文章目录
在给大家详细介绍RAM之前,先设想这么一个实际场景:某芯片,一次完整的输出需要1024个14位数据,该芯片开始工作后会循环持续的输出这1024个数据,但是,用户希望能够通过串口来改变这1024个数据的内容,以让该芯片在不同的工作阶段,获得的数据内容是不一样的。
这类实际需求有哪些特点呢?
1.数据量相对较大
2.数据要求能被更改
3.数据要能重复使用
所以为了解决这个问题,我们需要一个可读可写的存储器,RAM(random access memory),或者说RAM就是可以写的ROM。
RAM 是随机存取存储器(Random Access Memory)的简称,是一个易失性存储器。RAM 工作时可以随时从任何一个指定的地址写入或读出数据,同时我们还能修改其存储的数据,即写入新的数据,这是 ROM 所并不具备的功能。在 FPGA 中这也是其与 ROM 的最大区别。ROM 是只读存储器,而 RAM 是可写可读存储器,在我们 FPGA 中使用这两个存储器主要也是要区分这一点,因为这两个存储器使用的都是我们 FPGA 内部的 RAM 资源,不同的是 ROM 是只用到了 RAM 资源的读数据端口。RAM也可以提前添加了数据文件(.coe 格式)。
Xilinx 推出的 RAM IP 核分为两种类型:单端口 RAM 和双端口 RAM。其中双端口RAM 又分为简单双端口 RAM 和真正双端口 RAM。对于单端口 RAM,读写操作共用一组地址线,读写操作不能同时进行;对于简单双端口 RAM,读操作和写操作有专用地址端口(一个读端口和一个写端口),即写端口只能写不能读,而读端口只能读不能写;对于真正双端口 RAM,有两个地址端口用于读写操作(两个读/写端口),即两个端口都可以进行读写。具体差异,见下文。
新建 Vivado 工程,单击 IPCatalog,由于赛灵思 IP 将 RAM 和 ROM 一同归属于存储器件类,所以我们在右边窗口 Search 位置输入 ROM,在 Memories & Storage Elements 下可以看到有两个与 RAM 创建的入口,一个是 Distributed Memory Generator,另一个是 Block