本次爬取的目标是,2021年胡润百富榜的榜单数据:胡润百富 - 榜单
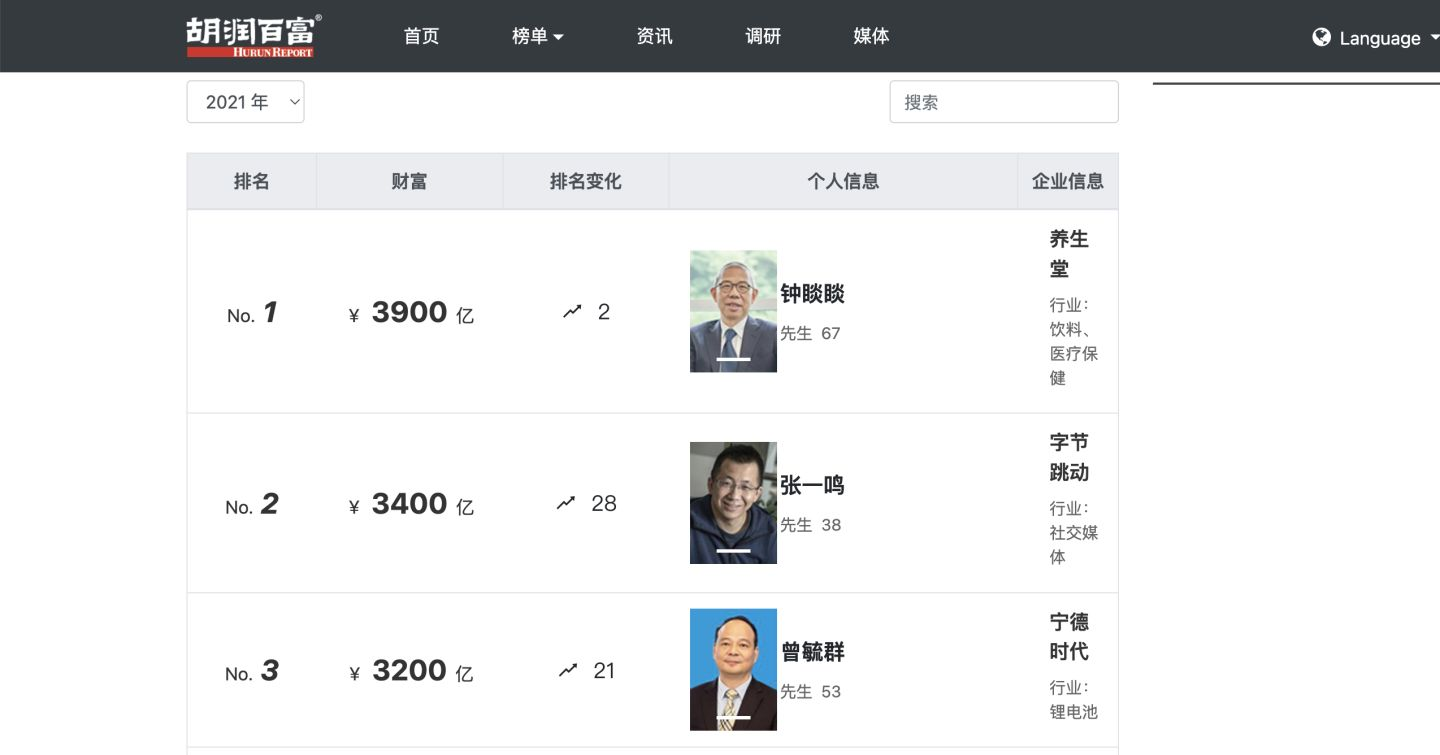
页面上能看到的信息有:
排名、财富值、排名变化、个人信息(姓名、性别、年龄)、企业信息(企业名称、所属行业)
页面结构很整齐,数据也很完整,非常适合爬虫和数据分析使用。
老规矩,打开Chrome浏览器,按F12进入开发者模式,依次点击Network->Fetch/XHR,准备好捕获ajax请求。
重新刷新一下页面,发现一条请求:

在预览界面,看到一共20条(0~19)返回数据,正好对应页面上的20个富豪信息。
所以,后面编写爬虫代码,针对这个地址发送请求就可以了。
另外,关于翻页,我的个人习惯是,选择每页显示最多的数据量,这样能保证少翻页几次,少发送几次请求,防止被对端服务器反爬。
所以,每页选择200条数据:

