1. 概念: 针对二分类问题,寻求最优超平面
SVM: 使到超平面最近的样本点的“距离”最大
SVR: 使到超平面最远的样本点的“距离”最小。
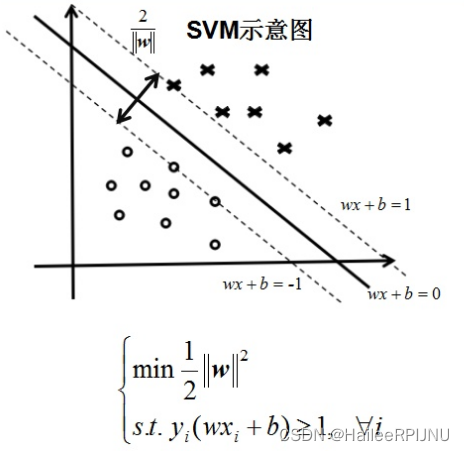
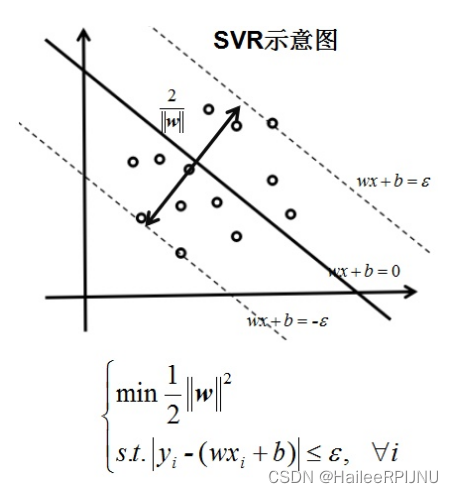
SVR回归的优势:容忍偏离
传统的回归方法当且仅当回归f(x)完全等于y时才认为是预测正确,需计算其损失;而支持向量回归(SVR)则认为只要是f(x)与y偏离程度不要太大,既可认为预测正确,不用计算损失。 eg: 支持向量回归表示只要在虚线内部的值都可认为是预测正确,只要计算虚线外部的值的损失即可。
2. 简易截面回归,并计算残差

3. SVR 参数详解
sklearn.svm.SVR(kernel='rbf', degree=3, gamma='auto_deprecated', coef0=0.0, tol=0.001, C=1.0, epsilon=0.1, shrinking=True,probability=False, cache_size=200, verbose=False, max_iter=-1, class_weight=None,decision_function_shape='ovr', random_state=None)
kernel:算法中所使用的核函数类型,其中有(‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’,‘precomputer’,默认使用‘rbf’)
degree:多项式核函数的次数,默认为3,所以当核函数为‘poly’时用到,其它核函数忽略
gamma: 核函数的系数, 在核函数为‘rbf’, ‘poly’, ‘sigmoid’时使用,其他核函数忽略。gamma的值必须大于0, 随着gamma的增大,对于测试集分类效果越差,对于训练集分类效果好,并且使模型的复杂度提高,泛化能力(对未知数的预测能力)较差,从而出现过拟合的情况。
coef0:核函数中的常数值(y=kx +b中的b值),只在核函数为‘poly’跟‘sigmoid’时使用。
tol:残差收敛条件,默认是0.0001,即容忍1000分类里出现一个错误,误差达到指定值时停止训练。
C: 错误项的惩罚因子:
原则上C可以根据需要选择所有大于0的数。C越大表示整个优化过程中对于总误差的关注程度越高,对于减小误差的要求越高,甚至不惜使间隔减小。
epsilon:type:float, optional(default=0.1)
pass
shrinking:是否使用收缩启发式
probability: 是否使用概率估计,默认是False。
cache_size: 内核缓存的大小,用来限制计算量,默认是200M
verbose:启用详细输出。如果启用,在多线程环境下可能无法正常工作
max_iter:type:int, 最大迭代次数,默认为-1(无限制)
class_weight : {dict, ‘balanced’},字典类型或者'balance'字符串。权重设置,正类和反类的样本数量是不一样的,这里就会出现类别不平衡问题,该参数就是指每个类所占据的权重,默认为1,即默认正类样本数量和反类一样多,也可以用一个字典dict指定每个类的权值,或者选择默认的参数balanced,指按照每个类中样本数量的比例自动分配权值
decision_function_shape : 原始的SVM只适用于二分类问题,如果要将其扩展到多类分类,就要采取一定的融合策略,这里提供了三种选择。‘ovo’ 一对一,为one v one,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果,决策所使用的返回的是(样本数,类别数*(类别数-1)/2); ‘ovr’ 一对多,为one v rest,即一个类别与其他类别进行划分,返回的是(样本数,类别数),或者None,就是不采用任何融合策略。默认是ovr。
random_state: 在使用SVM训练数据时,要先将训练数据打乱顺序,用来提高分类精度,这里就用到了伪随机序列。如果该参数给定的是一个整数,则该整数就是伪随机序列的种子值;如果给定的就是一个随机实例,则采用给定的随机实例来进行打乱处理;如果啥都没给,则采用默认的 np.random实例来处理。
可以看到,其中核函数是参数中非常重要的角色,那么什么是核函数?
核函数是为了解决维度转换过程中带来的过拟合问题而诞生的。对于非线性支持向量回归机,通常的做法是将数据从低维映射到高维,在高维中找到线性可分的超平面,再把高维空间的超平面映射回低维空间,这样就可以实现SVM的分类和回归,但是,在高维做计算的时候,计算量很大,也非常容易过拟合。
核函数的作用就在这里,在低维就做了计算,而这个计算可以看做将低维空间的数据映射到高维空间的隐式变换。它可以使原来的线性算法非线性化,即能做到非线性回归(有效控制过拟合)。
具体的用法来说,一般分为线性核和高斯核。
Linear 线性核:主要用于线性可分的情形,参数少,速度快。【原始空间的内积】
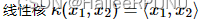
RBF核:主要用于线性不可分的情形,参数多,分类结果非常依赖于参数。【将原始空间映射为无穷维空间,应用最广泛,大样本和小样本都有比较好的性能】
如果 sigma 选得很大的话,高次特征上的权重实际上衰减得非常快,所以实际上(数值上近似一下)相当于一个低维的子空间;反过来,如果 sigma选得很小,则可以将任意的数据映射为线性可分——当然,这并不一定是好事,因为随之而来的可能是非常严重的过拟合问题。不过,总的来说,通过调控参数 ,高斯核实际上具有相当高的灵活性,也是使用最广泛的核函数之一。
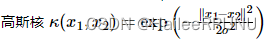
总结来说:
(1)如果特征维数很高,特征的数量大到和样本数量差不多, 往往线性可分(SVM解决非线性分类问题的思路就是将样本映射到更高维的特征空间中),可以采用LR或者线性核的SVM;
(2)如果特征数量少,样本数量很多,由于求解最优化问题的时候,目标函数涉及两两样本计算内积,使用高斯核明显计算量会大于线性核,所以手动添加一些特征,使得线性可分,然后可以用LR或者线性核的SVM;
(3)如果不满足上述两点,即特征维数少,样本数量正常,可以使用高斯核的SVM。
4. 使用网格搜索:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, RobustScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split, TimeSeriesSplit, GridSearchCV
from sklearn.svm import SVR
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error, accuracy_score
import warnings
warnings.filterwarnings('ignore')
1.数据示例
# 通过今天的价格预测五天后的价格
df['Target'] = df['Adj Close'].shift(-5)
X = df[['Adj Close']].values[:-n] 【二维】
y= df['Target'].values[:-n]

