hana数据库实时同步目前接触到有两种方式,一种是通过kafka connector的方式,定时全量或增量的拉取数据发送到kafka,这算是一种伪实时的方式;还有一种hana本身支持cdc,但是像Debezium这种实时增量同步工具并没有提供对应的connectors,通过查阅hana官方文档,目前好像只能在sap系统基础上通过graph编程的方式来搞,他是一种可视化的组件开发方式,目前暂无sap环境,打不开这个可视化的graph编程页面,不好尝试
目前先介绍第一种伪实时的数据同步方式
kafka原生没有提供连接sap的connector,基于github上开源的项目kafka-connector-hana来实现,github地址:GitHub - SAP/kafka-connect-sap: Kafka Connect SAP is a set of connectors, using the Apache Kafka Connect framework for reliably connecting Kafka with SAP systems
步骤:
1.项目下载,打包
在modules目录下会生成两个jar包,区分不同的scala版本
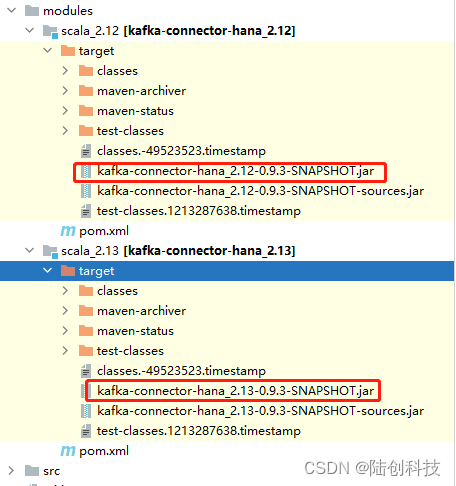
由于我们的kafka环境是scala2.13版本,所以此处采用kafka-connector-hana_2.13-0.9.3-SNAPSHOT.jar
2. 部署
将kafka-connector-hana_2.13-0.9.3-SNAPSHOT.jar和sap的jdbc驱动包ngdbc-2.5.49.jar放置到kafka环境的libs目录中
示例:
1.定时全量同步表TEST_TABLE1数据到kafka
创建配置文件connect-hana-source-1.properties,将文件放置到kafka环境的config目录
name=test-topic-1-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
topics=test_topic_1
connection.url=jdbc:sap://10.88.36.186:39017?reconnect=true
connection.user=SYSTEM
connection.password=1234@Qwer!
test_topic_1.table.name="TEST"."TEST_TABLE1"
test_topic_1.poll.interval.ms=60000执行如下命令:
./bin/connect-standalone.sh config/connect-standalone.properties config/connect-hana-source-1.propertieskafka将接收到如下消息,包含了字段信息和记录信息

2.定时增量同步表TEST_TABLE1数据到kafka
创建配置文件connect-hana-source-2.properties,将文件放置到kafka环境的config目录
(增量同步,要求表中有增量标识字段)
name=test-topic-2-source
connector.class=com.sap.kafka.connect.source.hana.HANASourceConnector
tasks.max=1
mode=incrementing
topics=test_topic_2
connection.url=jdbc:sap://10.88.36.186:39017?reconnect=true
connection.user=SYSTEM
connection.password=1234@Qwer!
test_topic_2.table.name="TEST"."TEST_TABLE1"
test_topic_2.poll.interval.ms=10000
test_topic_2.incrementing.column.name=ID往表中插入两条数据,kafka收到的消息如下:

可以看到此处都是增量的消息
配置说明:
topics - This setting can be used to specify a comma-separated list of topics. Must not have spaces.
mode- This setting can be used to specify the mode in which data should be fetched from SAP DB table. Default is bulk. And supported values are bulk, incrementing.
queryMode- This setting can be used to specify the query mode in which data should be fetched from SAP DB table. Default is table. And supported values are table, query ( to support sql queries ). When using queryMode: query it is also required to have query parameter defined. This query parameter needs to be prepended by TopicName. If the incrementing.column.name property is used together to constrain the result, then it can be omitted from its where clause.
{topic}.table.name- This setting allows specifying the SAP DB table name where the data needs to be read from. Should be a String. Must be compatible to SAP DB Table name like "SCHEMA"."TABLE".
{topic}.query- This setting allows specifying the query statement when queryMode is set to query. Should be a String.
{topic}.poll.interval.ms- This setting allows specifying the poll interval at which the data should be fetched from SAP DB table. Should be an Integer. Default value is 60000.
{topic}.incrementing.column.name- In order to fetch data from a SAP DB table when mode is set to incrementing, an incremental ( or auto-incremental ) column needs to be provided. The type of the column can be numeric types such as INTEGER, FLOAT, DECIMAL, datetime types such as DATE, TIME, TIMESTAMP, and character types VARCHAR, NVARCHAR containing alpha-numeric characters. This considers SAP DB Timeseries tables also. Should be a valid column name ( respresented as a String) present in the table. See data types in SAP HANA
{topic}.partition.count- This setting can be used to specify the no. of topic partitions that the Source connector can use to publish the data. Should be an Integer. Default value is 1.
基于官方的cdc方案
官方文档中所描述的sap的cdc,是基于触发器实现的