再刷新一下页面,进行几次翻页,观察请求地址的变化规律:
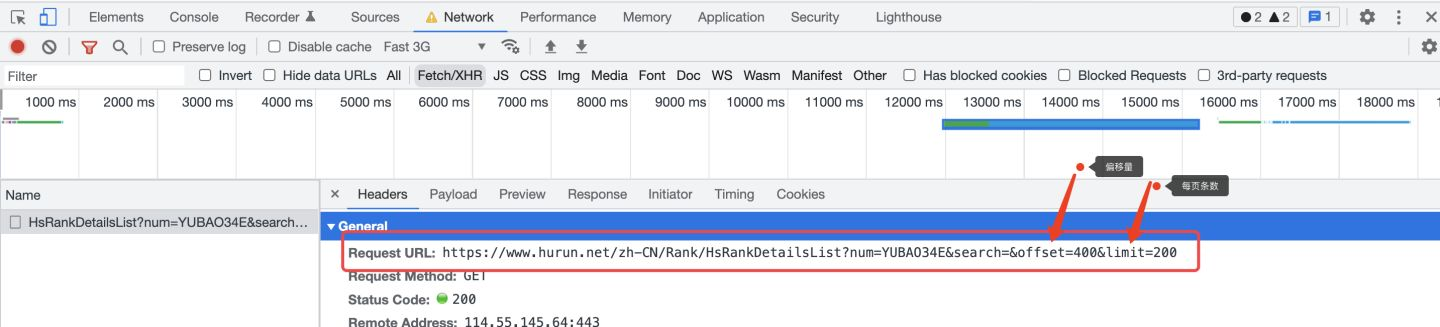
以翻到第3页为例,url中的offset(偏移量)为400,limit(每页的条数)为200,所以,可得出规律:
offset = (page - 1) * 200
limit = 200
下面开始编写爬虫代码。
首先,导入需要用到的库:
import requests # 发送请求
import pandas as pd # 存入excel数据
from time import sleep # 等待间隔,防止反爬
import random # 随机等待
根据1.2章节分析得出的结论,编写逻辑代码,向页面发送请求:
# 循环请求1-15页
for page in range(1, 16):
# 胡润百富榜地址
sleep_seconds = random.uniform(1, 2)
print('开始等待{}秒'.format(sleep_seconds))
sleep(sleep_seconds)
print('开始爬取第{}页'.format(page))
offset = (page - 1) * 200
url = 'https://www.hurun.net/zh-CN/Rank/HsRankDetailsList?num=YUBAO34E&search=&offset={}&limit=200'.format(offset)
# 构造请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Mobile Safari/537.36',
'accept': 'application/json, text/javascript, */*; q=0.01',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
'accept-encoding': 'gzip, deflate, br',
'content-type': 'application/json',
'referer': 'https://www.hurun.net/zh-CN/Rank/HsRankDetails?pagetype=rich'
}
# 发送请求
r = requests.get(url, headers=headers)
用json格式解析返回的请求数据:(一行代码即可完成接收)
json_data = r.json()
由于解析的字段较多,这里不再赘述详细过程,字段信息包含:
Fullname_Cn_list = [] # 全名_中文
Fullname_En_list = [] # 全名_英文
Age_list = [] # 年龄
BirthPlace_Cn_list = [] # 出生地_中文
BirthPlace_En_list = [] # 出生地_英文
Gender_list = [] # 性别
Photo_list = [] # 照片
ComName_Cn_list = [] # 公司名称_中文
ComName_En_list = [] # 公司名称_英文
ComHeadquarters_Cn_list = [] # 公司总部地_中文
ComHeadquarters_En_list = [] # 公司总部地_英文
Industry_Cn_list = [] # 所在行业_中文
Industry_En_list = [] # 所在行业_英文
Ranking_list = [] # 排名
Ranking_Change_list = [] # 排名变化
Relations_list = [] # 组织结构
Wealth_list = [] # 财富值_人民币_亿
Wealth_Change_list = [] # 财富值变化
Wealth_USD_list = [] # 财富值_美元
Year_list = [] # 年份
最后,依然采用我最习惯的保存数据的方法,先拼装DataFrame数据:
df = pd.DataFrame( # 拼装爬取到的数据为DataFrame
{
'排名': Ranking_list,
'排名变化': Ranking_Change_list,
'全名_中文': Fullname_Cn_list,
'全名_英文': Fullname_En_list,
'年龄': Age_list,
'出生地_中文': BirthPlace_Cn_list,
'出生地_英文': BirthPlace_En_list,
'性别': Gender_list,
'照片': Photo_list,
'公司名称_中文': ComName_Cn_list,
'公司名称_英文': ComName_En_list,
'公司总部地_中文': ComHeadquarters_Cn_list,
'公司总部地_英文': ComHeadquarters_En_list,
'所在行业_中文': Industry_Cn_list,
'所在行业_英文': Industry_En_list,
'组织结构': Relations_list,
'财富值_人民币_亿': Wealth_list,
'财富值变化': Wealth_Change_list,
'财富值_美元': Wealth_USD_list,
'年份': Year_list
}
)
再用pandas的to_csv方法保存:
# 保存结果数据
df.to_csv('2021胡润百富榜.csv', mode='a+', index=False, header=header, encoding='utf_8_sig')
注意,加上这个编码格式选项(utf_8_sig),否则产生乱码哦。
爬虫开发完成,下面展示结果数据。
看一下榜单上TOP20的数据吧:
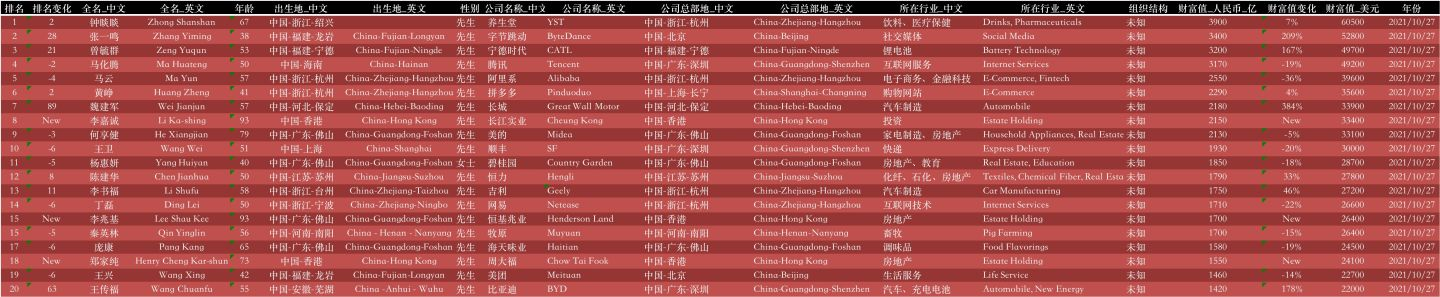
数据一共2916条,19个字段信息,含:
排名、排名变化、全名_中文、全名_英文、年龄、出生地_中文、出生地_英文、性别、公司名称_中文、公司名称_英文、公司总部地_中文、公司总部地_英文、所在行业_中文、所在行业_英文、组织结构、财富值_人民币_亿、财富值变化、 财富值_美元、年份。
数据信息还是很丰富的,希望能够挖掘出一些有价值的结论!
首先,导入用于数据分析的库:
import pandas as pd # 读取csv文件
import matplotlib.pyplot as plt # 画图
from wordcloud import WordCloud # 词云图
增加一个配置项,用于解决matplotlib中文乱码的问题:
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签 # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
读取csv数据:
# 读取csv数据
df = pd.read_csv('2021胡润百富榜.csv')
查看数据形状:

