闲来无事,想对Kafka的一些特性进行实验验证。
我们都知道,Kafka一个topic下可以有一个或多个partition。而消费一个partition是以消费组为单位的,一个消费组中如果有多个实例,只能有一个实例能消费该partition。但是一个消费实例却可以同时消费多个partition。
如果是不同消费组的两个实例,则可以对同一个partition进行消费,且他们之间互不影响。
spring boot下配置某个消费实例所属的Kafka消费组Id:
spring.kafka.consumer.group-id: xxxx
废话少说,进入实验验证阶段。
分为写Kafka和读Kafka两个方面进行验证。
写Kafka,包括以下场景:
1、不带key写入
(1)1个topic,2个partition的情况
(2)1个topic,3个partition的情况
2、带key写入
(1)1个topic,2个partition,1个key的情况
(1)1个topic,3个partition,2个key的情况
(2)1个topic,3个partition,3个key的情况
读Kafka,包括以下场景:
1、1个topic,1个partition,2个消费实例(同一消费组)的情况
2、1个topic,2个partition,3个消费实例(同一消费组)的情况
3、1个topic,2个partition,3个消费实例,两个消费组的情况
结论:不带key写Kafka时,将随机写入多个partition。
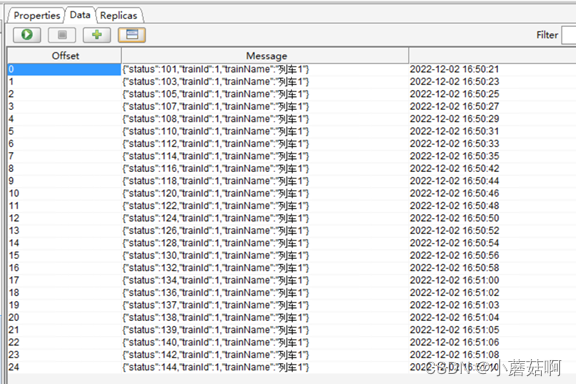
操作: 将一个topic的消息不带key,写入Kafka。现象如下所示,可以看到topic的消息被随机(注意并不是轮询方式)写入2个partition中。
partition0:
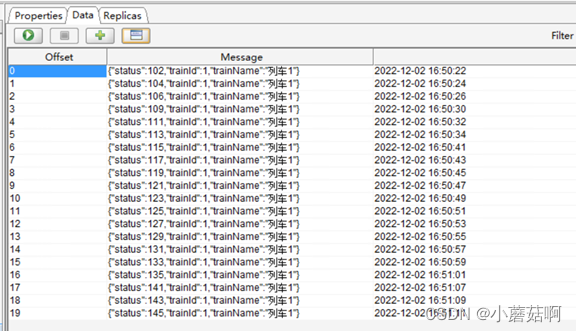
partition1:
操作:将一个topic的消息不带key,写入Kafka。现象如下所示,可以看到消息被随机(注意并不是轮询方式)写入3个partition中。
partition0:

partition1:
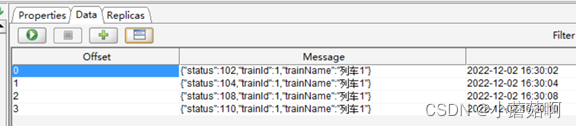
partition1:
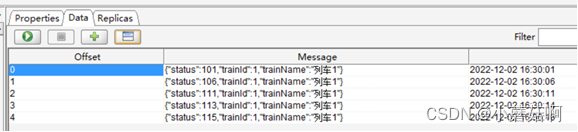
结论:相同的key会保证写入同一个partition。

操作: 将一个topic的消息带key,写入Kafka。现象如下所示,可以看到消息被固定写入某个partition中。
partition0: 没有数据
partition1:


操作: 将一个topic的消息带key,写入Kafka。现象如下所示,可以看到相同key的消息被写入相同的partition中。
partition0: 所有key为1的消息都写入了partition0
partition1: 没有数据
partition2: 所有key为2的消息都写入了partition2

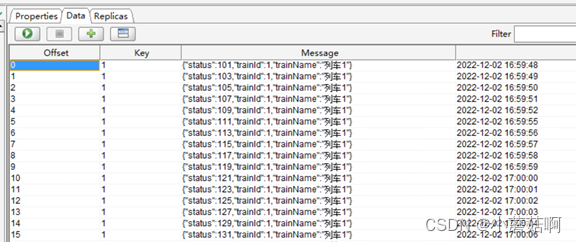
操作: 将一个topic的消息带key,写入Kafka。现象如下所示,可以看到相同key的消息被写入相同的partition中。
partition0: 所有key为1的消息都写入了partition0
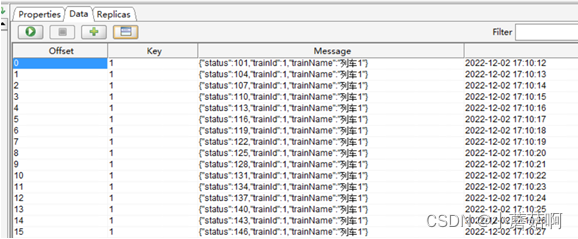
partition1: 没有数据
partition2: 所有key为2和3的消息都写入了partition2

