Yolov5如何在训练意外中断后接续训练
操作系统:Ubuntu20.04
CUDA版本:11.4
Pytorch版本:1.9.0
TorchVision版本:0.7.0
IDE:PyCharm
硬件:RTX2070S*2

在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python、主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时停下是十分崩溃了,好在博主摸索到在yolov5中接续训练的方法了。
首先直接上方法
如果你想从上一次训练结果中回复训练,那么首先保证你的训练结果(一般都存放在/runs/train目录下)在保存目录中代号为最大的。
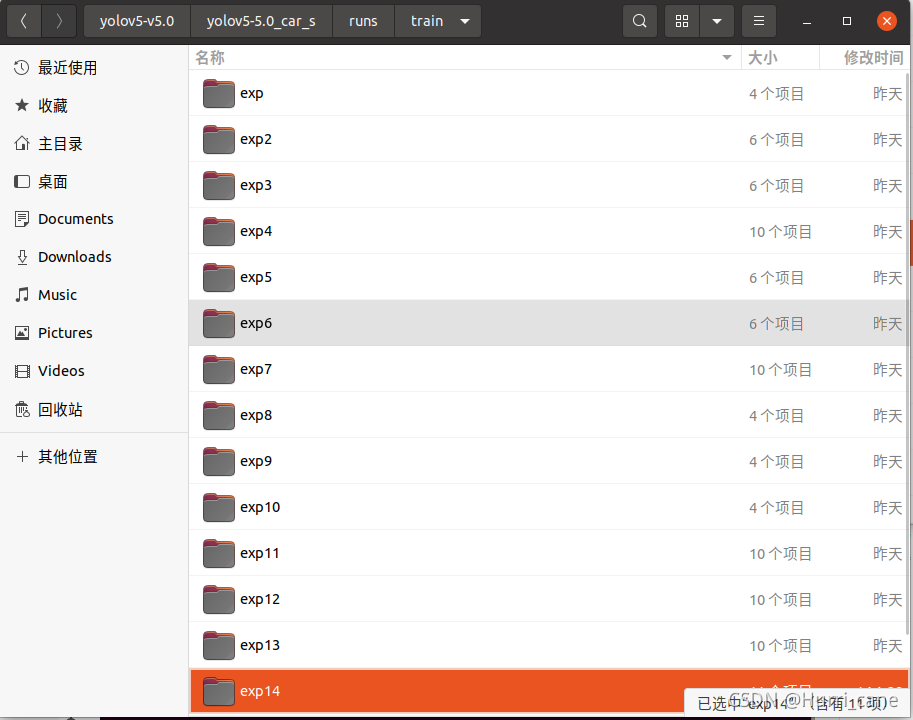
如上图所示,在train文件夹下一共有14个训练结果,假设我的第12次训练中断了,想接着第12次的结果继续训练,那么只需要将比12更大的:exp13、exp14这两个文件夹删除或者移动到其他地方,这样便设置好了需要接续训练的结果。
代码见yolov5代码中的train.py
if __name__ == '__main__':
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='../weights/yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/car.yaml', help='data.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=32, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='1', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
opt = parser.parse_args()
注意上面patser中第9个参数resume,将其设置为default=True即可,也就是那一行代码改变为
parser.add_argument('--resume', nargs='?', const=True, default=True, help='resume most recent training')
接下来运行python train.py边不会产生新的exp而是在最新的exp上接续训练
如下图所示:
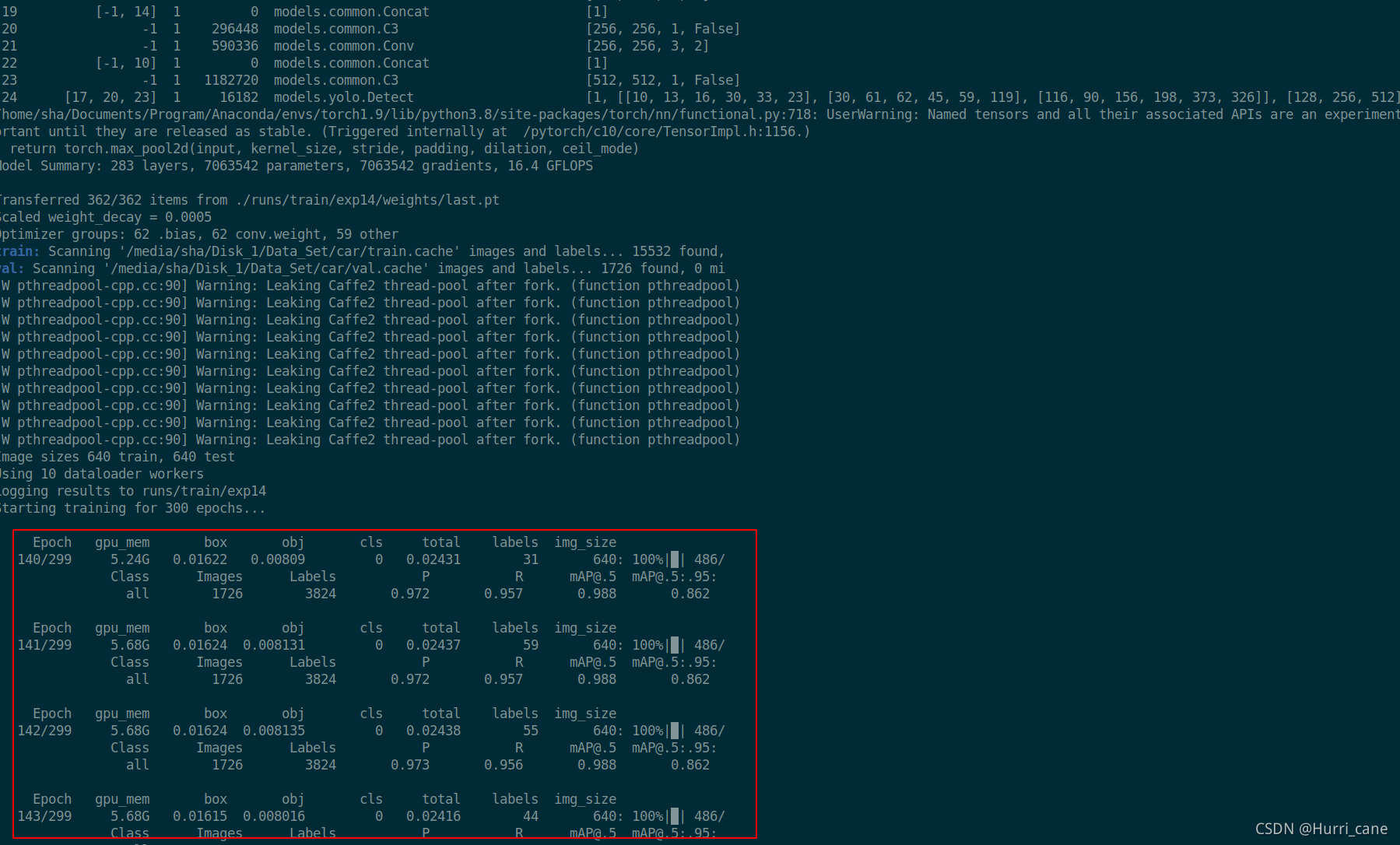
博主运行完python train.py后便是接着上一次训练完139个epoch继续训练
其实接续训练不是什么深奥内容 ,博主在训练自己模型的时候也早会使用。
我们在使用yolov5提供的权重,也就是像yolov5s.pt之类的文件时就是使用了官方提供的模型接续训练的。
我们每次训练模型时都会生成新的模型结果,存放在/runs/train/expxxx/weights下,接续训练就是将上次训练一半得到的结果拿来和模型结合进行训练。具体来说:如果最终训练目标是300个epoch,上次训练完了139个epoch,那么就是将第139个epoch得到的权重载入到模型中再训练161个epoch便可等效为训练了300个epoch
如果本文对你有帮助的话还请点赞、收藏一键带走哦,你的支持是我最大的动力!(づ。◕ᴗᴗ◕。)づ

出于纯粹的兴趣,我很好奇如何按顺序创建PI,而不是在过程结果之后生成数字,而是让数字在过程本身生成时显示。如果是这种情况,那么数字可以自行产生,我可以对以前看到的数字实现垃圾收集,从而创建一个无限系列。结果只是在Pi系列之后每秒生成一个数字。这是我通过互联网筛选的结果:这是流行的计算机友好算法,类机器算法:defarccot(x,unity)xpow=unity/xn=1sign=1sum=0loopdoterm=xpow/nbreakifterm==0sum+=sign*(xpow/n)xpow/=x*xn+=2sign=-signendsumenddefcalc_pi(digits
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
为了将Cucumber用于命令行脚本,我按照提供的说明安装了arubagem。它在我的Gemfile中,我可以验证是否安装了正确的版本并且我已经包含了require'aruba/cucumber'在'features/env.rb'中为了确保它能正常工作,我写了以下场景:@announceScenario:Testingcucumber/arubaGivenablankslateThentheoutputfrom"ls-la"shouldcontain"drw"假设事情应该失败。它确实失败了,但失败的原因是错误的:@announceScenario:Testingcucumber/ar
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我实际上是在尝试使用RVM在我的OSX10.7.5上更新ruby,并在输入以下命令后:rvminstallruby我得到了以下回复:Searchingforbinaryrubies,thismighttakesometime.Checkingrequirementsforosx.Installingrequirementsforosx.Updatingsystem.......Errorrunning'requirements_osx_brew_update_systemruby-2.0.0-p247',pleaseread/Users/username/.rvm/log/138121
这可能是个愚蠢的问题。但是,我是一个新手......你怎么能在交互式rubyshell中有多行代码?好像你只能有一条长线。按回车键运行代码。无论如何我可以在不运行代码的情况下跳到下一行吗?再次抱歉,如果这是一个愚蠢的问题。谢谢。 最佳答案 这是一个例子:2.1.2:053>a=1=>12.1.2:054>b=2=>22.1.2:055>a+b=>32.1.2:056>ifa>b#Thecode‘if..."startsthedefinitionoftheconditionalstatement.2.1.2:057?>puts"f
我是一个Rails初学者,但我想从我的RailsView(html.haml文件)中查看Ruby变量的内容。我试图在ruby中打印出变量(认为它会在终端中出现),但没有得到任何结果。有什么建议吗?我知道Rails调试器,但更喜欢使用inspect来打印我的变量。 最佳答案 您可以在View中使用puts方法将信息输出到服务器控制台。您应该能够在View中的任何位置使用Haml执行以下操作:-puts@my_variable.inspect 关于ruby-on-rails-如何在我的R