TensorRT 部署Yolov5模型C++
NVIDIA TensorRT™ 是用于高性能深度学习推理的 SDK,可为深度学习推理应用提供低延迟和高吞吐量。详细安装方式参考以下博客: NVIDIA TensorRT 安装 (Windows C++)
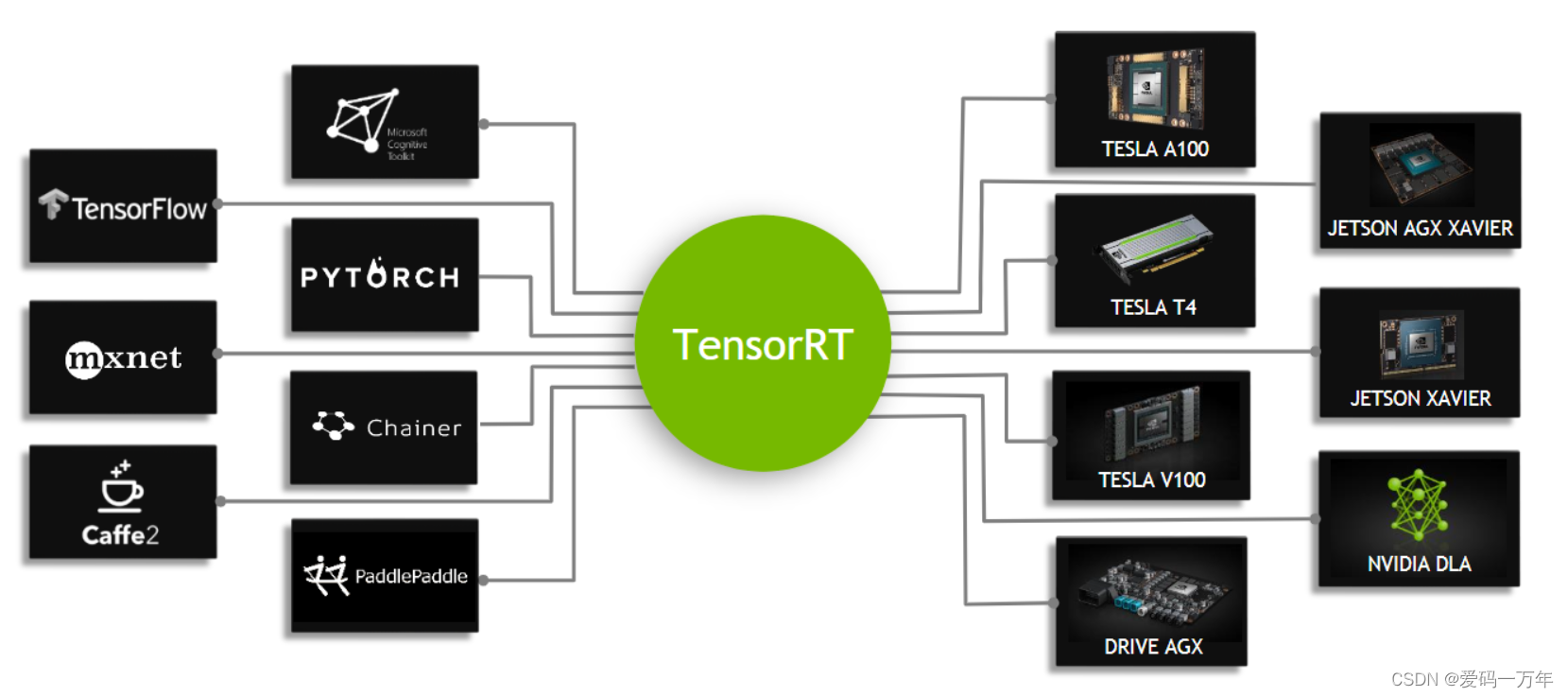
经典的一个TensorRT部署模型步骤为:onnx模型转engine、读取本地模型、创建推理引擎、创建推理上下文、创建GPU显存缓冲区、配置输入数据、模型推理以及处理推理结果。
TensorRT支持多种模型文件,不过随着onnx模型的发展,目前多种模型框架都将onnx模型当作中间转换格式,是的该模型结构变得越来越通用,因此TensorRT目前主要在更新的就是针对该模型的转换。TensorRT是可以直接读取engine文件,对于onnx模型需要进行一些列转换配置,转为engine引擎才可以进行后续的推理,因此在进行模型推理前,需要先进行模型的转换。项目中已经提供了转换方法接口:
void onnx_to_engine(std::string onnx_file_path, std::string engine_file_path, int type) {
// 构建器,获取cuda内核目录以获取最快的实现
// 用于创建config、network、engine的其他对象的核心类
nvinfer1::IBuilder* builder = nvinfer1::createInferBuilder(gLogger);
const auto explicitBatch = 1U << static_cast<uint32_t>(nvinfer1::NetworkDefinitionCreationFlag::kEXPLICIT_BATCH);
// 解析onnx网络文件
// tensorRT模型类
nvinfer1::INetworkDefinition* network = builder->createNetworkV2(explicitBatch);
// onnx文件解析类
// 将onnx文件解析,并填充rensorRT网络结构
nvonnxparser::IParser* parser = nvonnxparser::createParser(*network, gLogger);
// 解析onnx文件
parser->parseFromFile(onnx_file_path.c_str(), 2);
for (int i = 0; i < parser->getNbErrors(); ++i) {
std::cout << "load error: " << parser->getError(i)->desc() << std::endl;
}
printf("tensorRT load mask onnx model successfully!!!...\n");
// 创建推理引擎
// 创建生成器配置对象。
nvinfer1::IBuilderConfig* config = builder->createBuilderConfig();
// 设置最大工作空间大小。
config->setMaxWorkspaceSize(16 * (1 << 20));
// 设置模型输出精度
if (type == 1) {
config->setFlag(nvinfer1::BuilderFlag::kFP16);
}
if (type == 2) {
config->setFlag(nvinfer1::BuilderFlag::kINT8);
}
// 创建推理引擎
nvinfer1::ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
// 将推理银枪保存到本地
std::cout << "try to save engine file now~~~" << std::endl;
std::ofstream file_ptr(engine_file_path, std::ios::binary);
if (!file_ptr) {
std::cerr << "could not open plan output file" << std::endl;
return;
}
// 将模型转化为文件流数据
nvinfer1::IHostMemory* model_stream = engine->serialize();
// 将文件保存到本地
file_ptr.write(reinterpret_cast<const char*>(model_stream->data()), model_stream->size());
// 销毁创建的对象
model_stream->destroy();
engine->destroy();
network->destroy();
parser->destroy();
std::cout << "convert onnx model to TensorRT engine model successfully!" << std::endl;
}
此处读取本地模型为读取上一步保存在本地的engine二进制文件,将模型文件信息读取到内存中。该文件保存了模型的所有信息以及电脑的配置信息,因此该模型文件不支持在不同电脑上使用。
std::ifstream file_ptr(model_path_engine, std::ios::binary);
size_t size = 0;
file_ptr.seekg(0, file_ptr.end); // 将读指针从文件末尾开始移动0个字节
size = file_ptr.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file_ptr.seekg(0, file_ptr.beg); // 将读指针从文件开头开始移动0个字节
char* model_stream = new char[size];
file_ptr.read(model_stream, size);
file_ptr.close();
首先需要初始化日志记录接口类,该类用于创建后续反序列化引擎使用;然后创建反序列化引擎,其主要作用是允许对序列化的功能上不安全的引擎进行反序列化,接下调用反序列化引擎来创建推理引擎,这一步只需要输入上一步中读取的模型文件数据以及长度即可。
// 日志记录接口
Logger logger;
// 反序列化引擎
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 推理引擎
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
这里的推理上下文与OpenVINO中的推理请求相似,为后面进行模型推理的类。
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
TensorRT是利用英伟达显卡进行模型推理的,但是我们的推理数据以及后续处理数据是在内存中实现的,因此需要创建显存缓冲区,用于输入推理数据以及读取推理结果数据。
// 创建GPU显存缓冲区
void** data_buffer = new void* [num_ionode];
// 创建GPU显存输入缓冲区
int input_node_index = engine->getBindingIndex(input_node_name);
cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name);
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));
配置输入数据时只需要调用cudaMemcpyAsync()方法,便可将cuda流数据加载到与i里模型上。但数据需要根据模型要求进行预处理,除此以外需要将数据结果加入到cuda流中。
// 创建输入cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
std::vector<float> input_data(input_data_length);
memcpy(input_data.data(), BN_image.ptr<float>(), input_data_length * sizeof(float));
// 输入数据由内存到GPU显存
cudaMemcpyAsync(data_buffer[input_node_index], input_data.data(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
context->enqueueV2(data_buffer, stream, nullptr);
我们最后处理数据是在内存上实现的,首先需要将数据由显存读取到内存中。
float* result_array = new float[output_data_length];
cudaMemcpyAsync(result_array, data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
接下来就是根据模型输出结果进行数据处理,不同的模型会有不同的数据处理方式。
右击解决方案,选择添加新建项目,添加一个C++空项目,将C++项目命名为:cpp_tensorrt_yolov5。进入项目后,右击源文件,选择添加→新建项→C++文件(cpp),进行的文件的添加。
右击当前项目,进入属性设置,配置TensorRT以及OpenCV的属性。
设置包含目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\include
D:\Program Files\TensorRT-8.4.0.6\include
E:\OpenCV Source\opencv-4.5.5\build\include
E:\OpenCV Source\opencv-4.5.5\build\include\opencv2
设置 ** 库目录**:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.4\lib\x64
D:\Program Files\TensorRT-8.4.0.6\lib
E:\OpenCV Source\opencv-4.5.5\build\x64\vc15\lib
设置附加依赖项:
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
cublas.lib
cublasLt.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cudnn.lib
cudnn64_8.lib
cudnn_adv_infer.lib
cudnn_adv_infer64_8.lib
cudnn_adv_train.lib
cudnn_adv_train64_8.lib
cudnn_cnn_infer.lib
cudnn_cnn_infer64_8.lib
cudnn_cnn_train.lib
cudnn_cnn_train64_8.lib
cudnn_ops_infer.lib
cudnn_ops_infer64_8.lib
cudnn_ops_train.lib
cudnn_ops_train64_8.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusolverMg.lib
cusparse.lib
nppc.lib
nppial.lib
nppicc.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvjpeg.lib
nvml.lib
nvrtc.lib
OpenCL.lib
opencv_world455.lib
const char* model_path_onnx = "E:/Text_Model/yolov5/yolov5s.onnx";
const char* model_path_engine = "E:/Text_Model/yolov5/yolov5s.engine";
const char* image_path = "E:/Text_dataset/YOLOv5/0001.jpg";
std::string lable_path = "E:/Git_space/Al模型部署开发方式/model/yolov5/lable.txt";
const char* input_node_name = "images";
const char* output_node_name = "output";
int num_ionode = 2;
std::ifstream file_ptr(model_path_engine, std::ios::binary);
if (!file_ptr.good()) {
std::cerr << "文件无法打开,请确定文件是否可用!" << std::endl;
}
size_t size = 0;
file_ptr.seekg(0, file_ptr.end); // 将读指针从文件末尾开始移动0个字节
size = file_ptr.tellg(); // 返回读指针的位置,此时读指针的位置就是文件的字节数
file_ptr.seekg(0, file_ptr.beg); // 将读指针从文件开头开始移动0个字节
char* model_stream = new char[size];
file_ptr.read(model_stream, size);
file_ptr.close();
在此处我们需要初始化反序列化引擎以及推理引擎,并创建用于推理的上下文。
Logger logger;
// 反序列化引擎
nvinfer1::IRuntime* runtime = nvinfer1::createInferRuntime(logger);
// 推理引擎
nvinfer1::ICudaEngine* engine = runtime->deserializeCudaEngine(model_stream, size);
// 上下文
nvinfer1::IExecutionContext* context = engine->createExecutionContext();
GPU显存缓冲区的数量主要与模型的输入输出节点有关,我们在此处只需要按照模型输入输出的节点数量进行设置。
void** data_buffer = new void* [num_ionode];
// 创建GPU显存输入缓冲区
int input_node_index = engine->getBindingIndex(input_node_name);
nvinfer1::Dims input_node_dim = engine->getBindingDimensions(input_node_index);
size_t input_data_length = input_node_dim.d[1]* input_node_dim.d[2] * input_node_dim.d[3];
cudaMalloc(&(data_buffer[input_node_index]), input_data_length * sizeof(float));
// 创建GPU显存输出缓冲区
int output_node_index = engine->getBindingIndex(output_node_name);
nvinfer1::Dims output_node_dim = engine->getBindingDimensions(output_node_index);
size_t output_data_length = output_node_dim.d[1] * output_node_dim.d[2] ;
cudaMalloc(&(data_buffer[output_node_index]), output_data_length * sizeof(float));
首先对输入图片按照模型数据输入要求进行处理,首先是将图片数据复制到正方形背景中,然后交换RGB通道、缩放至指定大小以及归一化处理,在OpenCV中,blobFromImage()方法可以直接实现上述功能。
// 图象预处理 - 格式化操作
cv::Mat image = cv::imread(image_path);
int max_side_length = std::max(image.cols, image.rows);
cv::Mat max_image = cv::Mat::zeros(cv::Size(max_side_length, max_side_length), CV_8UC3);
cv::Rect roi(0, 0, image.cols, image.rows);
image.copyTo(max_image(roi));
// 将图像归一化,并放缩到指定大小
cv::Size input_node_shape(input_node_dim.d[2], input_node_dim.d[3]);
cv::Mat BN_image = cv::dnn::blobFromImage(max_image, 1 / 255.0, input_node_shape, cv::Scalar(0, 0, 0), true, false);
接下来创建cuda流,将处理后的数据放置在input_data容器里;最后直接使用cudaMemcpyAsync()方法,将输入数据输送到显存。
// 创建输入cuda流
cudaStream_t stream;
cudaStreamCreate(&stream);