Memory Generator,两者最主要的差别是生成的 Core 所占用的 FPGA 资源不一样,从Distributed Memory Generator 生成的 ROM/RAM Core 占用的资源是 LUT(查找表,查找表本质就是一个小的 RAM);从 Block Memory Generator 生成的 ROM/RAM Core 占用的资源是 Block Memory(嵌入式的硬件 RAM)。这个就和 ROM 创建类似,用户根据实际资源使用需求选择创建的入口。关于ROM IP核的内容可以参考我的另一篇博客:IP核的使用之ROM(Vivado)。
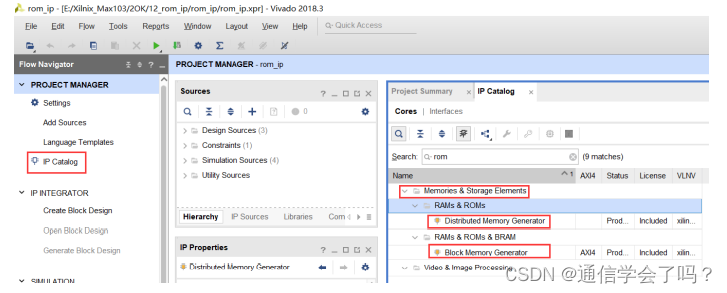
选择 Block Memory Generator 双击鼠标进入到 RAM IP 配置界面。
端口类型的选择,Xilinx 的很多 IP 一般都有提供两种接口,一种是常规接口,一种是AXI 接口,这里选择常规接口 Native。
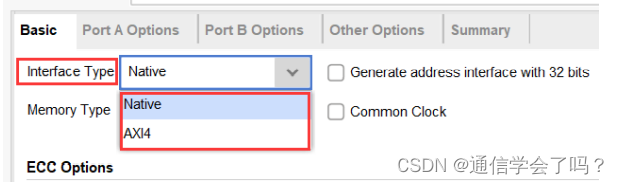
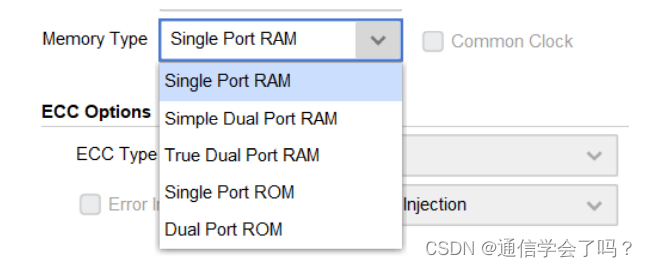
存储器类型的选择,与上一节不同,我们本节主要探讨 RAM 类存储器,对于 RAM 而言,有三种可选项,单端口 RAM、简单双端口 RAM 和真双端口 RAM。具体的差异我们可以通过依次选择,然后观察窗口左边 RAM 端口来进行对比。
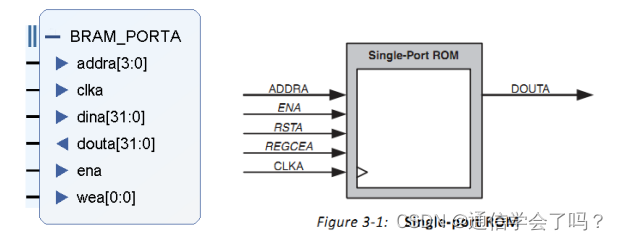
① 单端口 RAM:读写一个时钟,读写不能同时进行。
②简单双端口 RAM:相较单端口 RAM,多出一个 PORTB,有两个时钟,可以同时读写,PORTA 只能写数据,PORTB 只能进行读数据。
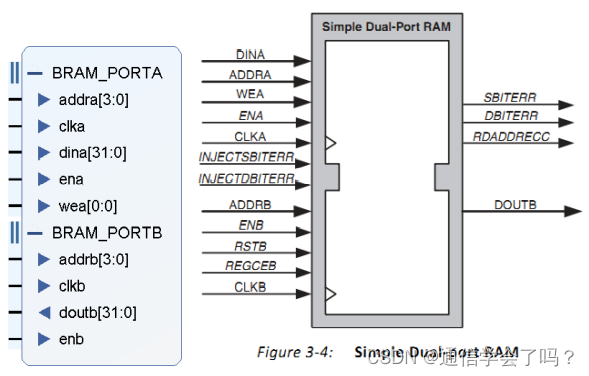
③真双端口 RAM:两个 PORT,分别有自己的时钟,地址,输入/输出数据端口,两个端口均可进行读写操作
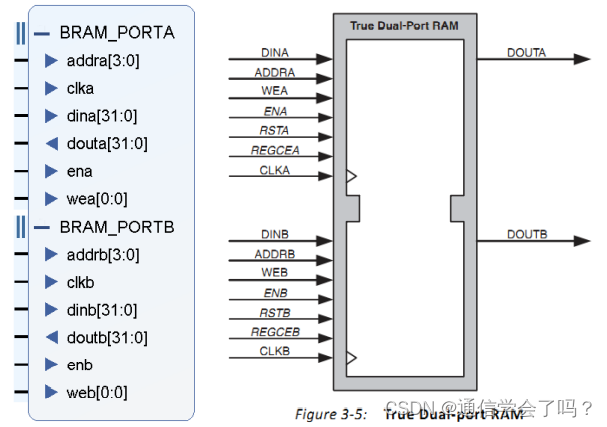
这里我们选择简单双端口 RAM(Simple Dual Port RAM)。
