些情况下ApplicationContr
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我注意到像bundler这样的项目在每个specfile中执行requirespec_helper我还注意到rspec使用选项--require,它允许您在引导rspec时要求一个文件。您还可以将其添加到.rspec文件中,因此只要您运行不带参数的rspec就会添加它。使用上述方法有什么缺点可以解释为什么像bundler这样的项目选择在每个规范文件中都需要spec_helper吗? 最佳答案 我不在Bundler上工作,所以我不能直接谈论他们的做法。并非所有项目都checkin.rspec文件。原因是这个文件,通常按照当前的惯例,只
我正在使用active_admin,我在Rails3应用程序的应用程序中有一个目录管理,其中包含模型和页面的声明。时不时地我也有一个类,当那个类有一个常量时,就像这样:classFooBAR="bar"end然后,我在每个必须在我的Rails应用程序中重新加载一些代码的请求中收到此警告:/Users/pupeno/helloworld/app/admin/billing.rb:12:warning:alreadyinitializedconstantBAR知道发生了什么以及如何避免这些警告吗? 最佳答案 在纯Ruby中:classA