std::vector<float> input_data(input_data_length);
memcpy(input_data.data(), BN_image.ptr<float>(), input_data_length * sizeof(float));
// 输入数据由内存到GPU显存
cudaMemcpyAsync(data_buffer[input_node_index], input_data.data(), input_data_length * sizeof(float), cudaMemcpyHostToDevice, stream);
context->enqueueV2(data_buffer, stream, nullptr);
首先读取推理结果数据,主要是将GPU显存上的推理数据结果赋值到内存上,方便后续对数据的进一步处理。
float* result_array = new float[output_data_length];
cudaMemcpyAsync(result_array, data_buffer[output_node_index], output_data_length * sizeof(float), cudaMemcpyDeviceToHost, stream);
接下来就是处理数据,Yolov5输出结果为85x25200大小的数组,其中没85个数据为一组,在该项目中我们提供了专门用于处理yolov5数据结果的结果处理类,因此在此处我们只需要调用该结果类即可:
ResultYolov5 result;
result.factor = max_side_length / (float) input_node_dim.d[2];
result.read_class_names(lable_path);
cv::Mat result_image = result.yolov5_result(image, result_array);
下图为我们测试效果。

我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我有一个包含模块的模型。我想在模块中覆盖模型的访问器方法。例如:classBlah这显然行不通。有什么想法可以实现吗? 最佳答案 您的代码看起来是正确的。我们正在毫无困难地使用这个确切的模式。如果我没记错的话,Rails使用#method_missing作为属性setter,因此您的模块将优先,阻止ActiveRecord的setter。如果您正在使用ActiveSupport::Concern(参见thisblogpost),那么您的实例方法需要进入一个特殊的模块:classBlah
我有一个表单,其中有很多字段取自数组(而不是模型或对象)。我如何验证这些字段的存在?solve_problem_pathdo|f|%>... 最佳答案 创建一个简单的类来包装请求参数并使用ActiveModel::Validations。#definedsomewhere,atthesimplest:require'ostruct'classSolvetrue#youcouldevencheckthesolutionwithavalidatorvalidatedoerrors.add(:base,"WRONG!!!")unlesss
我想向我的Controller传递一个参数,它是一个简单的复选框,但我不知道如何在模型的form_for中引入它,这是我的观点:{:id=>'go_finance'}do|f|%>Transferirde:para:Entrada:"input",:placeholder=>"Quantofoiganho?"%>Saída:"output",:placeholder=>"Quantofoigasto?"%>Nota:我想做一个额外的复选框,但我该怎么做,模型中没有一个对象,而是一个要检查的对象,以便在Controller中创建一个ifelse,如果没有检查,请帮助我,非常感谢,谢谢
我有一些非常大的模型,我必须将它们迁移到最新版本的Rails。这些模型有相当多的验证(User有大约50个验证)。是否可以将所有这些验证移动到另一个文件中?说app/models/validations/user_validations.rb。如果可以,有人可以提供示例吗? 最佳答案 您可以为此使用关注点:#app/models/validations/user_validations.rbrequire'active_support/concern'moduleUserValidationsextendActiveSupport:
对于Rails模型,是否可以/建议让一个类的成员不持久保存到数据库中?我想将用户最后选择的类型存储在session变量中。由于我无法从我的模型中设置session变量,我想将值存储在一个“虚拟”类成员中,该成员只是将值传递回Controller。你能有这样的类(class)成员吗? 最佳答案 将非持久属性添加到Rails模型就像任何其他Ruby类一样:classUser扩展解释:在Ruby中,所有实例变量都是私有(private)的,不需要在赋值前定义。attr_accessor创建一个setter和getter方法:classUs
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
ruby如何管理内存。例如:如果我们在执行过程中采用C程序,则以下是内存模型。类似于这个ruby如何处理内存。C:__________________|||stack|||------------------||||------------------|||||Heap|||||__________________|||data|__________________|text|__________________Ruby:? 最佳答案 Ruby中没有“内存”这样的东西。Class#allocate分配一个对象并返回该对象。这就是程序