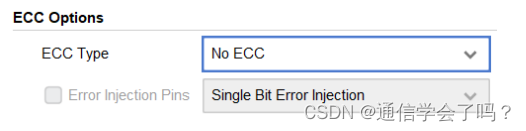
ECC 全称是 Error Correction Capability,是在简单双端口 RAM 类型下的一种纠错功能,具体该功能的详细说明,可以查看 IP 手册,这里选择 NO ECC。
写数据字节使能,如果勾选,写使能信号会根据写数据的字节数生成对应的 bit 数据,1 个字节对应 1bit 写使能,这里字节的大小可以设置为 8 或 9,当这里的选择后,输入输出的数据的位宽就必须是 8 或 9 的整数倍,这里我们需要一个位宽为 8bit 的 RAM,这里勾选Write Enable 并设置字节大小为 8bit。

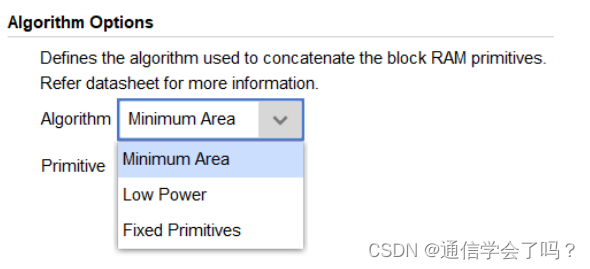
算法类型,有三种选项可选,最小面积、低功耗、固定原语。这里不过多讲解,需要了解更多的可以查阅 IP 手册,IP 手册上面 42 页开始有对这个详细的讲解。这里我们保持默认的最小面积选项即可。
RAM 数据位宽和深度设置,这个根据实际应用需求进行设置,这里设置数据位宽 8bit,深度 256。
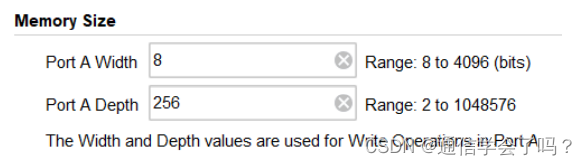
操作模式设置,这里有三个可选项,这里的设置主要是针对在同时对同一地址进行读操作和写操作时,读出数据是写入的最新数据、该地址原来的数据、读数据不变化。
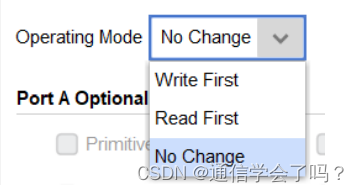
Write First 模式下的波形,如果仅读出数据而未发生数据的同时读写,则读出存储器以前存储的数据,如果发生数据的同时读写,读出数据为刚从数据总线送入的数据,而不考虑该地址以前存储的数据。
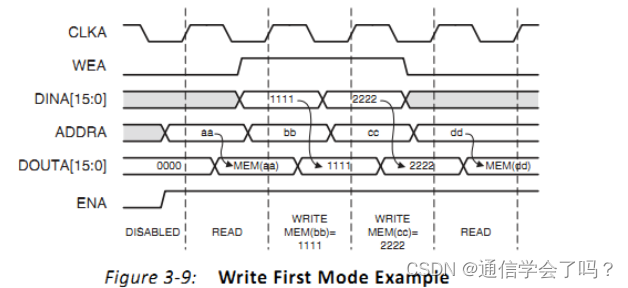
Read First 模式下的波形,同时对同一地址读写,读出数据为上次刚写入该地址以前的数据,忽略正在写数据这一事件对读出数据的影响。
No Change 模式下波形,读出的数据只有在进行读操作但未进行写操作时更新数据,在同时读写数据时,读出数据保持不变。