#测试集和训练集的划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, shuffle=False)
#通过pipeline将多个处理数据的节点按顺序打包在一起,数据在前一个节点处理之后的结果,转到下一个节点。
pipe = Pipeline([("scaler", MinMaxScaler()), ("regressor", SVR(kernel='rbf', C=1e3, gamma=0.1))])
pipe.fit(X_train, y_train)
y_pred = pipe.predict(X_test)
y_pred[-5:]
#检验精确度
pipe.score(X_test,y_test)
eg:0.89
#交叉验证: 使用TimeSeriesSplit,专门给时间序列设计,用于避免一次性划分测试集和训练集带来的偶然性,它是k-fold的一个变体,它首先返回k折作为训练数据集,并且 (k+1) 折作为测试数据集,连续的训练集是包含且超越前者的超集。
tscv = TimeSeriesSplit(n_splits=5)
# 查看所有参数的列表,来决定用网格搜索何种参数
pipe.get_params()

# 进行网格搜索
param_grid = {"regressor__C": [0.1, 1, 10, 100, 1000],
"regressor__kernel": ["poly", "rbf", "sigmoid"],
"regressor__gamma": [1e-7, 1e-4, 1e-3, 1e-2]}
gs = GridSearchCV(pipe, param_grid, n_jobs=-1, cv=tscv, verbose=1)
gs.fit(X_train, y_train)
# 得到搜索下最好的参数
params = gs.best_estimator_

#交叉验证下最好的评分的平均值
gs.best_score_
# 进行预测:
y_preds = gs.predict(X_test)
#比较预测结果:
print(f'Train Accuracy\t: {gs.score(X_train,y_train):0.6}')
print(f'Test Accuracy\t: {gs.score(X_test,y_test):0.6}')
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一
我正在使用RubyonRails3.0.9,我想生成一个传递一些自定义参数的link_toURL。也就是说,有一个articles_path(www.my_web_site_name.com/articles)我想生成如下内容:link_to'Samplelinktitle',...#HereIshouldimplementthecode#=>'http://www.my_web_site_name.com/articles?param1=value1¶m2=value2&...我如何编写link_to语句“alàRubyonRailsWay”以实现该目的?如果我想通过传递一些