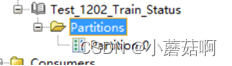
步骤1:
启动2个消费实例,然后往partition中生产消息,实例A未消费,只有实例B在消费partition。
实例B消费:
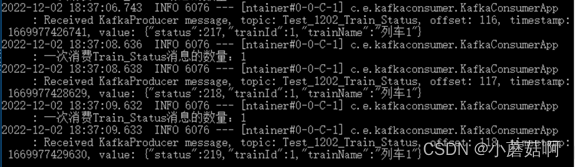
实例A未消费:
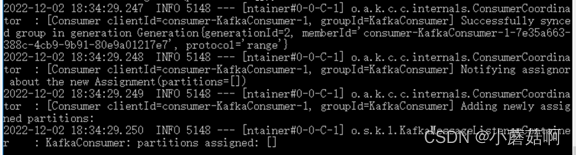
步骤2:
当suhtdown正在消费的实例B时,过了一段时间后(大概45秒),实例A开始消费partition。
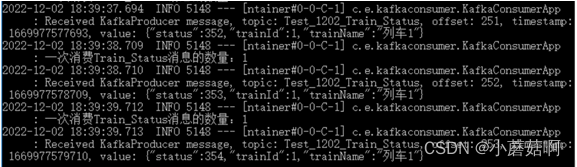
步骤3:
当重新启动实例B后(几乎没有时间间隔),实例B继续消费partition,而实例A不再消费。
实例B消费:
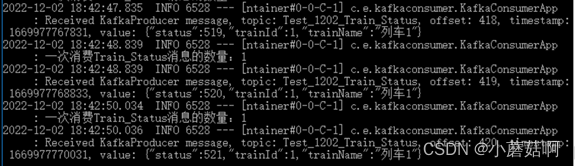
实例A不再消费:


步骤1:
启动3个消费实例,然后往2个partition中生产消息,会发现 有一个实例不消费,另外两个实例分别消费一个partition。
实例A消费partition1,实例B消费partition0,实例C不消费。
实例A消费partition1(列车1的消息)