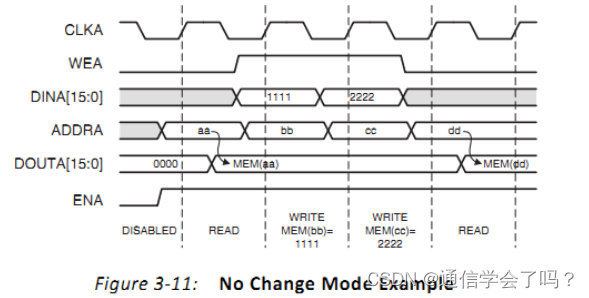
端口使能信号类型设置,一个是一直使能,一个是通过一个 ENA 信号管脚控制,这里选择 Always Enable。
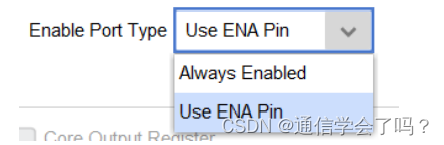
由于我们前面选择的是简单双端口 RAM,对于端口 A 只能进行数据的写入,没有数据的输出,所有关于端口 A 的数据输出的相关配置是不可配置的。
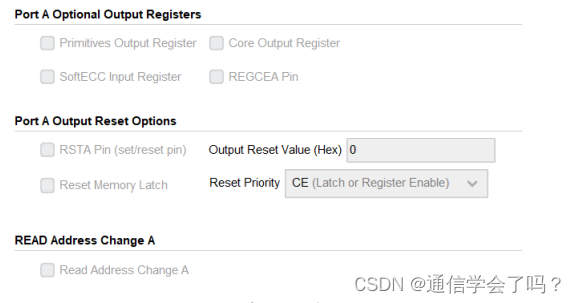
端口 B 数据位宽和内存深度的设置,这里设置位宽为8,深度会自动根据你选择的位宽进行设置。
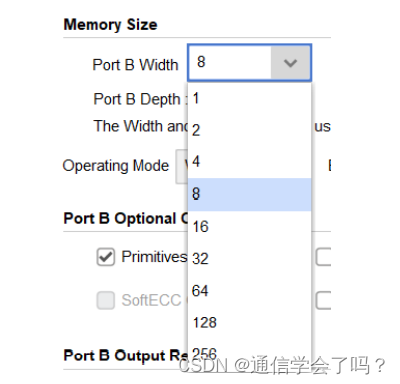
端口 B 操作模式不可设置,由于在简单双端口 RAM 下端口 B 只能进行读操作,不能进行写操作,所以这里不可设置,在真双单口 RAM 下,这里是可进行设置的。端口使能就设置为 Always Enable,让端口 B 一直使能。

端口 B 输出寄存器配置,这里可以看下 RAM 内部结构图,可以很清楚的看到 Primitives Output Register 是结构中的 1 处的寄存器,Core Output Register 是结构图中 2 出的寄存器。REGCEB Pin 是寄存器使能管脚,如果勾选,会有一个寄存器使能控制管脚用于控制寄存器的使能,如果不勾选寄存器就一直使能状态,这里就不勾选。要得到更好的性能,将这里的两个寄存器都勾选。
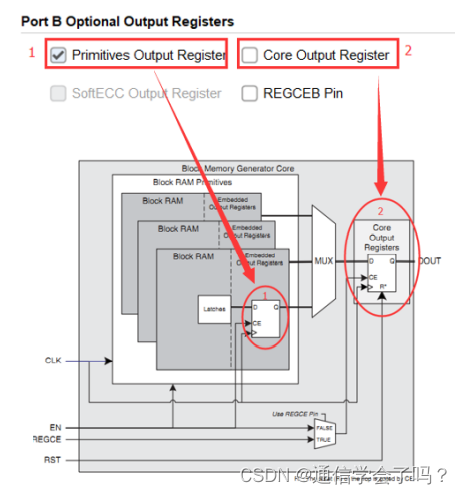
端口 B 输出置位/复位设置,这里不创建置位/复位端口,需注意这里置位/复位并不复位RAM 中的数据而是只复位寄存器上的值。
其他设置,这里不对 RAM 进行初始化, 关于仿真设置就保持默认即可。
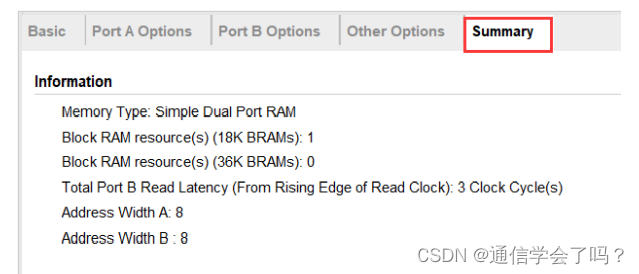
最后看一看总的情况,信息包括使用的资源,A,B 端口的地址位宽,以及端口 B Read Latency 为 3 个时钟周期。(关于Latency可以看我的ROM IP核文章)
`timescale 1ns / 1ns