查看前3名富豪:

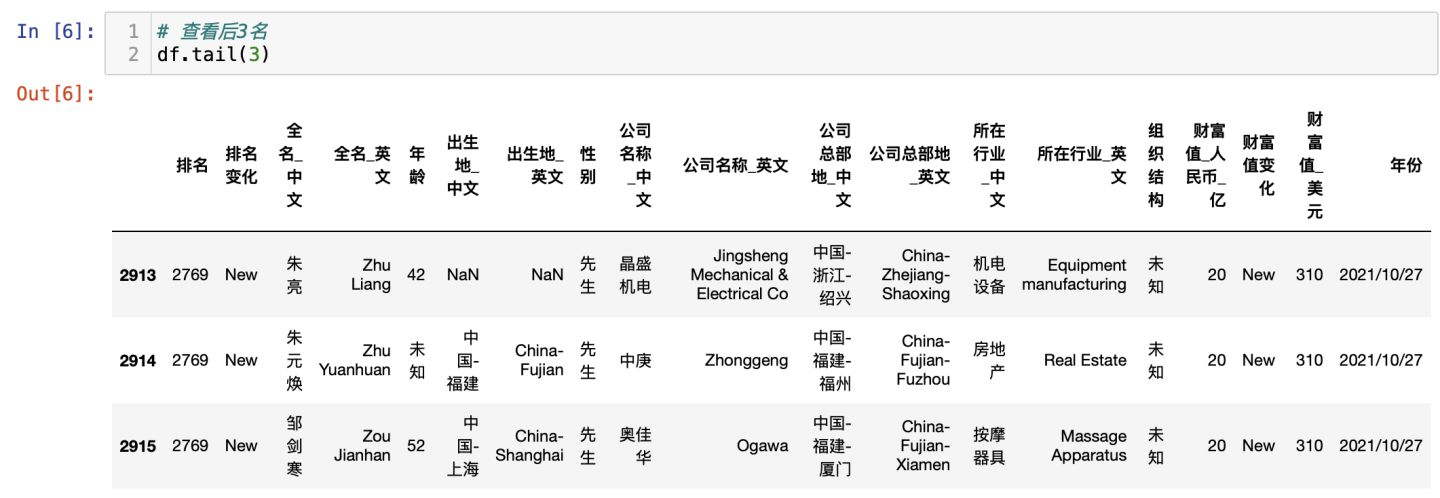
查看最后3名富豪:
描述性统计:

从描述性统计,可以得出结论:
从最大值3900亿、最小值20亿、方差242来看,分布很零散,各位富豪掌握的财富差距很大,马太效应明显。
代码:
df_Wealth = df['财富值_人民币_亿']
# 绘图
df_Wealth.plot.hist(figsize=(18, 6), grid=True, title='财富分布-直方图')
# 保存图片
plt.savefig('财富分布-直方图.png')
可视化图:

结论:大部分的富豪的财富集中在20亿~400亿之间,个别顶级富豪的财富在3000亿以上。
代码:
# 剔除未知
df_Age = df[df.年龄 != '未知']
# 数据切割,8个分段
df_Age_cut = pd.cut(df_Age.年龄.astype(float), bins=[20, 30, 40, 50, 60, 70, 80, 90, 100])
# 画柱形图
df_Age_cut.value_counts().plot.bar(figsize=(16, 6), title='年龄分布-柱形图')
# 保存图片
plt.savefig('年龄分布-柱形图.png')
可视化图:
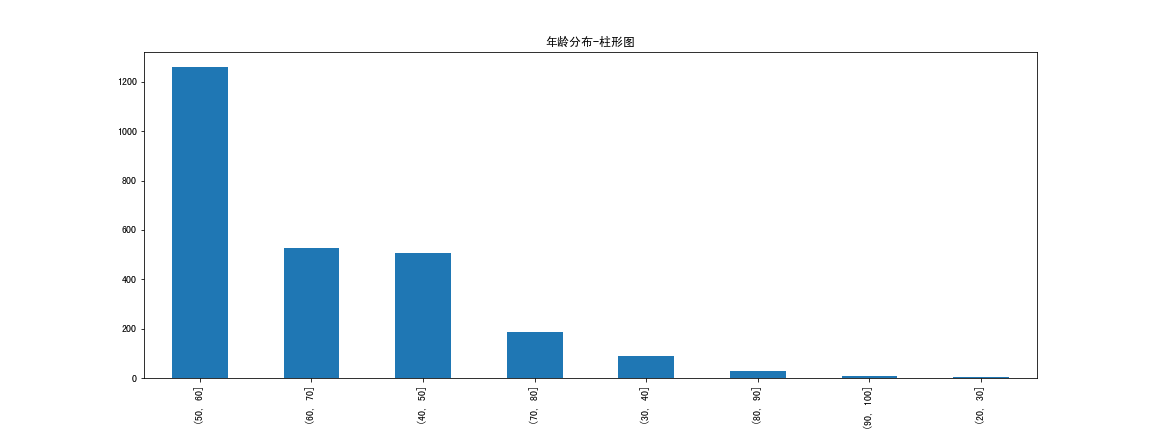
结论:大部分富豪的年龄在50-60岁,其次是60-70和40-50岁。极少数富豪在20-30岁(年轻有为?)
代码:
df_ComHeadquarters = df['公司总部地_中文'].value_counts()
# 绘图
df_ComHeadquarters.nlargest(n=30).plot.bar(
figsize=(16, 6), # 图片大小
grid=False, # 显示网格
title='公司总部分布TOP30-柱形图' # 图片标题
)
# 保存图片
plt.savefig('公司总部分布TOP30-柱形图.png')
可视化图:

