本文主要是对ES基本概念进行整合,理论先行,夯实对ES的基本概念,在知道“是什么”,才能提高学习效率,保姆级学习教程请移步: ES入门笔记.
Elasticsearch(简称ES)是一个基于Apache Lucene™的开源搜索引擎,无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。注意,Lucene 只是一个库。想要发挥其强大的作用,你需使用 Java 并要将其集成到你的应用中。
Lucene 非常复杂,你需要深入的了解检索相关知识来理解它是如何工作的,就跟学习 springmvc 之前先从 servlet 开始,繁琐复杂的工作,Solor、Elasticsearch 应由而生, 其使用 Java 编写并使用 Lucene 来建立索引并实现搜索功能,但是它的目的是通过简单连贯的 RESTful API 让全文搜索变得简单并隐藏 Lucene 的复杂性。
重要特性:
1、分布式的实时文件存储,每个字段都被索引并可被搜索
2、实时分析的分布式搜索引擎
3、可以扩展到上百台服务器,处理PB级结构化或非结构化数据
基本概念:
索引(indices)-------------------Databases 数据库
类型(type)----------------------Table 数据表
文档(Document)---------------Row 行
字段(Field)---------------------Columns 列
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
案例:背诵诗词,静夜思,原本用诗名检索全文,现在没有索引的情况让你说去带“前”的诗句只能将大脑中所有诗词进行遍历;
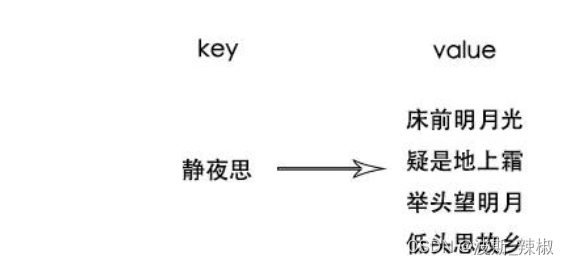
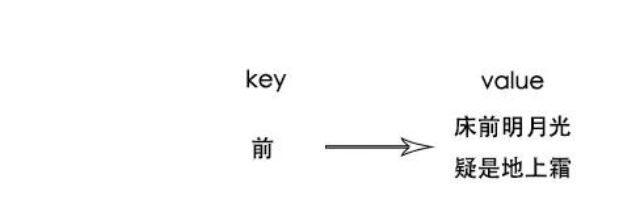
所以可以取诗句中的字当作索引快速获取数据;当然反向索引的建立数据量激增,文章越长,索引越长
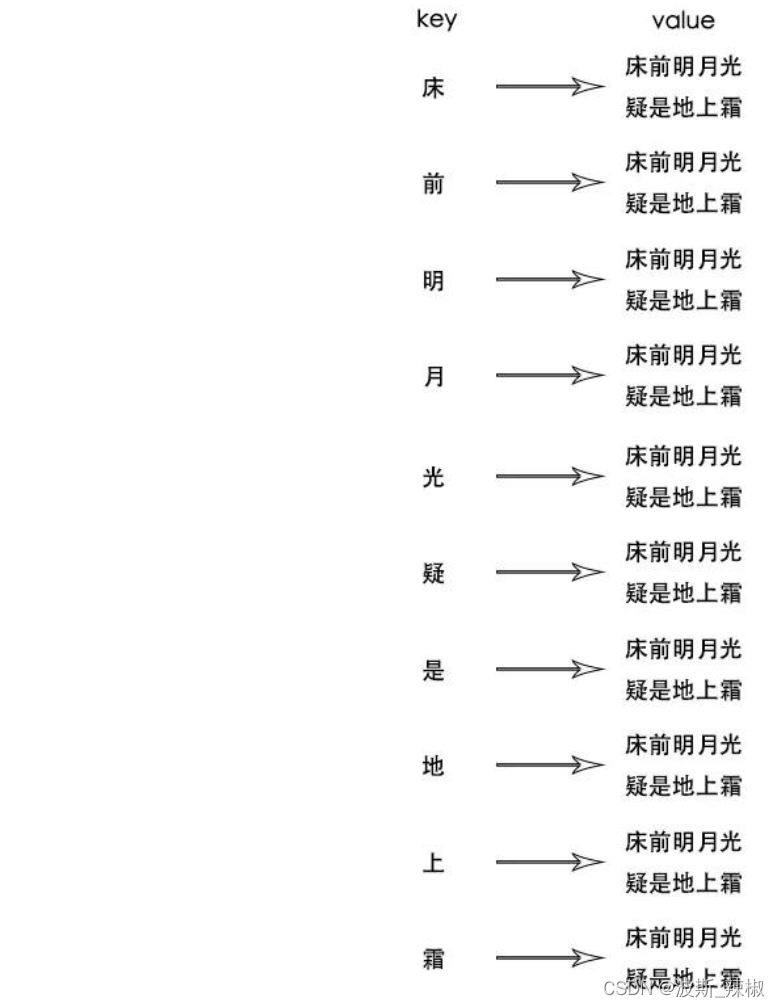
所以这个时候可以做一个压缩,既然已经可以用诗名来获取诗句;那就没必要索引到诗句了,直接索引到诗名就可以了
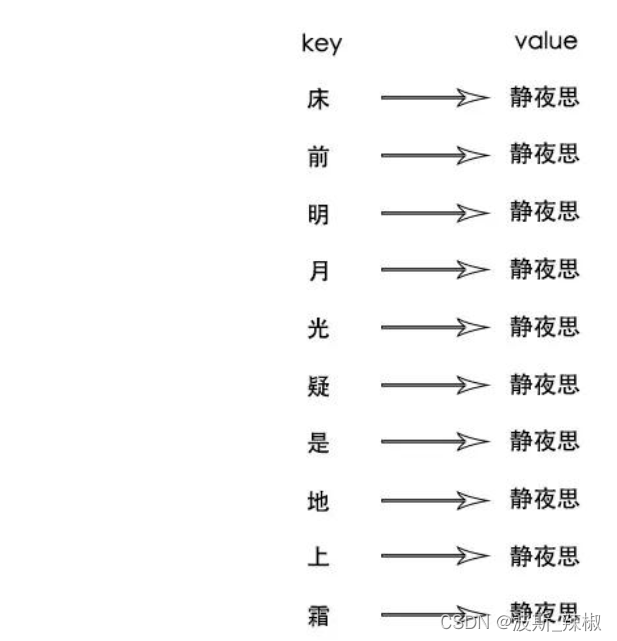
value现在不存诗句,改存诗名,这样数据量会减少很多;同时这里的诗名可以看作是正向索引;
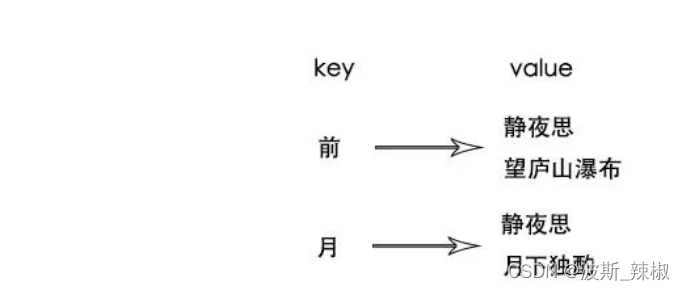
当然这还是只有一首诗的情况,多首诗还会形成索引矩阵:
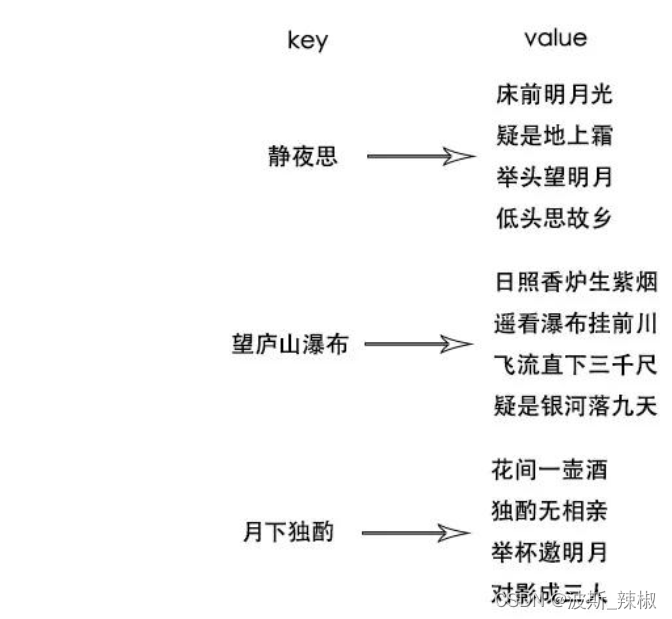
捋一下他们的关系

则可以根据情况来建立索引
其实像百度、谷歌等搜索引擎的原理,和刚刚背诗是一样的,最核心的都是建立倒排索引!
搜索引擎都是对文章分词之后,再根据关键字建立倒排索引
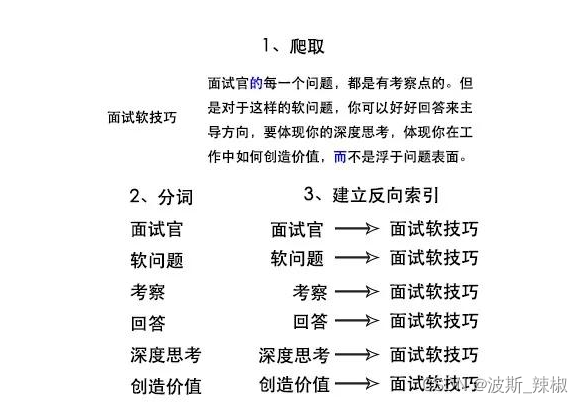
搜索引擎三大过程:爬取内容、进行分词、建立反向索引
比如一首诗,有诗题、作者、朝代、字数、诗内容等字段,那么首先,我们可以建立一个名叫 Poems 的索引,然后创建一个名叫 Poem 的类型,类型是通过 Mapping 来定义每个字段的类型。

类型相当于表结构的描述,描述每个字段的类型,文档以json形式描述一行数据
Keyword和text虽然都死字符串;但是涉及到分词的问题,keyword类型是不会分词的,直接用其中的内容建立反向索引;Text 类型在存入 Elasticsearch 的时候,会先分词,然后根据分词后的内容建立反向索引
建立索引
Elasticsearch 把操作都封装成了 HTTP 的 API,我们只要给 Elasticsearch 发送 HTTP 请求就行。
比如使用 curl -XPUT ‘http://ip:port/poems’,就能建立一个名为 Poems 的索引,其他操作也是类似的。
Elasticsearch 也是会对数据进行切分,同时每一个分片会保存多个副本,其原因和 HDFS (hadoop分布式文件系统)是一样的,都是为了保证分布式环境下的高可用。

绿色表示数据块,其实elasticsearch中数据块也是备份存储至多个节点中的;所以elasticsearch也是master-slave(主从)框架;在 Elasticsearch 中,节点是对等的,节点间会通过自己的一些规则选取集群的 Master,Master 会负责集群状态信息的改变,并同步给其他节点。
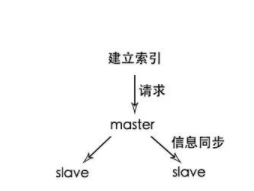
如图所示,建立索引的请求先发到master,master建立索引后,然后这个信息再同步给其他节点(将集群状态同步至slave),建立mapping也是类似的
Elasticsearch除了做搜索引擎,还有一些其他典型的应用场景;很多公司都用 Elasticsearch 搭建 ELK 系统,也就是日志分析系统。其中 E 就是 Elasticsearch,L 是 Logstash,是一个日志收集系统,K 是 Kibana,是一个数据可视化平台。
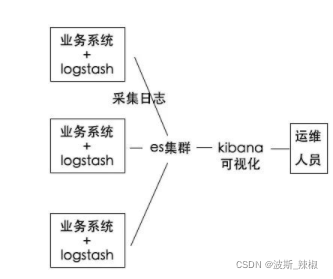
Logstash采集业务系统日志,存储到es中,通过kibana展现给运维人员分析。分析日志的用处很大,假如一个分布式系统有 1000 台机器,系统出现故障时,我要看下日志,还得一台一台登录上去查看,非常麻烦;但是如果日志接入了 ELK 系统就不一样。比如系统运行过程中,突然出现了异常,在日志中就能及时反馈,日志进入 ELK 系统中,我们直接在 Kibana 就能看到日志情况。如果再接入一些实时计算模块,还能做实时报警功能。
写入性能会不会很低?
注意:只有建立索引和类型需要经过 Master,数据的写入有一个简单的 Routing 规则,可以 Route 到集群中的任意节点,所以数据写入压力是分散在整个集群的。
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
Rails相对较新。我正在尝试调用一个API,它应该向我返回一个唯一的URL。我的应用程序中捆绑了HTTParty。我已经创建了一个UniqueNumberController,并且我已经阅读了几个HTTParty指南,直到我想要什么,但也许我只是有点迷路,真的不知道该怎么做。基本上,我需要做的就是调用API,获取它返回的URL,然后将该URL插入到用户的数据库中。谁能给我指出正确的方向或与我分享一些代码? 最佳答案 假设API为JSON格式并返回如下数据:{"url":"http://example.com/unique-url"
我正在尝试复制此GETcurl请求:curl-D--XGET-H"Authorization:BasicdGVzdEB0YXByZXNlYXJjaC5jb206NGMzMTg2Mjg4YWUyM2ZkOTY2MWNiNWRmY2NlMTkzMGU="-H"Content-Type:application/json"http://staging.example.com/api/v1/campaigns在Ruby中,通过电子邮件+apikey生成身份验证:auth="Basic"+Base64::encode64("test@example.com:4c3186288ae23fd9661c
不知何故,我似乎无法获得包含我的聚合的响应...使用curl它按预期工作:HBZUMB01$curl-XPOST"http://localhost:9200/contents/_search"-d'{"size":0,"aggs":{"sport_count":{"value_count":{"field":"dwid"}}}}'我收到回复:{"took":4,"timed_out":false,"_shards":{"total":5,"successful":5,"failed":0},"hits":{"total":90,"max_score":0.0,"hits":[]},"a
1.回顾.TransportServicepublicclassTransportServiceextendsAbstractLifecycleComponentTransportService:方法:1publicfinalTextendsTransportResponse>voidsendRequest(finalTransport.Connectionconnection,finalStringaction,finalTransportRequestrequest,finalTransportRequestOptionsoptions,TransportResponseHandlerT>
文章目录一、项目场景二、基本模块原理与调试方法分析——信源部分:三、信号处理部分和显示部分:四、基本的通信链路搭建:四、特殊模块:interpretedMATLABfunction:五、总结和坑点提醒一、项目场景 最近一个任务是使用simulink搭建一个MIMO串扰消除的链路,并用实际收到的数据进行测试,在搭建的过程中也遇到了不少的问题(当然这比vivado里面的debug好不知道多少倍)。准备趁着这个机会,先以一个很基本的通信链路对simulink基础和相关的debug方法进行总结。 在本篇中,主要记录simulink的基本原理和基本的SISO通信传输链路(QPSK方式),计划在下篇记
我有一个Rails应用程序,现在设置了ElasticSearch和Tiregem以在模型上进行搜索,我想知道我应该如何设置我的应用程序以对模型中的某些索引进行模糊字符串匹配。我将我的模型设置为索引标题、描述等内容,但我想对其中一些进行模糊字符串匹配,但我不确定在何处进行此操作。如果您想发表评论,我将在下面包含我的代码!谢谢!在Controller中:defsearch@resource=Resource.search(params[:q],:page=>(params[:page]||1),:per_page=>15,load:true)end在模型中:classResource'Us
我找不到任何使用Rack::Session::Cookie的简单示例,并且希望能够将信息存储在cookie中,并在以后的请求中访问它并让它过期.这些是我能找到的唯一示例:HowdoIset/getsessionvarsinaRackapp?http://rack.rubyforge.org/doc/classes/Rack/Session/Cookie.html这是我得到的:useRack::Session::Cookie,:key=>'rack.session',:domain=>'foo.com',:path=>'/',:expire_after=>2592000,:secret=
我正在尝试使用GnipPowerTrackAPI,这需要我使用基本身份验证连接到JSON的HTTPS流。我觉得这应该是相当微不足道的,所以我希望一些比我聪明的rubyist可以指出我明显的错误。这是我的ruby1.9.3代码的相关部分:require'eventmachine'require'em-http'require'json'usage="#{$0}"abortusageunlessuser=ARGV.shiftabortusageunlesspassword=ARGV.shiftGNIP_STREAMING_URL='https://stream.gnip.com:4