`define CLKA_PERIOD 20
`define CLKB_PERIOD 40
module ram_tb();
reg clka;
reg wea;
reg [7:0]addra;
reg [7:0]dina;
reg clkb;
reg [7:0]addrb;
wire[7:0]doutb;
integer i;
ram ram_inst (
.clka(clka), // input wire clka
.wea(wea), // input wire [0 : 0] wea
.addra(addra), // input wire [7 : 0] addra
.dina(dina), // input wire [7 : 0] dina
.clkb(clkb), // input wire clkb
.addrb(addrb), // input wire [7 : 0] addrb
.doutb(doutb) // output wire [7 : 0] doutb
);
initial clka = 1'b1;
always #(`CLKA_PERIOD/2) clka = ~clka;
initial clkb = 1'b1;
always #(`CLKB_PERIOD/2) clkb = ~clkb;
initial begin
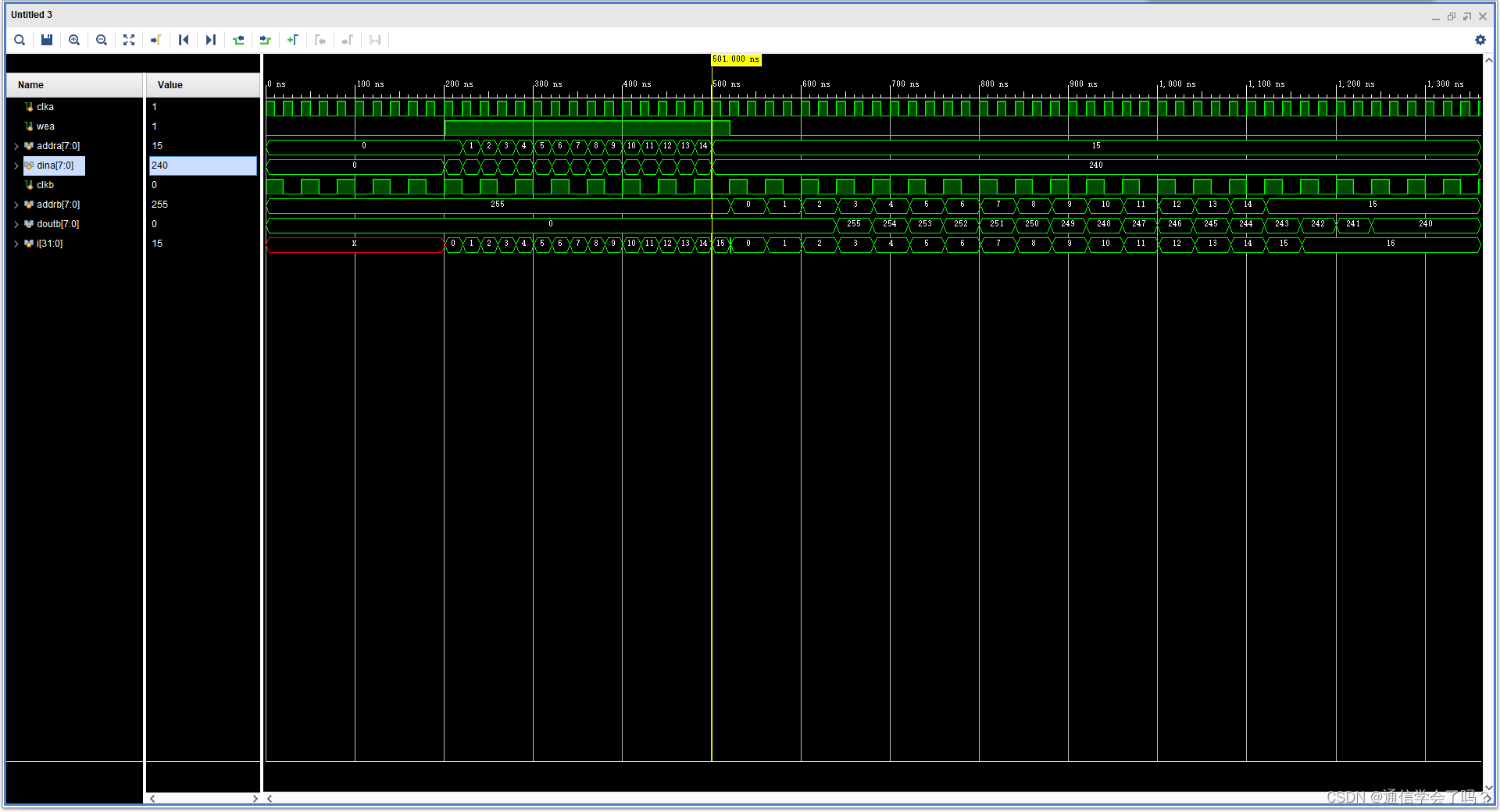
wea=0;
addra=0;
dina=0;
addrb=255; //255
#(`CLKA_PERIOD*10 +1 )
wea=1;
for (i=0;i<=15;i=i+1)begin
dina=255-i;
addra = i;
#`CLKA_PERIOD;
end
wea=0;
#1;
for (i=0;i<=15;i=i+1)begin
addrb=i;
#`CLKB_PERIOD;
end
#200;
$stop;
end
endmodule
参考阅读:
小梅哥:嵌入式块存储器RAM的介绍
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po