如果要体验sap本身提供的该功能,需安装SAP Data Intelligence,所需服务器资源比较大,而且要求是3个节点,部署教程:
[Quick Start Guide – Part I] Installing SAP Data Intelligence on Red Hat Openshift | SAP Blogs
如果不在此平台操作,我们自己的实现思路是这样(该思路也是网上找到的):
1.创建目标表的日志表
-- 目标表
CREATE COLUMN TABLE "PAX" ("ID" INTEGER CS_INT GENERATED BY DEFAULT AS IDENTITY, "NAME" VARCHAR(64), PRIMARY KEY ("ID")) UNLOAD PRIORITY 5 AUTO MERGE ;
-- 目标表的日志表
CREATE COLUMN TABLE "PAX_JOURNAL" ("ID_JOURNAL" INTEGER CS_INT GENERATED BY DEFAULT AS IDENTITY, "ACTION_JOURNAL" VARCHAR(1), "TIMESTAMP_JOURNAL" LONGDATE CS_LONGDATE, "ID" INTEGER CS_INT, "NAME" VARCHAR(64), PRIMARY KEY("ID_JOURNAL")) UNLOAD PRIORITY 5 AUTO MERGE ;2.创建触发器trigger,监听目标表的insert,update,delete操作,在目标表有此类操作时,会将日志写到对应的日志表中
--触发器,此处只监听了update
CREATE TRIGGER "TRG_PAX_AFTER_ROW_UPDATE" AFTER
UPDATE
ON
"PAX" REFERENCING NEW ROW mynewrow FOR EACH ROW
BEGIN
INSERT
INTO
PAX_JOURNAL (ACTION_JOURNAL, TIMESTAMP_JOURNAL, ID, NAME)
VALUES ('U', CURRENT_TIMESTAMP, :mynewrow.ID, :mynewrow.NAME);
end;3.采用本文档上半部分所描述的kafka-connector,定时读取日志表中的内容发送至kafka平台
(猜想:既然sap的cdc是基于trigger实现,那么SAP Data Intelligence平台上的基于图形化的hana cdc组件最底层也是采用trigger实现,只不过做了层封装,如自动建日志表,自动建trigger,然后将change log写到targets)
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
参考文章搭建文章gitte源码在线体验可以注册两个号来测试演示图:一.整体介绍 介绍SignalR一种通讯模型Hub(中心模型,或者叫集线器模型),调用这个模型写好的方法,去发送消息。 内容有: ①:Hub模型的方法介绍 ②:服务器端代码介绍 ③:前端vue3安装并调用后端方法 ④:聊天室样例整体流程:1、进入网站->调用连接SignalR的方法2、与好友发送消息->调用SignalR的自定义方法 前端通过,signalR内置方法.invoke() 去请求接口3、监听接受方法(渲染消息)通过new signalR.HubConnectionBuilder().on
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。要求我们推荐或查找工具、库或最喜欢的场外资源的问题对于StackOverflow来说是偏离主题的,因为它们往往会吸引自以为是的答案和垃圾邮件。相反,describetheproblem以及迄今为止为解决该问题所做的工作。关闭9年前。Improvethisquestion我想知道是否有人知道Ruby的rubyzip替代品,它可以处理各种格式,特别是zip/rar/7z?我知道libarchive,但它对我的目的来说并不完整(它是一个很好的gem)。(澄清一下,libarchive-对我不起作用-因为
我爱Sanitize.这是一个了不起的实用程序。我遇到的唯一问题是,它需要永远准备一个开发环境,因为它使用Nokogiri,这对编译时间来说是一种痛苦。是否有任何程序可以在不使用Nokogiri的情况下执行Sanitize的操作(如果没有别的,只是温和地执行它的操作)?这将以指数方式提供帮助! 最佳答案 Rails有自己的SanitizeHelper。根据http://api.rubyonrails.org/classes/ActionView/Helpers/SanitizeHelper.html,它将Thissanitizehe
类似的问题,但对于java,Keepingi18nresourcessynced如何保持i18nyamllocals的key同步?即,当将key添加到en.yml时,如何将它们添加到nb.yml或ru.yml?如果我在my_title:"atitle"旁边添加键my_label:"sometextinenglish"我想把它给我的其他本地人我指定,因为我不能做所有的翻译,它应该回到其他语言的英语例如en.ymlsomegroup:my_tile:"atitleinenglish"my_label:"sometextinenglish"othergroup:...我想发出命令,将整个键和
在Rails3.x应用程序中,我正在使用net::ssh并向远程pc运行一些命令。我想向用户的浏览器显示实时日志。比如,如果两个命令在net中运行::ssh执行即echo"Hello",echo"Bye"被传递然后"Hello"应该在执行后立即显示在浏览器中。这是代码我在rubyonrails应用程序中使用ssh连接和运行命令Net::SSH.start(@servers['local'],@machine_name,:password=>@machine_pwd,:timeout=>30)do|ssh|ssh.open_channeldo|channel|channel.requ
我尝试每天在我的Rails应用程序中自动记录一些数据。我想知道是否有人知道一个好的解决方案?我找到了https://github.com/javan/whenever,但我想确保在选择之前了解所有选项。谢谢!艾略特 最佳答案 我真的很喜欢whenever-这是一个很棒的Gem,我已经在生产中使用了它。关于它还有一个很好的Railscasts插曲:http://railscasts.com/episodes/164-cron-in-ruby 关于ruby-on-rails-rails3中c
我正在寻找一个很好的基于角色的授权解决方案来与Authlogic一起使用。有人有什么好的建议吗?如果可能,请根据您的经验列出一些优缺点。 最佳答案 Acl9与AuthLogic配合得很好:http://github.com/be9/acl9/tree/master 关于ruby-on-rails-与Authlogic一起使用的一些好的角色授权解决方案是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c