实例B消费partition0(列车2的消息)
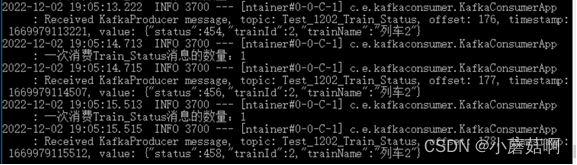
步骤2:
shutdown其中一个正在消费的实例B,一段时间后(大概45秒), 剩下的两个实例重新分配partition进行消费。 实例A消费partition0(列车2),实例C消费partition1(列车1)。
实例A消费partition0(列车2):
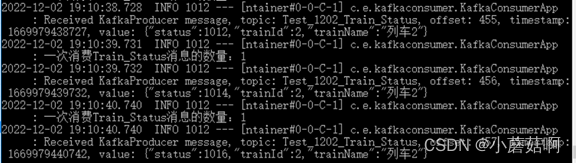
实例C消费partition1(列车1)::
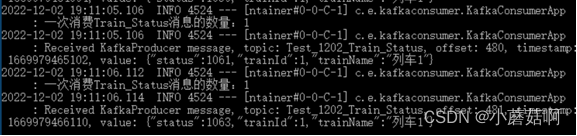
步骤3:
重新启动实例B后(几乎没有时间间隔),实例B继续消费partition0(列车2),同时实例C不再消费。
实例B消费partition0(列车2):
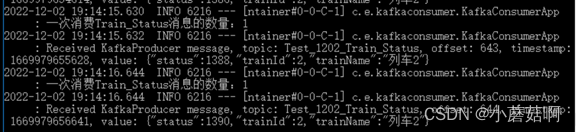
实例C不再消费:
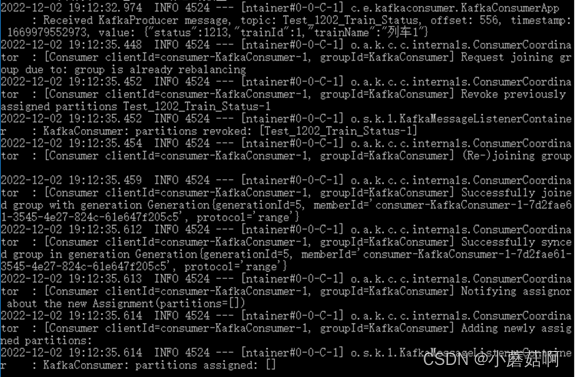
步骤1:
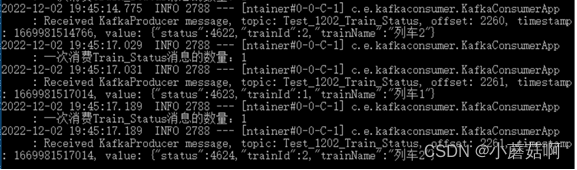
启动3个消费实例(实例A和B属于消费组1,实例C属于消费组2),然后往2个partition中生产消息,会发现 实例A消费partition1,实例B消费partition0,实例C同时消费partition0和partition1。
实例A消费partition1(列车1)
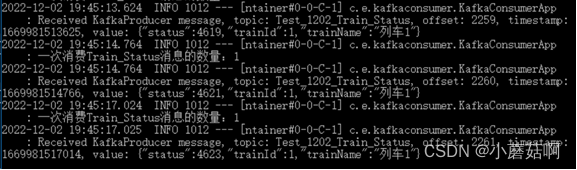
实例B消费partition0(列车2)
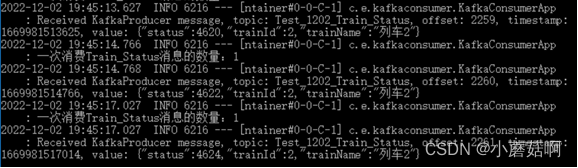
实例C消费partition0(列车2)和partition1(列车1)
这是在Ruby中设置默认值的常用方法:classQuietByDefaultdefinitialize(opts={})@verbose=opts[:verbose]endend这是一个容易落入的陷阱:classVerboseNoMatterWhatdefinitialize(opts={})@verbose=opts[:verbose]||trueendend正确的做法是:classVerboseByDefaultdefinitialize(opts={})@verbose=opts.include?(:verbose)?opts[:verbose]:trueendend编写Verb
我正在查看instance_variable_set的文档并看到给出的示例代码是这样做的:obj.instance_variable_set(:@instnc_var,"valuefortheinstancevariable")然后允许您在类的任何实例方法中以@instnc_var的形式访问该变量。我想知道为什么在@instnc_var之前需要一个冒号:。冒号有什么作用? 最佳答案 我的第一直觉是告诉你不要使用instance_variable_set除非你真的知道你用它做什么。它本质上是一种元编程工具或绕过实例变量可见性的黑客攻击
在我的应用程序中,我需要能够找到所有数字子字符串,然后扫描每个子字符串,找到第一个匹配范围(例如5到15之间)的子字符串,并将该实例替换为另一个字符串“X”。我的测试字符串s="1foo100bar10gee1"我的初始模式是1个或多个数字的任何字符串,例如,re=Regexp.new(/\d+/)matches=s.scan(re)给出["1","100","10","1"]如果我想用“X”替换第N个匹配项,并且只替换第N个匹配项,我该怎么做?例如,如果我想替换第三个匹配项“10”(匹配项[2]),我不能只说s[matches[2]]="X"因为它做了两次替换“1fooX0barXg
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
我是rails的新手,想在form字段上应用验证。myviewsnew.html.erb.....模拟.rbclassSimulation{:in=>1..25,:message=>'Therowmustbebetween1and25'}end模拟Controller.rbclassSimulationsController我想检查模型类中row字段的整数范围,如果不在范围内则返回错误信息。我可以检查上面代码的范围,但无法返回错误消息提前致谢 最佳答案 关键是您使用的是模型表单,一种显示ActiveRecord模型实例属性的表单。c
我有一个正在构建的应用程序,我需要一个模型来创建另一个模型的实例。我希望每辆车都有4个轮胎。汽车模型classCar轮胎模型classTire但是,在make_tires内部有一个错误,如果我为Tire尝试它,则没有用于创建或新建的activerecord方法。当我检查轮胎时,它没有这些方法。我该如何补救?错误是这样的:未定义的方法'create'forActiveRecord::AttributeMethods::Serialization::Tire::Module我测试了两个环境:测试和开发,它们都因相同的错误而失败。 最佳答案
我正在处理旧代码的一部分。beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)endRubocop错误如下:Avoidstubbingusing'allow_any_instance_of'我读到了RuboCop::RSpec:AnyInstance我试着像下面那样改变它。由此beforedoallow_any_instance_of(SportRateManager).toreceive(:create).and_return(true)end对此:let(:sport_
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
我最近决定从我的系统中卸载RVM。在thispage提出的一些论点说服我:实际上,我的决定是,我根本不想担心Ruby的多个版本。我只想使用1.9.2-p290版本而不用担心其他任何事情。但是,当我在我的Mac上运行ruby--version时,它告诉我我的版本是1.8.7。我四处寻找如何简单地从我的Mac上卸载这个Ruby,但奇怪的是我没有找到任何东西。似乎唯一想卸载Ruby的人运行linux,而使用Mac的每个人都推荐RVM。如何从我的Mac上卸载Ruby1.8.7?我想升级到1.9.2-p290版本,并且我希望我的系统上只有一个版本。 最佳答案