结论:公司分布城市,大多集中在北上广深等一线城市,另外杭州、香港、苏州也位列前茅。
代码:
df_Gender = df['性别'].value_counts()
# 绘图
df_Gender.plot.pie(
figsize=(8, 8), # 图片大小
legend=True, # 显示图例
autopct='%1.2f%%', # 百分比格式
title='性别占比分布-饼图', # 图片标题
)
# 保存图片
plt.savefig('性别占比分布-饼图.png')
可视化图:
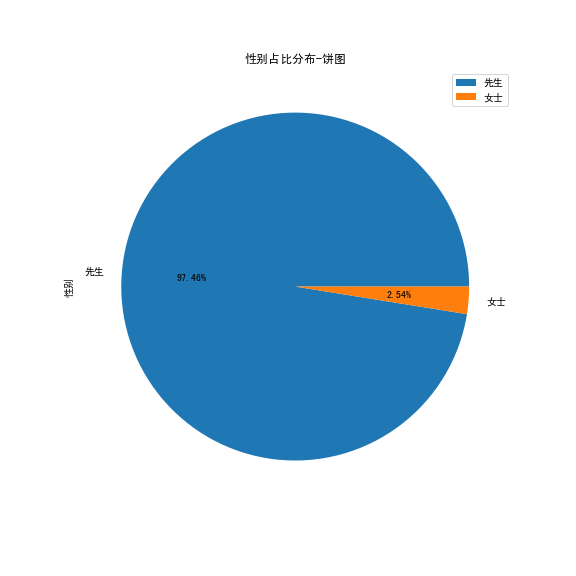
结论:男性富豪占据绝大多数,个别女性在列(巾帼不让须眉?)
代码:
df_Industry = df['所在行业_中文'].value_counts()
df_Industry.nlargest(n=20).plot.bar(
figsize=(18, 6), # 图片大小
grid=False, # 显示网格
title='行业分布TOP20-柱形图' # 图片标题
)
# 保存图片
plt.savefig('行业分布TOP20-柱形图.png')
可视化图:

结论:百富榜中占比最多的行业分别是:房地产、医药、投资、化工等。
代码:
df_Relations = df['组织结构'].value_counts()
# 绘图
df_Relations.plot.pie(
figsize=(8, 8), # 图片大小
legend=True, # 显示图例
autopct='%1.2f%%', # 百分比格式
title='组织结构分布-饼图', # 图片标题
)
# 保存图片
plt.savefig('组织结构分布-饼图.png')
可视化图:

结论:半数以上是未知,企业未对外开放,或榜单没有统计到;家族和夫妇占据前两类。
代码:
ComName_list = df['公司名称_中文'].values.tolist()
ComName_str = ' '.join(ComName_list)
stopwords = [] # 停用词
# backgroud_Image = np.array(Image.open('幻灯片2.png')) # 读取背景图片
wc = WordCloud(
scale=3, # 清晰度
background_color="white", # 背景颜色
max_words=1000,#最大字符数
width=800, # 图宽
height=500, # 图高
font_path='/System/Library/Fonts/SimHei.ttf', # 字体文件路径,根据实际情况替换
stopwords=stopwords, # 停用词
# mask=backgroud_Image, # 背景图片
)
wc.generate_from_text(ComName_str) # 生成词云图
wc.to_file('2021胡润百富榜_公司名称_词云图.png') # 保存图片
wc.to_image() # 显示图片
可视化图:

结论:阿里系公司占据榜首,其次是海天味业等。
综上所述,针对2021年胡润百富榜的榜单数据,得出如下结论:
财富分布:大部分的富豪的财富集中在20亿~400亿之间,个别顶级富豪的财富在3000亿以上。
年龄分布:大部分富豪的年龄在50-60岁,其次是60-70和40-50岁。极少数富豪在20-30岁(年轻有为?)
城市分布:公司分布城市,大多集中在北上广深等一线城市,另外杭州、香港、苏州也位列前茅
性别分布:男性富豪占据绝大多数,个别女性在列(巾帼不让须眉?)
行业分布:百富榜中占比最多的行业分别是:房地产、医药、投资、化工等
组织结构分布:半数以上是未知,企业未对外开放,或榜单没有统计到;家族和夫妇占据前两类。
公司名称分布:阿里系公司占据榜首,其次是海天味业等。
爬虫讲解视频:
https://www.zhihu.com/zvideo/1492523459087896577
可视化讲解视频:
https://www.zhihu.com/zvideo/1492525821340729344
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我即将开始一个将录制和编辑音频文件的项目,我正在寻找一个好的库(最好是Ruby,但会考虑Java或.NET以外的任何库)以进行实时可视化波形。有人知道我应该从哪里开始搜索吗? 最佳答案 要流入浏览器的数据量很大。Flash或Flex图表可能是唯一能提高内存效率的解决方案。Javascript图表往往会因大型数据集而崩溃。 关于ruby-Ruby中的波形可视化,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.c
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit